
京東熱key探測中間件太火了!竟然單機(jī)qps能從2萬提升至35萬
京東hotkey框架(JD-hotkey)是京東app后臺研發(fā)的一款高性能熱數(shù)據(jù)探測中間件,用來實時探測出系統(tǒng)的熱數(shù)據(jù),并將熱數(shù)據(jù)毫秒內(nèi)推送至系統(tǒng)的業(yè)務(wù)集群服務(wù)器的JVM內(nèi)存。以下統(tǒng)稱為"熱key"。
該框架主要用于對任意突發(fā)性的無法預(yù)先感知的熱key,包括并不限于熱點數(shù)據(jù)(如突發(fā)大量請求同一個商品)、熱用戶(如惡意爬蟲刷子)、熱接口(突發(fā)海量請求同一個接口)等,進(jìn)行毫秒級精準(zhǔn)探測到。然后對這些熱key,推送到所有服務(wù)端JVM內(nèi)存中,以大幅減輕對后端數(shù)據(jù)存儲層的沖擊,并可以由使用者決定如何分配、使用這些熱key(譬如對熱商品做本地緩存、對熱用戶進(jìn)行拒絕訪問、對熱接口進(jìn)行熔斷或返回默認(rèn)值)。這些熱數(shù)據(jù)在整個服務(wù)端集群內(nèi)保持一致性,并且業(yè)務(wù)隔離,worker端性能強(qiáng)悍。
之前在發(fā)布過該框架架構(gòu)設(shè)計的文章,詳細(xì)講述了框架的工作原理。目前該框架已在京東App后臺、數(shù)據(jù)中臺、白條、金融、商家等多十余個業(yè)務(wù)部門接入運行,目前應(yīng)用最廣泛的場景是刷子(爬蟲)用戶實時探測和redis熱key實時探測。
由于框架自身核心點在于實時(準(zhǔn)實時,可配置1-500ms內(nèi))探測系統(tǒng)運行中產(chǎn)生的熱key,而且還要面臨隨時可能突發(fā)的暴增流量(如突發(fā)搶購某商品),還要在探測出熱key后在毫秒時間內(nèi)推送到該業(yè)務(wù)組的幾百、數(shù)千到上萬臺服務(wù)器JVM內(nèi)存中,所以對于它的單機(jī)性能要求非常高。
我們知道框架的計算單元worker端,它的工作流程是:啟動一個netty server,和業(yè)務(wù)服務(wù)器(數(shù)百——上萬)建立長連接,業(yè)務(wù)服務(wù)器批量定時(1——500ms一次)上傳自己的待測key給worker,worker對發(fā)來的key進(jìn)行滑動窗口累加計算,達(dá)到用戶設(shè)置的閾值(如某個類型的key,pin_xxxx達(dá)到2秒20次),則將該key推送至整個業(yè)務(wù)服務(wù)器集群內(nèi),從而業(yè)務(wù)服務(wù)器可以在內(nèi)存中使用這些熱key,到達(dá)設(shè)置的過期時間后會自動過期刪除。
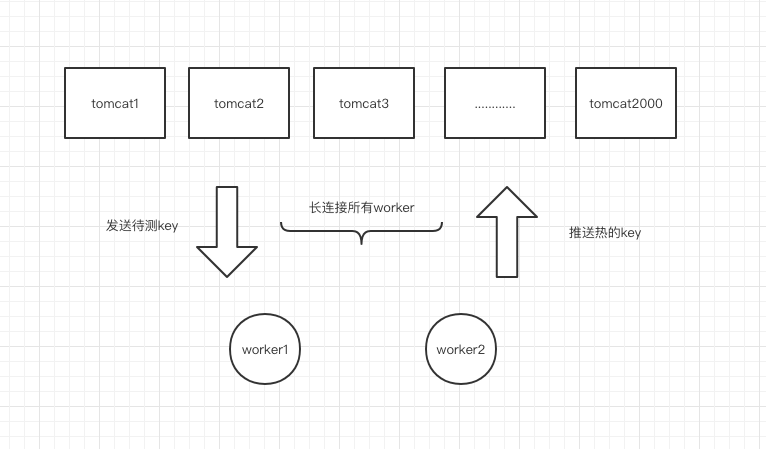
截止目前,該框架0.4版本的性能表現(xiàn)如下(硬件配置為隨機(jī)機(jī)房創(chuàng)建的16核docker容器):
1、key探測計算:每秒可接收N臺服務(wù)器發(fā)來的40多萬個待測key,并計算完畢其中的35萬左右。實測可每秒穩(wěn)定計算30萬,極限計算37萬,超過的量會進(jìn)入隊列等待。
2、熱key推送:當(dāng)熱key產(chǎn)生后,對該業(yè)務(wù)集群所有長連接的服務(wù)器進(jìn)行key推送,每秒可穩(wěn)定推送10-12萬次(毫秒內(nèi)送達(dá))。譬如1千臺服務(wù)器,每秒該worker可以支撐產(chǎn)生100個熱key,即推送100*1000次。當(dāng)每秒產(chǎn)生200個熱key,即每秒需要推送20萬次時,會出現(xiàn)有1s左右的延遲送達(dá)。強(qiáng)度壓測當(dāng)每秒要推送50萬次時,出現(xiàn)了極其明顯的延遲,推送至client端的時間已不可控。在所有積壓的key推送完畢后,可繼續(xù)正常工作。
注意,推送是和接收30萬key并行的,也就是進(jìn)和出加起來吞吐量在40多萬每秒。
以上為單機(jī)性能表現(xiàn),通過橫向擴(kuò)展,可以提升對應(yīng)的處理量,不存在單點問題,橫向擴(kuò)展中無性能瓶頸。以當(dāng)前的性能表現(xiàn),單機(jī)可以完成1000臺業(yè)務(wù)服務(wù)器的熱key探測任務(wù)。系統(tǒng)設(shè)計之初,期望值是單機(jī)能支撐200臺業(yè)務(wù)器的日常計算,所以目前性能是高于預(yù)期的,在逐步的優(yōu)化過程中,也遇到了很多問題,本文就是對這個過程中所遇到的與性能有關(guān)的問題和優(yōu)化過程,做個記錄。
以下所有數(shù)據(jù),不特殊指明的話,均默認(rèn)是隨機(jī)機(jī)房的16核docker容器,屬于共享型資源,實際配置強(qiáng)于8核物理機(jī),弱于16核物理機(jī)。
# 初始版本——2萬QPS
該版本采用的是jdk1.8.20(jdk的小版本影響很大),worker端采用的架構(gòu)方式為netty默認(rèn)參數(shù)+disruptor重復(fù)消費模式。
netty默認(rèn)開啟cpu核數(shù)*2個線程,作為netty的工作線程,用于接收幾千臺機(jī)器發(fā)來的key,接收到待測key后,全部寫入到disruptor的生產(chǎn)者線程,生產(chǎn)者是單線程。之后disruptor同樣是cpu核數(shù)*2個消費者線程,每個消費者都重復(fù)消費每條發(fā)來的key。
這里很明顯的問題,大家都能看到,disruptor為什么要重復(fù)消費每個key?
因為當(dāng)初的設(shè)想是將同一個key固定交給同一個線程進(jìn)行累加計算,以避免多線程同時累加同一個key造成數(shù)量計算錯誤。所以每個消費者線程都全部消費所有的key,譬如8個線程,線程1只處理key的hash值為1的,其他的return不處理。
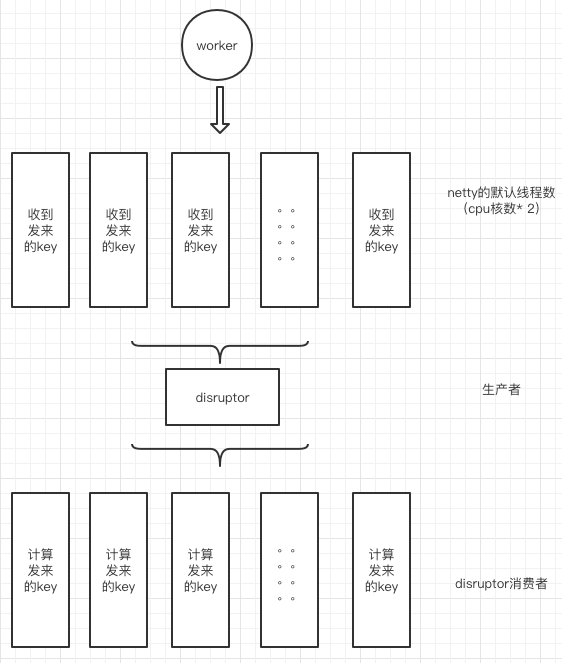
該版本上線后,長連接3千臺業(yè)務(wù)服務(wù)器,單機(jī)每秒處理幾千個key的情況下,cpu占用率在20%多。猛一看,貌似還可以接受的樣子是嗎。
其實不是的,該版本隨后經(jīng)歷了618大促壓測演練,首次壓測,該版本在壓測開始的一瞬間就已經(jīng)生活不能自理了。
首次壓測量級只有10萬,我有4臺worker,平均每臺也就2萬多秒級key寫入,而cpu占用率直接飆升至100%,系統(tǒng)卡的連10s一次的定時任務(wù)都不走了,完全僵死狀態(tài)。
那么問題在哪里?僅通過猜測我們大概考慮是disruptor負(fù)載比較重,譬如是不是因為重復(fù)消費的問題?
要尋找問題在哪里,進(jìn)入容器內(nèi)部,查看top的進(jìn)程id,再使用top -H -p1234(1234為javaa進(jìn)行pid),再使用jstack命令導(dǎo)出java各個線程的狀態(tài)。
在top -H這一步,我們看到有巨多的線程在占用cpu,數(shù)量之多,令見者傷心、聞?wù)呗錅I。
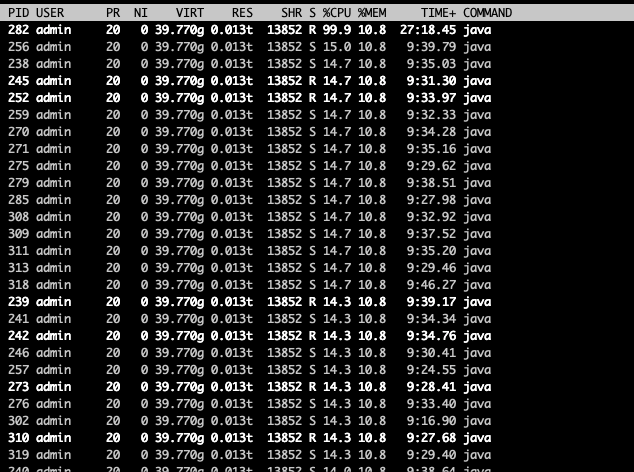
里面有大量的如下
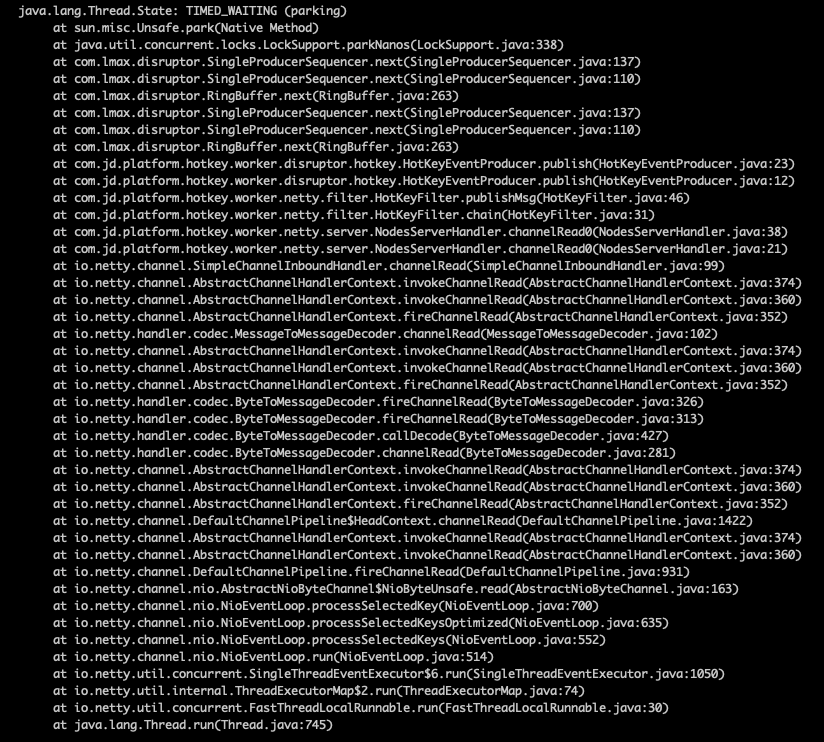
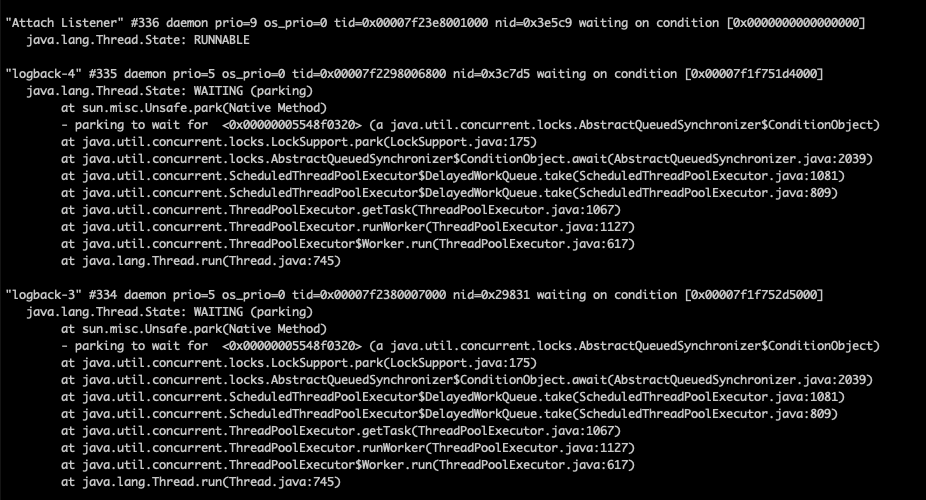
也就是說大量的disruptor消費者線程吃光了cpu,說好的百萬并發(fā)框架disruptor性能呢?
當(dāng)然,這次的鍋不能給disruptor去背。這次的問題首要罪魁禍?zhǔn)资莏dk版本問題,我們使用的1.8.0_20在docker容器內(nèi)通過
Runtime.getRuntime().availableProcessors()方法獲取到的數(shù)量是宿主機(jī)的核數(shù),而不是分配的核數(shù)。
即便只分配這個容器4核8核,該方法取到的卻是宿主機(jī)的32核、64核,直接導(dǎo)致netty默認(rèn)分配的高達(dá)128個線程,disruptor也是128個線程。這幾百個線程一開啟,平時空閑著就占用20%多的cpu,壓測一開始,cpu直接原地起飛,忙于輪轉(zhuǎn),瞬間癱瘓。
# 首次優(yōu)化——10萬QPS
jdk在1.8.0_191之后,修復(fù)了容器內(nèi)獲取cpu核數(shù)的問題,我們首先升級了jdk小版本,然后增加了對不同版本cpu核數(shù)的判斷邏輯,把線程數(shù)降了下來。
這其中我并沒有去修改disruptor所有線程都消費key的邏輯,保持了原樣。也就是說,16核機(jī)器,目前是32個netty IO線程,32個消費者業(yè)務(wù)線程。再次上線,cpu日常占用率降低到7%-10%左右。
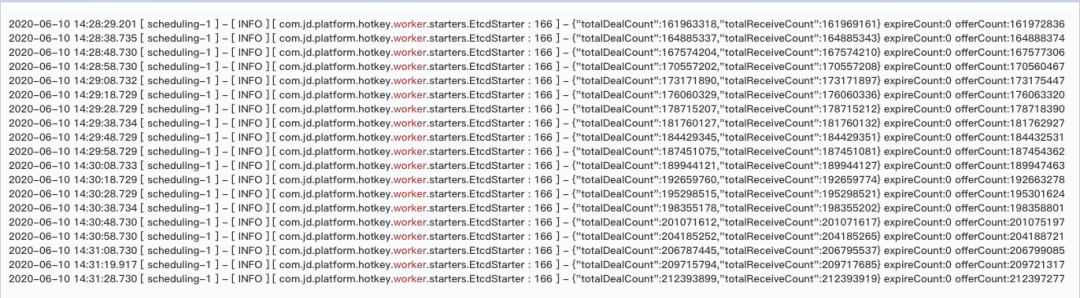
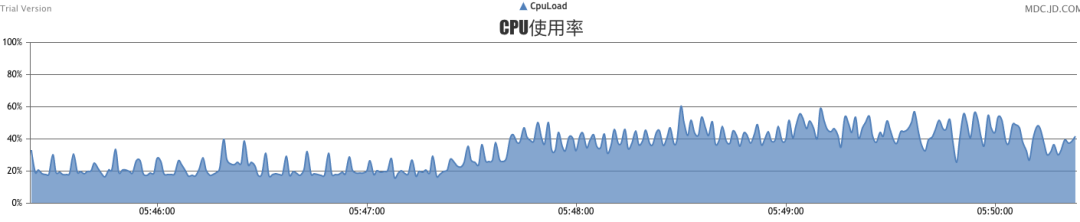
二次壓測開始,從下圖每10秒打印一次的日志來看,單機(jī)秒級計算完畢的key在8萬多,同時秒級推送量在10萬左右。

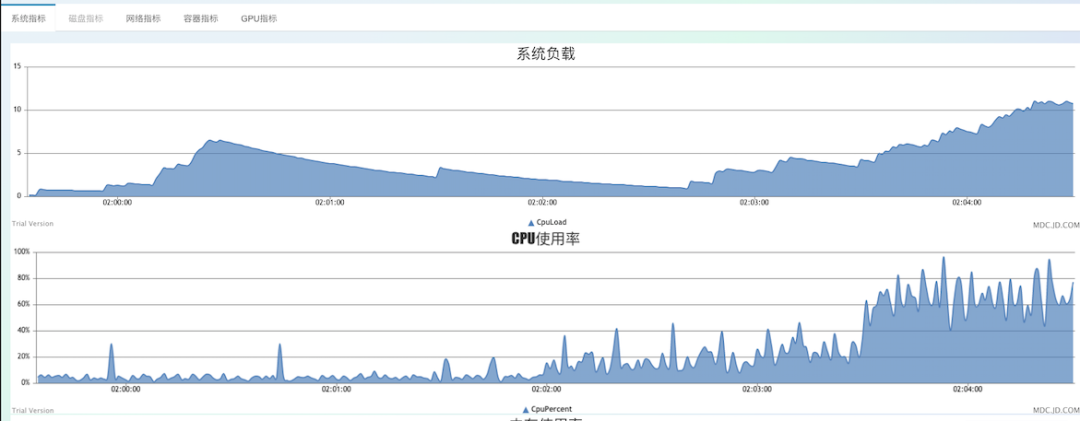
此時cpu已經(jīng)開始飄高了,當(dāng)單機(jī)秒級達(dá)到14萬時,CPU接近跑滿狀態(tài),此時已達(dá)線上平穩(wěn)值上限10萬。其中占用cpu較多的依舊是disruptor大量的線程。
# 二次優(yōu)化——16萬QPS
考慮到線程數(shù)對性能影響還是很大,該應(yīng)用作為純內(nèi)存計算框架,是典型的cpu密集型,根本不需要那么多的線程來做計算。
我大幅調(diào)低了netty的IO線程數(shù)和disruptor線程數(shù),并隨后進(jìn)行了多次實驗。首先netty的IO線程分別為4和8反復(fù)測試,業(yè)務(wù)線程也調(diào)為4和8進(jìn)行反復(fù)測試。
最終得出結(jié)論,netty的IO線程在低于4時,秒級能接收到的key數(shù)量上限較低,4和8時區(qū)別不太大。而業(yè)務(wù)線程在高于8時,cpu占用偏高。尤其是key發(fā)來的量比較少時,線程越多,cpu越高。注意,是發(fā)來的key更少,cpu更高,當(dāng)完全沒有key發(fā)來時,cpu會比有key時更高。
原因在于disruptor它的策略就是會反復(fù)輪詢隊列是否有可消費的數(shù)據(jù),沒有數(shù)據(jù)時,它這個輪詢空耗cpu,即便等待策略是BlockingWaitStrategy。
所以,最終定下了IO線程和業(yè)務(wù)線程分別為8,即核數(shù)的一半。一半用來接收數(shù)據(jù),一半用來做計算。
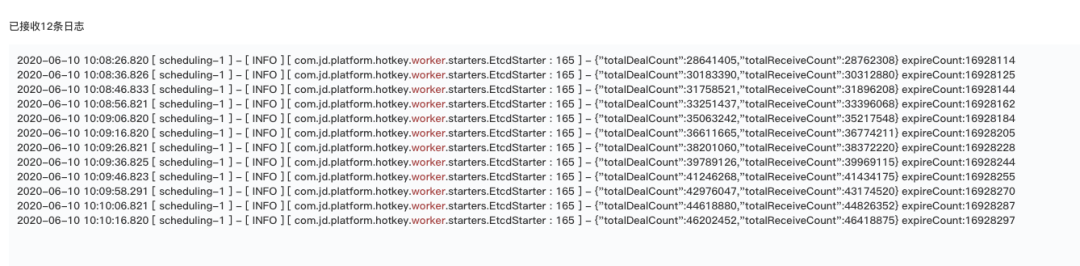
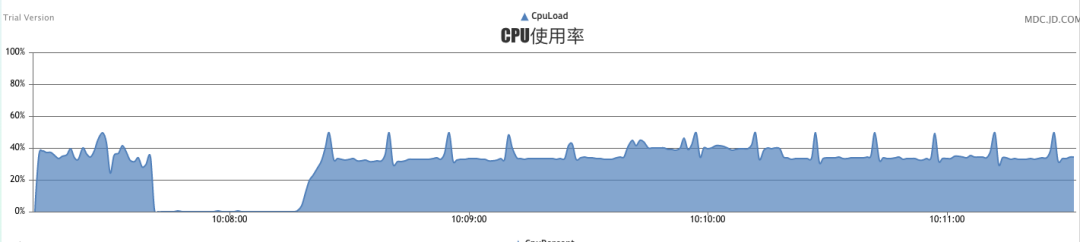
從圖上可以看到,秒級可以處理完畢16萬個key,cpu占用率在40%。
加大壓力源后,實際處理量會繼續(xù)提升,但此時我對disruptor的實際表現(xiàn)并不滿意,總是在每百萬key左右就出現(xiàn)幾個發(fā)來的key在被消費時就已經(jīng)超時(key發(fā)送時比key被處理時超過5秒)的情況。追查原因也無果,就是個別key好像是被遺忘在角落一樣,遲遲未被處理。
# 三次優(yōu)化——25萬QPS
由于對disruptor不滿意,所以這一次直接丟棄了它,改為jdk自帶的LinkedBlockQueue,這是一個讀寫分別加鎖的隊列,比ArrayBlockQueue性能稍好,理論上不如disruptor性能好。
原因大家應(yīng)該都清楚,首先ArrayBlockQueue讀寫同用一把鎖,LinkedBlockQueue是讀一把鎖、寫一把鎖,ArrayBlockQueue肯定是性能不如LinkedBlockQueue。
disruptor采用ringbuffer環(huán)形隊列,如果生產(chǎn)消費速率相當(dāng)情況下,理論上讀寫均無鎖,是生產(chǎn)消費模型里理論上性能最優(yōu)的。然而,一切都要靠場景和最終成績來說話,網(wǎng)上拋開了這些單獨談框架性能其實沒有什么意義。
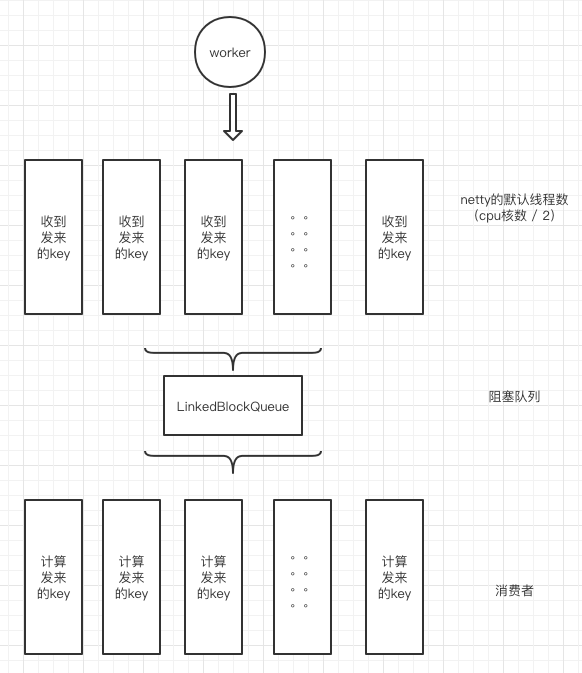
同樣是8線程讀取key然后寫入到隊列,8線程死循環(huán)消費隊列。此時已經(jīng)不會重復(fù)消費了,我采用了別的方式來避免多線程同時計算同一個key的數(shù)量累加問題。
再次上線后,首先非常明顯的變化就是再也沒有key被處理時發(fā)生超時的情況了,之前每百萬必出幾個,而這個Queue幾億也沒一個超時的,每個寫入都會迅速被消費。另一個非常直觀的感受就是cpu占用率明顯下降。
在平時的日常生產(chǎn)環(huán)境,disruptor版在秒級幾千key,3千個長連接情況下,cpu占用在7%-10%之間,不低于5%。而BlockQueue版上線后,日常同等狀態(tài)下,cpu占用率0.5%-1%之間,即便是后來我加入了秒級監(jiān)控這個單線程挺耗資源的邏輯(該邏輯會統(tǒng)計累加所有client每秒的key訪問數(shù)據(jù),單線程cpu占用單核50%以上),cpu占用率也才在1.5%,不超過2%。
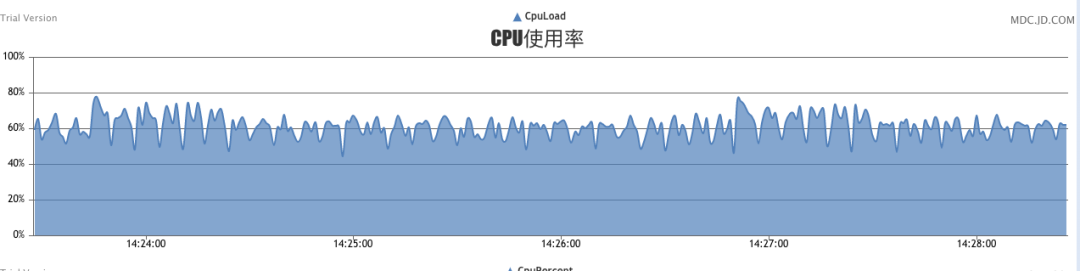
此時壓測可以看到,秒級處理量能達(dá)到25-30萬,cpu占用率在70%。cpu整體處于比較穩(wěn)定的狀態(tài),該壓測持續(xù)N個小時,未見任何異常。
并且該版也進(jìn)行過并發(fā)寫入同時對推送的壓測,穩(wěn)定推送每秒10-12萬次可保持極其穩(wěn)定毫秒級送達(dá)的狀態(tài)。在20萬次時開始出現(xiàn)延遲送達(dá),極限每秒壓至48萬次推送,出現(xiàn)大量延遲,部分送達(dá)至業(yè)務(wù)client時延遲已超過5秒,此時我們認(rèn)為熱key毫秒級推送功能在如此延遲下已不能達(dá)到既定目的。讀寫并行情況下,吞吐量在40萬左右。
這一版也是618大促期間線上運行的版本(秒級監(jiān)控是618后加入的功能)。
# 最近優(yōu)化——35萬QPS
之前所有版本,都是通過fastjson進(jìn)行的序列化和反序列化,兩端通信時交互的對象都是fastjson序列化的字符串,采用netty的StringDecoder進(jìn)行交互。
這種序列化和反序列化方式在平時使用中,性能處于足夠的狀態(tài),幾千幾萬個小對象序列化耗時很少。大家都知道一些其他的序列化方式,如protobuf、msgPack等。
本地測試很容易,搞個只有幾個屬性的對象,做30萬次序列化、反序列化,對比json和protobuf的耗時區(qū)別。30萬次,大概相差個300-500ms的樣子,在量小時幾乎沒什么區(qū)別,但在30萬QPS時,差的就是這幾百ms。
網(wǎng)上相關(guān)評測序列化方式的文章也很多,可以自行找一些看看對比。
在更換序列化方式,修改netty編解碼器后,壓測如圖:
秒級16萬時,cpu大概25%。

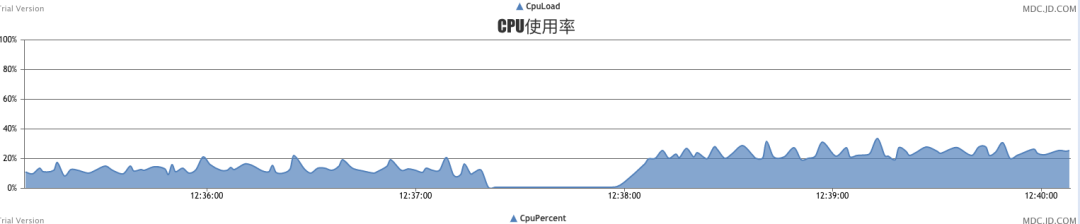
秒級36.5萬時,cpu在50%的樣子。
此時,每秒壓力機(jī)發(fā)來的key在42萬以上,但處理量維持在36萬左右,不能繼續(xù)提升。因為多線程消費LinkedBlockQueue,已達(dá)到該組件性能上限。netty的IO線程尚未達(dá)到接收上限。

# 爭議項
其實從上面的生產(chǎn)消費圖大家都能看出來,所有netty收到的消息都發(fā)到了BlockQueue里,這是唯一的隊列,生產(chǎn)消費者都是多線程,那么必然是存在鎖競爭的。
很多人都會考慮為何不采用8個隊列,每個線程只往一個隊列發(fā),消費者也只消費這一個線程。或者干脆去掉隊列,直接消費netty收到的消息。這樣不就沒有鎖競爭了嗎,性能不就能再次起飛?
這個事情自然我也是多次測試過了,首先通過上面的壓測,我們知道瓶頸是在BlockQueue那里,它一秒被8線程消費了37萬次,已經(jīng)不能再高了,那么8個隊列只要能超過這個數(shù)值,就代表這樣的優(yōu)化是有效的。
然而實際測試結(jié)果并不讓人滿意,分發(fā)到8個隊列后,實際秒級處理量驟降至25萬浮動。至于直接在netty的IO線程做業(yè)務(wù)邏輯,這更不可取,如果不小心可能導(dǎo)致較為嚴(yán)重的積壓,甚至導(dǎo)致客戶端阻塞。
雖然網(wǎng)上很多文章都專門講鎖競爭導(dǎo)致性能下降,避免鎖來提升性能,但在這種30萬以上的場景下,實踐的重要性遠(yuǎn)大于理論。至于為什么會性能變差,就留給大家思考一下吧。
# 后記
可能大家覺得哇塞你這個調(diào)優(yōu)好簡單,我也學(xué)會了,就是減少線程數(shù),那么實際是這樣嗎?
我們再來看看,線程少時導(dǎo)致吞吐量大幅下降的場景。
之前我們的測試都是說每秒收到了多少萬個key,處理了多少萬個key,大部分負(fù)載都是處理key上。現(xiàn)在我們來測試一下純推送量,只接收很少的key,然后讓所有的key都是熱key,開啟很多個客戶端,每秒推送很多次。
測試是這樣的,由一個單獨的client每秒發(fā)送1萬個key到單個worker,設(shè)置變熱規(guī)則為1,那么這1萬個就全是熱key,然后我分別采用40、60、80、100個client端機(jī)器,這樣就意味著每秒單個worker要推送40、60、80、100萬次,通過觀察client端每秒是否接收到了1萬個熱key推送來判斷worker的推送極限。
首先還是使用上面的配置,即8個IO線程,8個消費者線程。

可以看到8線程在每秒推送40萬次時比較穩(wěn)定,在client端打日志也是基本1秒1萬個全部收到,沒有超時的情況。在60萬次時,cpu大幅抖動,大部分能及時推送到達(dá),但開始出現(xiàn)部分超時送達(dá)的情況。上到60萬以上時,系統(tǒng)已不可用,大量的超時,所有信息都超時,開始出現(xiàn)推送積壓,堆外內(nèi)存持續(xù)增長,逐漸內(nèi)存溢出。
調(diào)大IO線程至16,推送量每秒60萬:
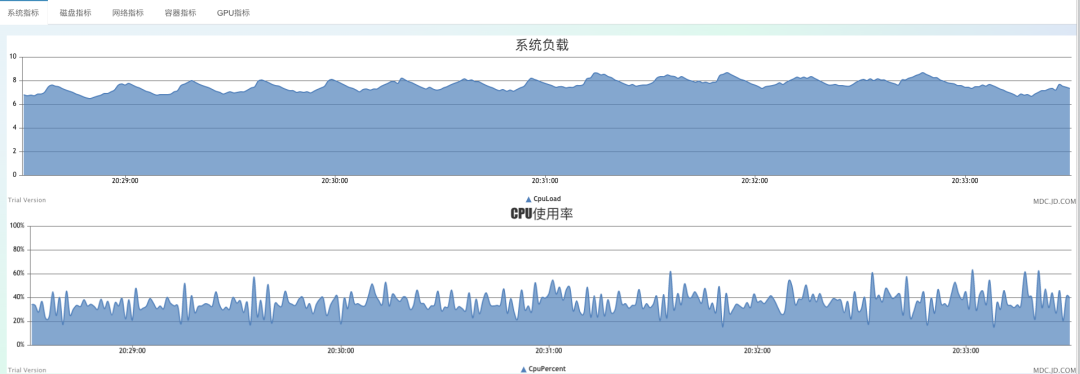
持續(xù)運行較長時間,cpu非常穩(wěn)定,未出現(xiàn)8線程時那種偶爾大幅抖動的情況,穩(wěn)定性比之前的8線程明顯好很多。
隨后我加大到80個客戶端,即每秒推送80萬次。
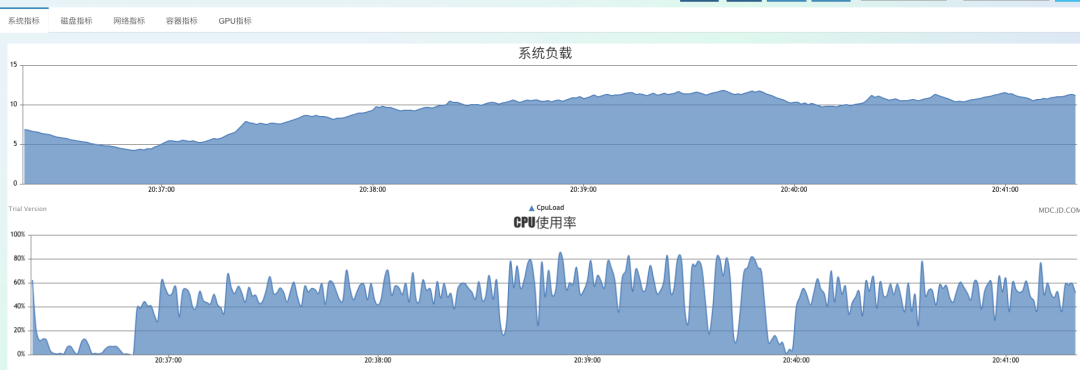
總體還是比較平穩(wěn),cpu來了60%附近,full gc開始變得頻繁起來,幾乎每20秒一次,但并未出現(xiàn)大量的超時情況,只有full gc那一刻,會有個別key在到達(dá)client時超過1秒。系統(tǒng)開始出現(xiàn)不穩(wěn)定的情況。
我加大到100個client,即每秒要推送100萬次。
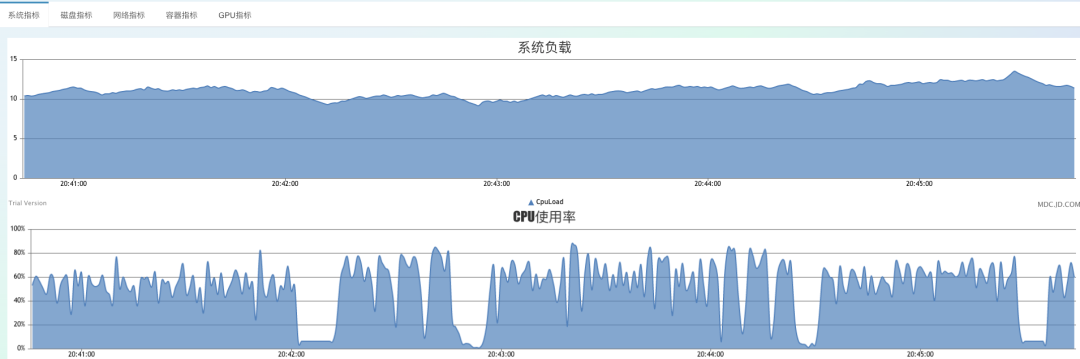
此時系統(tǒng)已經(jīng)明顯不堪重負(fù),full gc非常密集,cpu開始大幅抖動,大量的1秒超時,整體已經(jīng)不可控了,持續(xù)運行后,就會開始出異常,內(nèi)存溢出等問題。
通過對純推送的壓測,發(fā)現(xiàn)更多的IO線程,幾乎可以到達(dá)每秒70萬推送穩(wěn)定,比8線程的時候40多萬穩(wěn)定,強(qiáng)了不是一點點。同樣一臺機(jī)器,僅改了改線程數(shù)量而已。
那么問題又來了,我們應(yīng)該怎么去配置這個線程數(shù)量呢?
那么就有實際場景了,你是到底每秒有很多key要探測、但是熱的不多,還是探測量一般般、但是閾值調(diào)的低、熱key產(chǎn)生多、需要每秒推送很多次。歸根到底,是要把計算資源讓給IO線程多一些,還是消費者線程多一些的問題。
# 總結(jié)
在開發(fā)過程中,遇到了諸多問題,遠(yuǎn)不止上面調(diào)個線程數(shù)那么簡單,對很多數(shù)據(jù)結(jié)構(gòu)、包傳輸、并發(fā)、和客戶端的連接處理很多地方都出過問題,也對很多地方選型做過權(quán)衡,線上以求穩(wěn)為主,穩(wěn)中有性能提升是最好的。
主要的結(jié)論就是一切靠實踐,任何理論、包括書上寫的、博客寫的,很多是靠想象,平時本地運行多久都不出問題,拿到線上,百萬流量一沖擊,各種奇奇怪怪的問題。有些在被沖擊后,過一會能恢復(fù)服務(wù),而有些技術(shù)就不行了,就直接癱瘓只能重啟,甚至于連個異常信息都沒有,就那么安安靜靜的停止響應(yīng)了。
線上真實流量+極端暴力壓測是我們在每一個微小改動后都會去做的事情,力求服務(wù)極端流量不宕機(jī)、不誤判。
目前該框架已在開源中國發(fā)布開源,https://gitee.com/jd-platform-opensource/hotkey,有相關(guān)熱key痛點需求的可以了解一下,有定制化需求,或不滿足自己場景的也可以反饋,我們也在積極采納內(nèi)外部意見建議,共建優(yōu)質(zhì)框架。
來源:https://my.oschina.net/1Gk2fdm43/blog/4533994