
【EMNLP2020】控制對話生成中的specificity
本文介紹一篇2020EMNLP-findings上的論文《Consistent Response Generation with Controlled Specificity》,介紹在對話生成中控制回復(fù)的specificity。
所謂specificity,我把它翻譯成“具體的程度”,舉個例子,我跟機(jī)器說:“今天天真冷”,機(jī)器可以以三種不同的specificity回答我:
- 是的
- 確實挺冷的
- 哎呀 心疼 喝熱水,多穿 快回 外面冷,你忙 好夢 早點睡,早安 晚安 睡了沒,確實冷,多喝熱水注意保暖別著涼了

誰不想要一個像第3種這么貼心的聊天機(jī)器人呢?(
這篇論文其實是作者發(fā)表在2019ACL workshop上的工作《Relevant and Informative Response Generation using Pointwise Mutual Information》的延續(xù)。
這篇論文提出了一個叫做Positive Pointwise Mutual Information(PPMI)的東西,首先使用PPMI給訓(xùn)練集中的每個word打分,找出keywords,設(shè)計了一個loss,鼓勵模型生成屬于keywords的單詞,做法和下面要介紹的論文大同小異。
PPMI的定義如下,為單詞出現(xiàn)在上句中的概率,為單詞出現(xiàn)在回復(fù)中的概率,是單詞和同時分別出現(xiàn)在一對中的概率,這些概率P都可以通過對訓(xùn)練集預(yù)先的統(tǒng)計得到。由此可以得到PPMI矩陣,PPMI[x][y]就是PPMI(x, y)的值,預(yù)先存儲好以供后面模型使用。
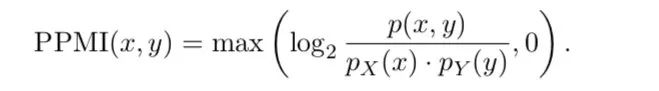
作者進(jìn)一步提出一條數(shù)據(jù)的MaxPMI,定義如下
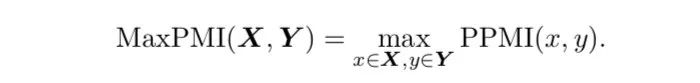
通過min-max normalization將每條數(shù)據(jù)的MaxPMI分?jǐn)?shù)歸一化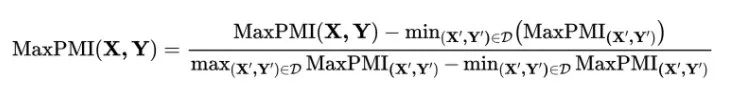
模型的整體架構(gòu)如下
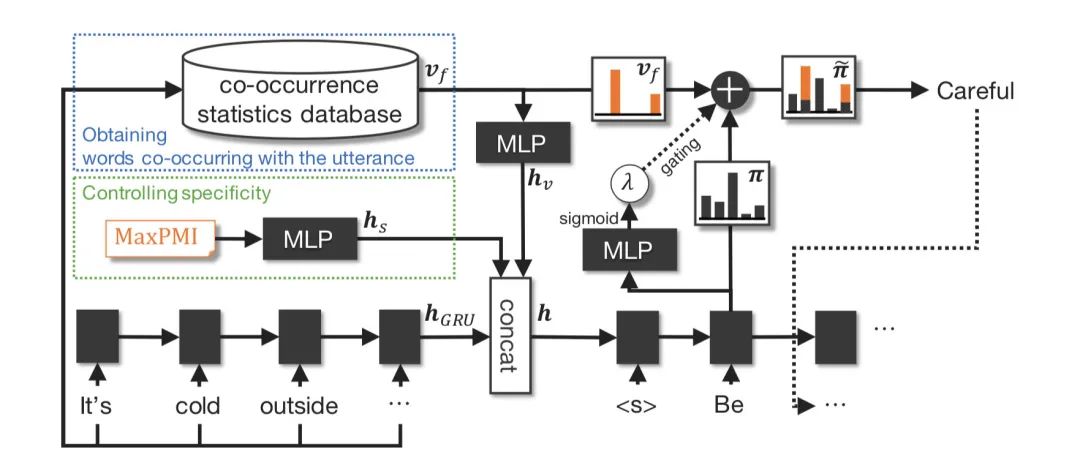 模型架構(gòu)
模型架構(gòu)首先對于一條數(shù)據(jù),使用GRU將utterance?編碼為一個向量,然后把這條數(shù)據(jù)的MaxPMI分?jǐn)?shù)丟到一個多層全連接網(wǎng)絡(luò)里(MLP)輸出一個vector?,接著把整個詞表上的每一個單詞和utterance?中所有的單詞求PPMI分?jǐn)?shù)之和,得到一個長度和詞表大小一樣的vector?,
然后,同樣地把丟到一個多層全連接網(wǎng)絡(luò)中輸出一個vector?,把得到的三個向量給concat起來得到,把h作為decoder的初始狀態(tài),因此decoder應(yīng)該可以利用PPMI所定義的詞與詞之間的共現(xiàn)關(guān)系,來學(xué)習(xí)如何生成更具體specific的回復(fù)。
為了直接地提升decoder輸出更specific的單詞的概率,作者還把和decoder在每個timestep i輸出的概率通過加權(quán)的方式加在了一起得到
用于平衡二者,由decoder當(dāng)前輸出的隱狀態(tài)通過一層MLP得出
Inference階段只需要手動定義MaxPMI的值s,就可以生成不同specificity程度的回復(fù)。同時作者還提出inference不手動提供值s的方法,可使用下式自動求出的值,是整個詞表,是給出的問句
作者的實驗在DailyDialog和Twitter(Japanese)上進(jìn)行,對比的模型是SC-Seq2Seq,它出自ACL2018上的《Learning to Control the Specificity in Neural Response Generation》,同樣是控制生成的,最大的區(qū)別可能在于本文用的是作者定義的PPMI,那篇也是作者定義了一個指標(biāo),并提前告訴decoder每個詞的得分。
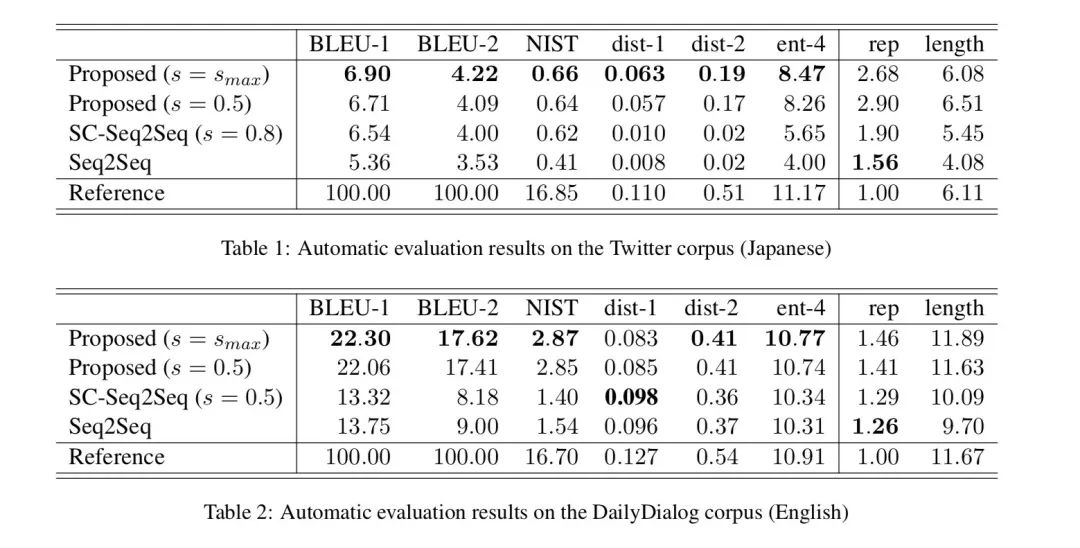
作者發(fā)現(xiàn)使用的效果最好
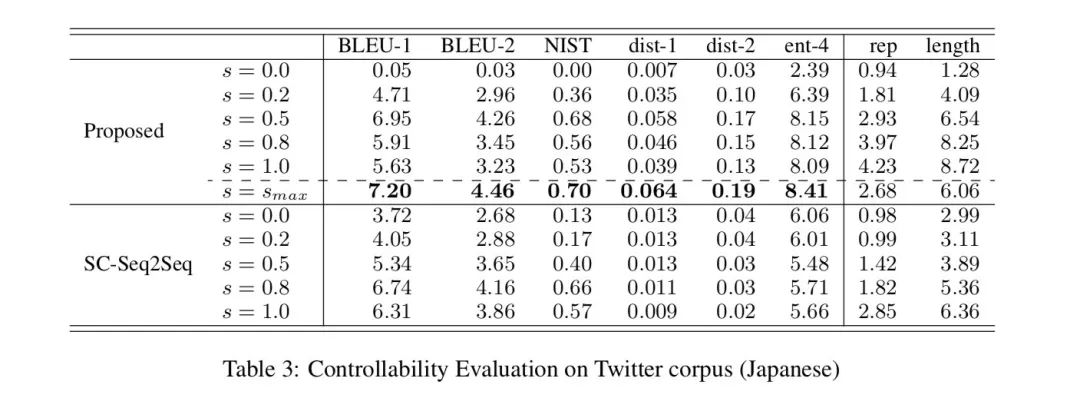
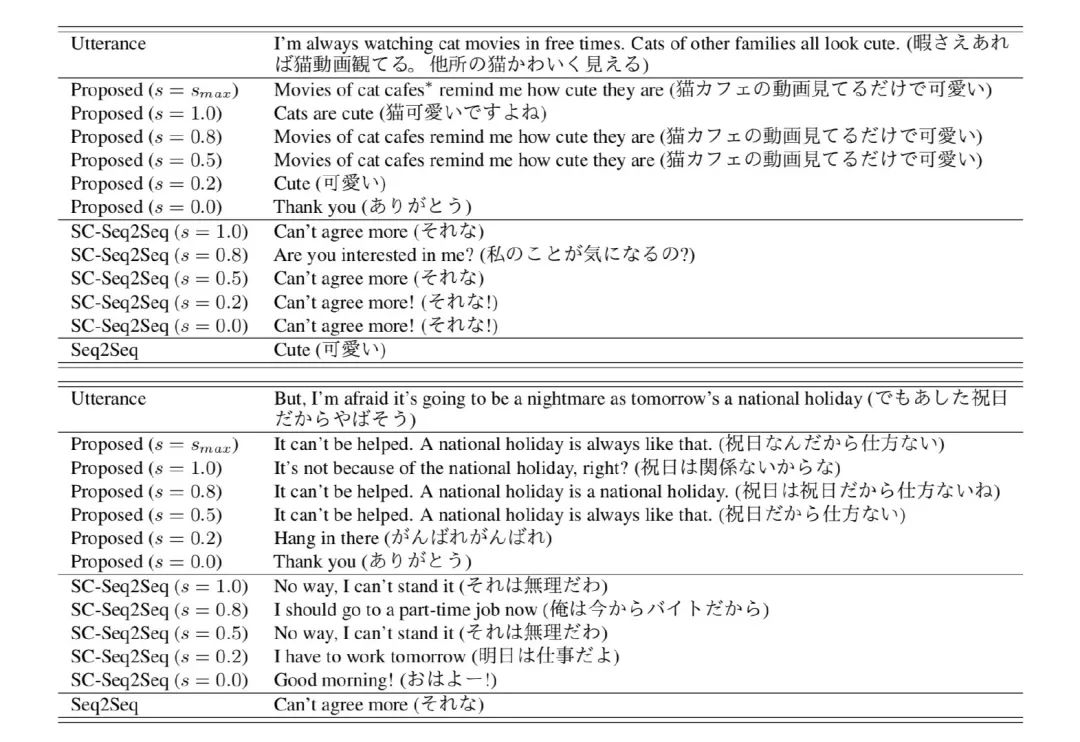
作者也舉了一個生成效果的例子,通過控制s的大小可以操控回復(fù)的specificity
有什么想法歡迎在評論區(qū)討論,掃碼關(guān)注加星標(biāo)以第一時間獲得推送文章~