
Spark性能調(diào)優(yōu)指北:性能優(yōu)化和故障處理
一、Spark 性能優(yōu)化
生產(chǎn)環(huán)境 Spark submit 腳本
\--class com.atguigu.spark.WordCount \--num-executors 80 \--driver-memory 6g \--executor-memory 6g \--executor-cores 3 \--master yarn \--deploy-mode cluster \--queue root.default \--conf spark.yarn.executor.memoryOverhead=2048 \--conf spark.core.connection.ack.wait.timeout=300 \/usr/local/spark/spark.jar

RDD 優(yōu)化
RDD 復(fù)用,避免相同的算子和計(jì)算邏輯之下對 RDD 進(jìn)行重復(fù)的計(jì)算
RDD 持久化,對多次使用的 RDD 進(jìn)行持久化,將 RDD 緩存到內(nèi)存/磁盤中,之后對于 該RDD 的計(jì)算都會從內(nèi)存/磁盤中直接獲取。
RRD 盡可能早的進(jìn)行 filter 操作。
并行調(diào)節(jié)
Spark 官方推薦,Task 數(shù)量應(yīng)該設(shè)置為 Spark 作業(yè)總 CPU core 數(shù)量的 2~3 倍。
val conf = new SparkConf().set("spark.default.parallelism", "500")廣播大變量
Task 中的算子中如果使用了外部的變量,每個(gè) Task 都會緩存這個(gè)變量的副本,造成了內(nèi)存的極大消耗。而廣播變量在可以在每個(gè) Executor 中保存一個(gè)副本,此 Executor 的所有 Task 共用此廣播變量,這讓變量產(chǎn)生的副本數(shù)量大大減少。
廣播變量起初在 Driver 中,Task 在運(yùn)行時(shí)會首先在自己本地的 Executor 上的 BlockManager 中嘗試獲取變量,如果本地沒有,BlockManager 會從 Driver 中遠(yuǎn)程拉取變量的副本,之后 Executor 的所有 Task 都會直接從 BlockManager 中獲取變量。
Kryo 序列化
Spark 默認(rèn)使用 Java 的序列化機(jī)制。而 Kryo 序列化機(jī)制比 Java 序列化機(jī)制性能提高10倍左右,但 Kryo 序列化不支持所有對象的序列化,并且需要用戶在使用前注冊需要序列化的類型,不夠方便,但從 Spark 2.0.0 版本開始,簡單類型、簡單類型數(shù)組、字符串類型的Shuffling RDDs 已經(jīng)默認(rèn)使用 Kryo 序列化方式了。
public class MyKryoRegistrator implements KryoRegistrator{@Overridepublic void registerClasses(Kryo kryo){kryo.register(StartupReportLogs.class);}}//創(chuàng)建SparkConf對象val conf = new SparkConf().setMaster(…).setAppName(…)//使用Kryo序列化庫,如果要使用Java序列化庫,需要把該行屏蔽掉conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");//在Kryo序列化庫中注冊自定義的類集合,如果要使用Java序列化庫,需要把該行屏蔽掉conf.set("spark.kryo.registrator", "atguigu.com.MyKryoRegistrator");
調(diào)節(jié)本地化等待時(shí)間
網(wǎng)絡(luò)傳輸會嚴(yán)重影響性能,所以可以設(shè)置調(diào)節(jié)本地化等待的時(shí)間,若等待某個(gè)時(shí)長后,目標(biāo)節(jié)點(diǎn)處理完了一部分 Task,當(dāng)前的 Task 將有機(jī)會得到執(zhí)行。
Spark本地化等級

在 Spark 項(xiàng)目開發(fā)階段,可以使用 client 模式對程序進(jìn)行測試,此時(shí),可以在本地看到比較全的日志信息,日志信息中有明確的 Task 數(shù)據(jù)本地化的級別,如果大部分都是 PROCESS_LOCAL,那么就無需進(jìn)行調(diào)節(jié),但是如果發(fā)現(xiàn)很多的級別都是 NODE_LOCAL、ANY,那么需要對本地化的等待時(shí)長進(jìn)行調(diào)節(jié),通過延長本地化等待時(shí)長,看看 Task 的本地化級別有沒有提升,并觀察 Spark 作業(yè)的運(yùn)行時(shí)間有沒有縮短。注意,過猶不及,不要將本地化等待時(shí)長延長地過長,導(dǎo)致因?yàn)榇罅康牡却龝r(shí)長,使得 Spark 作業(yè)的運(yùn)行時(shí)間反而增加了。
val conf = new SparkConf().set("spark.locality.wait", "6")1.2 算子調(diào)優(yōu)
mapPatitions
普通的 map 算子對 RDD 中的每一個(gè)元素進(jìn)行操作,而 mapPartitions 算子對 RDD 中每一個(gè)分區(qū)進(jìn)行操作。
比如,當(dāng)要把 RDD 中的所有數(shù)據(jù)通過 JDBC 寫入數(shù)據(jù),如果使用 map 算子,那么需要對 RDD 中的每一個(gè)元素都創(chuàng)建一個(gè)數(shù)據(jù)庫連接,這樣對資源的消耗很大,如果使用mapPartitions算子,那么針對一個(gè)分區(qū)的數(shù)據(jù),只需要建立一個(gè)數(shù)據(jù)庫連接。
缺點(diǎn):普通 map 算子,可以將已處理完的數(shù)據(jù)及時(shí)的回收掉,但使用 mapPartitions 算子,當(dāng)數(shù)據(jù)量非常大時(shí),function 一次處理一個(gè)分區(qū)的數(shù)據(jù),如果一旦內(nèi)存不足,此時(shí)無法回收內(nèi)存,就可能會 OOM,即內(nèi)存溢出。在項(xiàng)目中,應(yīng)該首先估算一下 RDD 的數(shù)據(jù)量、每個(gè) partition 的數(shù)據(jù)量,以及分配給每個(gè) Executor 的內(nèi)存資源,如果資源允許,可以考慮使用 mapPartitions 算子代替 map。
foreachPartition 優(yōu)化數(shù)據(jù)庫操作
在生產(chǎn)環(huán)境中,通常使用 foreachPartition 算子來完成數(shù)據(jù)庫的寫入,通過 foreachPartition 算子的特性,可以優(yōu)化寫數(shù)據(jù)庫的性能。
foreachPartition 算子 與 mapPartitions 算子類似,如果一個(gè)分區(qū)的數(shù)據(jù)量特別大,可能會造成OOM,即內(nèi)存溢出。
filter 與 coalsce 的配合使用
使用 filter 算子完成 RDD 中數(shù)據(jù)的過濾,但是 filter 過濾后,每個(gè)分區(qū)的數(shù)據(jù)量有可能會存在較大差異,造成數(shù)據(jù)傾。此時(shí)使用 coalesce 算子,壓縮分區(qū)數(shù)量,而且讓每個(gè)分區(qū)的數(shù)據(jù)量盡量均勻緊湊,便于后面的 Task 進(jìn)行計(jì)算操作。
repartition 與 coalesce 都可以用來進(jìn)行重分區(qū),其中 repartition 只是 coalesce 接口中 shuffle 為 true 的簡易實(shí)現(xiàn),coalesce 默認(rèn)情況下不進(jìn)行 shuffle,但是可以通過參數(shù)進(jìn)行設(shè)置。
repartition 解決 SparkSQL 低并行度問題
并行度的設(shè)置對于 Spark SQL 是不生效的,用戶設(shè)置的并行度只對于 Spark SQL 以外的所有 Spark 的 stage 生效。Spark SQL 自己會默認(rèn)根據(jù) hive 表對應(yīng)的 HDFS 文件的 split 個(gè)數(shù)自動(dòng)設(shè)置 Spark SQL 所在的那個(gè) stage 的并行度,Spark SQL自動(dòng)設(shè)置的 Task 數(shù)量很少。
Spark SQL 查詢出來的 RDD,立即使用 repartition 算子重新分區(qū)為多個(gè) partition,從 repartition 之后的 RDD 操 作的并行度就會提高。
reduceByKey 預(yù)聚合
reduceByKey 相較于普通的 shuffle 操作一個(gè)顯著的特點(diǎn)就是會進(jìn)行 map 端的本地聚合,map 端會先對本地的數(shù)據(jù)進(jìn)行 combine 操作。故我們可以考慮使用 reduceByKey 代替其他的 Shuffle 算子,比如 groupByKey。
reduceByKey 對性能的提升如下:1. 本地聚合后,在 map 端的數(shù)據(jù)量變少,減少了磁盤IO;2. 本地聚合后,下一個(gè) stage 拉取的數(shù)據(jù)量變少,減少了網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)量;3. 本地聚合后,在 reduce 端進(jìn)行數(shù)據(jù)緩存的內(nèi)存占用減少;4. 本地聚合后,在 reduce 端進(jìn)行聚合的數(shù)據(jù)量減少。
1.3 JVM 調(diào)優(yōu)
對于 JVM 調(diào)優(yōu),首先應(yīng)該明確,full gc/minor gc,都會導(dǎo)致 JVM 的工作線程停止工作,即 stop the world。
降低 cache 操作的內(nèi)存占比
靜態(tài)內(nèi)存管理
在 Spark UI 中可以查看每個(gè) stage 的運(yùn)行情況,包括每個(gè) Task 的運(yùn)行時(shí)間、gc 時(shí)間等等,如果發(fā)現(xiàn) gc 太頻繁,時(shí)間太長,可以考慮調(diào)節(jié) Storage 的內(nèi)存占比,讓 Task 執(zhí)行算子函數(shù)式,有更多的內(nèi)存可以使用。Storage 內(nèi)存區(qū)域可以通過 spark.storage.memoryFraction 參數(shù)進(jìn)行指定,默認(rèn)為0.6,即60%,可以逐級向下遞減。
val conf = new SparkConf().set("spark.storage.memoryFraction", "0.4")統(tǒng)一內(nèi)存管理
Storage 主要用于緩存數(shù)據(jù),Execution 主要用于緩存在 shuffle 過程中產(chǎn)生的中間數(shù)據(jù),兩者所組成的內(nèi)存部分稱為統(tǒng)一內(nèi)存,Storage和Execution各占統(tǒng)一內(nèi)存的50%,由于動(dòng)態(tài)占用機(jī)制的實(shí)現(xiàn),shuffle 過程需要的內(nèi)存過大時(shí),會自動(dòng)占用 Storage 的內(nèi)存區(qū)域,因此無需手動(dòng)進(jìn)行調(diào)節(jié)。
調(diào)節(jié) Executor 堆外內(nèi)存
有時(shí) Spark 作業(yè)處理的數(shù)據(jù)量非常大,達(dá)到幾億的數(shù)據(jù)量,此時(shí)運(yùn)行 Spark 作業(yè)會時(shí)不時(shí)地報(bào)錯(cuò),例如 shuffle output file cannot find,executor lost,task lost,out of memory 等,這可能是 Executor 的堆外內(nèi)存不太夠用,導(dǎo)致 Executor 在運(yùn)行的過程中內(nèi)存溢出。
默認(rèn)情況下,Executor 堆外內(nèi)存上限大概為 300MB,在實(shí)際的生產(chǎn)環(huán)境下,對海量數(shù)據(jù)進(jìn)行處理的時(shí)候,這里都會出現(xiàn)問題,導(dǎo)致 Spark 作業(yè)反復(fù)崩潰,無法運(yùn)行,此時(shí)就會去調(diào)節(jié)這個(gè)參數(shù),到至少1G,甚至于2G、4G。
# Executor 堆外內(nèi)存的配置需要在 spark-submit 腳本里配置。--conf spark.yarn.executor.memoryOverhead=2048
調(diào)節(jié)連接等待時(shí)長
遇到 file not found、file lost 這類錯(cuò)誤,在這種情況下,很有可能是 Executor 的 BlockManager 在拉取數(shù)據(jù)的時(shí)候,無法建立連接,然后超過默認(rèn)的連接等待時(shí)長 60s 后,宣告數(shù)據(jù)拉取失敗,如果反復(fù)嘗試都拉取不到數(shù)據(jù),可能會導(dǎo)致 Spark 作業(yè)的崩潰。此時(shí)調(diào)節(jié)連接的等待時(shí)長,通常可以避免部分的XX文件拉取失敗、XX文件 lost 等報(bào)錯(cuò)。
# 連接等待時(shí)長需要在 spark-submit 腳本中進(jìn)行設(shè)置。--conf spark.core.connection.ack.wait.timeout=300
數(shù)據(jù)傾斜的表現(xiàn):
Spark 作業(yè)的大部分 task 都執(zhí)行迅速,只有有限的幾個(gè)task執(zhí)行的非常慢,此時(shí)可能出現(xiàn)了數(shù)據(jù)傾斜,作業(yè)可以運(yùn)行,但是運(yùn)行得非常慢;
Spark 作業(yè)的大部分task都執(zhí)行迅速,但是有的task在運(yùn)行過程中會突然報(bào)出OOM,反復(fù)執(zhí)行幾次都在某一個(gè)task報(bào)出OOM錯(cuò)誤,此時(shí)可能出現(xiàn)了數(shù)據(jù)傾斜,作業(yè)無法正常運(yùn)行。
定位數(shù)據(jù)傾斜問題:
查閱代碼中的 shuffle 算子,例如 reduceByKey、countByKey、groupByKey、join等算子,根據(jù)代碼邏輯判斷此處是否會出現(xiàn)數(shù)據(jù)傾斜;
查看 Spark 作業(yè)的 log 文件,log 文件對于錯(cuò)誤的記錄會精確到代碼的某一行,可以根據(jù)異常定位到的代碼位置來明確錯(cuò)誤發(fā)生在第幾個(gè)stage,對應(yīng)的 shuffle 算子是哪一個(gè);
2.1 Shuffle 調(diào)優(yōu)
調(diào)節(jié) map 端緩沖區(qū)大小
通過調(diào)節(jié) map 端緩沖的大小,可以避免頻繁的磁盤 IO 操作。map 端緩沖的默認(rèn)配置是32KB,如果每個(gè) Task 處理640KB 的數(shù)據(jù),那么會發(fā)生 640/32 = 20次溢寫,這對于性能的影響是非常嚴(yán)重的。map 端緩沖區(qū)的大小可以通過 spark.shuffle.file.buffer 參數(shù)進(jìn)行設(shè)置定。
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64")調(diào)節(jié) reduce 端拉取數(shù)據(jù)緩沖區(qū)大小
適當(dāng)增加拉取數(shù)據(jù)緩沖區(qū)的大小,可以減少拉取數(shù)據(jù)的次數(shù),也就可以減少網(wǎng)絡(luò)傳輸?shù)拇螖?shù)。reduce 端數(shù)據(jù)拉取緩沖區(qū)的大小可以通過 spark.reducer.maxSizeInFlight 參數(shù)進(jìn)行設(shè)置,默認(rèn)為 48MB。
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "96")調(diào)節(jié) reduce 端拉取數(shù)據(jù)重試次數(shù)
reduce task 拉取屬于自己的數(shù)據(jù)時(shí),如果因?yàn)榫W(wǎng)絡(luò)異常等原因?qū)е率詣?dòng)進(jìn)行重試。對于那些包含了特別耗時(shí)的 shuffle 操作的作業(yè),建議增加重試最大次數(shù)(比如60次),調(diào)節(jié)該參數(shù)可以大幅度提升穩(wěn)定性。reduce 端拉取數(shù)據(jù)重試次數(shù)可以通過 spark.shuffle.io.maxRetries 參數(shù)進(jìn)行設(shè)置,默認(rèn)為 3 次。
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "6")調(diào)節(jié) reduce 端拉取數(shù)據(jù)等待間隔
reduce 端拉取數(shù)據(jù)等待間隔可以通過 spark.shuffle.io.retryWait 參數(shù)進(jìn)行設(shè)置,默認(rèn)值為5s
val conf = new SparkConf().set("spark.shuffle.io.retryWait", "60s")調(diào)節(jié) SortShuffle 排序操作閾值
對于 SortShuffleManager,如果 shuffle reduce task 的數(shù)量小于某一閾值則 shuffle write 過程中不會進(jìn)行排序操作,而是直接按照未經(jīng)優(yōu)化的 HashShuffleManager 的方式去寫數(shù)據(jù)。
當(dāng)使用 SortShuffleManager 時(shí),如果的確不需要排序操作,建議將這個(gè)參數(shù)調(diào)大一些,大于 shuffle read task 的數(shù)量,此時(shí) map-side 就不會進(jìn)行排序,減少了排序的性能開銷,但是這種方式下,依然會產(chǎn)生大量的磁盤文件,因此 shuffle write 性能有待提高。排序操作閾值可以通過 spark.shuffle.sort. bypassMergeThreshold 參數(shù)進(jìn)行設(shè)置,默認(rèn)值為200。
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")2.2 聚合原數(shù)據(jù)
避免 shuffle 過程
為了避免數(shù)據(jù)傾斜,可以考慮避免 shuffle 過程,如果避免了shuffle過程,就從根本上消除了數(shù)據(jù)傾斜問題的可能。
如果 Spark 作業(yè)的數(shù)據(jù)來源于 Hive 表,那么可以先在 Hive 表中對數(shù)據(jù)進(jìn)行聚合,例如按照 key 進(jìn)行分組,將同一key 對應(yīng)的所有 value 用一種特殊的格式拼接到一個(gè)字符串里去,這樣一個(gè) key 就只有一條數(shù)據(jù)了;之后對一個(gè) key 的所有 value 進(jìn)行處理時(shí),只需要進(jìn)行 map 操作即可,無需再進(jìn)行任何的 shuffle 操作。通過上述方式就避免了執(zhí)行 shuffle 操作,也就不可能會發(fā)生任何的數(shù)據(jù)傾斜問題。
對于 Hive 表中數(shù)據(jù)的操作,不一定是拼接成一個(gè)字符串,也可以是直接對 key 的每一條數(shù)據(jù)進(jìn)行累計(jì)計(jì)算。
改變 Key 的粒度
在具體的場景下,可以考慮擴(kuò)大或縮小 key 的聚合粒度,可以減輕數(shù)據(jù)傾斜的現(xiàn)象。
例如,目前有10萬條用戶數(shù)據(jù),當(dāng)前 key 的粒度是(省,城市,區(qū),日期),現(xiàn)在我們考慮擴(kuò)大粒度,將 key 的粒度擴(kuò)大為(省,城市,日期),這樣 key 的數(shù)量會減少,key 之間的數(shù)據(jù)量差異也有可能會減少。
過濾導(dǎo)致傾斜的 key
在 Spark 作業(yè)過程中出現(xiàn)的異常數(shù)據(jù),比如 null 值,將可能導(dǎo)致數(shù)據(jù)傾斜,此時(shí)濾除可能導(dǎo)致數(shù)據(jù)傾斜的 key 對應(yīng)的數(shù)據(jù),這樣就不會發(fā)生數(shù)據(jù)傾斜了。
提高 shuffle 操作中的 reduce 并行度
增加 reduce 端并行度可以增加 reduce 端 Task 的數(shù)量,每個(gè) Task 分配到的數(shù)據(jù)量就會相應(yīng)減少,從而緩解數(shù)據(jù)傾斜。
reduce 端并行度的設(shè)置
部分 shuffle 算子中可以傳入并行度的設(shè)置參數(shù),比如 reduceByKey(500),這個(gè)參數(shù)會決定 shuffle 過程中 reduce端的并行度。
對于 group by、join 等算子,需要設(shè)置參數(shù) spark.sql.shuffle.partitions,該參數(shù)代表 shuffle read task 的并行度,默認(rèn)是200,對于很多場景來說都有點(diǎn)過小。
reduce 端并行度設(shè)置存在的缺陷
提高 reduce 端并行度并沒有從根本上改變數(shù)據(jù)傾斜的本質(zhì)和問題,只是盡可能地去緩解和減輕 shuffle reduce task 的數(shù)據(jù)壓力,以及數(shù)據(jù)傾斜的問題,適用于有較多 key 對應(yīng)的數(shù)據(jù)量都比較大的情況。
比如,某個(gè) key 對應(yīng)的數(shù)據(jù)量有100萬,那么無論你的 Task 數(shù)量增加到多少,這個(gè)對應(yīng)著100萬數(shù)據(jù)的 key 肯定還是會分配到一個(gè) Task 中去處理。
使用隨機(jī) key 實(shí)現(xiàn)雙重聚合
當(dāng)使用類似 groupByKey、reduceByKey 這樣的算子時(shí),可以考慮使用隨機(jī) key 實(shí)現(xiàn)雙重聚合。
首先,通過 map 算子給每個(gè)數(shù)據(jù)的 key 添加隨機(jī)數(shù)前綴,對 key 進(jìn)行打散,將原先一樣的 key 變成不一樣的 key,然后進(jìn)行第一次聚合,這樣就可以讓原本被一個(gè) Task 處理的數(shù)據(jù)分散到多個(gè) Task 上去做局部聚合;隨后,去除掉每個(gè) key 的前綴,再次進(jìn)行聚合。
此方法對于由 groupByKey、reduceByKey 這類算子造成的數(shù)據(jù)傾斜有比較好的效果。如果是 join 類的 shuffle 操作,還得用其他的解決方案。
將 reduce join 轉(zhuǎn)換為 map join
正常情況下 join 操作會執(zhí)行 shuffle 過程,并且執(zhí)行的是 reduce join,先將所有相同的 key 和對應(yīng)的 value 匯聚到一個(gè) reduce task 中,然后再進(jìn)行 join。
但是如果一個(gè) RDD 是比較小的,則可以 采用廣播小RDD全量數(shù)據(jù)+map算子 來實(shí)現(xiàn)與 join 同樣的效果,也就是 map join,此時(shí)就不會發(fā)生 shuffle 操作,也就不會發(fā)生數(shù)據(jù)傾斜。
注意:RDD 是并不能進(jìn)行廣播的,只能將 RDD 內(nèi)部的數(shù)據(jù)通過 collect 拉取到 Driver 內(nèi)存然后再進(jìn)行廣播。并且如果將一個(gè)數(shù)據(jù)量比較大的 RDD 做成廣播變量,那么很有可能會造成內(nèi)存溢出。
sample 采樣對傾斜 key 單獨(dú)進(jìn)行 join
如果某個(gè) RDD 只有一個(gè) key,在 shuffle 過程中會默認(rèn)將此 key 對應(yīng)的數(shù)據(jù)打散,由不同的 reduce 端 task 處理。
所以, 當(dāng)由單個(gè) key 導(dǎo)致數(shù)據(jù)傾斜時(shí),可有將發(fā)生數(shù)據(jù)傾斜的 key 單獨(dú)提取出來,組成一個(gè) RDD,然后用這個(gè)原本會導(dǎo)致傾斜的 key 組成的 RDD 跟其他 RDD 單獨(dú) join,此時(shí),根據(jù) Spark 的運(yùn)行機(jī)制,此 RDD 中的數(shù)據(jù)會在 shuffle 階段被分散到多個(gè) Task 中去進(jìn)行 join 操作。
對于 RDD 中的數(shù)據(jù),可以將其轉(zhuǎn)換為一個(gè)中間表,或者使用 countByKey() 的方式,查看這個(gè) RDD 中各個(gè) key 對應(yīng)的數(shù)據(jù)量,此時(shí)如果你發(fā)現(xiàn)整個(gè) RDD 就一個(gè) key 的數(shù)據(jù)量特別多,那么就可以考慮使用這種方法。
當(dāng)數(shù)據(jù)量非常大時(shí),可以考慮使用 sample 采樣獲取 10% 的數(shù)據(jù),然后分析這 10% 的數(shù)據(jù)中哪個(gè) key 可能會導(dǎo)致數(shù)據(jù)傾斜,然后將這個(gè) key 對應(yīng)的數(shù)據(jù)單獨(dú)提取出來。
如果一個(gè) RDD 中導(dǎo)致數(shù)據(jù)傾斜的 key 很多,那么此方案不適用。
使用隨機(jī)數(shù)以及擴(kuò)容進(jìn)行 join
如果在進(jìn)行 join 操作時(shí),RDD 中有大量的 key 導(dǎo)致數(shù)據(jù)傾斜,那么進(jìn)行分拆 key 也沒什么意義,此時(shí)就可以使用擴(kuò)容的方式來解決。
選擇一個(gè) RDD,使用 flatMap 進(jìn)行擴(kuò)容,對每條數(shù)據(jù)的 key 添加數(shù)值前綴(1~N的數(shù)值),將一條數(shù)據(jù)映射為多條數(shù)據(jù)(擴(kuò)容);選擇另外一個(gè)RDD,進(jìn)行 map 映射操作,每條數(shù)據(jù)的 key 都打上一個(gè)隨機(jī)數(shù)作為前綴(1~N的隨機(jī)數(shù))(稀釋)。
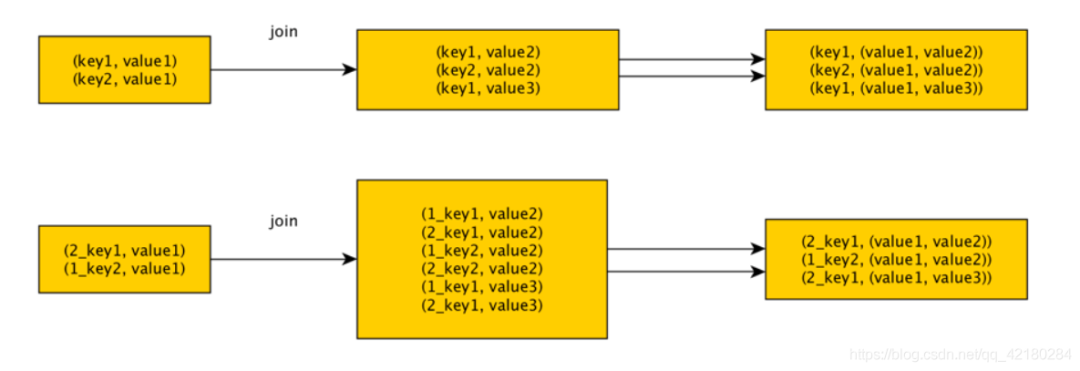
缺點(diǎn):如果兩個(gè) RDD 都很大,那么將 RDD 進(jìn)行 N倍 的擴(kuò)容顯然行不通;使用擴(kuò)容的方式只能緩解數(shù)據(jù)傾斜,不能徹底解決數(shù)據(jù)傾斜問題。
控制 reduce 端緩沖大小以避免 OOM
在 Shuffle 過程,reduce 端 Task 并不是等到 map 端 Task 將其數(shù)據(jù)全部寫入磁盤后再去拉取,而是 map 端寫一點(diǎn)數(shù)據(jù),reduce 端 Task 就會拉取一小部分?jǐn)?shù)據(jù)。
增大 reduce 端緩沖區(qū)大小可以減少拉取次數(shù),提升 shuffle 性能。
但是有時(shí) map 端的數(shù)據(jù)量非常大,寫出的速度非常快,此時(shí) reduce 端的所有 Task 都在拉取數(shù)據(jù),且全部達(dá)到緩沖的最大值,即 48MB,再加上 reduce 端執(zhí)行的聚合函數(shù)的代碼,會創(chuàng)建大量的對象,這可能導(dǎo)致內(nèi)存溢出,即OOM。
一旦出現(xiàn) reduce 端內(nèi)存溢出的問題,可以考慮減小 reduce 端拉取數(shù)據(jù)緩沖區(qū)的大小,例如減少為 12MB。這是典型的以性能換時(shí)間的原理。reduce 端拉取數(shù)據(jù)的緩沖區(qū)減小,不容易導(dǎo)致OOM,但是相應(yīng)的 reudce 端的拉取次數(shù)增加,造成更多的網(wǎng)絡(luò)傳輸開銷,造成性能的下降。在開發(fā)中還是要保證任務(wù)能夠運(yùn)行,再考慮性能的優(yōu)化。
JVM GC 導(dǎo)致的 shuffle 文件拉取失敗
在 Shuffle 過程中,后面 stage 的 Task 想要去上一個(gè) stage 的 Task 所在的 Executor 拉取數(shù)據(jù),結(jié)果對方正在執(zhí)行GC。BlockManager、netty 的網(wǎng)絡(luò)通信都會停止工作,就會導(dǎo)致報(bào)錯(cuò) shuffle file not found,但是第二次再次執(zhí)行就不會再出現(xiàn)這種錯(cuò)誤。
所以,通過調(diào)整 reduce 端拉取數(shù)據(jù)重試次數(shù)和 reduce 端拉取數(shù)據(jù)時(shí)間間隔這兩個(gè)參數(shù)來對 Shuffle 性能進(jìn)行調(diào)整,增大參數(shù)值,使得 reduce 端拉取數(shù)據(jù)的重試次數(shù)增加,并且每次失敗后等待的時(shí)間間隔加長。
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "60").set("spark.shuffle.io.retryWait", "60s")
解決各種序列化導(dǎo)致的報(bào)錯(cuò)
當(dāng)報(bào)錯(cuò)信息中含有 Serializable 等類似詞匯,那么可能是序列化問題導(dǎo)致的報(bào)錯(cuò)。
序列化問題要注意以下三點(diǎn):
作為RDD的元素類型的自定義類,必須是可以序列化的;
算子函數(shù)里可以使用的外部的自定義變量,必須是可以序列化的;
不可以在RDD的元素類型、算子函數(shù)里使用第三方的不支持序列化的類型,例如 Connection。
解決算子函數(shù)返回 NULL 導(dǎo)致的問題
一些算子函數(shù)里,需要有返回值,但是在一些情況下我們不希望有返回值,此時(shí)我們?nèi)绻苯臃祷?NULL,會報(bào)錯(cuò),例如Scala.Math(NULL)異常。
可以通過下述方式解決:
返回特殊值,不返回NULL,例如“-1”;
在通過算子獲取到了一個(gè) RDD 之后,可以對這個(gè) RDD 執(zhí)行 filter 操作,進(jìn)行數(shù)據(jù)過濾,將數(shù)值為 -1 的過濾掉;
在使用完 filter 算子后,繼續(xù)調(diào)用 coalesce 算子進(jìn)行優(yōu)化。
解決 YARN-CLIENT 模式導(dǎo)致的網(wǎng)卡流量激增問題
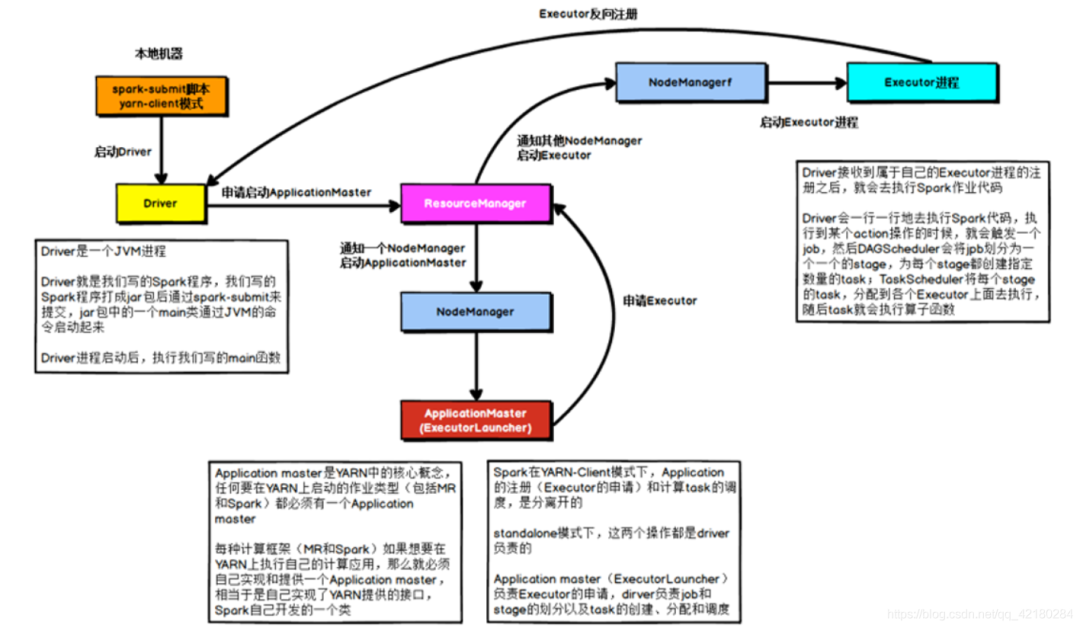
假設(shè)有100個(gè)Executor, 1000個(gè)task,那么每個(gè)Executor分配到10個(gè)task,之后,Driver要頻繁地跟Executor上運(yùn)行的1000個(gè)task進(jìn)行通信,通信數(shù)據(jù)非常多,并且通信品類特別高。這就導(dǎo)致有可能在Spark任務(wù)運(yùn)行過程中,由于頻繁大量的網(wǎng)絡(luò)通訊,本地機(jī)器的網(wǎng)卡流量會激增。
YARN-client 模式只會在測試環(huán)境中使用, YARN-client模式可以看到詳細(xì)全面的 log 信息,通過查看 log,可以鎖定程序中存在的問題,避免在生產(chǎn)環(huán)境下發(fā)生故障。
生產(chǎn)環(huán)境下,使用的是 YARN-cluster 模式。在 YARN-cluster 模式下,就不會造成本地機(jī)器網(wǎng)卡流量激增問題,如果 YARN-cluster 模式下存在網(wǎng)絡(luò)通信的問題,需要運(yùn)維團(tuán)隊(duì)進(jìn)行解決。
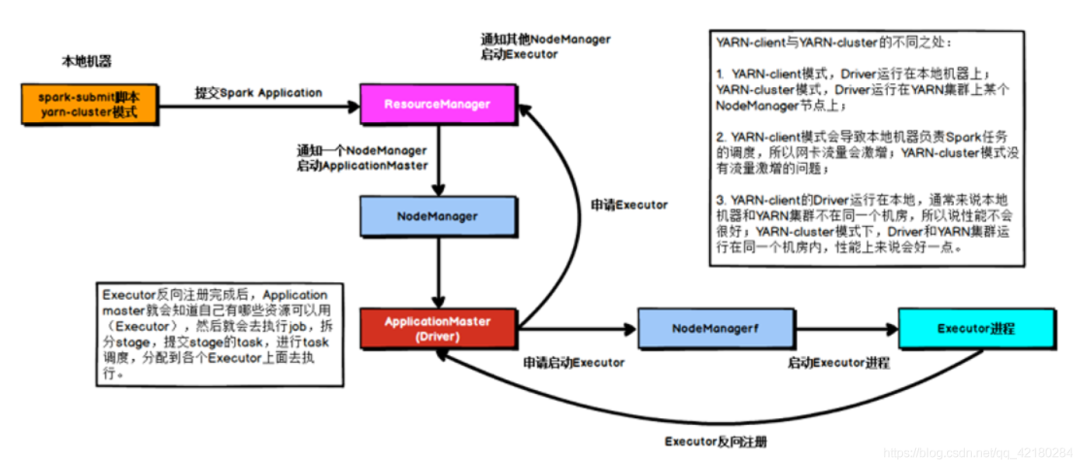
YARN-client 模式下,Driver 是運(yùn)行在本地機(jī)器上的,Spark 使用的 JVM 的 PermGen 的配置,是本地機(jī)器上的 spark-class 文件,JVM 永久代的大小是 128MB,但是在 YARN-cluster 模式下,Driver 運(yùn)行在 YARN 集群的某個(gè)節(jié)點(diǎn)上,使用的是沒有經(jīng)過配置的默認(rèn)設(shè)置,PermGen 永久代大小為 82MB。
SparkSQL 的內(nèi)部需要進(jìn)行很復(fù)雜的SQL的語義解析、語法樹轉(zhuǎn)換等等。如果 sql 語句非常復(fù)雜,很有可能會導(dǎo)致性能的損耗和內(nèi)存的占用,特別是對 PermGen 的占用會比較大。
此時(shí)如果 PermGen 的占用好過了 82MB,但是又小于128MB,就會出現(xiàn) YARN-client 模式下可以運(yùn)行,YARN-cluster 模式下無法運(yùn)行的情況。
解決上述問題的方法時(shí)增加 PermGenspark-submit:
# 設(shè)置 Driver 永久代大小,默認(rèn)為128MB,最大256MB--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
解決 SparkSQL 導(dǎo)致的 JVM 棧內(nèi)存溢出
JVM棧內(nèi)存溢出基本上就是由于調(diào)用的方法層級過多,產(chǎn)生了大量的,非常深的,超出了 JVM 棧深度限制的遞歸。很可能是 SparkSQL 有大量 or 語句導(dǎo)致的,因?yàn)樵诮馕?SQL 時(shí),轉(zhuǎn)換為語法樹或者進(jìn)行執(zhí)行計(jì)劃的生成對于 or 的處理是遞歸的。
建議將一條 sql 語句拆分為多條 sql 語句來執(zhí)行,每條sql語句盡量保證 100 個(gè)以內(nèi)的子句。
持久化與 checkpoint 的使用
一個(gè) RDD 緩存并 checkpoint 后,如果一旦發(fā)現(xiàn)緩存丟失,Spark 會優(yōu)先查看 checkpoint 數(shù)據(jù)存不存在,如果有就會使用 checkpoint 數(shù)據(jù),而不用重新計(jì)算。checkpoint 可以視為 cache 的保障機(jī)制,如果 cache 失敗,就使用 checkpoint 的數(shù)據(jù)。
使用 checkpoint 的優(yōu)點(diǎn)在于提高了 Spark 作業(yè)的可靠性,一旦緩存出現(xiàn)問題,不需要重新計(jì)算數(shù)據(jù),缺點(diǎn)在于, checkpoint 時(shí)需要將數(shù)據(jù)寫入 HDFS 等文件系統(tǒng),對性能的消耗較大。
原文地址:https://blog.csdn.net/qq_42180284/article/details/103945403