
終于有人總結(jié)了圖神經(jīng)網(wǎng)絡(luò)!
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


導(dǎo)讀
本文從一個(gè)更直觀的角度對(duì)當(dāng)前經(jīng)典流行的GNN網(wǎng)絡(luò),包括GCN、GraphSAGE、GAT、GAE以及graph pooling策略DiffPool等等做一個(gè)簡(jiǎn)單的小結(jié)。
筆者注:行文如有錯(cuò)誤或者表述不當(dāng)之處,還望批評(píng)指正!
一、為什么需要圖神經(jīng)網(wǎng)絡(luò)?
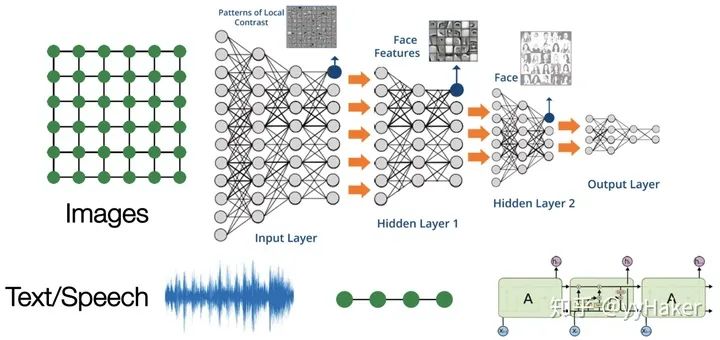
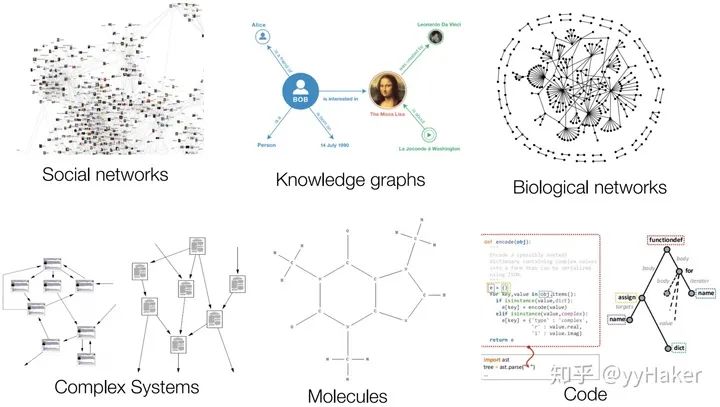
圖的大小是任意的,圖的拓?fù)浣Y(jié)構(gòu)復(fù)雜,沒(méi)有像圖像一樣的空間局部性 圖沒(méi)有固定的節(jié)點(diǎn)順序,或者說(shuō)沒(méi)有一個(gè)參考節(jié)點(diǎn) 圖經(jīng)常是動(dòng)態(tài)圖,而且包含多模態(tài)的特征
二. 圖神經(jīng)網(wǎng)絡(luò)是什么樣子的?
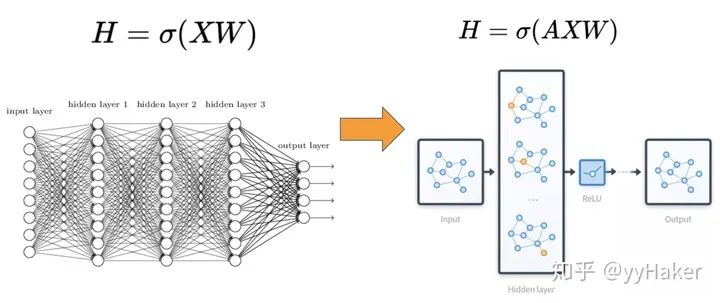
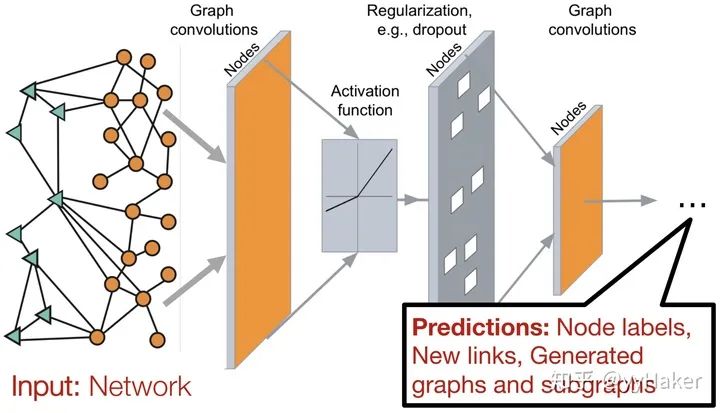
三、圖神經(jīng)網(wǎng)絡(luò)的幾個(gè)經(jīng)典模型與發(fā)展
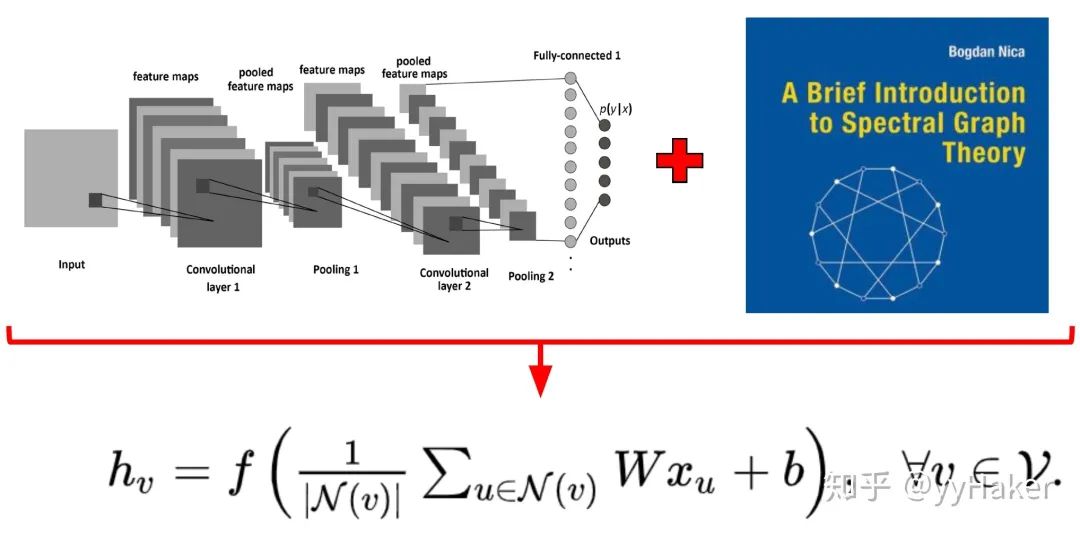
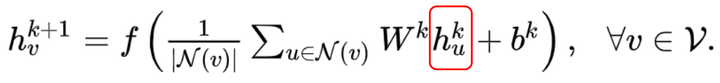
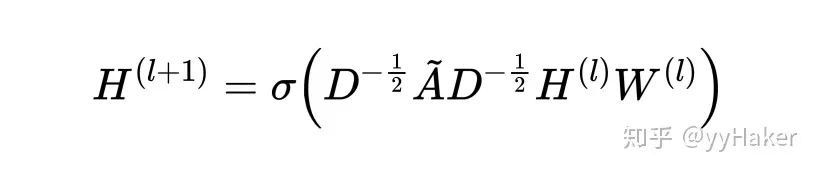
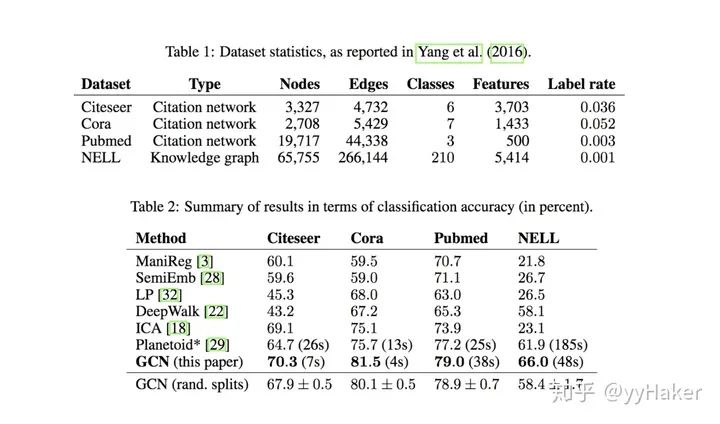
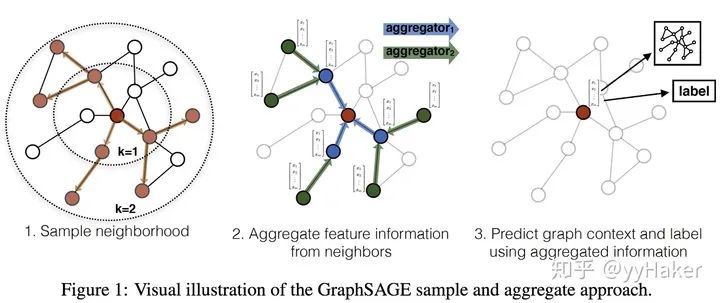




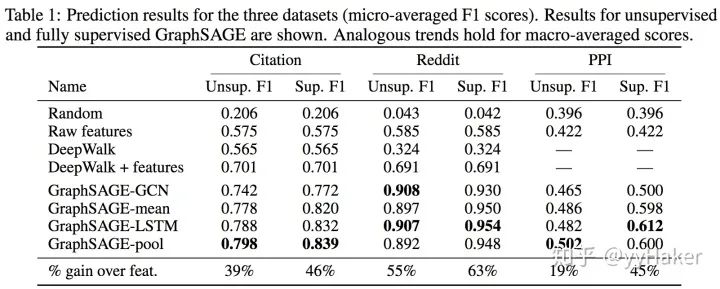
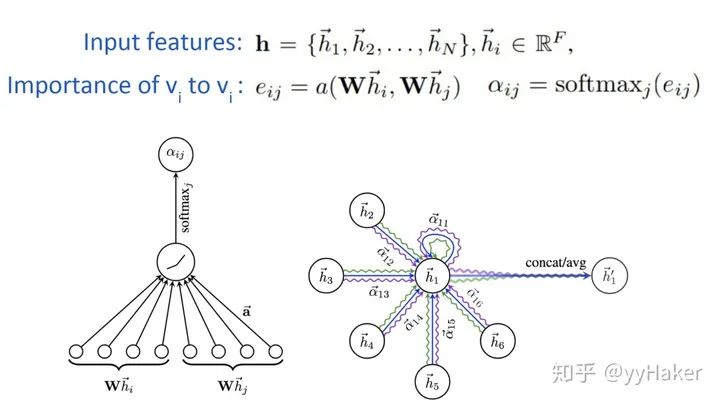
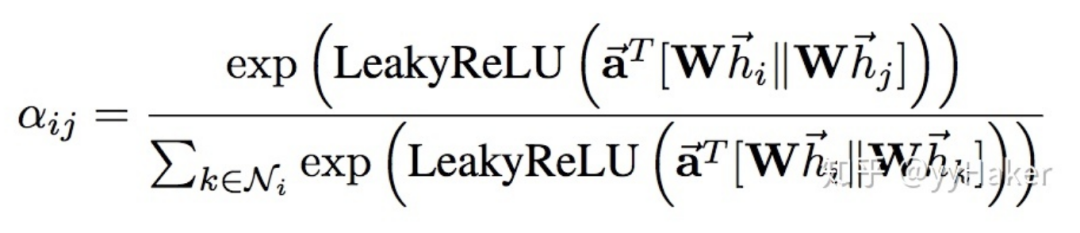
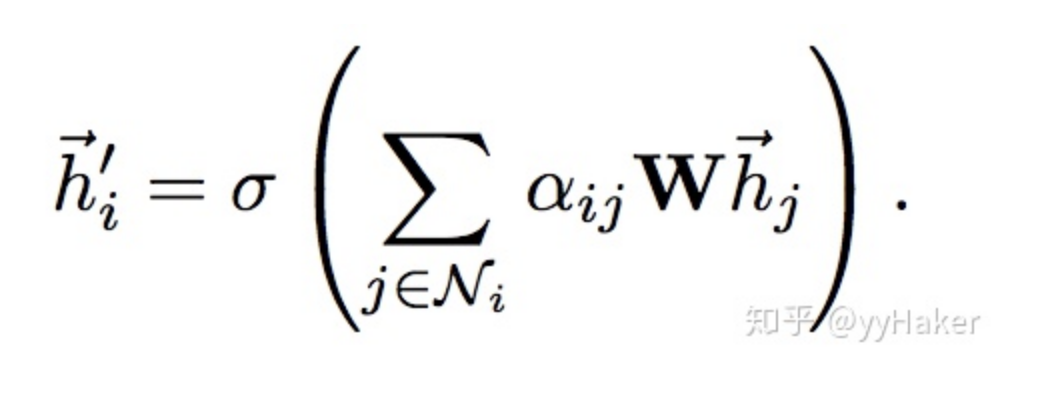
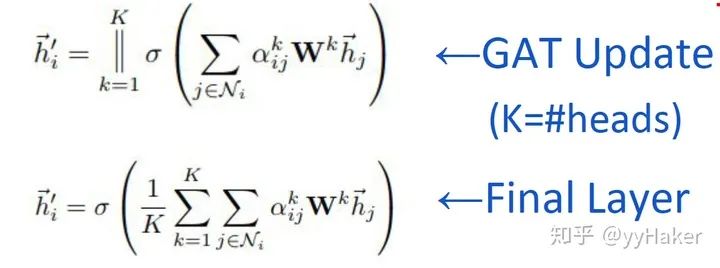
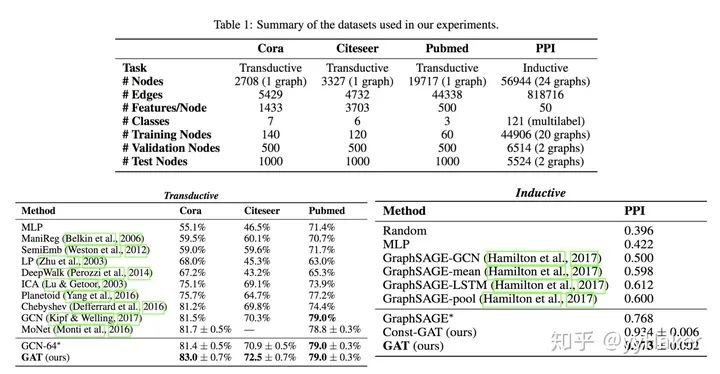
Graph Auto-Encoder(GAE)[10]
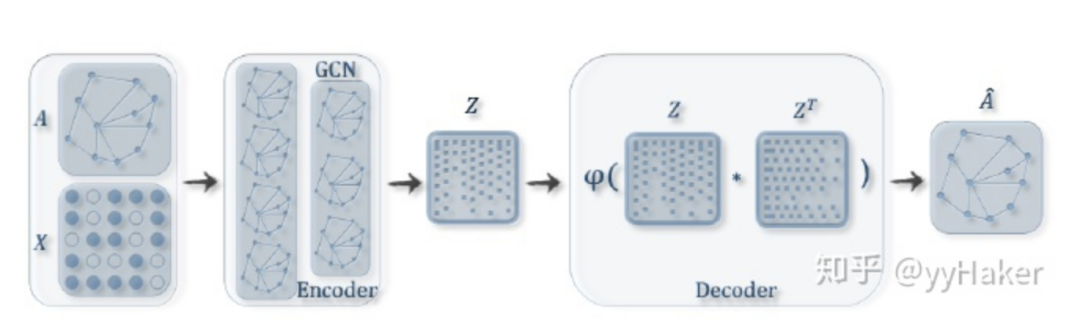

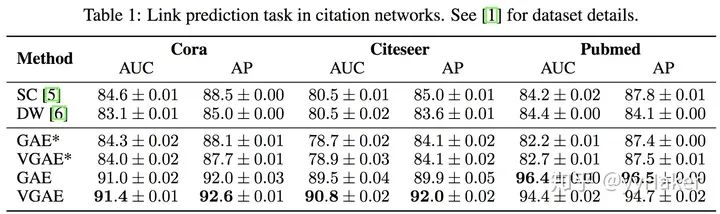
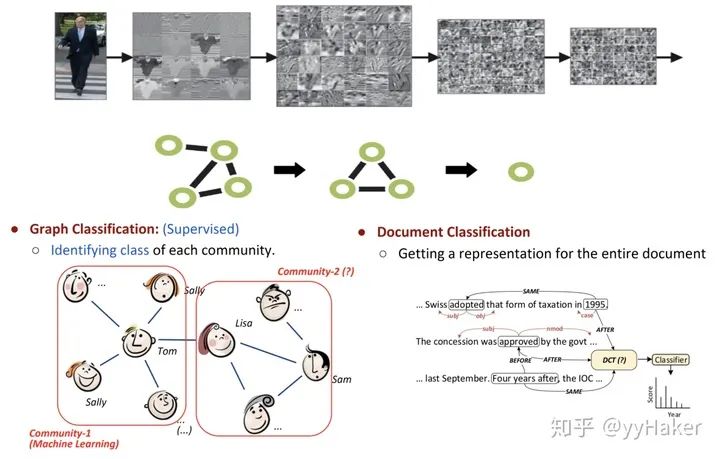
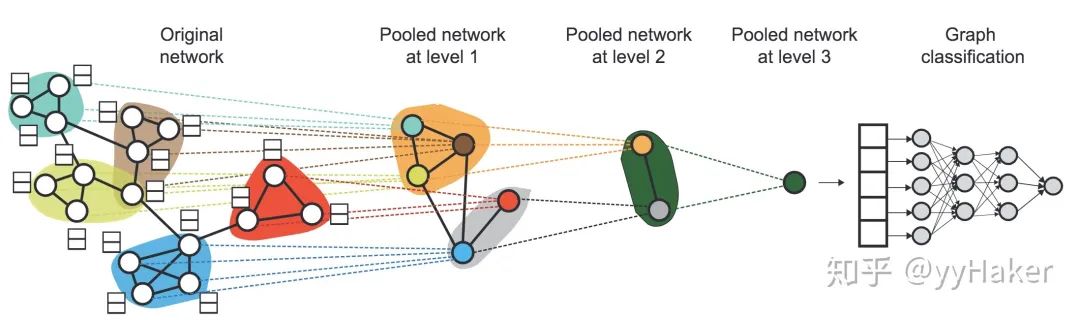
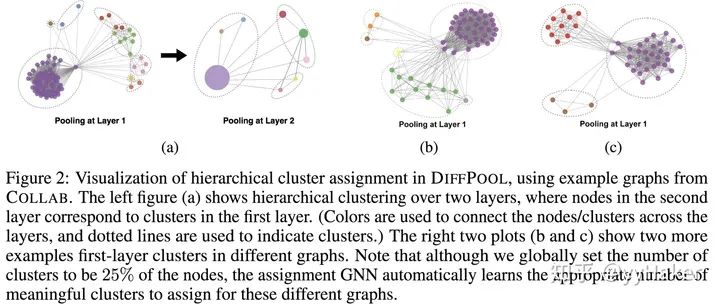
分配矩陣的學(xué)習(xí)

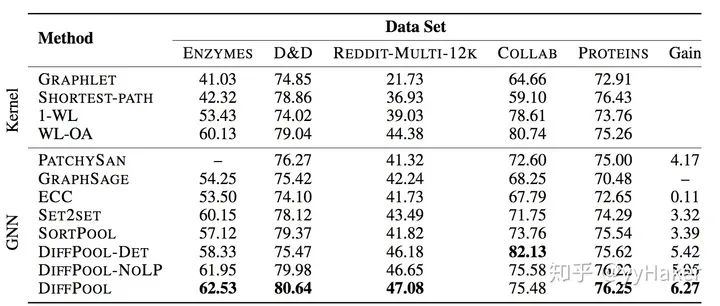
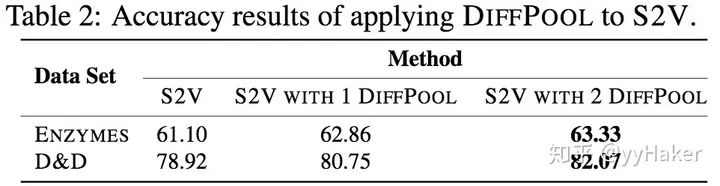
池化分配矩陣
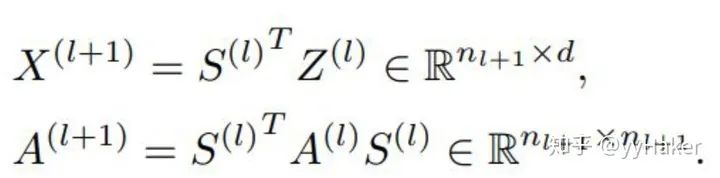
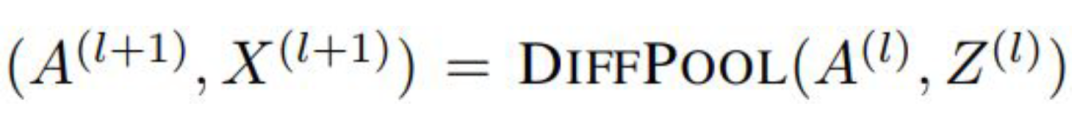
參考
推薦閱讀
國(guó)產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(wàn)(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂(lè)于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!
評(píng)論
圖片
表情