
Kubernetes存儲大腦之etcd
etcd 簡介
etcd 是兼具一致性和高可用性的鍵值數(shù)據(jù)庫,可用于服務(wù)發(fā)現(xiàn)以及配置中心。ETCD 采用 raft 一致性算法,基于 Go 語言實(shí)現(xiàn)。可以作為保存 Kubernetes 所有集群數(shù)據(jù)的后臺數(shù)據(jù)庫,在整個云原生中發(fā)揮極其重要的作用。
ectd 版本: v3.4
etcd 文檔地址: https://etcd.io/docs/v3.4/
etcd 在 kubernetes 的架構(gòu)
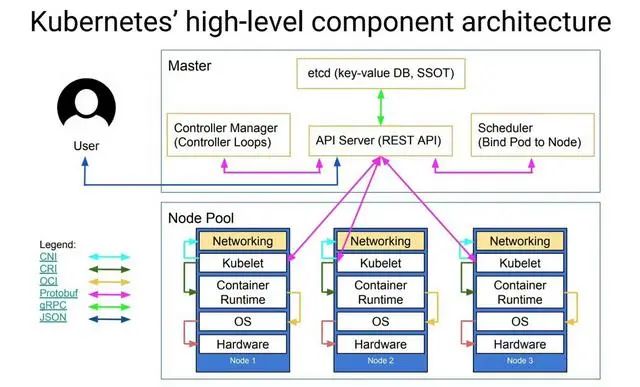
etcd 中存儲著 k8s 的所有的元數(shù)據(jù),至關(guān)重要,再次,我們就揭開 etcd 的最佳實(shí)踐。
etcd 特點(diǎn)
扁平化二進(jìn)制鍵值空間 保留事件歷史記錄,直到壓縮為止 訪問舊版本 keys 用戶自定義 key 版本歷史壓縮 支持范圍查詢 帶 limit 參數(shù)的分頁支持 支持多個范圍查詢的一致性保證 通過租約替換 TTL 鍵 更高效以及低成本的 keepalive 為不同的 TTL key 配置配置相同邏輯的租約 通過多對象 Txn 替換 CAS/CAD 更加強(qiáng)大和靈活 支持多范圍高效 watch RPC API 支持完整的 API 集 比 JSON/HTTP 更有效 額外的 TXN/租約支持 HTTP API 支持 API 子集。 用戶更容易嘗試 etcd 用戶更易于編寫簡單的 etcd 應(yīng)用程序
etcd 運(yùn)行建議
運(yùn)行的 etcd 集群個數(shù)成員為奇數(shù)。 etcd 是一個 leader-based 分布式系統(tǒng)。確保主節(jié)點(diǎn)定期向所有從節(jié)點(diǎn)發(fā)送心跳,以保持集群穩(wěn)定。 確保資源充足。
集群的性能和穩(wěn)定性對網(wǎng)絡(luò)和磁盤 IO 非常敏感。任何資源匱乏都會導(dǎo)致心跳超時,從而導(dǎo)致集群的不穩(wěn)定。不穩(wěn)定的情況表明沒有選出任何主節(jié)點(diǎn)。在這種情況下,集群不能對其當(dāng)前狀態(tài)進(jìn)行任何更改,這意味著不能調(diào)度新的 pod。保持穩(wěn)定的 etcd 集群對 Kubernetes 集群的穩(wěn)定性至關(guān)重要。因此,請在專用機(jī)器或隔離環(huán)境上運(yùn)行 etcd 集群,以滿足所需資源需求。 在生產(chǎn)中運(yùn)行的 etcd 的最低推薦版本是 3.2.10+ 硬件建議:https://etcd.io/docs/v3.4/op-guide/hardware/
etcd 架構(gòu)實(shí)踐
為了性能和高可用性,在生產(chǎn)中將以多節(jié)點(diǎn)集群的方式運(yùn)行 etcd,并且定期備份。建議在生產(chǎn)中使用五個成員的集群。有關(guān)該內(nèi)容的更多信息,請參閱https://etcd.io/docs/v3.4/faq/#what-is-failure-tolerance。
可以通過靜態(tài)成員信息或動態(tài)發(fā)現(xiàn)的方式配置 etcd 集群。有關(guān)集群的詳細(xì)信息,請參閱https://etcd.io/docs/v3.4/op-guide/clustering/。
| 集群規(guī)模 | 半數(shù)節(jié)點(diǎn) | 容錯節(jié)點(diǎn) |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
| 8 | 5 | 3 |
| 9 | 5 | 4 |
etcd 調(diào)優(yōu)指南
本次調(diào)優(yōu)針對于 etcd 本身的參數(shù)調(diào)優(yōu):
時間相關(guān)參數(shù)
在大型 etcd 集群中,由于網(wǎng)絡(luò)的復(fù)雜性,etcd 本身的分布式共識協(xié)議將受到影響,其主要依賴于兩個時間參數(shù):
第一個參數(shù)稱為 Heartbeat Interval。領(lǐng)導(dǎo)者將以此頻率通知關(guān)注者它仍然是領(lǐng)導(dǎo)者。為了獲得最佳實(shí)踐,應(yīng)圍繞成員之間的往返時間設(shè)置參數(shù)。默認(rèn)情況下,etcd 使用 100ms 心跳間隔。
第二個參數(shù)是 Election Timeout。此超時時間是指跟隨者節(jié)點(diǎn)在嘗試成為領(lǐng)導(dǎo)者之前要等待多長時間而不會聽到心跳信號。默認(rèn)情況下,etcd 使用 1000ms 選舉超時。
調(diào)整這些值是一個權(quán)衡。建議心跳間隔的值應(yīng)介于成員之間的平均往返時間(RTT)的最大值附近,通常約為往返時間的 0.5-1.5 倍。如果心跳間隔太短,etcd 將發(fā)送不必要的消息,從而增加 CPU 和網(wǎng)絡(luò)資源的使用。另一方面,過高的心跳間隔會導(dǎo)致較高的選舉超時時間。較高的選舉超時時間需要更長的時間才能檢測到領(lǐng)導(dǎo)者失敗。測量往返時間(RTT)的最簡單方法是使用 PING 實(shí)用程序。
應(yīng)該根據(jù)心跳間隔和成員之間的平均往返時間來設(shè)置選舉超時。選舉超時時間必須至少是往返時間的 10 倍,這樣才能解決網(wǎng)絡(luò)中的差異。例如,如果成員之間的往返時間為 10 毫秒,則選舉超時應(yīng)至少為 100 毫秒。
選舉超時上限為 50000ms(50s),僅在部署全球分布的 etcd 集群時才應(yīng)使用。
一個集群中所有成員的心跳間隔和選舉超時值應(yīng)相同。為 etcd 成員設(shè)置不同的值可能會破壞集群的穩(wěn)定性。
以上參數(shù)可以通過命令進(jìn)行調(diào)整:
# Command line arguments:
$ etcd --heartbeat-interval=100 --election-timeout=500
# Environment variables:
$ ETCD_HEARTBEAT_INTERVAL=100 ETCD_ELECTION_TIMEOUT=500 etcd
快照
etcd 將所有關(guān)鍵更改附加到日志文件。此日志將永遠(yuǎn)增長,并且是對鍵所做的每次更改的完整線性歷史記錄。完整的歷史記錄適用于輕度使用的集群,但是頻繁使用的集群將攜帶大量日志。
為了避免有大量日志,etcd 會進(jìn)行定期快照。這些快照為 etcd 提供了一種通過保存系統(tǒng)當(dāng)前狀態(tài)并刪除舊日志來壓縮日志的方法。
使用 V2 后端創(chuàng)建快照可能會很昂貴,因此僅在對 etcd 進(jìn)行給定數(shù)量的更改后才能創(chuàng)建快照。默認(rèn)情況下,每 10,000 次更改后將創(chuàng)建快照。如果 etcd 的內(nèi)存使用量和磁盤使用量過高,請嘗試通過在命令行上設(shè)置以下內(nèi)容來降低快照閾值:
# Command line arguments:
$ etcd --snapshot-count=5000
# Environment variables:
$ ETCD_SNAPSHOT_COUNT=5000 etcd
磁盤
etcd 集群對磁盤延遲非常敏感。由于 etcd 必須將建議持久保存到其日志中,因此其他進(jìn)程的磁盤活動可能會導(dǎo)致較長的 fsync 延遲。etcd 可能會錯過心跳,從而導(dǎo)致請求超時和臨時領(lǐng)導(dǎo)者丟失。當(dāng)給予較高的磁盤優(yōu)先級時,etcd 服務(wù)器有時可以與這些進(jìn)程一起穩(wěn)定運(yùn)行。
在 Linux 上,可以使用以下命令配置 etcd 的磁盤優(yōu)先級 ionice:
# best effort, highest priority
$ sudo ionice -c2 -n0 -p `pgrep etcd`
網(wǎng)絡(luò) 如果 etcd 領(lǐng)導(dǎo)者處理大量并發(fā)的客戶端請求,由于網(wǎng)絡(luò)擁塞,可能會延遲處理跟隨者對等體請求。這表現(xiàn)為在跟隨者節(jié)點(diǎn)上的發(fā)送緩沖區(qū)錯誤消息:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full
通過將 etcd 的對等流量優(yōu)先于其客戶端流量,可以解決這些錯誤。在 Linux 上,可以使用流量控制機(jī)制來確定對等流量的優(yōu)先級:
tc qdisc add dev eth0 root handle 1: prio bands 3
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1
內(nèi)存
etcd 默認(rèn)的存儲大小限制為 2GB,可使用--quota-backend-bytes 標(biāo)志進(jìn)行配置。建議在正常環(huán)境下使用 8GB 的最大大小,如果配置的值超過該值,etcd 會在啟動時發(fā)出警告。請求體
etcd 被設(shè)計用于元數(shù)據(jù)的小鍵值對的處理。較大的請求將工作的同時,可能會增加其他請求的延遲。默認(rèn)情況下,任何請求的最大大小為 1.5 MiB。這個限制可以通過--max-request-bytesetcd 服務(wù)器的標(biāo)志來配置。key 的歷史記錄壓縮 ETCD 會存儲多版本數(shù)據(jù),隨著寫入的主鍵增加,歷史版本將會越來越多,并且 ETCD 默認(rèn)不會自動清理歷史數(shù)據(jù)。數(shù)據(jù)達(dá)到 --quota-backend-bytes 設(shè)置的配額值時就無法寫入數(shù)據(jù),必須要壓縮并清理歷史數(shù)據(jù)才能繼續(xù)寫入。
--auto-compaction-mode
--auto-compaction-retention
所以,為了避免配額空間耗盡的問題,在創(chuàng)建集群時候建議默認(rèn)開啟歷史版本清理 功能。
3.3.0 之前的版本,只能按周期 periodic 來壓縮。比如設(shè)置 --auto-compaction-retention=72h,那么就會每 72 小時進(jìn)行一次數(shù)據(jù)壓縮。
3.3.0 之后的版本,可以通過 --auto-compaction-mode 設(shè)置壓縮模式,可以選擇 revision 或者 periodic 來壓縮數(shù)據(jù),默認(rèn)為 periodic。
etcd 備份
所有 Kubernetes 對象都存儲在 etcd 上。定期備份 etcd 集群數(shù)據(jù)對于在災(zāi)難場景(例如丟失所有主節(jié)點(diǎn))下恢復(fù) Kubernetes 集群非常重要。快照文件包含所有 Kubernetes 狀態(tài)和關(guān)鍵信息。為了保證敏感的 Kubernetes 數(shù)據(jù)的安全,可以對快照文件進(jìn)行加密。備份 etcd 集群可以通過兩種方式完成: etcd 內(nèi)置快照和卷快照。
內(nèi)置快照
etcd 支持內(nèi)置快照,因此備份 etcd 集群很容易。快照可以從使用 etcdctl snapshot save 命令的活動成員中獲取,也可以通過從 etcd 數(shù)據(jù)目錄復(fù)制 member/snap/db 文件,該 etcd 數(shù)據(jù)目錄目前沒有被 etcd 進(jìn)程使用。獲取快照通常不會影響成員的性能。
下面是一個示例,用于獲取 $ENDPOINT 所提供的鍵空間的快照到文件 snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
# exit 0
# verify the snapshot
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
卷快照
如果 etcd 運(yùn)行在支持備份的存儲卷(如 Amazon Elastic Block 存儲)上,則可以通過獲取存儲卷的快照來備份 etcd 數(shù)據(jù)。
etcd 恢復(fù)
etcd 支持從 major.minor 或其他不同 patch 版本的 etcd 進(jìn)程中獲取的快照進(jìn)行恢復(fù)。還原操作用于恢復(fù)失敗的集群的數(shù)據(jù)。
在啟動還原操作之前,必須有一個快照文件。它可以是來自以前備份操作的快照文件,也可以是來自剩余數(shù)據(jù)目錄的快照文件。有關(guān)從快照文件還原集群的詳細(xì)信息和示例,請參閱 etcd 災(zāi)難恢復(fù)文檔。
如果還原的集群的訪問 URL 與前一個集群不同,則必須相應(yīng)地重新配置 Kubernetes API 服務(wù)器。在本例中,使用參數(shù) --etcd-servers=$NEW_ETCD_CLUSTER 而不是參數(shù)--etcd-servers=$OLD_ETCD_CLUSTER 重新啟動 Kubernetes API 服務(wù)器。用相應(yīng)的 IP 地址替換 $NEW_ETCD_CLUSTER 和 $OLD_ETCD_CLUSTER。如果在 etcd 集群前面使用負(fù)載平衡,則可能需要更新負(fù)載均衡器。
如果大多數(shù) etcd 成員永久失敗,則認(rèn)為 etcd 集群失敗。在這種情況下,Kubernetes 不能對其當(dāng)前狀態(tài)進(jìn)行任何更改。雖然已調(diào)度的 pod 可能繼續(xù)運(yùn)行,但新的 pod 無法調(diào)度。在這種情況下,恢復(fù) etcd 集群并可能需要重新配置 Kubernetes API 服務(wù)器以修復(fù)問題。
注意:
如果集群中正在運(yùn)行任何 API 服務(wù)器,則不應(yīng)嘗試還原 etcd 的實(shí)例。相反,請按照以下步驟還原 etcd:
停止 所有 kube-apiserver 實(shí)例 在所有 etcd 實(shí)例中恢復(fù)狀態(tài) 重啟所有 kube-apiserver 實(shí)例
我們還建議重啟所有組件(例如 kube-scheduler、kube-controller-manager、kubelet),以確保它們不會 依賴一些過時的數(shù)據(jù)。請注意,實(shí)際中還原會花費(fèi)一些時間。在還原過程中,關(guān)鍵組件將丟失領(lǐng)導(dǎo)鎖并自行重啟。
總結(jié)
etcd 為 kubernetes 的存儲基石,想用好 k8s,必須熟悉 etcd,我們才更有信心,以及更好的服務(wù)業(yè)務(wù),提供更穩(wěn)定的技術(shù)服務(wù)。
參考文檔
https://etcd.io/docs/ https://kubernetes.io/zh/docs/tasks/administer-cluster/configure-upgrade-etcd/