
一次死鎖導(dǎo)致CPU異常飄高的整個故障排查過程
點擊上方藍(lán)色字體,選擇“標(biāo)星公眾號”
優(yōu)質(zhì)文章,第一時間送達(dá)
作者 | 自由早晚亂余生
來源 | urlify.cn/nYzAfm
一、問題詳情
linux一切皆文件
2021年4月2號,晚上10.45分左右,線上業(yè)務(wù)異常,后排查 線上服務(wù)器CPU 異常高,機(jī)器是 16核 64G的。但是實際負(fù)載已經(jīng)達(dá)到了 140左右。
top 命令截圖
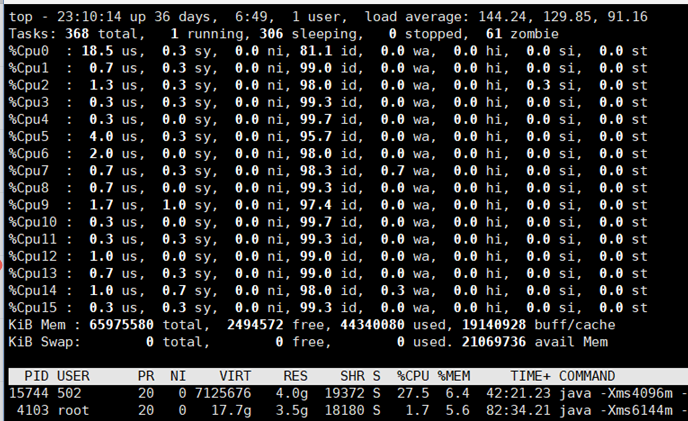
聯(lián)系騰訊云排查
虛擬機(jī)所屬于物理機(jī)是否有故障。
虛擬機(jī)所用的資源是否有抖動或者變更。(網(wǎng)絡(luò)/存儲等)
騰訊云回復(fù)暫無異常。
檢查系統(tǒng)日志發(fā)現(xiàn)異常
Apr 2 22:45:22 docker-machine systemd: Reloading.
Apr 2 22:46:37 docker-machine systemd-logind: Failed to start session scope session-175098.scope: Connection timed out
Apr 2 22:47:26 docker-machine systemd-logind: Failed to start session scope session-175101.scope: Connection timed out
Apr 2 22:47:51 docker-machine systemd-logind: Failed to start session scope session-175102.scope: Connection timed out
Apr 2 22:48:26 docker-machine systemd-logind: Failed to start session scope session-175104.scope: Connection timed out
Apr 2 22:48:51 docker-machine systemd-logind: Failed to start session scope session-175105.scope: Connection timed out
Apr 2 22:49:06 docker-machine kernel: INFO: task systemd:1 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:06 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebc68 ffff880fd5e69c00 ffff880fd8be0000 ffff880fd8bec000
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebdb8 ffff880fd8bebdb0 ffff880fd8be0000 ffff88039c6a9140
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebc80 ffffffff81700085 7fffffffffffffff ffff880fd8bebd30
Apr 2 22:49:06 docker-machine kernel: Call Trace:
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81702d97>] schedule_timeout+0x237/0x2d0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff813392cf>] ? idr_remove+0x17f/0x260
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700b81>] wait_for_completion+0xf1/0x130
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810aa6a0>] ? wake_up_q+0x80/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e2804>] __synchronize_srcu+0xf4/0x130
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e1c70>] ? trace_raw_output_rcu_utilization+0x60/0x60
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e2864>] synchronize_srcu+0x24/0x30
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81249b3b>] fsnotify_destroy_group+0x3b/0x70
Apr 2 22:49:06 docker-machine kernel: [<ffffffff8124b872>] inotify_release+0x22/0x50
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81208b64>] __fput+0xe4/0x210
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81208cce>] ____fput+0xe/0x10
Apr 2 22:49:06 docker-machine kernel: [<ffffffff8109c1e6>] task_work_run+0x86/0xb0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81079acf>] exit_to_usermode_loop+0x73/0xa2
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81003bcd>] syscall_return_slowpath+0x8d/0xa0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81703d8c>] int_ret_from_sys_call+0x25/0x8f
Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:06 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993c88 ffff880fdf597648 ffff880fd8375900 ffff880fd4994000
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993dd8 ffff880fd4993dd0 ffff880fd8375900 ffff880fd4993e40
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993ca0 ffffffff81700085 7fffffffffffffff ffff880fd4993d50
Apr 2 22:49:06 docker-machine kernel: Call Trace:
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81702d97>] schedule_timeout+0x237/0x2d0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81062aee>] ? kvm_clock_read+0x1e/0x20
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700b81>] wait_for_completion+0xf1/0x130
Apr 2 22:49:11 docker-machine kernel: INFO: task java:12560 blocked for more than 120 seconds.
Apr 2 22:49:11 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:11 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:11 docker-machine kernel: java D ffff880bfbdc7b00 0 12560 4206 0x00000180
Apr 2 22:49:11 docker-machine kernel: ffff880bfbdc7b00 ffff880bfbdc7b40 ffff880bfbdac2c0 ffff880bfbdc8000
Apr 2 22:49:11 docker-machine kernel: ffff8809beb142d8 ffff8809beb14200 0000000000000000 0000000000000000
Apr 2 22:49:11 docker-machine kernel: ffff880bfbdc7b18 ffffffff81700085 ffff880b155adfc0 ffff880bfbdc7b98
Apr 2 22:49:11 docker-machine kernel: Call Trace:
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8124ca55>] fanotify_handle_event+0x1b5/0x2f0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff810c2b50>] ? prepare_to_wait_event+0xf0/0xf0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8124933f>] fsnotify+0x26f/0x460
Apr 2 22:49:11 docker-machine kernel: [<ffffffff810a1fd1>] ? in_group_p+0x31/0x40
Apr 2 22:49:11 docker-machine kernel: [<ffffffff812111fc>] ? generic_permission+0x15c/0x1d0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff812b355b>] security_file_open+0x8b/0x90
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8120484f>] do_dentry_open+0xbf/0x320
Apr 2 22:49:11 docker-machine kernel: [<ffffffffa02cb552>] ? ovl_d_select_inode+0x42/0x110 [overlay]
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81205e15>] vfs_open+0x55/0x80
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81214143>] path_openat+0x1c3/0x1300
查看日志,覺得很大可能性是:cache 落盤故障,有可能是 io 的問題。通過 iotop 進(jìn)行排查,未發(fā)現(xiàn)異常。
當(dāng)時我們認(rèn)為是 騰訊云底層存儲或者網(wǎng)絡(luò)出現(xiàn)問題導(dǎo)致的。
在排查了近一個小時,機(jī)器上面的cpu 還是沒有降低。我們對機(jī)器進(jìn)行了重啟。重啟后,一些恢復(fù)了正常。
二、 問題解析
認(rèn)為是存儲的問題
首先上面的故障是同時出現(xiàn)在兩臺機(jī)器(A和B)的, 詢問騰訊云 A 的系統(tǒng)盤和A的數(shù)據(jù)盤以及B的數(shù)據(jù)盤都是在同一個遠(yuǎn)端存儲的,所以這更加深了我們認(rèn)為是存儲導(dǎo)致的問題,有可能是到物理機(jī)到存儲之間的網(wǎng)絡(luò),也有可能是存儲本身的性能問題。
騰訊云排查后說這兩個機(jī)器,所用的存儲和存儲網(wǎng)絡(luò)沒有問題,所以存儲問題不成立。
系統(tǒng)的僵尸進(jìn)程很多
在上面top 命令我們可以看到有僵死進(jìn)程,后面也是一直在增加僵死進(jìn)程。
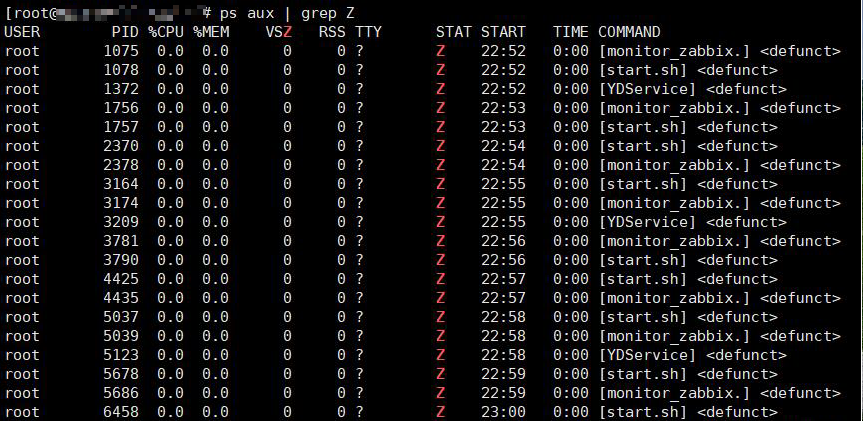
僵死進(jìn)程的來源:
如何看僵死進(jìn)程
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]'上面的僵死進(jìn)程來源是我們的定時任務(wù)導(dǎo)致的,我們定時任務(wù)腳本執(zhí)行的進(jìn)程變成的僵死進(jìn)程。
/var/log/message 異常信息
我們再看看
/var/log/message的日志,我們可以看到一個很關(guān)鍵的信息kernel: INFO: task systemd:1 blocked for more than 120 seconds.網(wǎng)上大多數(shù)時是說
vm.dirty_ratio和vm.dirty_background_ratio這兩個參數(shù)設(shè)置的有問題。我們查看了我們這兩個內(nèi)核參數(shù)的配置,都是正常合理的。
$ sysctl -a|grep -E 'vm.dirty_background_ratio|vm.dirty_ratio'
vm.dirty_background_ratio = 10 #
vm.dirty_ratio = 30具體的參數(shù)詳解,見下文。
我們再看看
/var/log/message的日志,我們可以看到一個很關(guān)鍵的信息
Apr 2 22:45:22 docker-machine systemd: Reloading.
Apr 2 22:49:06 docker-machine kernel: INFO: task systemd:1 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000
Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000
Apr 2 22:49:11 docker-machine kernel: INFO: task java:12560 blocked for more than 120 seconds.
Apr 2 22:49:11 docker-machine kernel: java D ffff880bfbdc7b00 0 12560 4206 0x00000180就是
systemd在Reloading,systemd和fsnotify_mark都被block了,那么被鎖了原因是什么,按道理來說應(yīng)該io的問題啊,就是寫得慢啊,但是我們忽略了一個問題,如果要寫的文件加鎖了,那么也是會出現(xiàn)這個情況的啊。尋找加鎖的原因:騰訊云主機(jī)安全產(chǎn)品 云鏡, 沒錯就很大可能性是它導(dǎo)致的。具體內(nèi)容見下文。
三、問題原因
為什么會定位到云鏡產(chǎn)品,首先是我們認(rèn)為如果底層 io 沒有問題的話,那么就只能是文件可能被鎖了,并且如果你細(xì)心的話,你會發(fā)現(xiàn)僵死進(jìn)程里面,有云鏡的身影
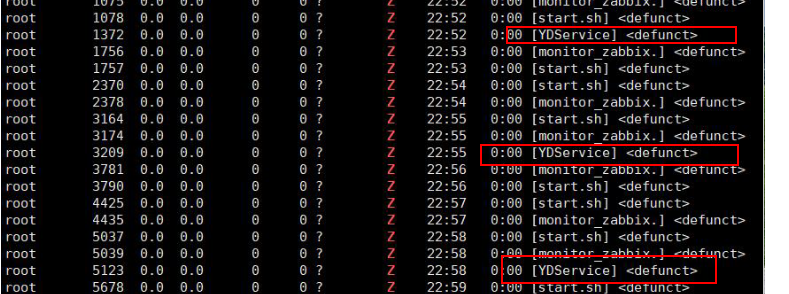
為什么云鏡會變成僵死進(jìn)程,是因為云鏡啟動失敗了,一直在啟動。
我們再說回為什么會定位到云鏡上面,主要是因為云鏡會對系統(tǒng)上文件有定期掃描的,為什么會想到就是安全產(chǎn)品(https://access.redhat.com/solutions/2838901)。安全產(chǎn)品就是云鏡。
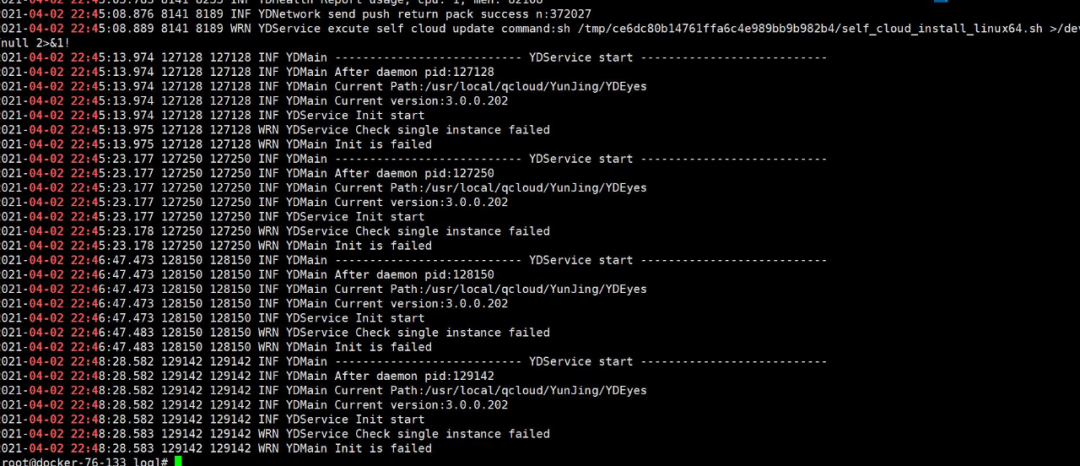
我們觀察云鏡的日志,我們又發(fā)現(xiàn)了一個問題,原來在 22:45 左右,云鏡在更新,這個很巧合啊,我們出問題的兩個機(jī)器都在這個時間段進(jìn)行了更新,而沒有異常的機(jī)器,都沒有更新操作。
云鏡更新的日志

更新后一直沒有云鏡一直啟動失敗
redhat官方文檔https://access.redhat.com/solutions/2838901
也是說到安全產(chǎn)品會可能觸發(fā)這個問題。
最終結(jié)論
最終讓騰訊云排查云鏡此次版本升級,得到答復(fù):
推測YDService在exit group退出的時未及時對fanotify/inotify進(jìn)行適當(dāng)?shù)那謇砉ぷ鳎瑢?dǎo)致其它進(jìn)程阻塞等待,因此針對此點進(jìn)行了優(yōu)化。
問題1:針對為什么只有兩臺機(jī)器在那個時間點進(jìn)行更新,是因為那個云鏡后端調(diào)度策略是分批升級。
四、擴(kuò)展
進(jìn)程的幾種狀態(tài)
https://liam.page/2020/01/10/the-states-of-processes-on-Linux/
進(jìn)程通常處于以下兩種狀態(tài)之一:
在 CPU 上執(zhí)行(此時,進(jìn)程正在運(yùn)行) 在
ps或是top中,狀態(tài)標(biāo)識為R的進(jìn)程,即處于正在運(yùn)行狀態(tài)。不在 CPU 上執(zhí)行(此時,進(jìn)程未在運(yùn)行)
未在運(yùn)行的進(jìn)程可能處于不同狀態(tài):
馬后炮
在前面的日志中,也就是下面:
Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000
Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000我們部分進(jìn)程處于
不可中斷之睡眠狀態(tài)(D), 在這個狀態(tài)的服務(wù),前面也說到只能給他資源,或者重啟系統(tǒng)。也就可以說明:解釋疑問:
對于怨婦,你還能怎么辦,只能滿足它啊:搞定不可中斷之睡眠狀態(tài)進(jìn)程所等待的資源,使資源可用。
如果滿足不了它,那就只能 kill the world——重啟系統(tǒng)。
可運(yùn)行狀態(tài) (R)
進(jìn)程獲取了所有所需資源,正等待 CPU 時,就會進(jìn)入可運(yùn)行狀態(tài)。處于可運(yùn)行狀態(tài)的進(jìn)程在
ps的輸出中,也已R標(biāo)識。舉例來說,一個正在 I/O 的進(jìn)程并不立即需要 CPU。當(dāng)進(jìn)程完成 I/O 操作后,就會觸發(fā)一個信號,通知 CPU 和調(diào)度器將該進(jìn)程置于運(yùn)行隊列(由內(nèi)核維護(hù)的可運(yùn)行進(jìn)程的列表)。當(dāng) CPU 可用時,該進(jìn)程就會進(jìn)入正在運(yùn)行狀態(tài)。
可中斷之睡眠狀態(tài) (S)
可中斷之睡眠狀態(tài)表示進(jìn)程在等待時間片段或者某個特定的事件。一旦事件發(fā)生,進(jìn)程會從可中斷之睡眠狀態(tài)中退出。
ps命令的輸出中,可中斷之睡眠狀態(tài)標(biāo)識為S。不可中斷之睡眠狀態(tài)(D)
不可中斷之睡眠狀態(tài)的進(jìn)程不會處理任何信號,而僅在其等待的資源可用或超時時退出(前提是設(shè)置了超時時間)。
不可中斷之睡眠狀態(tài)通常和設(shè)備驅(qū)動等待磁盤或網(wǎng)絡(luò) I/O 有關(guān)。在內(nèi)核源碼
fs/proc/array.c中,其文字定義為"D (disk sleep)", /* 2 */。當(dāng)進(jìn)程進(jìn)入不可中斷之睡眠狀態(tài)時,進(jìn)程不會處理信號,而是將信號都積累起來,等進(jìn)程喚醒之后再處理。在 Linux 中,ps命令使用D來標(biāo)識處于不可中斷之睡眠狀態(tài)的進(jìn)程。系統(tǒng)會為不可中斷之睡眠狀態(tài)的進(jìn)程設(shè)置進(jìn)程運(yùn)行狀態(tài)為:
p->state = TASK_UNINTERRUPTABLE;由于處于不可中斷之睡眠狀態(tài)的進(jìn)程不會處理任何信號,所以
kill -9也殺不掉它。解決此類進(jìn)程的辦法只有兩個:僵死狀態(tài)(Z)
進(jìn)程可以主動調(diào)用
exit系統(tǒng)調(diào)用來終止,或者接受信號來由信號處理函數(shù)來調(diào)用exit系統(tǒng)調(diào)用來終止。當(dāng)進(jìn)程執(zhí)行
exit系統(tǒng)調(diào)用后,進(jìn)程會釋放相應(yīng)的數(shù)據(jù)結(jié)構(gòu);此時,進(jìn)程本身已經(jīng)終止。不過,此時操作系統(tǒng)還沒有釋放進(jìn)程表中該進(jìn)程的槽位(可以形象地理解為,「父進(jìn)程還沒有替子進(jìn)程收尸」);為解決這個問題,終止前,進(jìn)程會向父進(jìn)程發(fā)送SIGCHLD信號,通知父進(jìn)程來釋放子進(jìn)程在操作系統(tǒng)進(jìn)程表中的槽位。這個設(shè)計是為了讓父進(jìn)程知道子進(jìn)程退出時所處的狀態(tài)。子進(jìn)程終止后到父進(jìn)程釋放進(jìn)程表中子進(jìn)程所占槽位的過程,子進(jìn)程進(jìn)入僵尸狀態(tài)(zombie state)。如果在父進(jìn)程因為各種原因,在釋放子進(jìn)程槽位之前就掛掉了,也就是,父進(jìn)程來不及為子進(jìn)程收尸。那么,子進(jìn)程就會一直處于僵尸狀態(tài)。而考慮到,處于僵尸狀態(tài)的進(jìn)程本身已經(jīng)終止,無法再處理任何信號,所以它就只能是孤魂野鬼,飄在操作系統(tǒng)進(jìn)程表里,直到系統(tǒng)重啟。
為什么我們故障機(jī)器上面部分服務(wù)存在問題,部分服務(wù)正常。
因為部分進(jìn)程處于
不可中斷之睡眠狀態(tài)(D)。文件(linux一切皆文件)被鎖,導(dǎo)致了部分服務(wù)進(jìn)程進(jìn)入了不可中斷睡眠狀態(tài)。
如何快速清理僵尸進(jìn)程(Z)
用top查看系統(tǒng)中的僵尸進(jìn)程情況
top
再看看這些僵尸是什么程序來的
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]'
kill -s SIGCHLD pid (父進(jìn)程pid)
內(nèi)核參數(shù)相關(guān)
dirty_background_ratio 指當(dāng)文件系統(tǒng)緩存臟頁數(shù)量達(dá)到系統(tǒng)內(nèi)存百分之多少時(默認(rèn)10%)喚醒內(nèi)核的 flush 等進(jìn)程,寫回磁盤。
dirty_ratio 為最大臟頁比例,當(dāng)臟頁數(shù)達(dá)到該比例時,必須將所有臟數(shù)據(jù)提交到磁盤,同時所有新的 IO 都會被阻塞,直到臟數(shù)據(jù)被寫入磁盤,通常會造成 IO 卡頓。系統(tǒng)先會達(dá)到
vm.dirty_background_ratio的條件然后觸發(fā) flush 進(jìn)程進(jìn)行異步的回寫操作,此時應(yīng)用進(jìn)程仍然可以進(jìn)行寫操作,如果達(dá)到vm.dirty_ratio這個參數(shù)所設(shè)定的值,此時操作系統(tǒng)會轉(zhuǎn)入同步地處理臟頁的過程,阻塞應(yīng)用進(jìn)程。
如何查看哪些文件被哪些進(jìn)程被鎖
http://blog.chinaunix.net/uid-28541347-id-5678998.html
cat /proc/locks
1: POSIX ADVISORY WRITE 3376 fd:10:805736756 0 EOF
2: FLOCK ADVISORY WRITE 1446 00:14:23843 0 EOF
3: FLOCK ADVISORY WRITE 4650 00:14:32551 0 EOF
4: POSIX ADVISORY WRITE 4719 fd:01:531689 1073741824 1073742335
5: OFDLCK ADVISORY READ 1427 00:06:1028 0 EOF
6: POSIX ADVISORY WRITE 4719 00:14:26155 0 EOF
7: POSIX ADVISORY WRITE 4443 00:14:26099 0 EOF
8: FLOCK ADVISORY WRITE 4561 00:14:34870 0 EOF
9: POSIX ADVISORY WRITE 566 00:14:15509 0 EOF
10: POSIX ADVISORY WRITE 4650 fd:01:788600 0 EOF
11: OFDLCK ADVISORY READ 1713 00:06:1028 0 EOF
12: FLOCK ADVISORY WRITE 1713 fd:10:268435553 0 EOF
13: FLOCK ADVISORY WRITE 1713 fd:10:268435528 0 EOF
14: POSIX ADVISORY WRITE 12198 fd:01:526366 0 EOF
15: POSIX ADVISORY WRITE 3065 fd:10:805736741 0 EOF
16: FLOCK ADVISORY WRITE 1731 fd:10:268435525 0 EOF
17: FLOCK ADVISORY WRITE 4459 00:14:37972 0 EOF
18: POSIX ADVISORY WRITE 1444 00:14:14793 0 EOF
我們可以看到/proc/locks下面有鎖的信息:我現(xiàn)在分別敘述下含義:
POSIX FLOCK這個比較明確,就是哪個類型的鎖。flock系統(tǒng)調(diào)用產(chǎn)生的是FLOCK,fcntl調(diào)用F_SETLK,F_SETLKW或者lockf產(chǎn)生的是POSIX類型,有次可見兩種調(diào)用產(chǎn)生的鎖的類型是不同的;ADVISORY表明是勸告鎖;
WRITE顧名思義,是寫鎖,還有讀鎖;
18849 是持有鎖的進(jìn)程ID。當(dāng)然對于flock這種類型的鎖,會出現(xiàn)進(jìn)程已經(jīng)退出的狀況。
08:02:852674表示的對應(yīng)磁盤文件的所在設(shè)備的主設(shè)備好,次設(shè)備號,還有文件對應(yīng)的inode number。0 表示的是所的其實位置
EOF表示的是結(jié)束位置。這兩個字段對fcntl類型比較有用,對flock來是總是0 和EOF。
粉絲福利:Java從入門到入土學(xué)習(xí)路線圖
??????

??長按上方微信二維碼 2 秒
感謝點贊支持下哈 