
Flink入門 01.概述
1 實(shí)時(shí)即未來

如今的我們正生活在新一次的信息革命浪潮中,5G、物聯(lián)網(wǎng)、智慧城市、工業(yè)4.0、新基建……等新名詞層出不窮,唯一不變的就是變化!對(duì)于我們所學(xué)習(xí)的大數(shù)據(jù)來說更是這樣:數(shù)據(jù)產(chǎn)生的越來越快、數(shù)據(jù)量越來越大,數(shù)據(jù)的來源越來越千變?nèi)f化,數(shù)據(jù)中隱藏的價(jià)值規(guī)律更是越來越被重視!數(shù)字化時(shí)代的未來正在被我們創(chuàng)造!
歷史的發(fā)展從來不會(huì)一帆風(fēng)順,隨著大數(shù)據(jù)時(shí)代的發(fā)展,海量數(shù)據(jù)和多種業(yè)務(wù)的實(shí)時(shí)處理需求激增,比如:實(shí)時(shí)監(jiān)控報(bào)警系統(tǒng)、實(shí)時(shí)風(fēng)控系統(tǒng)、實(shí)時(shí)推薦系統(tǒng)等,傳統(tǒng)的批處理方式和早期的流式處理框架因其自身的局限性,難以在延遲性、吞吐量、容錯(cuò)能力,以及使用便捷性等方面滿足業(yè)務(wù)日益苛刻的要求。在這種形勢(shì)下,F(xiàn)link 以其獨(dú)特的天然流式計(jì)算特性和更為先進(jìn)的架構(gòu)設(shè)計(jì),極大地改善了以前的流式處理框架所存在的問題。
擴(kuò)展閱讀:為什么說流處理即未來?
https://news.qudong.com/article/562521.shtml

2 一切從Apache開始

Flink 誕生于歐洲的一個(gè)大數(shù)據(jù)研究項(xiàng)目 StratoSphere。該項(xiàng)目是柏林工業(yè)大學(xué)的一個(gè)研究性項(xiàng)目。早期, Flink 是做 Batch 計(jì)算的,但是在 2014 年, StratoSphere 里面的核心成員孵化出 Flink,同年將 Flink 捐贈(zèng) Apache,并在后來成為 Apache 的頂級(jí)大數(shù)據(jù)項(xiàng)目,同時(shí) Flink 計(jì)算的主流方向被定位為 Streaming, 即用流式計(jì)算來做所有大數(shù)據(jù)的計(jì)算,這就是 Flink 技術(shù)誕生的背景。
2014 年 Flink 作為主攻流計(jì)算的大數(shù)據(jù)引擎開始在開源大數(shù)據(jù)行業(yè)內(nèi)嶄露頭角。區(qū)別于 Storm、Spark Streaming 以及其他流式計(jì)算引擎的是:它不僅是一個(gè)高吞吐、低延遲的計(jì)算引擎,同時(shí)還提供很多高級(jí)的功能。比如它提供了有狀態(tài)的計(jì)算,支持狀態(tài)管理,支持強(qiáng)一致性的數(shù)據(jù)語義以及支持 基于Event Time的WaterMark對(duì)延遲或亂序的數(shù)據(jù)進(jìn)行處理等
3 富二代Flink

https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/86117374
隨著人工智能時(shí)代的降臨,數(shù)據(jù)量的爆發(fā),在典型的大數(shù)據(jù)的業(yè)務(wù)場景下數(shù)據(jù)業(yè)務(wù)最通用的做法是:
選用批處理的技術(shù)處理全量數(shù)據(jù),采用流式計(jì)算處理實(shí)時(shí)增量數(shù)據(jù)。在絕大多數(shù)的業(yè)務(wù)場景之下,用戶的業(yè)務(wù)邏輯在批處理和流處理之中往往是相同的。但是,用戶用于批處理和流處理的兩套計(jì)算引擎是不同的。因此,用戶通常需要寫兩套代碼。毫無疑問,這帶來了一些額外的負(fù)擔(dān)和成本。阿里巴巴的商品數(shù)據(jù)處理就經(jīng)常需要面對(duì)增量和全量兩套不同的業(yè)務(wù)流程問題,所以阿里就在想,我們能不能有一套統(tǒng)一的大數(shù)據(jù)引擎技術(shù),用戶只需要根據(jù)自己的業(yè)務(wù)邏輯開發(fā)一套代碼。這樣在各種不同的場景下,不管是全量數(shù)據(jù)還是增量數(shù)據(jù),亦或者實(shí)時(shí)處理,一套方案即可全部支持,這就是阿里選擇 Flink 的背景和初衷。
2015 年阿里巴巴開始使用 Flink 并持續(xù)貢獻(xiàn)社區(qū)(阿里內(nèi)部還基于Flink做了一套Blink),2019年1月8日,阿里巴巴以 9000 萬歐元(7億元人民幣)收購了創(chuàng)業(yè)公司 Data Artisans。從此Flink開始了新一輪的乘風(fēng)破浪!

4 Flink官方介紹
官網(wǎng)地址: https://flink.apache.org/
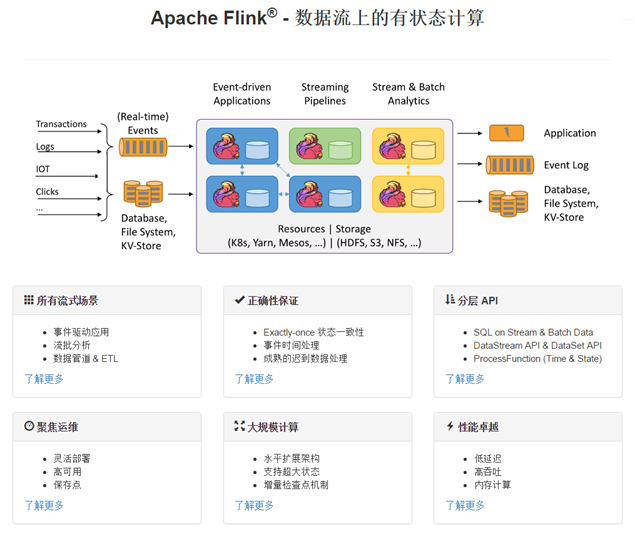
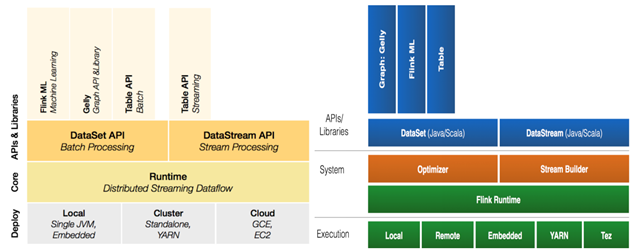
5 Flink組件棧
一個(gè)計(jì)算框架要有長遠(yuǎn)的發(fā)展,必須打造一個(gè)完整的 Stack。只有上層有了具體的應(yīng)用,并能很好的發(fā)揮計(jì)算框架本身的優(yōu)勢(shì),那么這個(gè)計(jì)算框架才能吸引更多的資源,才會(huì)更快的進(jìn)步。所以 Flink 也在努力構(gòu)建自己的 Stack。
Flink分層的組件棧如下圖所示:每一層所包含的組件都提供了特定的抽象,用來服務(wù)于上層組件。
各層詳細(xì)介紹:
物理部署層:Flink 支持本地運(yùn)行、能在獨(dú)立集群或者在被 YARN 管理的集群上運(yùn)行, 也能部署在云上,該層主要涉及Flink的部署模式,目前Flink支持多種部署模式:本地、集群(Standalone、YARN)、云(GCE/EC2)、Kubenetes。Flink能夠通過該層能夠支持不同平臺(tái)的部署,用戶可以根據(jù)需要選擇使用對(duì)應(yīng)的部署模式。
Runtime核心層:Runtime層提供了支持Flink計(jì)算的全部核心實(shí)現(xiàn),為上層API層提供基礎(chǔ)服務(wù),該層主要負(fù)責(zé)對(duì)上層不同接口提供基礎(chǔ)服務(wù),也是Flink分布式計(jì)算框架的核心實(shí)現(xiàn)層,支持分布式Stream作業(yè)的執(zhí)行、JobGraph到ExecutionGraph的映射轉(zhuǎn)換、任務(wù)調(diào)度等。將DataSteam和DataSet轉(zhuǎn)成統(tǒng)一的可執(zhí)行的Task Operator,達(dá)到在流式引擎下同時(shí)處理批量計(jì)算和流式計(jì)算的目的。
API&Libraries層:Flink 首先支持了 Scala 和 Java 的 API,Python 也正在測試中。DataStream、DataSet、Table、SQL API,作為分布式數(shù)據(jù)處理框架,F(xiàn)link同時(shí)提供了流式計(jì)算和批計(jì)算的接口,兩者都提供給用戶豐富的數(shù)據(jù)處理高級(jí)API,例如Map、FlatMap操作等,也提供比較低級(jí)的Process Function API,用戶可以直接操作狀態(tài)和時(shí)間等底層數(shù)據(jù)。
擴(kuò)展庫:Flink 還包括用于復(fù)雜事件處理的CEP,機(jī)器學(xué)習(xí)庫FlinkML,圖處理庫Gelly等。Table 是一種接口化的 SQL 支持,也就是 API 支持(DSL),而不是文本化的SQL 解析和執(zhí)行。
6 Flink基石
Flink之所以能這么流行,離不開它最重要的四個(gè)基石:Checkpoint、State、Time、Window。

Checkpoint
這是Flink最重要的一個(gè)特性。
Flink基于Chandy-Lamport算法實(shí)現(xiàn)了一個(gè)分布式的一致性的快照,從而提供了一致性的語義。
Chandy-Lamport算法實(shí)際上在1985年的時(shí)候已經(jīng)被提出來,但并沒有被很廣泛的應(yīng)用,而Flink則把這個(gè)算法發(fā)揚(yáng)光大了。
Spark最近在實(shí)現(xiàn)Continue streaming,Continue streaming的目的是為了降低處理的延時(shí),其也需要提供這種一致性的語義,最終也采用了Chandy-Lamport這個(gè)算法,說明Chandy-Lamport算法在業(yè)界得到了一定的肯定。
https://zhuanlan.zhihu.com/p/53482103
State
提供了一致性的語義之后,F(xiàn)link為了讓用戶在編程時(shí)能夠更輕松、更容易地去管理狀態(tài),還提供了一套非常簡單明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能夠自動(dòng)享受到這種一致性的語義。
Time
除此之外,F(xiàn)link還實(shí)現(xiàn)了Watermark的機(jī)制,能夠支持基于事件的時(shí)間的處理,能夠容忍遲到/亂序的數(shù)據(jù)。
Window
另外流計(jì)算中一般在對(duì)流數(shù)據(jù)進(jìn)行操作之前都會(huì)先進(jìn)行開窗,即基于一個(gè)什么樣的窗口上做這個(gè)計(jì)算。Flink提供了開箱即用的各種窗口,比如滑動(dòng)窗口、滾動(dòng)窗口、會(huì)話窗口以及非常靈活的自定義的窗口。
7 Flink用武之地
http://www.liaojiayi.com/flink-IoT/
https://flink.apache.org/zh/usecases.html
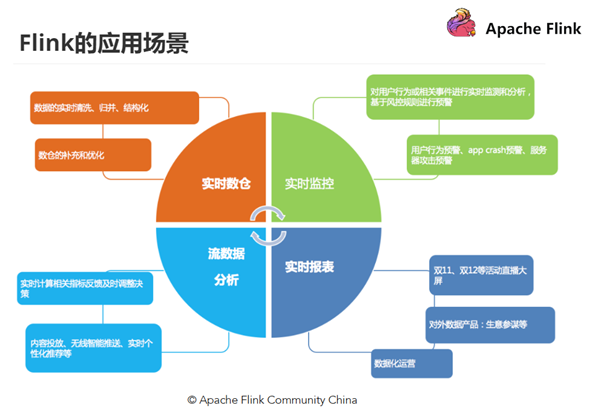
從很多公司的應(yīng)用案例發(fā)現(xiàn),其實(shí)Flink主要用在如下三大場景:
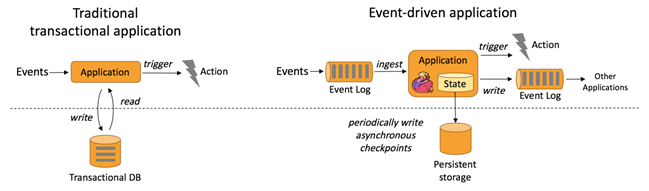
7.1 Event-driven Applications【事件驅(qū)動(dòng)】
事件驅(qū)動(dòng)型應(yīng)用是一類具有狀態(tài)的應(yīng)用,它從一個(gè)或多個(gè)事件流提取數(shù)據(jù),并根據(jù)到來的事件觸發(fā)計(jì)算、狀態(tài)更新或其他外部動(dòng)作。
事件驅(qū)動(dòng)型應(yīng)用是在計(jì)算存儲(chǔ)分離的傳統(tǒng)應(yīng)用基礎(chǔ)上進(jìn)化而來。
在傳統(tǒng)架構(gòu)中,應(yīng)用需要讀寫遠(yuǎn)程事務(wù)型數(shù)據(jù)庫。
相反,事件驅(qū)動(dòng)型應(yīng)用是基于狀態(tài)化流處理來完成。在該設(shè)計(jì)中,數(shù)據(jù)和計(jì)算不會(huì)分離,應(yīng)用只需訪問本地(內(nèi)存或磁盤)即可獲取數(shù)據(jù)。
系統(tǒng)容錯(cuò)性的實(shí)現(xiàn)依賴于定期向遠(yuǎn)程持久化存儲(chǔ)寫入 checkpoint。下圖描述了傳統(tǒng)應(yīng)用和事件驅(qū)動(dòng)型應(yīng)用架構(gòu)的區(qū)別。
從某種程度上來說,所有的實(shí)時(shí)的數(shù)據(jù)處理或者是流式數(shù)據(jù)處理都應(yīng)該是屬于Data Driven,流計(jì)算本質(zhì)上是Data Driven 計(jì)算。應(yīng)用較多的如風(fēng)控系統(tǒng),當(dāng)風(fēng)控系統(tǒng)需要處理各種各樣復(fù)雜的規(guī)則時(shí),Data Driven 就會(huì)把處理的規(guī)則和邏輯寫入到Datastream 的API 或者是ProcessFunction 的API 中,然后將邏輯抽象到整個(gè)Flink 引擎,當(dāng)外面的數(shù)據(jù)流或者是事件進(jìn)入就會(huì)觸發(fā)相應(yīng)的規(guī)則,這就是Data Driven 的原理。在觸發(fā)某些規(guī)則后,Data Driven 會(huì)進(jìn)行處理或者是進(jìn)行預(yù)警,這些預(yù)警會(huì)發(fā)到下游產(chǎn)生業(yè)務(wù)通知,這是Data Driven 的應(yīng)用場景,Data Driven 在應(yīng)用上更多應(yīng)用于復(fù)雜事件的處理。
典型實(shí)例:
欺詐檢測(Fraud detection)
異常檢測(Anomaly detection)
基于規(guī)則的告警(Rule-based alerting)
業(yè)務(wù)流程監(jiān)控(Business process monitoring)
Web應(yīng)用程序(社交網(wǎng)絡(luò))
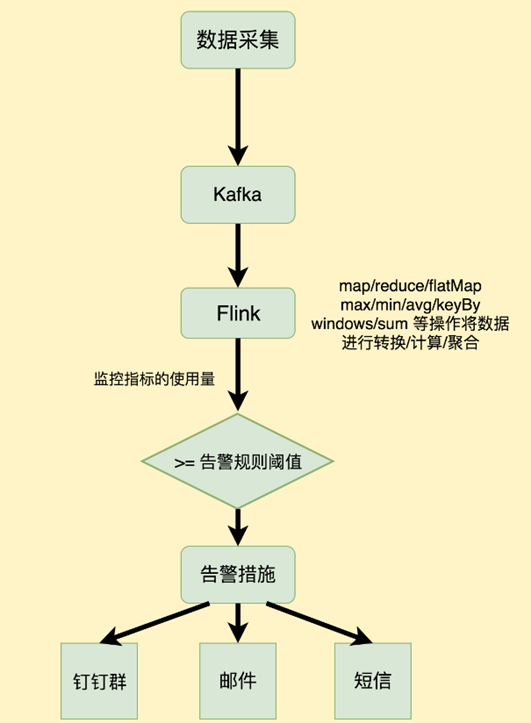
7.2 Data Analytics Applications【數(shù)據(jù)分析】
數(shù)據(jù)分析任務(wù)需要從原始數(shù)據(jù)中提取有價(jià)值的信息和指標(biāo)。
如下圖所示,Apache Flink 同時(shí)支持流式及批量分析應(yīng)用。
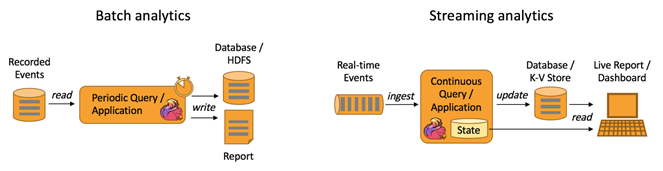
Data Analytics Applications包含Batch analytics(批處理分析)和Streaming analytics(流處理分析)。
Batch analytics可以理解為周期性查詢:Batch Analytics 就是傳統(tǒng)意義上使用類似于Map Reduce、Hive、Spark Batch 等,對(duì)作業(yè)進(jìn)行分析、處理、生成離線報(bào)表。比如Flink應(yīng)用凌晨從Recorded Events中讀取昨天的數(shù)據(jù),然后做周期查詢運(yùn)算,最后將數(shù)據(jù)寫入Database或者HDFS,或者直接將數(shù)據(jù)生成報(bào)表供公司上層領(lǐng)導(dǎo)決策使用。
Streaming analytics可以理解為連續(xù)性查詢:比如實(shí)時(shí)展示雙十一天貓銷售GMV(Gross Merchandise Volume成交總額),用戶下單數(shù)據(jù)需要實(shí)時(shí)寫入消息隊(duì)列,F(xiàn)link 應(yīng)用源源不斷讀取數(shù)據(jù)做實(shí)時(shí)計(jì)算,然后不斷的將數(shù)據(jù)更新至Database或者K-VStore,最后做大屏實(shí)時(shí)展示。
典型實(shí)例:
電信網(wǎng)絡(luò)質(zhì)量監(jiān)控
移動(dòng)應(yīng)用中的產(chǎn)品更新及實(shí)驗(yàn)評(píng)估分析
消費(fèi)者技術(shù)中的實(shí)時(shí)數(shù)據(jù)即席分析
大規(guī)模圖分析
7.3 Data Pipeline Applications【數(shù)據(jù)管道】
什么是數(shù)據(jù)管道?
提取-轉(zhuǎn)換-加載(ETL)是一種在存儲(chǔ)系統(tǒng)之間進(jìn)行數(shù)據(jù)轉(zhuǎn)換和遷移的常用方法。
ETL 作業(yè)通常會(huì)周期性地觸發(fā),將數(shù)據(jù)從事務(wù)型數(shù)據(jù)庫拷貝到分析型數(shù)據(jù)庫或數(shù)據(jù)倉庫。
數(shù)據(jù)管道和 ETL 作業(yè)的用途相似,都可以轉(zhuǎn)換、豐富數(shù)據(jù),并將其從某個(gè)存儲(chǔ)系統(tǒng)移動(dòng)到另一個(gè)。
但數(shù)據(jù)管道是以持續(xù)流模式運(yùn)行,而非周期性觸發(fā)。
因此數(shù)據(jù)管道支持從一個(gè)不斷生成數(shù)據(jù)的源頭讀取記錄,并將它們以低延遲移動(dòng)到終點(diǎn)。
例如:數(shù)據(jù)管道可以用來監(jiān)控文件系統(tǒng)目錄中的新文件,并將其數(shù)據(jù)寫入事件日志;另一個(gè)應(yīng)用可能會(huì)將事件流物化到數(shù)據(jù)庫或增量構(gòu)建和優(yōu)化查詢索引。
和周期性 ETL 作業(yè)相比,持續(xù)數(shù)據(jù)管道可以明顯降低將數(shù)據(jù)移動(dòng)到目的端的延遲。
此外,由于它能夠持續(xù)消費(fèi)和發(fā)送數(shù)據(jù),因此用途更廣,支持用例更多。
下圖描述了周期性ETL作業(yè)和持續(xù)數(shù)據(jù)管道的差異。
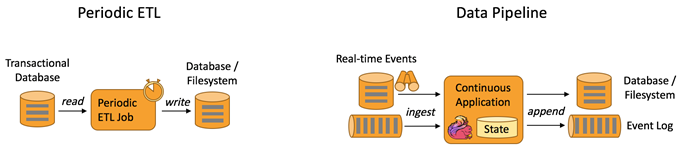
Periodic ETL:比如每天凌晨周期性的啟動(dòng)一個(gè)Flink ETL Job,讀取傳統(tǒng)數(shù)據(jù)庫中的數(shù)據(jù),然后做ETL,最后寫入數(shù)據(jù)庫和文件系統(tǒng)。
Data Pipeline:比如啟動(dòng)一個(gè)Flink 實(shí)時(shí)應(yīng)用,數(shù)據(jù)源(比如數(shù)據(jù)庫、Kafka)中的數(shù)據(jù)不斷的通過Flink Data Pipeline流入或者追加到數(shù)據(jù)倉庫(數(shù)據(jù)庫或者文件系統(tǒng)),或者Kafka消息隊(duì)列。
Data Pipeline 的核心場景類似于數(shù)據(jù)搬運(yùn)并在搬運(yùn)的過程中進(jìn)行部分?jǐn)?shù)據(jù)清洗或者處理,而整個(gè)業(yè)務(wù)架構(gòu)圖的左邊是Periodic ETL,它提供了流式ETL 或者實(shí)時(shí)ETL,能夠訂閱消息隊(duì)列的消息并進(jìn)行處理,清洗完成后實(shí)時(shí)寫入到下游的Database或File system 中。
典型實(shí)例:
電子商務(wù)中的持續(xù) ETL(實(shí)時(shí)數(shù)倉)
當(dāng)下游要構(gòu)建實(shí)時(shí)數(shù)倉時(shí),上游則可能需要實(shí)時(shí)的Stream ETL。這個(gè)過程會(huì)進(jìn)行實(shí)時(shí)清洗或擴(kuò)展數(shù)據(jù),清洗完成后寫入到下游的實(shí)時(shí)數(shù)倉的整個(gè)鏈路中,可保證數(shù)據(jù)查詢的時(shí)效性,形成實(shí)時(shí)數(shù)據(jù)采集、實(shí)時(shí)數(shù)據(jù)處理以及下游的實(shí)時(shí)Query。
電子商務(wù)中的實(shí)時(shí)查詢索引構(gòu)建(搜索引擎推薦)
搜索引擎這塊以淘寶為例,當(dāng)賣家上線新商品時(shí),后臺(tái)會(huì)實(shí)時(shí)產(chǎn)生消息流,該消息流經(jīng)過Flink 系統(tǒng)時(shí)會(huì)進(jìn)行數(shù)據(jù)的處理、擴(kuò)展。然后將處理及擴(kuò)展后的數(shù)據(jù)生成實(shí)時(shí)索引,寫入到搜索引擎中。這樣當(dāng)淘寶賣家上線新商品時(shí),能在秒級(jí)或者分鐘級(jí)實(shí)現(xiàn)搜索引擎的搜索。
8 擴(kuò)展閱讀:Flink發(fā)展現(xiàn)狀
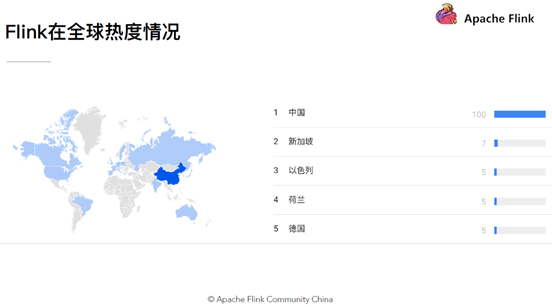
8.1 Flink在全球
Flink近年來逐步被人們所熟知,不僅是因?yàn)镕link提供同時(shí)支持高吞吐/低延遲和Exactly-Once語義的實(shí)時(shí)計(jì)算能力,同時(shí)Flink還提供了基于流式計(jì)算引擎處理批量數(shù)據(jù)的計(jì)算能力,真正意義上實(shí)現(xiàn)批流統(tǒng)一
同時(shí)隨著阿里對(duì)Blink的開源,極大地增強(qiáng)了Flink對(duì)批計(jì)算領(lǐng)域的支持.眾多優(yōu)秀的特性,使得Flink成為開源大數(shù)據(jù)處理框架中的一顆新星,隨著國內(nèi)社區(qū)的不斷推動(dòng),越來越多的公司開始選擇使用Flink作為實(shí)時(shí)數(shù)據(jù)處理技術(shù),在不久的將來,Flink也將會(huì)成為企業(yè)內(nèi)部主流的數(shù)據(jù)處理框架,最終成為下一代大數(shù)據(jù)處理的標(biāo)準(zhǔn).
8.2 Flink在中國
Flink在很多公司的生產(chǎn)環(huán)境中得到了使用, 例如: ebay, 騰訊, 阿里, 亞馬遜, 華為等

8.3 Flink在阿里
阿里自15年起開始調(diào)研開源流計(jì)算引擎,最終決定基于Flink打造新一代計(jì)算引擎,阿里貢獻(xiàn)了數(shù)百個(gè)commiter,并對(duì)Flink進(jìn)行高度定制,并取名為Blink,
阿里是Flink SQL的最大貢獻(xiàn)者,一半以上的功能都是阿里的工程師開發(fā)的,基于Apache Flink在阿里巴巴搭建的平臺(tái)于2016年正式上線,并從阿里巴巴的搜索和推薦這兩大場景開始實(shí)現(xiàn)。
2019年Flink的母公司被阿里7億元全資收購,阿里一直致力于Flink在國內(nèi)的推廣使用,目前阿里巴巴所有的業(yè)務(wù),包括阿里巴巴所有子公司都采用了基于Flink搭建的實(shí)時(shí)計(jì)算平臺(tái)。
同時(shí)Flink計(jì)算平臺(tái)運(yùn)行在開源的Hadoop集群之上,采用Hadoop的YARN做為資源管理調(diào)度,以 HDFS作為數(shù)據(jù)存儲(chǔ)。因此,F(xiàn)link可以和開源大數(shù)據(jù)軟件Hadoop無縫對(duì)接。
目前,這套基于Flink搭建的實(shí)時(shí)計(jì)算平臺(tái)不僅服務(wù)于阿里巴巴集團(tuán)內(nèi)部,而且通過阿里云的云產(chǎn)品API向整個(gè)開發(fā)者生態(tài)提供基于Flink的云產(chǎn)品支持。
主要包含四個(gè)模塊:實(shí)時(shí)監(jiān)控、實(shí)時(shí)報(bào)表、流數(shù)據(jù)分析和實(shí)時(shí)倉庫。
實(shí)時(shí)監(jiān)控:
用戶行為預(yù)警、app crash 預(yù)警、服務(wù)器攻擊預(yù)警 對(duì)用戶行為或者相關(guān)事件進(jìn)行實(shí)時(shí)監(jiān)測和分析,基于風(fēng)控規(guī)則進(jìn)行預(yù)警、復(fù)雜事件處理 實(shí)時(shí)報(bào)表:
雙11、雙12等活動(dòng)直播大屏 對(duì)外數(shù)據(jù)產(chǎn)品:生意參謀等 數(shù)據(jù)化運(yùn)營 流數(shù)據(jù)分析:
實(shí)時(shí)計(jì)算相關(guān)指標(biāo)反饋及時(shí)調(diào)整決策 內(nèi)容投放、無線智能推送、實(shí)時(shí)個(gè)性化推薦等 實(shí)時(shí)倉庫/ETL:
數(shù)據(jù)實(shí)時(shí)清洗、歸并、結(jié)構(gòu)化 數(shù)倉的補(bǔ)充和優(yōu)化
Flink在阿里巴巴的大規(guī)模應(yīng)用表現(xiàn)如何?
規(guī)模:一個(gè)系統(tǒng)是否成熟,規(guī)模是重要指標(biāo),F(xiàn)link最初上線阿里巴巴只有數(shù)百臺(tái)服務(wù)器,目前規(guī)模已達(dá)上萬臺(tái),此等規(guī)模在全球范圍內(nèi)也是屈指可數(shù);
狀態(tài)數(shù)據(jù):基于Flink,內(nèi)部積累起來的狀態(tài)數(shù)據(jù)已經(jīng)是PB級(jí)別規(guī)模;
Events:如今每天在Flink的計(jì)算平臺(tái)上,處理的數(shù)據(jù)已經(jīng)超過十萬億條;
TPS:在峰值期間可以承擔(dān)每秒超過17億次的訪問,最典型的應(yīng)用場景是阿里巴巴雙11大屏;

8.4 Flink在騰訊
https://blog.csdn.net/qianshangding0708/article/details/91469978


8.5 Flink在美團(tuán)
http://ju.outofmemory.cn/entry/367345
https://tech.meituan.com/2018/10/18/meishi-data-flink.html

9 擴(kuò)展閱讀:為什么選擇Flink?

主要原因
Flink 具備統(tǒng)一的框架處理有界和無界兩種數(shù)據(jù)流的能力
部署靈活,F(xiàn)link 底層支持多種資源調(diào)度器,包括Yarn、Kubernetes 等。Flink 自身帶的Standalone 的調(diào)度器,在部署上也十分靈活。
極高的可伸縮性,可伸縮性對(duì)于分布式系統(tǒng)十分重要,阿里巴巴雙11大屏采用Flink 處理海量數(shù)據(jù),使用過程中測得Flink 峰值可達(dá)17 億條/秒。
極致的流式處理性能。Flink 相對(duì)于Storm 最大的特點(diǎn)是將狀態(tài)語義完全抽象到框架中,支持本地狀態(tài)讀取,避免了大量網(wǎng)絡(luò)IO,可以極大提升狀態(tài)存取的性能。
其他更多的原因:
同時(shí)支持高吞吐、低延遲、高性能
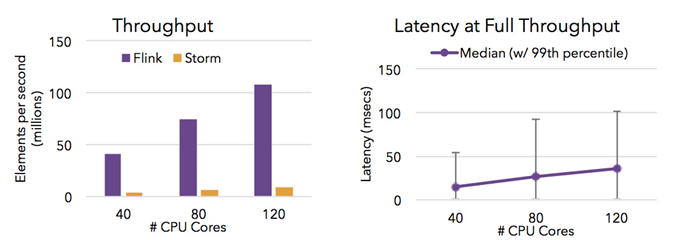
Flink 是目前開源社區(qū)中唯一一套集高吞吐、低延遲、高性能三者于一身的分布式流式數(shù)據(jù)處理框架。Spark 只能兼顧高吞吐和高性能特性,無法做到低延遲保障,因?yàn)镾park是用批處理來做流處理
Storm 只能支持低延時(shí)和高性能特性,無法滿足高吞吐的要求
下圖顯示了 Apache Flink 與 Apache Storm 在完成流數(shù)據(jù)清洗的分布式任務(wù)的性能對(duì)比。
支持事件時(shí)間(Event Time)概念
在流式計(jì)算領(lǐng)域中,窗口計(jì)算的地位舉足輕重,但目前大多數(shù)框架窗口計(jì)算采用的都是系統(tǒng)時(shí)間(Process Time),也就是事件傳輸?shù)接?jì)算框架處理時(shí),系統(tǒng)主機(jī)的當(dāng)前時(shí)間。
Flink 能夠支持基于事件時(shí)間(Event Time)語義進(jìn)行窗口計(jì)算
這種基于事件驅(qū)動(dòng)的機(jī)制使得事件即使亂序到達(dá)甚至延遲到達(dá),流系統(tǒng)也能夠計(jì)算出精確的結(jié)果,保持了事件原本產(chǎn)生時(shí)的時(shí)序性,盡可能避免網(wǎng)絡(luò)傳輸或硬件系統(tǒng)的影響。

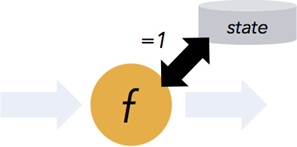
支持有狀態(tài)計(jì)算
Flink1.4開始支持有狀態(tài)計(jì)算
所謂狀態(tài)就是在流式計(jì)算過程中將算子的中間結(jié)果保存在內(nèi)存或者文件系統(tǒng)中,等下一個(gè)事件進(jìn)入算子后可以從之前的狀態(tài)中獲取中間結(jié)果,計(jì)算當(dāng)前的結(jié)果,從而無須每次都基于全部的原始數(shù)據(jù)來統(tǒng)計(jì)結(jié)果,極大的提升了系統(tǒng)性能,狀態(tài)化意味著應(yīng)用可以維護(hù)隨著時(shí)間推移已經(jīng)產(chǎn)生的數(shù)據(jù)聚合
支持高度靈活的窗口(Window)操作
Flink 將窗口劃分為基于 Time 、Count 、Session、以及Data-Driven等類型的窗口操作,窗口可以用靈活的觸發(fā)條件定制化來達(dá)到對(duì)復(fù)雜的流傳輸模式的支持,用戶可以定義不同的窗口觸發(fā)機(jī)制來滿足不同的需求
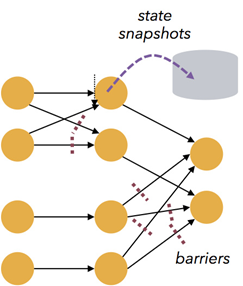
基于輕量級(jí)分布式快照(Snapshot/Checkpoints)的容錯(cuò)機(jī)制
Flink 能夠分布運(yùn)行在上千個(gè)節(jié)點(diǎn)上,通過基于分布式快照技術(shù)的Checkpoints,將執(zhí)行過程中的狀態(tài)信息進(jìn)行持久化存儲(chǔ),一旦任務(wù)出現(xiàn)異常停止,F(xiàn)link 能夠從 Checkpoints 中進(jìn)行任務(wù)的自動(dòng)恢復(fù),以確保數(shù)據(jù)處理過程中的一致性
Flink 的容錯(cuò)能力是輕量級(jí)的,允許系統(tǒng)保持高并發(fā),同時(shí)在相同時(shí)間內(nèi)提供強(qiáng)一致性保證。
基于 JVM 實(shí)現(xiàn)的獨(dú)立的內(nèi)存管理
Flink 實(shí)現(xiàn)了自身管理內(nèi)存的機(jī)制,通過使用散列,索引,緩存和排序有效地進(jìn)行內(nèi)存管理,通過序列化/反序列化機(jī)制將所有的數(shù)據(jù)對(duì)象轉(zhuǎn)換成二進(jìn)制在內(nèi)存中存儲(chǔ),降低數(shù)據(jù)存儲(chǔ)大小的同時(shí),更加有效的利用空間。使其獨(dú)立于 Java 的默認(rèn)垃圾收集器,盡可能減少 JVM GC 對(duì)系統(tǒng)的影響。
SavePoints 保存點(diǎn)
對(duì)于 7 * 24 小時(shí)運(yùn)行的流式應(yīng)用,數(shù)據(jù)源源不斷的流入,在一段時(shí)間內(nèi)應(yīng)用的終止有可能導(dǎo)致數(shù)據(jù)的丟失或者計(jì)算結(jié)果的不準(zhǔn)確。比如集群版本的升級(jí),停機(jī)運(yùn)維操作等。
值得一提的是,F(xiàn)link 通過SavePoints 技術(shù)將任務(wù)執(zhí)行的快照保存在存儲(chǔ)介質(zhì)上,當(dāng)任務(wù)重啟的時(shí)候,可以從事先保存的 SavePoints 恢復(fù)原有的計(jì)算狀態(tài),使得任務(wù)繼續(xù)按照停機(jī)之前的狀態(tài)運(yùn)行。
Flink 保存點(diǎn)提供了一個(gè)狀態(tài)化的版本機(jī)制,使得能以無丟失狀態(tài)和最短停機(jī)時(shí)間的方式更新應(yīng)用或者回退歷史數(shù)據(jù)。
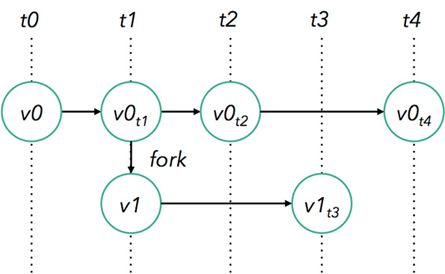
靈活的部署方式,支持大規(guī)模集群
Flink 被設(shè)計(jì)成能用上千個(gè)點(diǎn)在大規(guī)模集群上運(yùn)行。除了支持獨(dú)立集群部署外,F(xiàn)link 還支持 YARN 和Mesos 方式部署。
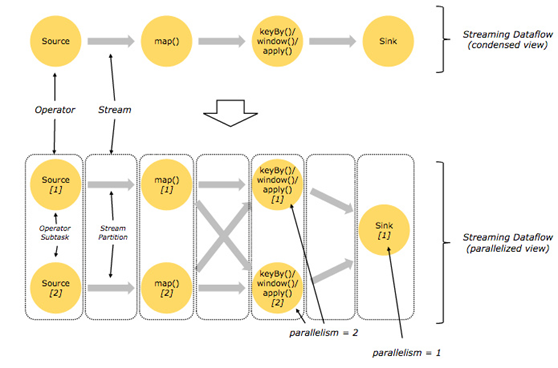
Flink 的程序內(nèi)在是并行和分布式的
數(shù)據(jù)流可以被分區(qū)成 stream partitions,operators 被劃分為operator subtasks; 這些 subtasks 在不同的機(jī)器或容器中分不同的線程獨(dú)立運(yùn)行;operator subtasks 的數(shù)量就是operator的并行計(jì)算數(shù),不同的 operator 階段可能有不同的并行數(shù);
如下圖所示,source operator 的并行數(shù)為 2,但最后的 sink operator 為1;
豐富的庫
Flink 擁有豐富的庫來進(jìn)行機(jī)器學(xué)習(xí),圖形處理,關(guān)系數(shù)據(jù)處理等。
10 擴(kuò)展閱讀:大數(shù)據(jù)框架發(fā)展史

這幾年大數(shù)據(jù)的飛速發(fā)展,出現(xiàn)了很多熱門的開源社區(qū),其中著名的有 Hadoop、Storm,以及后來的 Spark,他們都有著各自專注的應(yīng)用場景。Spark 掀開了內(nèi)存計(jì)算的先河,也以內(nèi)存為賭注,贏得了內(nèi)存計(jì)算的飛速發(fā)展。Spark 的火熱或多或少的掩蓋了其他分布式計(jì)算的系統(tǒng)身影。就像 Flink,也就在這個(gè)時(shí)候默默的發(fā)展著。
在國外一些社區(qū),有很多人將大數(shù)據(jù)的計(jì)算引擎分成了 4 代,當(dāng)然,也有很多人不會(huì)認(rèn)同。我們先姑且這么認(rèn)為和討論。
第1代——Hadoop MapReduce
首先第一代的計(jì)算引擎,無疑就是 Hadoop 承載的 MapReduce。它將計(jì)算分為兩個(gè)階段,分別為 Map 和 Reduce。對(duì)于上層應(yīng)用來說,就不得不想方設(shè)法去拆分算法,甚至于不得不在上層應(yīng)用實(shí)現(xiàn)多個(gè) Job 的串聯(lián),以完成一個(gè)完整的算法,例如迭代計(jì)算。
批處理
Mapper、Reducer
第2代——DAG框架(Tez) + MapReduce
由于這樣的弊端,催生了支持 DAG 框架的產(chǎn)生。因此,支持 DAG 的框架被劃分為第二代計(jì)算引擎。如 Tez 以及更上層的 Oozie。這里我們不去細(xì)究各種 DAG 實(shí)現(xiàn)之間的區(qū)別,不過對(duì)于當(dāng)時(shí)的 Tez 和 Oozie 來說,大多還是批處理的任務(wù)。
批處理
1個(gè)Tez = MR(1) + MR(2) + ... + MR(n)
相比MR效率有所提升
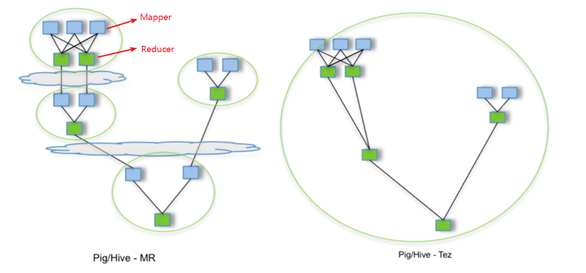
第3代——Spark
接下來就是以 Spark 為代表的第三代的計(jì)算引擎。第三代計(jì)算引擎的特點(diǎn)主要是 Job 內(nèi)部的 DAG 支持(不跨越 Job),以及強(qiáng)調(diào)的實(shí)時(shí)計(jì)算。在這里,很多人也會(huì)認(rèn)為第三代計(jì)算引擎也能夠很好的運(yùn)行批處理的 Job。
批處理、流處理、SQL高層API支持
自帶DAG
內(nèi)存迭代計(jì)算、性能較之前大幅提升
第4代——Flink
隨著第三代計(jì)算引擎的出現(xiàn),促進(jìn)了上層應(yīng)用快速發(fā)展,例如各種迭代計(jì)算的性能以及對(duì)流計(jì)算和 SQL 等的支持。Flink 的誕生就被歸在了第四代。這應(yīng)該主要表現(xiàn)在 Flink 對(duì)流計(jì)算的支持,以及更一步的實(shí)時(shí)性上面。當(dāng)然 Flink 也可以支持 Batch 的任務(wù),以及 DAG 的運(yùn)算。
批處理、流處理、SQL高層API支持
自帶DAG
流式計(jì)算性能更高、可靠性更高
11 擴(kuò)展閱讀:流處理 VS 批處理
數(shù)據(jù)的時(shí)效性
日常工作中,我們一般會(huì)先把數(shù)據(jù)存儲(chǔ)在表,然后對(duì)表的數(shù)據(jù)進(jìn)行加工、分析。既然先存儲(chǔ)在表中,那就會(huì)涉及到時(shí)效性概念。
如果我們處理以年,月為單位的級(jí)別的數(shù)據(jù)處理,進(jìn)行統(tǒng)計(jì)分析,個(gè)性化推薦,那么數(shù)據(jù)的的最新日期離當(dāng)前有幾個(gè)甚至上月都沒有問題。但是如果我們處理的是以天為級(jí)別,或者一小時(shí)甚至更小粒度的數(shù)據(jù)處理,那么就要求數(shù)據(jù)的時(shí)效性更高了。比如:
這些場景需要工作人員立即響應(yīng),這樣的場景下,傳統(tǒng)的統(tǒng)一收集數(shù)據(jù),再存到數(shù)據(jù)庫中,再取出來進(jìn)行分析就無法滿足高時(shí)效性的需求了。
對(duì)網(wǎng)站的實(shí)時(shí)監(jiān)控
對(duì)異常日志的監(jiān)控
流式計(jì)算和批量計(jì)算
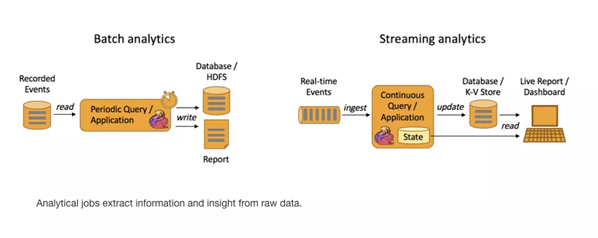
Batch Analytics,右邊是 Streaming Analytics。批量計(jì)算: 統(tǒng)一收集數(shù)據(jù)->存儲(chǔ)到DB->對(duì)數(shù)據(jù)進(jìn)行批量處理,就是傳統(tǒng)意義上使用類似于 Map Reduce、Hive、Spark Batch 等,對(duì)作業(yè)進(jìn)行分析、處理、生成離線報(bào)表
Streaming Analytics 流式計(jì)算,顧名思義,就是對(duì)數(shù)據(jù)流進(jìn)行處理,如使用流式分析引擎如 Storm,F(xiàn)link 實(shí)時(shí)處理分析數(shù)據(jù),應(yīng)用較多的場景如實(shí)時(shí)大屏、實(shí)時(shí)報(bào)表。
它們的主要區(qū)別是:
與批量計(jì)算那樣慢慢積累數(shù)據(jù)不同,流式計(jì)算立刻計(jì)算,數(shù)據(jù)持續(xù)流動(dòng),計(jì)算完之后就丟棄。
批量計(jì)算是維護(hù)一張表,對(duì)表進(jìn)行實(shí)施各種計(jì)算邏輯。流式計(jì)算相反,是必須先定義好計(jì)算邏輯,提交到流式計(jì)算系統(tǒng),這個(gè)計(jì)算作業(yè)邏輯在整個(gè)運(yùn)行期間是不可更改的。
計(jì)算結(jié)果上,批量計(jì)算對(duì)全部數(shù)據(jù)進(jìn)行計(jì)算后傳輸結(jié)果,流式計(jì)算是每次小批量計(jì)算后,結(jié)果可以立刻實(shí)時(shí)化展現(xiàn)。
12 擴(kuò)展閱讀:流批統(tǒng)一
在大數(shù)據(jù)處理領(lǐng)域,批處理任務(wù)與流處理任務(wù)一般被認(rèn)為是兩種不同的任務(wù),一個(gè)大數(shù)據(jù)框架一般會(huì)被設(shè)計(jì)為只能處理其中一種任務(wù):
MapReduce只支持批處理任務(wù);
Storm只支持流處理任務(wù);
Spark Streaming采用micro-batch架構(gòu),本質(zhì)上還是基于Spark批處理對(duì)流式數(shù)據(jù)進(jìn)行處理
Flink通過靈活的執(zhí)行引擎,能夠同時(shí)支持批處理任務(wù)與流處理任務(wù)
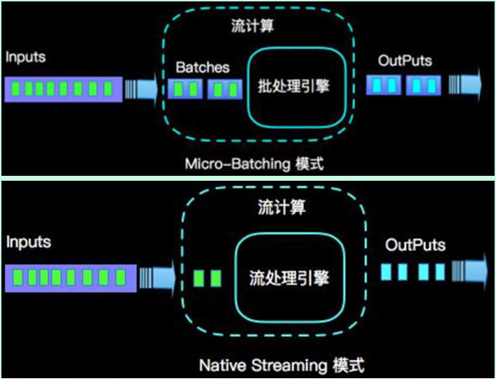
在執(zhí)行引擎這一層,流處理系統(tǒng)與批處理系統(tǒng)最大不同在于節(jié)點(diǎn)間的數(shù)據(jù)傳輸方式:
對(duì)于一個(gè)流處理系統(tǒng),其節(jié)點(diǎn)間數(shù)據(jù)傳輸?shù)臉?biāo)準(zhǔn)模型是:當(dāng)一條數(shù)據(jù)被處理完成后,序列化到緩存中,然后立刻通過網(wǎng)絡(luò)傳輸?shù)较乱粋€(gè)節(jié)點(diǎn),由下一個(gè)節(jié)點(diǎn)繼續(xù)處理
對(duì)于一個(gè)批處理系統(tǒng),其節(jié)點(diǎn)間數(shù)據(jù)傳輸?shù)臉?biāo)準(zhǔn)模型是:當(dāng)一條數(shù)據(jù)被處理完成后,序列化到緩存中,并不會(huì)立刻通過網(wǎng)絡(luò)傳輸?shù)较乱粋€(gè)節(jié)點(diǎn),當(dāng)緩存寫滿,就持久化到本地硬盤上,當(dāng)所有數(shù)據(jù)都被處理完成后,才開始將處理后的數(shù)據(jù)通過網(wǎng)絡(luò)傳輸?shù)较乱粋€(gè)節(jié)點(diǎn)
這兩種數(shù)據(jù)傳輸模式是兩個(gè)極端,對(duì)應(yīng)的是流處理系統(tǒng)對(duì)低延遲的要求和批處理系統(tǒng)對(duì)高吞吐量的要求
Flink的執(zhí)行引擎采用了一種十分靈活的方式,同時(shí)支持了這兩種數(shù)據(jù)傳輸模型:
Flink以固定的緩存塊為單位進(jìn)行網(wǎng)絡(luò)數(shù)據(jù)傳輸,用戶可以通過設(shè)置緩存塊超時(shí)值指定緩存塊的傳輸時(shí)機(jī)。
如果緩存塊的超時(shí)值為0,則Flink的數(shù)據(jù)傳輸方式類似上文所提到流處理系統(tǒng)的標(biāo)準(zhǔn)模型,此時(shí)系統(tǒng)可以獲得最低的處理延遲
如果緩存塊的超時(shí)值為無限大/-1,則Flink的數(shù)據(jù)傳輸方式類似上文所提到批處理系統(tǒng)的標(biāo)準(zhǔn)模型,此時(shí)系統(tǒng)可以獲得最高的吞吐量
同時(shí)緩存塊的超時(shí)值也可以設(shè)置為0到無限大之間的任意值。緩存塊的超時(shí)閾值越小,則Flink流處理執(zhí)行引擎的數(shù)據(jù)處理延遲越低,但吞吐量也會(huì)降低,反之亦然。通過調(diào)整緩存塊的超時(shí)閾值,用戶可根據(jù)需求靈活地權(quán)衡系統(tǒng)延遲和吞吐量
默認(rèn)情況下,流中的元素并不會(huì)一個(gè)一個(gè)的在網(wǎng)絡(luò)中傳輸,而是緩存起來伺機(jī)一起發(fā)送(默認(rèn)為32KB,通過taskmanager.memory.segment-size設(shè)置),這樣可以避免導(dǎo)致頻繁的網(wǎng)絡(luò)傳輸,提高吞吐量,但如果數(shù)據(jù)源輸入不夠快的話會(huì)導(dǎo)致后續(xù)的數(shù)據(jù)處理延遲,所以可以使用env.setBufferTimeout(默認(rèn)100ms),來為緩存填入設(shè)置一個(gè)最大等待時(shí)間。等待時(shí)間到了之后,即使緩存還未填滿,緩存中的數(shù)據(jù)也會(huì)自動(dòng)發(fā)送。
timeoutMillis > 0 表示最長等待 timeoutMillis 時(shí)間,就會(huì)flush
timeoutMillis = 0 表示每條數(shù)據(jù)都會(huì)觸發(fā) flush,直接將數(shù)據(jù)發(fā)送到下游,相當(dāng)于沒有Buffer了(避免設(shè)置為0,可能導(dǎo)致性能下降)
timeoutMillis = -1 表示只有等到 buffer滿了或 CheckPoint的時(shí)候,才會(huì)flush。相當(dāng)于取消了 timeout 策略
總結(jié):
Flink以緩存塊為單位進(jìn)行網(wǎng)絡(luò)數(shù)據(jù)傳輸,用戶可以設(shè)置緩存塊超時(shí)時(shí)間和緩存塊大小來控制緩沖塊傳輸時(shí)機(jī),從而控制Flink的延遲性和吞吐量。