
Python下載文件的11種方式
使用Requests

使用wget


下載重定向的文件


分塊下載大文件

下載多個文件(并行/批量下載)

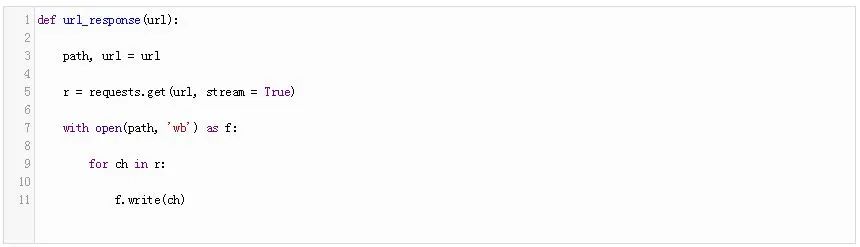



使用進度條進行下載

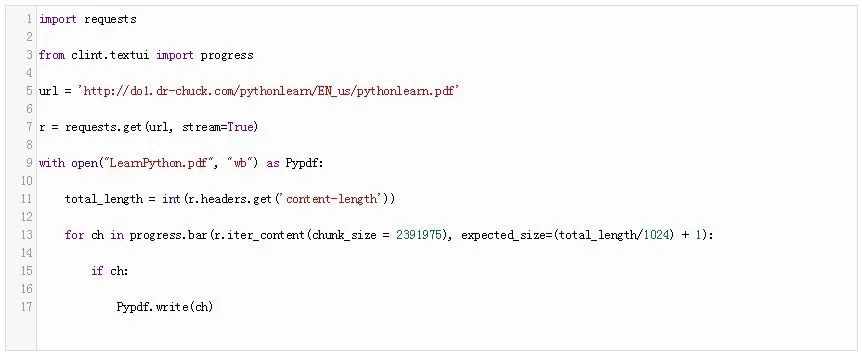
使用urllib下載網(wǎng)頁


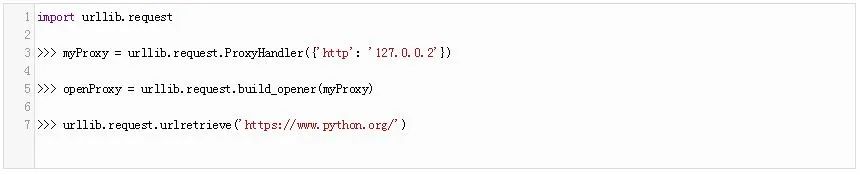
通過代理下載

使用urllib3






使用Boto3從S3下載文件





?Bucket名稱
你需要下載的文件名稱
文件下載之后的名稱



使用asyncio



-END- 往期精彩推薦 --?? -- 1、這個在線代碼編輯器,可以分享給任何人 -- 2、Python 造假數(shù)據(jù),用Faker就夠了 -- 3、在Python中玩轉(zhuǎn)Json數(shù)據(jù) -- 你??“三連”??了嗎?

評論
圖片
表情