
Pod 垂直自動伸縮的使用

VPA(Pod 垂直自動伸縮)是 Kubernetes 中非常棒的一個功能,但是平時使用卻并不多。這是因為在最初 Kubernetes 就是為水平擴展而構(gòu)建的,垂直擴展一個 Pod 貌似不是一個好的方式,如果你想處理更多的負載,新增一個 Pod 副本可能更好。
但是這需要大量的資源優(yōu)化,如果你沒有適當?shù)卣{(diào)整你的 Pod,通過提供適當?shù)馁Y源請求和限制配置,可能最終會很頻繁地驅(qū)逐你的 Pod,或者浪費很多有用的資源。開發(fā)人員和系統(tǒng)管理員通過對資源的各種監(jiān)控,以及通過基準測試或通過對資源利用率和流量的監(jiān)控,來調(diào)整這些 Pod 的資源請求和限制的最佳值。
當流量不穩(wěn)定、資源利用率不理想的時候,可能就相對復雜一些了,隨著容器在微服務(wù)架構(gòu)中的不斷發(fā)展,系統(tǒng)管理員更注重穩(wěn)定性,這樣就導致最后使用的資源請求往往會遠遠超過實際的需求。
Kubernetes 提供了一個解決方案來解決這個問題,那就是 VPA(Vertical Pod Autoscaler),接下來我們來了解下 VPA 的作用,以及什么時候應該使用它。
VPA 如何工作
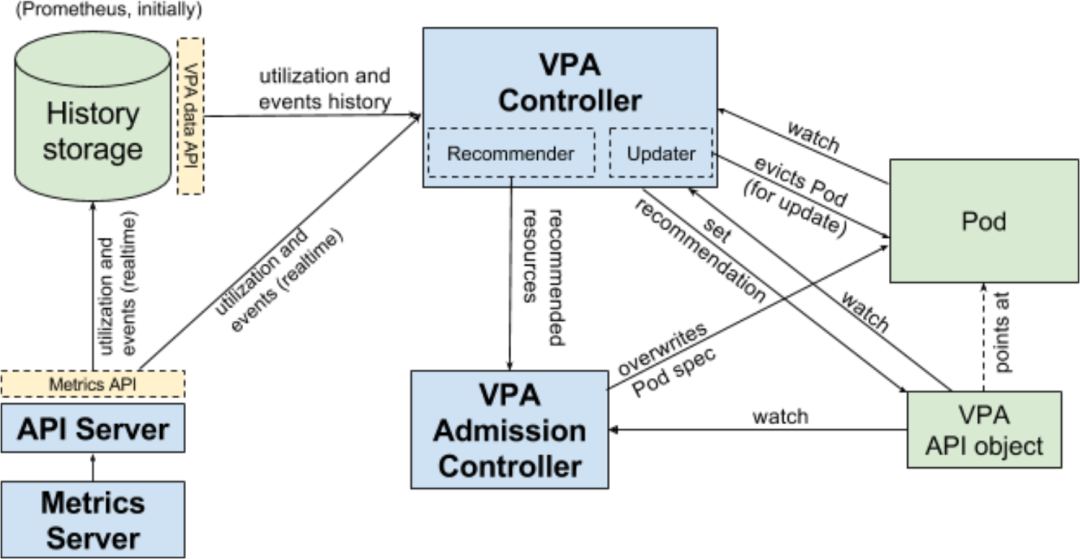
VPA 主要使用兩個組件來實現(xiàn)自動伸縮,實現(xiàn)原理如下所示:
VPA 推薦器檢查歷史資源利用率和當前使用的模式,并推薦一個理想的資源請求值 如果你將更新模式定義為自動,VPA 自動調(diào)整器將驅(qū)逐正在運行的 Pod,并根據(jù)新的資源請求值創(chuàng)建一個新的 Pod VPA 自動調(diào)整器還將按照最初定義的限制值的比例來調(diào)整限制值。
實際上資源限制并沒有什么意義,因為調(diào)整器會不斷調(diào)整它,不過,如果你想要避免內(nèi)存泄露,可以在 VPA 中設(shè)置最大的資源值。
VPA 資源清單
我們先來看一個 VPA 的資源清單文件長什么樣子,如下所示:
#?vpa-example.yaml
apiVersion:?autoscaling.k8s.io/v1beta2
kind:?VerticalPodAutoscaler
metadata:
??name:?nginx-vpa
spec:
??targetRef:
????apiVersion:?"apps/v1"
????kind:???????Deployment
????name:???????nginx
??updatePolicy:
????updateMode:?"On"
??resourcePolicy:
????containerPolicies:
????-?containerName:?"nginx"
??????minAllowed:
????????cpu:?"250m"
????????memory:?"100Mi"
??????maxAllowed:
????????cpu:?"2000m"
????????memory:?"2048Mi"
????-?containerName:?"istio-proxy"
??????mode:?"Off"
和其他資源清單文件一樣,VPA 一樣有 apiVersion、kind、metadata、spec 這些屬性,在 spec 規(guī)范部分,我們看到有一個 targetRef 的屬性,它指定這個 VPA 對象所應用的資源對象,updatePolicy 定義了這個 VPA 是否會根據(jù) updateMode 屬性進行推薦或自動縮放。如果 updateMode 屬性設(shè)置為 Auto,則 Pod 會自動垂直縮放,如果設(shè)置為 Off,則只是推薦理想的資源請求值。resourcePolicy 屬性運行我們?yōu)槊總€容器指定容器策略,并給出 minAllowed 和 maxAllowed 資源值,這一點極為重要,可以避免自動的內(nèi)存泄露。你還可以在一個 Pod 中的指定容器上關(guān)閉資源推薦和自動縮放,通常在 Istio sidecar 或 initContainer 中設(shè)置。
局限性
VPA 是有限制的。
不能和 HPA 一起使用
由于 VPA 會自動修改請求和限制值,所以不能將其與 HPA 一起使用,因為 HPA 依靠 CPU 和內(nèi)存利用率來進行水平伸縮。有一個例外的情況是,當你 HPA 依靠自定義和外部指標來進行伸縮的時候。
需要至少兩個健康的 Pod 才能工作
這種違背了它的初衷,也是沒有被廣泛使用的原因之一。由于 VPA 會破壞一個 Pod,并重新創(chuàng)建一個 Pod 來進行垂直自動伸縮,因此它需要至少兩個監(jiān)控的 Pod 副本來確保不會出現(xiàn)服務(wù)中斷。這在單實例有狀態(tài)應用上造成了不必要的復雜,你不得不考慮副本的設(shè)計。對于無狀態(tài)應用來說,你又可以更好地使用 HPA 而不是 VPA 了,所以是不是很尷尬??
默認最小內(nèi)存分配為250MiB
無論指定了什么配置,VPA 都會分配250MiB的最小內(nèi)存,雖然這個默認值可以在全局層面進行修改,但對于消耗較少內(nèi)存的應用程序來說,是比較浪費資源的。
不能用于單個 Pod
VPA 只適用于 Deployments、StatefulSets、DaemonSets、ReplicaSets 等控制器,你不能將它直接用于獨立的 Pod,當然這個也還好,因為我們基本上也不使用獨立的 Pod,而是會使用上層的控制器來管理 Pod。
在推薦模式下使用 VPA
目前 VPA 在生產(chǎn)中的最佳方式是在推薦模式下使用,這有助于我們了解最佳的資源請求值是多少,以及隨著時間推移它們是如何變化的。
一旦配置了,我們就可以通過獲取這些 metrics 指標,并將其發(fā)送到監(jiān)控工具中去,比如 Prometheus 和 Grafana 或者 ELK 技術(shù)棧。然后可以利用這些數(shù)據(jù)來調(diào)整 Pods 的大小。
當然現(xiàn)在并不建議在生產(chǎn)中用自動模式來運行 VPA,因為該特性還比較新。我們可以在開發(fā)環(huán)境中進行實驗,看看在負載不斷增加的情況下是如何表現(xiàn)的,我們可以很容易地通過運行負載測試找到 Pod 可以消耗的最大資源量,這也是我們獲取 Pod 資源限制值的一種很好的方式。
測試
首先請確保已經(jīng)在 Kubernetes 集群中啟用了 VPA。首先,創(chuàng)建一個NGINX Deployment,默認請求為250MiB 內(nèi)存和100m 的 CPU。
$?cat?<?|?kubectl?apply?-f?-
apiVersion:?apps/v1
kind:?Deployment
metadata:
??labels:
????app:?nginx
??name:?nginx
spec:
??replicas:?2
??selector:
????matchLabels:
??????app:?nginx
??strategy:?{}
??template:
????metadata:
??????labels:
????????app:?nginx
????spec:
??????containers:
??????-?image:?nginx
????????name:?nginx
????????resources:
??????????requests:
????????????cpu:?100m
????????????memory:?250Mi
EOF
現(xiàn)在我們將該應用通過 LoadBalancer 服務(wù)(如果不支持可以使用 NodePort)來對外進行暴露:
$?kubectl?expose?deployment?nginx?--type=LoadBalancer?--port?80
暴露后云服務(wù)商會提供一個負載均衡器,然后可以獲得這個負載均衡器的 IP。
$?kubectl?get?svc?nginx
NAME????TYPE???????????CLUSTER-IP???EXTERNAL-IP??????PORT(S)????????AGE
nginx???LoadBalancer???10.4.1.4?????34.121.204.234???80:30750/TCP???46s
現(xiàn)在,讓我們創(chuàng)建一個 VPA 資源對象,其中 updateMode 模式設(shè)置為 "Off",這并不會進行垂直擴展,只是提供一些建議。
#?vpa-off.ayml
$?cat?<?|?kubectl?apply?-f?-
apiVersion:?autoscaling.k8s.io/v1beta2
kind:?VerticalPodAutoscaler
metadata:
??name:?nginx-vpa
spec:
??targetRef:
????apiVersion:?"apps/v1"
????kind:???????Deployment
????name:???????nginx
??updatePolicy:
????updateMode:?"Off"
??resourcePolicy:
????containerPolicies:
????-?containerName:?"nginx"
??????minAllowed:
????????cpu:?"250m"
????????memory:?"100Mi"
??????maxAllowed:
????????cpu:?"2000m"
????????memory:?"2048Mi"
EOF
接下來我們使用 hey 這個工具來進行一些負載測試,看看會得到什么樣的結(jié)果。
$?hey?-z?300s?-c?1000?http://34.121.204.234
該命令使用1000個線程發(fā)出300秒的請求。我們可以運行下面的命令來獲取 VPA 的相關(guān)信息:
$?kubectl?describe?vpa?nginx-vpa
如果觀察一段時間,我們會發(fā)現(xiàn) VPA 會逐漸增加推薦的資源請求。
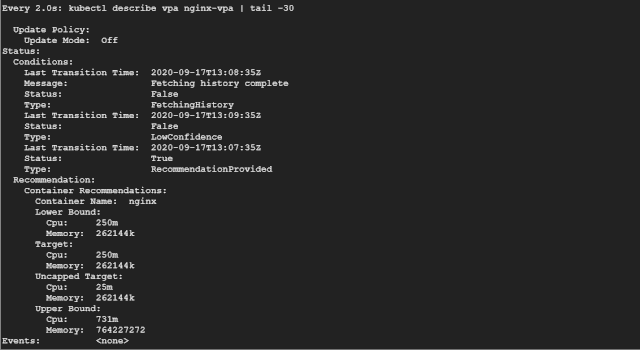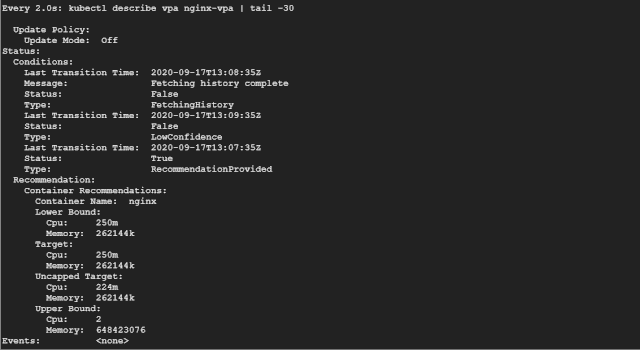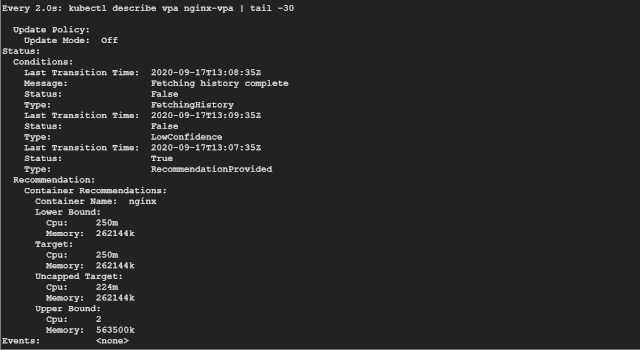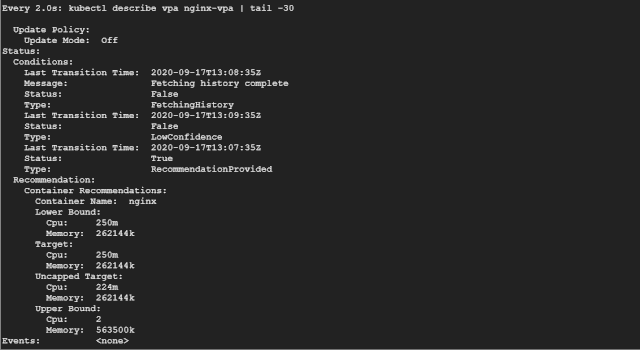
如果你看 Recommendation 推薦部分,可以看到如下所示的一些信息:
Target:這是 VPA 在驅(qū)逐當前 Pod 并創(chuàng)建另一個 Pod 時將使用的真實值。 Lower Bound:這反映了觸發(fā)調(diào)整大小的下限,如果你的 Pod 利用率低于這些值,則 VPA 會將其逐出并縮小其規(guī)模。 Upper Bound:這表示下一次要觸發(fā)調(diào)整大小的上限。如果你的 Pod 利用率高于這些值,則 VPA 會將其驅(qū)逐并擴大其規(guī)模。 Uncapped target:如果你沒有為 VPA 提供最小或最大邊界值,則表示目標利用率。
現(xiàn)在我們?nèi)绻?updateMode 設(shè)置成 Auto 會發(fā)生什么呢?執(zhí)行下面的程序來測試下。
#?vpa-auto.yaml
$?cat?<?|?kubectl?apply?-f?-
apiVersion:?autoscaling.k8s.io/v1beta2
kind:?VerticalPodAutoscaler
metadata:
??name:?nginx-vpa
spec:
??targetRef:
????apiVersion:?"apps/v1"
????kind:???????Deployment
????name:???????nginx
??updatePolicy:
????updateMode:?"Auto"
??resourcePolicy:
????containerPolicies:
????-?containerName:?"nginx"
??????minAllowed:
????????cpu:?"250m"
????????memory:?"100Mi"
??????maxAllowed:
????????cpu:?"2000m"
????????memory:?"2048Mi"
EOF
然后讓我們重新運行負載測試,在另一個終端中,我們將持續(xù)觀察 Pod,看它們被驅(qū)逐和重新創(chuàng)建的過程。
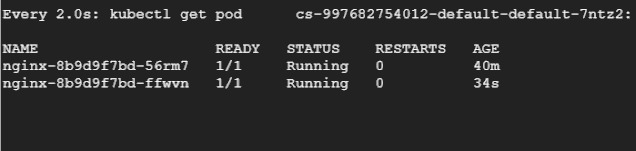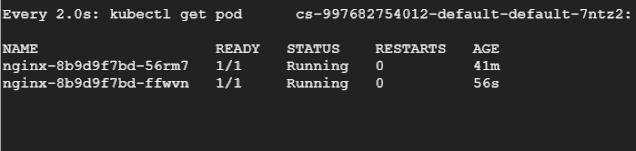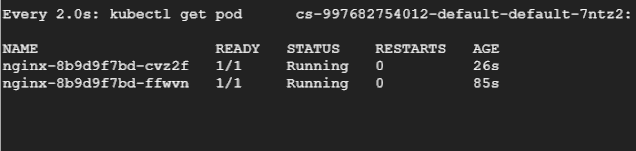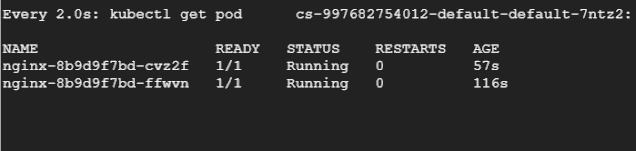
總結(jié)
VPA 是 Kubernetes 一個比較新的自動更新概念,比較適用于有狀態(tài)應用,或者了解資源利用情況的應用。但是在目前的情況下,不建議在生產(chǎn)中使用它的自動更新模式,但它的推薦模式有利于我們觀察資源的使用情況。
原文鏈接:https://medium.com/better-programming/understanding-vertical-pod-autoscaling-in-kubernetes-6d53e6d96ef3
K8S進階訓練營,點擊下方圖片了解詳情
