
知乎 | 有哪些當(dāng)時(shí)很有潛力但是最終沒有流行的深度學(xué)習(xí)算法?
編者薦語(yǔ)
?每天的新工作新paper層出不窮,而能夠在深度學(xué)習(xí)圈子里脫穎而出的工作屈指可數(shù),還有很多有潛力的工作因?yàn)榉N種原因被埋沒了。在你的科研/工程閱讀中遇見過哪些看起來很有潛力的深度學(xué)習(xí)模型,對(duì)他們沒有流行起來你有什么見解?
轉(zhuǎn)自丨極市平臺(tái)
原問題:最近讀了一些201x年的論文感覺有一些十分新穎但是也不知道為什么后續(xù)沒有被重視。在你的科研/工程閱讀中遇見過哪些看起來很有潛力的深度學(xué)習(xí)模型,對(duì)他們沒有流行起來你有什么見解?
問題鏈接:https://www.zhihu.com/question/490517834
#?回答一
作者:霍華德
來源鏈接:https://www.zhihu.com/question/490517834/answer/2169566194
提名Memory Networks 原文鏈接:https://arxiv.org/pdf/1410.3916.pdf
原文鏈接:https://arxiv.org/pdf/1410.3916.pdf
準(zhǔn)確說Memory Networks并不只是一個(gè)模型,而是一套思路,使用外部的一個(gè)memory來存儲(chǔ)長(zhǎng)期記憶信息,因?yàn)楫?dāng)時(shí)RNN系列模型使用final state 存儲(chǔ)的信息,序列過長(zhǎng)就會(huì)遺忘到早期信息。
甚至,我覺得Memory Networks的思想后面啟發(fā)了self-attention和transformer。最重要的就是提出了query - key - value思想,當(dāng)時(shí)的該模型聚焦的任務(wù)主要是question answering,先用輸入的問題query檢索key-value memories,找到和問題相似的memory的key,計(jì)算相關(guān)性分?jǐn)?shù),然后對(duì)value embedding進(jìn)行加權(quán)求和,得到一個(gè)輸出向量。這后面就衍生出了self-attention里的Q,K,V表示,在self-attention里的Q=K=V,但早期的Memory Networks中可以看出,QKV其實(shí)是三個(gè)向量。
如今,Memory Networks已少有人提及,但它的思想已經(jīng)被transformer繼承,而transformer已經(jīng)橫掃NLP和CV等多個(gè)領(lǐng)域。突然有了一種“功成不必在我,而功成必定有我"的感慨。又聯(lián)想到譚嗣同變法雖然失敗了,但他又一個(gè)學(xué)生叫楊昌濟(jì),楊昌濟(jì)又有一個(gè)學(xué)生叫毛澤東...
#?回答二
作者:edisonlee
來源鏈接:
https://www.zhihu.com/question/490517834/answer/2171472030我也提一個(gè):脈沖神經(jīng)網(wǎng)絡(luò)(Spiking Neural Networks, SNN),最早由Maass教授[1]于1997年提出的模型。SNN不能說完全消失,每年頂會(huì)都有那么幾篇,但是總感覺不溫不火的。
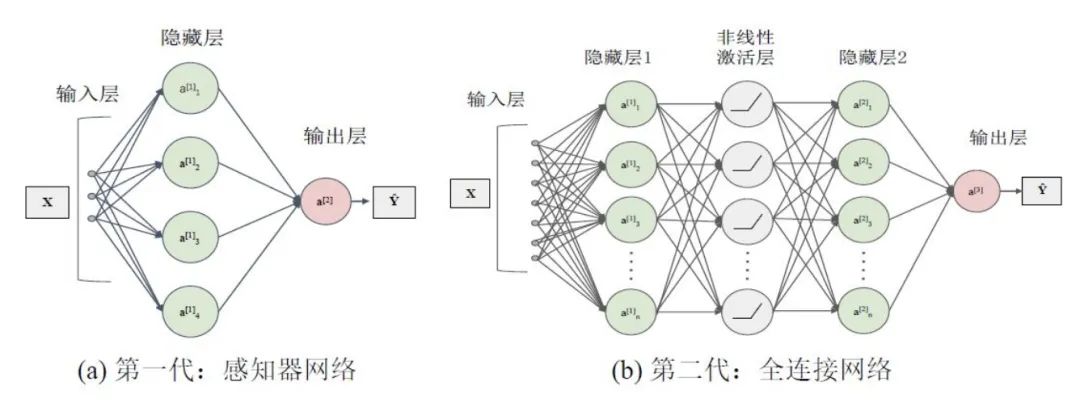
SNN是基于大腦運(yùn)行機(jī)制的新一代人工神經(jīng)網(wǎng)絡(luò),是目前最接近類腦計(jì)算水平的一類生物啟發(fā)模型,具有可以處理生物激勵(lì)信號(hào)以及解釋大腦復(fù)雜智能行為的優(yōu)勢(shì),被譽(yù)為第三代神經(jīng)網(wǎng)絡(luò)(第一代感知機(jī),第二代以CNN為代表的的神經(jīng)網(wǎng)絡(luò))。SNN在本質(zhì)上與目前廣泛使用的人工神經(jīng)網(wǎng)絡(luò)(ANN)存在巨大差異,主要體現(xiàn)在如下幾點(diǎn):
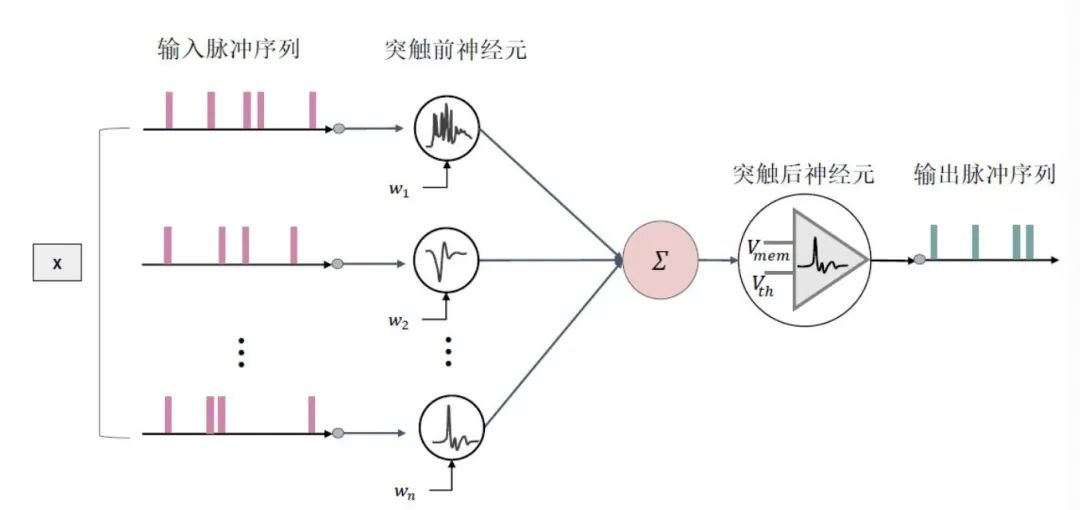
SNN使用離散的脈沖序列(0和1)進(jìn)行消息傳遞,而ANN使用實(shí)值;因此ANN具有更高的運(yùn)算效率。
SNN分為時(shí)間驅(qū)動(dòng)和事件驅(qū)動(dòng)兩種。前者利用時(shí)間步長(zhǎng)仿真信號(hào),后者根據(jù)只有在接收或發(fā)射脈沖信號(hào)時(shí)才處于活躍狀態(tài);而大部分的ANN架構(gòu)無法獲取時(shí)間維度信息(除了RNN類的模型),并且每個(gè)神經(jīng)元永遠(yuǎn)處于激活狀態(tài),因此SNN具有更少的能量消耗。
SNN使用脈沖序列進(jìn)行通訊,與人腦的消息傳播機(jī)制更像,因此SNN比ANN更像神經(jīng)網(wǎng)絡(luò)。
SNN可以運(yùn)行在專用的神經(jīng)形態(tài)硬件上,例如Intel Loihi[2],Brainchip Akida[3]等;而ANN主要應(yīng)用在GPU上進(jìn)行加速。已有文獻(xiàn)證明,基于SNN 架構(gòu)的芯片能量效率比基于Field Programmable Gate Array(FPGA)實(shí)現(xiàn)的卷積神經(jīng)網(wǎng)絡(luò)的能量效率高出兩個(gè)數(shù)量級(jí)。
導(dǎo)致SNN難以流行的原因主要是:
SNN使用離散脈沖序列,其中脈沖發(fā)射函數(shù)Heaviside step函數(shù)具有不可微的性質(zhì),因此難以像目前的ANN一樣使用梯度下降算法優(yōu)化。雖然目前有一些替代梯度的方法,但是在效果上還是和ANN有點(diǎn)差距。
目前的神經(jīng)形態(tài)硬件沒有流行。目前主流的計(jì)算硬件都是GPU,在GPU上,0-1的脈沖序列都被當(dāng)成實(shí)值進(jìn)行矩陣運(yùn)算,無法看出SNN與ANN的差距。
參考文獻(xiàn):
[1] Maass W. Networks of spiking neurons: the third generation of neural network models[J]. Neural networks, 1997, 10(9):1659-1671.
[2] Mike Davies, Narayan Srinivasa, Tsung-Han Lin, Gautham Chinya, YongqiangCao, Sri Harsha Choday, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain,et al. 2018. Loihi: A neuromorphic manycore processor with on-chip learning.Ieee Micro38, 1 (2018), 82–99.
[3] Anup Vanarse, Adam Osseiran, Alexander Rassau, and Peter van der Made. 2019.A hardware-deployable neuromorphic solution for encoding and classificationof electronic nose data.Sensors19, 22 (2019), 4831.
[4] Cao Y, Chen Y, Khosla D. Spiking deep convolutional neural networks for energy-efficient object recognition[J]. International Journal of Computer Vision, 2015, 113(1):54-66.
#?回答三
作者:陀飛輪
來源鏈接:https://www.zhihu.com/question/490517834/answer/2169518353
Hinton的膠囊網(wǎng)絡(luò)(Capsule Network)
 原文鏈接:https://arxiv.org/pdf/1710.09829.pdf
原文鏈接:https://arxiv.org/pdf/1710.09829.pdf
 原文鏈接:https://openreview.net/pdf?id=HJWLfGWRb
原文鏈接:https://openreview.net/pdf?id=HJWLfGWRb
Hinton認(rèn)為人的視覺系統(tǒng)會(huì)建立“坐標(biāo)框架”,并且坐標(biāo)框架的不同會(huì)極大地改變?nèi)说恼J(rèn)知。而在CNN上卻很難看到類似“坐標(biāo)框架”的東西。Hinton的看法是,我們需要 Equivariance 而不是 Invariance。Invariance,是指表示不隨變換變化,比如分類結(jié)果等等;而 equivariance 不會(huì)丟失這些信息,它只是對(duì)內(nèi)容的一種變換。
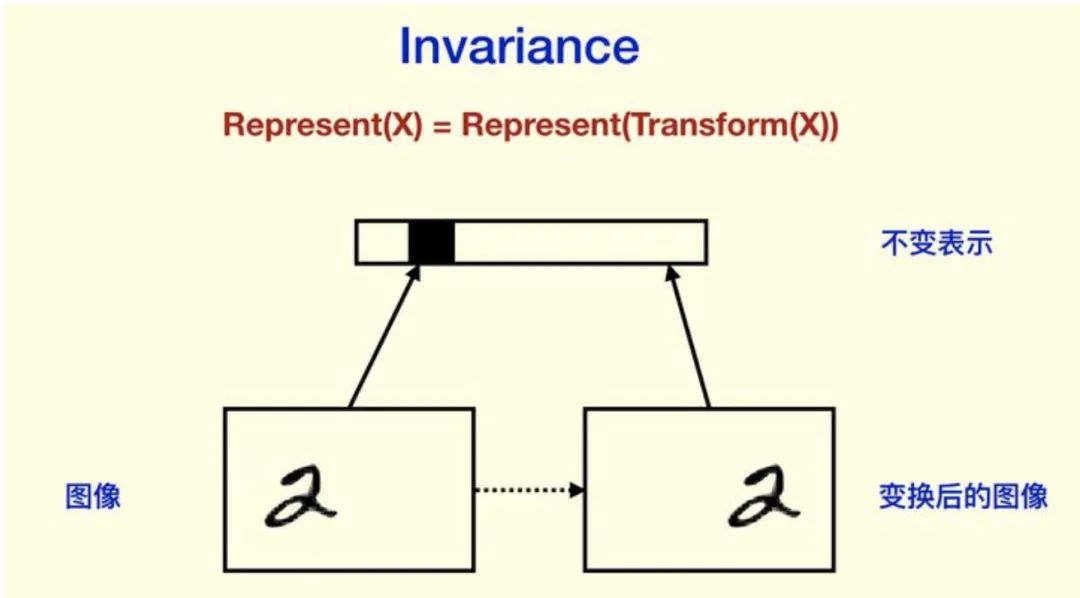
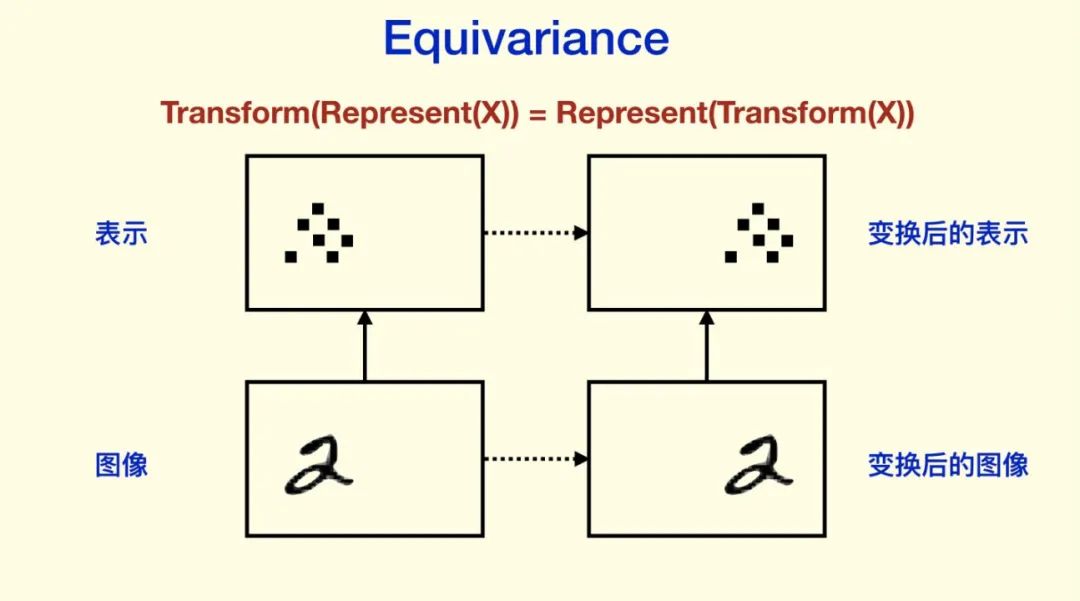
Invariance 主要是通過 Pooling 等下采樣過程得到的。CNN同樣強(qiáng)調(diào)對(duì)空間的 invariance,也就是對(duì)物體的平移之類的不敏感(物體不同的位置不影響它的識(shí)別)。對(duì)平移和旋轉(zhuǎn)的 invariance(CNN的設(shè)計(jì)希望有invariance,雖然CNN不是完全的invariance),其實(shí)是丟棄了“坐標(biāo)框架”,Hinton認(rèn)為這是CNN不能反映“坐標(biāo)框架”的重要原因。CNN 前面非 Pooling 的部分是 equivariance 的。
于是Hinton 提出了一個(gè)猜想:
物體和觀察者之間的關(guān)系(比如物體的姿態(tài)),應(yīng)該由一整套激活的神經(jīng)元表示,而不是由單個(gè)神經(jīng)元,或者一組粗編碼(coarse-coded,這里意思是指類似一層中,并沒有經(jīng)過精細(xì)組織)的神經(jīng)元表示。只有這樣的表示,才能有效表達(dá)關(guān)于“坐標(biāo)框架”的先驗(yàn)知識(shí)。而這一整套神經(jīng)元,Hinton認(rèn)為就是Capsule。
capsule network最大的特點(diǎn)就是“vector in vector out”,而之前的scaler neuron則是“scaler in scaler out”,所以本質(zhì)上來講capsule是一種vector neuron。capsule network中的每一層由若干個(gè)capsule組成,capsule的輸入和輸出均為一個(gè)向量。
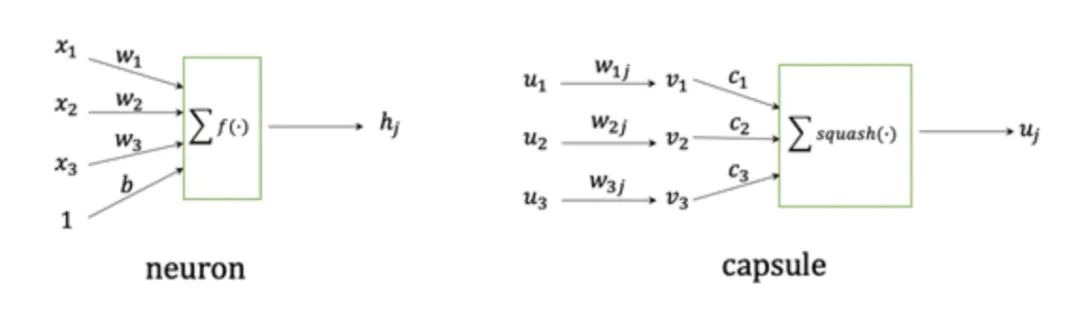
圖2對(duì)neuron和capsule進(jìn)行對(duì)比。神經(jīng)網(wǎng)絡(luò)的輸入是一系列的標(biāo)量,通過對(duì)這些標(biāo)量進(jìn)行加權(quán)求和并經(jīng)過激活函數(shù),得到一個(gè)標(biāo)量,也就是神經(jīng)元的最終輸出。capsule的輸入則是一系列的向量,這些向量首先經(jīng)過一個(gè)編碼整體與部分關(guān)系的矩陣映射,然后這些向量根據(jù)和整體特征的相似度加權(quán)平均,得到表示整體的特征向量,最后通過一個(gè)squash函數(shù)得到capsule的輸出。高層特征由低層特征加權(quán)得到,而權(quán)重又由高層特征和低層特征的相似程度計(jì)算得到,這兩個(gè)問題相互依賴,于是capsule network提出一種動(dòng)態(tài)路由算法(Dynamic Rounting)。
Capsule Network在剛發(fā)表的時(shí)候,引起了深度學(xué)習(xí)領(lǐng)域的廣泛關(guān)注,一度認(rèn)為可能會(huì)替代CNN成為新一代的通用網(wǎng)絡(luò)架構(gòu),誰(shuí)知道之后被Transformer一統(tǒng)江湖了。
Capsule Network之所以沒有流行起來可能有三點(diǎn)原因:
理解capsule本身就有難度,而且使用了機(jī)器學(xué)習(xí)的一些算法,深度學(xué)習(xí)當(dāng)?shù)赖哪甏瑱C(jī)器學(xué)習(xí)算法就算是高門檻了。
capsule本身有很多細(xì)節(jié)沒想清楚,比如原始的capsule是引入聚類的思想來對(duì)特征進(jìn)行抽象,那有沒有其他更合適的方法呢,capsule還存在許多沒有解決的問題。
Transformer中的self-attention能夠建模pixel之間的相對(duì)關(guān)系,跟capsule的某些理念不謀而合,而且Transformer整體框架上要比capsule簡(jiǎn)潔易懂。
關(guān)于Capsule Network的來龍去脈可以看這篇介紹:https://zhuanlan.zhihu.com/p/29435406
關(guān)于CNN平移不變性的討論,可以看以下回答:https://www.zhihu.com/question/301522740
往期精彩:
?時(shí)隔一年!深度學(xué)習(xí)語(yǔ)義分割理論與代碼實(shí)踐指南.pdf第二版來了!
?新書預(yù)告 | 《機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)》出版在即!