
元數(shù)據(jù)管理在數(shù)據(jù)倉庫的實(shí)踐應(yīng)用
如果一本書是一個(gè)“數(shù)據(jù)",那么它的書名、封面、出版社、作者、總頁碼就是它的“元數(shù)據(jù)”。 如果一個(gè)電影是一個(gè)“數(shù)據(jù)”,那么它的總時(shí)長、制作人、總導(dǎo)演、演員列表就是它的“元數(shù)據(jù)”。 如果數(shù)據(jù)庫中某個(gè)表是一個(gè)”數(shù)據(jù)”,那么它的列名、列類型、列長度、表注釋就是它的"元數(shù)據(jù)"。
2、什么是數(shù)據(jù)倉庫?
3、什么是數(shù)據(jù)倉庫的元數(shù)據(jù)管理?
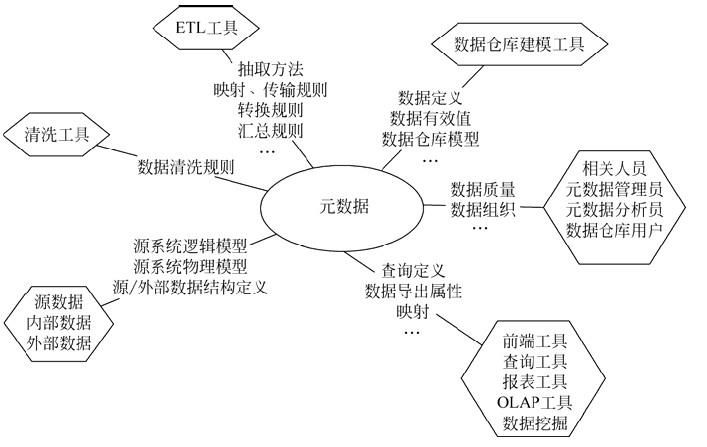
1、建設(shè)數(shù)據(jù)倉庫所必須
2、幫助快速理解數(shù)倉系統(tǒng)
3、高效精準(zhǔn)溝通
4、保證數(shù)據(jù)質(zhì)量
5、降低數(shù)據(jù)系統(tǒng)建設(shè)成本
6、快速分析變更影響
7、為未來做好準(zhǔn)備
1、業(yè)務(wù)元數(shù)據(jù)
主題定義:每段 ETL、表背后的歸屬業(yè)務(wù)主題。 業(yè)務(wù)描述:每段代碼實(shí)現(xiàn)的具體業(yè)務(wù)邏輯。 標(biāo)準(zhǔn)指標(biāo):類似于 BI 中的語義層、數(shù)倉中的一致性事實(shí);將分析中的指標(biāo)進(jìn)行規(guī)范化。 標(biāo)準(zhǔn)維度:同標(biāo)準(zhǔn)指標(biāo),對分析的各維度定義實(shí)現(xiàn)規(guī)范化、標(biāo)準(zhǔn)化。
2、技術(shù)元數(shù)據(jù)
數(shù)據(jù)清洗元數(shù)據(jù):數(shù)據(jù)清洗,主要目的是為了解決掉臟數(shù)據(jù)及規(guī)范數(shù)據(jù)格式。因此此處元數(shù)據(jù)主要為:各表各列的"正確"數(shù)據(jù)規(guī)則;默認(rèn)數(shù)據(jù)類型的"正確"規(guī)則。 數(shù)據(jù)處理元數(shù)據(jù):數(shù)據(jù)處理,例如常見的表輸入表輸出;非結(jié)構(gòu)化數(shù)據(jù)結(jié)構(gòu)化;特殊字段的拆分等。源數(shù)據(jù)到數(shù)倉、數(shù)據(jù)集市層的各類規(guī)則。比如內(nèi)容、清理、數(shù)據(jù)刷新規(guī)則。
3、管理元數(shù)據(jù)
CWM (CommonWarehouseMetamodel公共倉庫元模型)是 OMG 組織在數(shù)據(jù)倉庫系統(tǒng)中定義了一套完整的元模型體系結(jié)構(gòu),用于數(shù)據(jù)倉庫構(gòu)建和應(yīng)用的元數(shù)據(jù)建模。公共倉庫元模型指定的接口,可用于啟用交換倉庫之間元數(shù)據(jù)倉庫和業(yè)務(wù)智能工具、倉庫平臺、應(yīng)用的元數(shù)據(jù)建模和倉庫元數(shù)據(jù)存儲在分布式異構(gòu)環(huán)境 CWM 元模型由一系列子元模型構(gòu)成。 由于 CWM 制定時(shí)間是 2001 年,且過于細(xì)節(jié)深入,因此筆者認(rèn)為其更適合作為開發(fā)參考而非開發(fā)標(biāo)準(zhǔn)。
在建設(shè)數(shù)據(jù)倉庫系統(tǒng)的初期,只需確定源系統(tǒng)的元數(shù)據(jù)構(gòu)成和 數(shù)倉我們想要實(shí)現(xiàn)的元數(shù)據(jù)內(nèi)容:比如,我們只想通過元數(shù)據(jù)來管理數(shù)據(jù)倉庫中數(shù)據(jù)的轉(zhuǎn)換過程,以及有關(guān)數(shù)據(jù)的抽取路線,以使數(shù)據(jù)倉庫開發(fā)和使用人員明白倉庫中數(shù)據(jù)的整個(gè)歷史過程。 確定源系統(tǒng)和元數(shù)據(jù)構(gòu)成后,先將源系統(tǒng)的元數(shù)據(jù)整理并記錄,可以用文檔記錄;也可以存入關(guān)系型數(shù)據(jù)庫中。 隨著數(shù)據(jù)倉庫系統(tǒng)的建設(shè),逐步將需要的元數(shù)據(jù)補(bǔ)充錄入——例如 DM 的語義層、ETL 的同步規(guī)則。 數(shù)據(jù)倉庫建設(shè)完成后,對元數(shù)據(jù)進(jìn)行結(jié)構(gòu)化、標(biāo)準(zhǔn)化儲存。
1、影響分析
如果我要改動某個(gè)表、ETL,會造成怎樣的影響?
2、血緣分析
血緣分析是 data science 非常重要的應(yīng)用,未來筆者會單獨(dú)展開介紹。
3、ETL 自動化管理
以上的規(guī)則其實(shí)就屬于一部分元數(shù)據(jù)。
4、數(shù)據(jù)質(zhì)量管理
數(shù)據(jù)質(zhì)量管理,屬于?數(shù)據(jù)治理?與?元數(shù)據(jù)管理?交集,更偏向數(shù)據(jù)治理方面。未來也會展開更詳細(xì)介紹。
5、數(shù)據(jù)安全管理
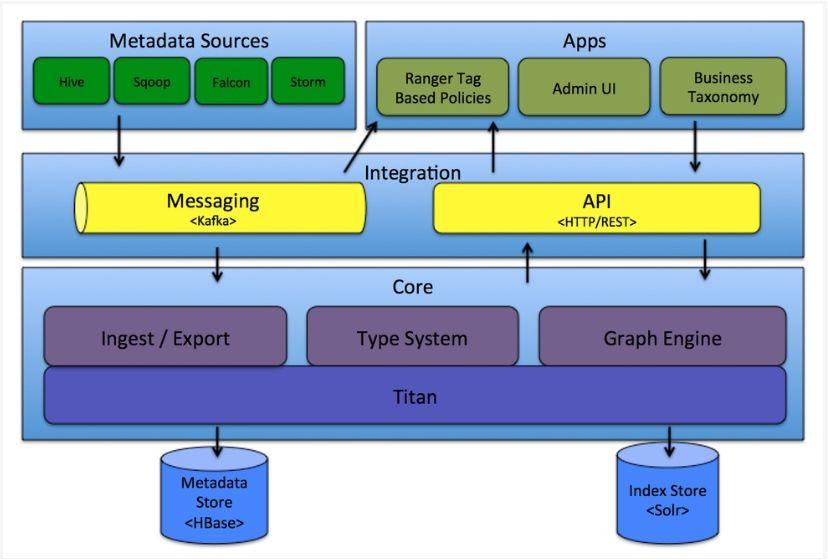
2、wherehows

支持元數(shù)據(jù)歷史版本及對比分析。 一站式的元數(shù)據(jù)分析管理系統(tǒng)。
支持的源系統(tǒng)比較少 開源版本僅支持 Azkaban 調(diào)度任務(wù)的血緣分析。其他調(diào)度任務(wù)僅能獲得元數(shù)據(jù)信息,而沒有血緣信息。 血緣分析較粗,不支持列級血緣。如 HDFS 僅能顯示數(shù)據(jù)文件之間的血緣。 Web UI 僅提供查詢能力,相關(guān)配置需要調(diào)用 API 接口。 缺乏用戶、權(quán)限管理能力。
3、其他
整個(gè)公司數(shù)據(jù)的集成——數(shù)據(jù)倉庫的搭建 整個(gè)公司業(yè)務(wù)流程的完善——"業(yè)務(wù)中臺"的實(shí)現(xiàn) 整個(gè)公司技術(shù)開發(fā)的統(tǒng)一——"技術(shù)中臺"的實(shí)現(xiàn)
阿里所推崇的數(shù)據(jù)中臺,理念上比較接近 數(shù)據(jù)倉庫+元數(shù)據(jù)管理。
用 ETL 的開發(fā)舉一個(gè)例子。
全部用 SQL 解決——開發(fā)很快,結(jié)果也很少出錯(cuò)。但未來可能要讀一個(gè)上千行的 SQL。 全部用 python 解決——開發(fā)、維護(hù)的代碼門檻較高,且性能相比 SQL 相差何止百倍。 python 來調(diào)度 SQL ——筆者較為推崇的方法,將處理邏輯變?yōu)?python 的函數(shù)、類,但底層邏輯使用 SQL 實(shí)現(xiàn)。從而達(dá)到一個(gè)相對平衡的角度。
HDFS的快照講解
Hadoop 數(shù)據(jù)遷移用法詳解
Hbase修復(fù)工具Hbck
數(shù)倉建模分層理論
一文搞懂Hive的數(shù)據(jù)存儲與壓縮
大數(shù)據(jù)組件重點(diǎn)學(xué)習(xí)這幾個(gè)
評論
圖片
表情