
分布式ID生成器(CosId)的設(shè)計(jì)與實(shí)現(xiàn)
點(diǎn)擊上方藍(lán)色字體,選擇“標(biāo)星公眾號(hào)”
優(yōu)質(zhì)文章,第一時(shí)間送達(dá)
CosId 簡(jiǎn)介
CosId 旨在提供通用、靈活、高性能的分布式 ID 生成器。目前提供了倆類 ID 生成器:
SnowflakeId: 單機(jī) TPS 性能:409W/s JMH 基準(zhǔn)測(cè)試 , 主要解決 時(shí)鐘回?fù)軉?wèn)題 、機(jī)器號(hào)分配問(wèn)題 并且提供更加友好、靈活的使用體驗(yàn)。SegmentId: 每次獲取一段 (Step) ID,來(lái)降低號(hào)段分發(fā)器的網(wǎng)絡(luò)IO請(qǐng)求頻次提升性能。PrefetchWorker維護(hù)安全距離(safeDistance), 并且支持基于饑餓狀態(tài)的動(dòng)態(tài)safeDistance擴(kuò)容/收縮。RedisIdSegmentDistributor: 基于 Redis 的號(hào)段分發(fā)器。JdbcIdSegmentDistributor: 基于 Jdbc 的號(hào)段分發(fā)器,支持各種關(guān)系型數(shù)據(jù)庫(kù)。IdSegmentDistributor: 號(hào)段分發(fā)器(號(hào)段存儲(chǔ)器)SegmentChainId(推薦):SegmentChainId(lock-free) 是對(duì)SegmentId的增強(qiáng)。性能可達(dá)到近似AtomicLong的 TPS 性能:12743W+/s JMH 基準(zhǔn)測(cè)試 。
背景(為什么需要分布式ID)
在軟件系統(tǒng)演進(jìn)過(guò)程中,隨著業(yè)務(wù)規(guī)模的增長(zhǎng),我們需要進(jìn)行集群化部署來(lái)分?jǐn)傆?jì)算、存儲(chǔ)壓力,應(yīng)用服務(wù)我們可以很輕松做到無(wú)狀態(tài)、彈性伸縮。
但是僅僅增加服務(wù)副本數(shù)就夠了嗎?顯然不夠,因?yàn)樾阅芷款i往往是在數(shù)據(jù)庫(kù)層面,那么這個(gè)時(shí)候我們就需要考慮如何進(jìn)行數(shù)據(jù)庫(kù)的擴(kuò)容、伸縮、集群化,通常使用分庫(kù)、分表的方式來(lái)處理。
那么我如何分片(水平分片,當(dāng)然還有垂直分片不過(guò)不是本文需要討論的內(nèi)容)呢,分片得前提是我們得先有一個(gè)ID,然后才能根據(jù)分片算法來(lái)分片。(比如比較簡(jiǎn)單常用的ID取模分片算法,這個(gè)跟Hash算法的概念類似,我們得先有key才能進(jìn)行Hash取得插入槽位。)
當(dāng)然還有很多分布式場(chǎng)景需要分布式ID,這里不再一一列舉。
分布式ID方案的核心指標(biāo)
全局(相同業(yè)務(wù))唯一性:唯一性保證是ID的必要條件,假設(shè)ID不唯一就會(huì)產(chǎn)生主鍵沖突,這點(diǎn)很容易可以理解。
通常所說(shuō)的全局唯一性并不是指所有業(yè)務(wù)服務(wù)都要唯一,而是相同業(yè)務(wù)服務(wù)不同部署副本唯一。
比如 Order 服務(wù)的多個(gè)部署副本在生成t_order這張表的Id時(shí)是要求全局唯一的。至于t_order_item生成的ID與t_order是否唯一,并不影響唯一性約束,也不會(huì)產(chǎn)生什么副作用。
不同業(yè)務(wù)模塊間也是同理。即唯一性主要解決的是ID沖突問(wèn)題。有序性:有序性保證是面向查詢的數(shù)據(jù)結(jié)構(gòu)算法(除了Hash算法)所必須的,是二分查找法(分而治之)的前提。
MySq-InnoDB B+樹(shù)是使用最為廣泛的,假設(shè) Id 是無(wú)序的,B+ 樹(shù) 為了維護(hù) ID 的有序性,就會(huì)頻繁的在索引的中間位置插入而挪動(dòng)后面節(jié)點(diǎn)的位置,甚至導(dǎo)致頻繁的頁(yè)分裂,這對(duì)于性能的影響是極大的。那么如果我們能夠保證ID的有序性這種情況就完全不同了,只需要進(jìn)行追加寫(xiě)操作。所以 ID 的有序性是非常重要的,也是ID設(shè)計(jì)不可避免的特性。
吞吐量/性能(ops/time):即單位時(shí)間(每秒)能產(chǎn)生的ID數(shù)量。生成ID是非常高頻的操作,也是最為基本的。假設(shè)ID生成的性能緩慢,那么不管怎么進(jìn)行系統(tǒng)優(yōu)化也無(wú)法獲得更好的性能。
一般我們會(huì)首先生成ID,然后再執(zhí)行寫(xiě)入操作,假設(shè)ID生成緩慢,那么整體性能上限就會(huì)受到限制,這一點(diǎn)應(yīng)該不難理解。
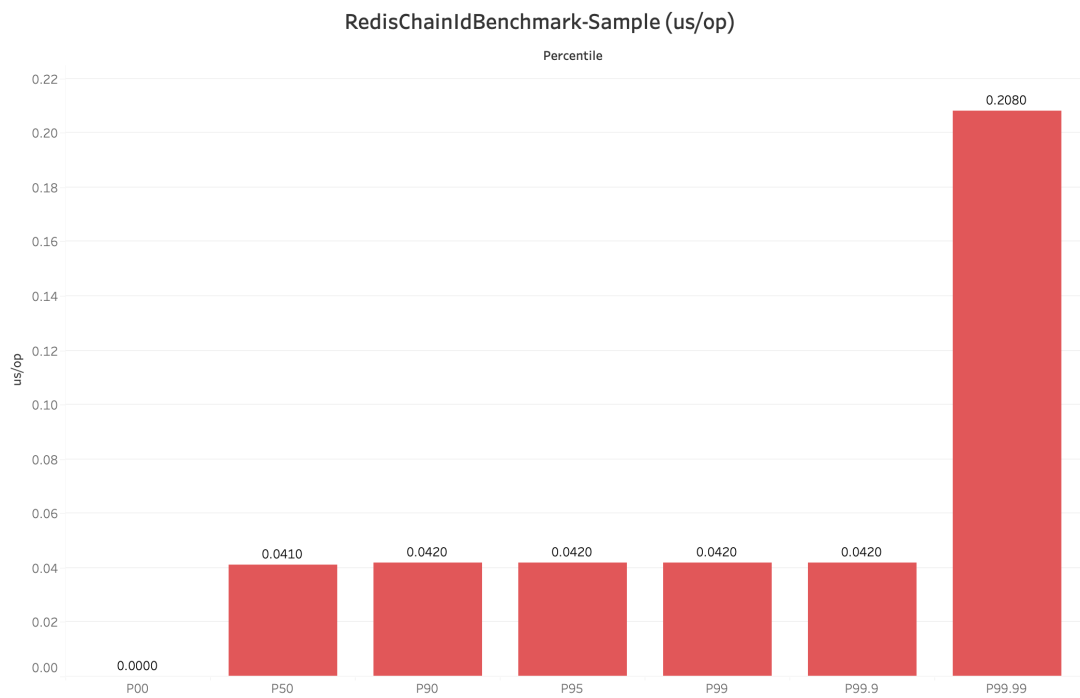
穩(wěn)定性(time/op):穩(wěn)定性指標(biāo)一般可以采用每個(gè)操作的時(shí)間進(jìn)行百分位采樣來(lái)分析,比如 CosId 百分位采樣 P9999=0.208 us/op,即 0% ~ 99.99% 的單位操作時(shí)間小于等于 0.208 us/op。
百分位數(shù) WIKI :統(tǒng)計(jì)學(xué)術(shù)語(yǔ),若將一組數(shù)據(jù)從小到大排序,并計(jì)算相應(yīng)的累計(jì)百分點(diǎn),則某百分點(diǎn)所對(duì)應(yīng)數(shù)據(jù)的值,就稱為這百分點(diǎn)的百分位數(shù),以Pk表示第k百分位數(shù)。百分位數(shù)是用來(lái)比較個(gè)體在群體中的相對(duì)地位量數(shù)。
為什么不用平均每個(gè)操作的時(shí)間:馬老師的身價(jià)跟你的身價(jià)能平均么?平均后的值有意義不?
可以使用最小每個(gè)操作的時(shí)間、最大每個(gè)操作的時(shí)間作為參考嗎?因?yàn)樽钚 ⒆畲笾抵徽f(shuō)明了零界點(diǎn)的情況,雖說(shuō)可以作為穩(wěn)定性的參考,但依然不夠全面。而且百分位數(shù)已經(jīng)覆蓋了這倆個(gè)指標(biāo)。
自治性(依賴):主要是指對(duì)外部環(huán)境有無(wú)依賴,比如號(hào)段模式會(huì)強(qiáng)依賴第三方存儲(chǔ)中間件來(lái)獲取
NexMaxId。自治性還會(huì)對(duì)可用性造成影響。可用性:分布式ID的可用性主要會(huì)受到自治性影響,比如SnowflakeId會(huì)受到時(shí)鐘回?fù)苡绊懀瑢?dǎo)致處于短暫時(shí)間的不可用狀態(tài)。而號(hào)段模式會(huì)受到第三方發(fā)號(hào)器(
NexMaxId)的可用性影響。可用性 WIKI:在一個(gè)給定的時(shí)間間隔內(nèi),對(duì)于一個(gè)功能個(gè)體來(lái)講,總的可用時(shí)間所占的比例。
MTBF:平均故障間隔
MDT:平均修復(fù)/恢復(fù)時(shí)間
Availability=MTBF/(MTBF+MDT)
假設(shè)MTBF為1年,MDT為1小時(shí),即
Availability=(365*24)/(365*24+1)=0.999885857778792≈99.99%,也就是我們通常所說(shuō)對(duì)可用性4個(gè)9。適應(yīng)性:是指在面對(duì)外部環(huán)境變化的自適應(yīng)能力,這里我們主要說(shuō)的是面對(duì)流量突發(fā)時(shí)動(dòng)態(tài)伸縮分布式ID的性能,
SegmentChainId可以基于饑餓狀態(tài)進(jìn)行安全距離的動(dòng)態(tài)伸縮。
SnowflakeId常規(guī)位分配方案性能恒定409.6W,雖然可以通過(guò)調(diào)整位分配方案來(lái)獲得不同的TPS性能,但是位分配方法的變更是破壞性的,一般根據(jù)業(yè)務(wù)場(chǎng)景確定位分配方案后不再變更。
存儲(chǔ)空間:還是用MySq-InnoDB B+樹(shù)來(lái)舉例,普通索引(二級(jí)索引)會(huì)存儲(chǔ)主鍵值,主鍵越大占用的內(nèi)存緩存、磁盤(pán)空間也會(huì)越大。Page頁(yè)存儲(chǔ)的數(shù)據(jù)越少,磁盤(pán)IO訪問(wèn)的次數(shù)會(huì)增加。總之在滿足業(yè)務(wù)需求的情況下,盡可能小的存儲(chǔ)空間占用在絕大多數(shù)場(chǎng)景下都是好的設(shè)計(jì)原則。
不同分布式ID方案核心指標(biāo)對(duì)比
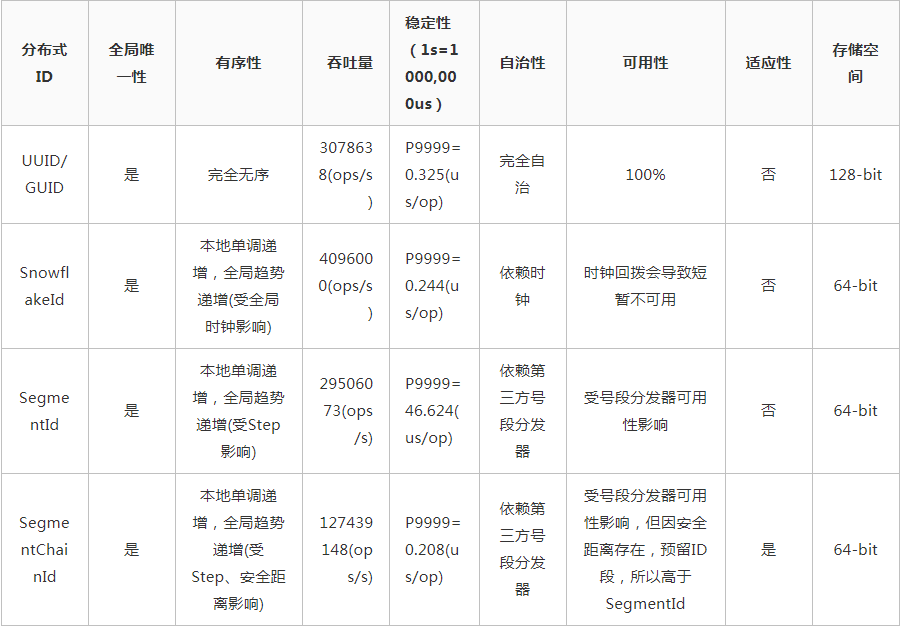
有序性(要想分而治之·二分查找法,必須要維護(hù)我)
剛剛我們已經(jīng)討論了ID有序性的重要性,所以我們?cè)O(shè)計(jì)ID算法時(shí)應(yīng)該盡可能地讓ID是單調(diào)遞增的,比如像表的自增主鍵那樣。但是很遺憾,因全局時(shí)鐘、性能等分布式系統(tǒng)問(wèn)題,我們通常只能選擇局部單調(diào)遞增、全局趨勢(shì)遞增的組合(就像我們?cè)诜植际较到y(tǒng)中不得不的選擇最終一致性那樣)以獲得多方面的權(quán)衡。下面我們來(lái)看一下什么是單調(diào)遞增與趨勢(shì)遞增。
有序性之單調(diào)遞增
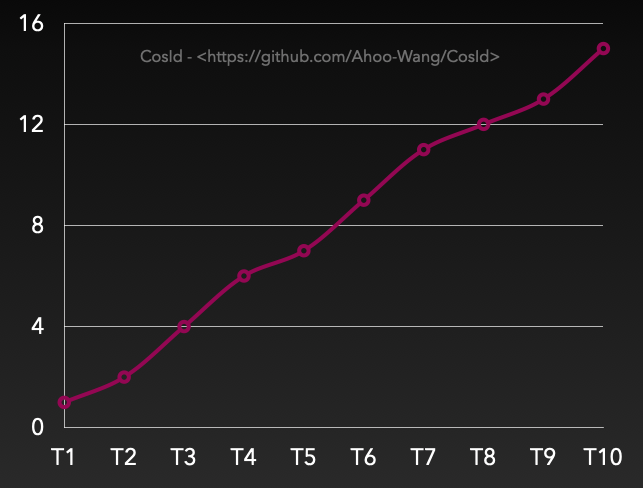
單調(diào)遞增:T表示全局絕對(duì)時(shí)點(diǎn),假設(shè)有Tn+1>Tn(絕對(duì)時(shí)間總是往前進(jìn)的,這里不考慮相對(duì)論、時(shí)間機(jī)器等),那么必然有F(Tn+1)>F(Tn),數(shù)據(jù)庫(kù)自增主鍵就屬于這一類。
另外需要特別說(shuō)明的是單調(diào)遞增跟連續(xù)性遞增(F(n+1)=F(n)+step)是不同的概念。
有序性之趨勢(shì)遞增
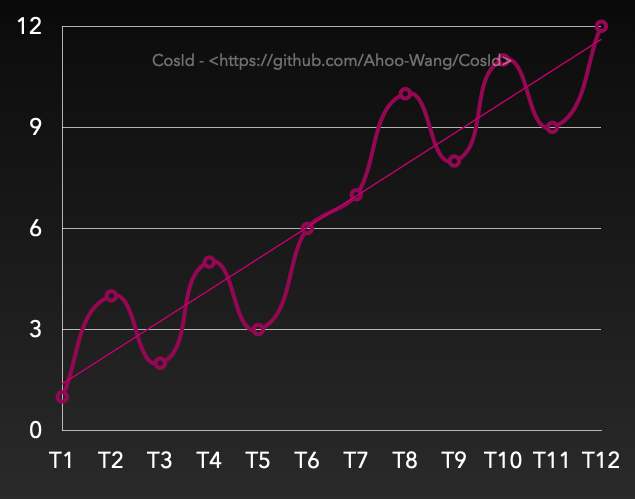
趨勢(shì)遞增:Tn>Tn-s,那么大概率有F(Tn)>F(Tn-s)。雖然在一段時(shí)間間隔內(nèi)有亂序,但是整體趨勢(shì)是遞增。從上圖上看,是有上升趨勢(shì)的(趨勢(shì)線)。
在SnowflakeId中n-s受到全局時(shí)鐘同步影響。
在號(hào)段模式(SegmentId)中n-s受到號(hào)段可用區(qū)間(
Step)影響。
分布式ID分配方案
UUID/GUID
??不依賴任何第三方中間件
??性能高
??完全無(wú)序
??空間占用大,需要占用128位存儲(chǔ)空間。
UUID最大的缺陷是隨機(jī)的、無(wú)序的,當(dāng)用于主鍵時(shí)會(huì)導(dǎo)致數(shù)據(jù)庫(kù)的主鍵索引效率低下(為了維護(hù)索引樹(shù),頻繁的索引中間位置插入數(shù)據(jù),而不是追加寫(xiě))。這也是UUID不適用于數(shù)據(jù)庫(kù)主鍵的最為重要的原因。
SnowflakeId
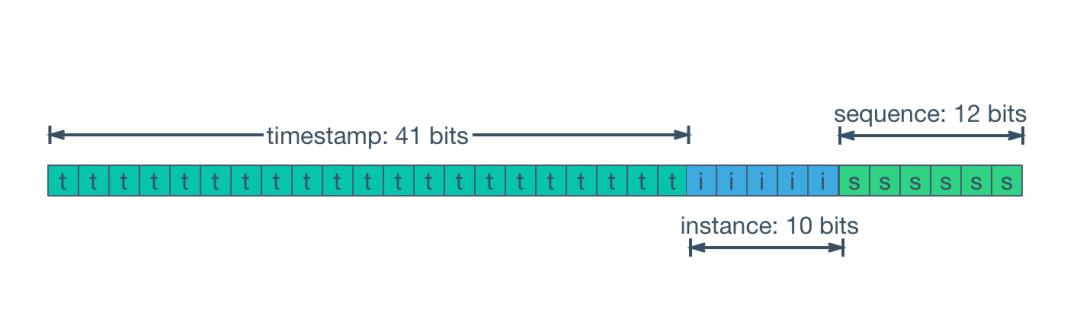
SnowflakeId使用
Long(64-bit)位分區(qū)來(lái)生成ID的一種分布式ID算法。
通用的位分配方案為:timestamp(41-bit)+machineId(10-bit)+sequence(12-bit)=63-bit。
41-bit
timestamp=(1L<<41)/(1000/3600/365),約可以存儲(chǔ)69年的時(shí)間戳,即可以使用的絕對(duì)時(shí)間為EPOCH+69年,一般我們需要自定義EPOCH為產(chǎn)品開(kāi)發(fā)時(shí)間,另外還可以通過(guò)壓縮其他區(qū)域的分配位數(shù),來(lái)增加時(shí)間戳位數(shù)來(lái)延長(zhǎng)可用時(shí)間。10-bit
machineId=(1L<<10)=1024,即相同業(yè)務(wù)可以部署1024個(gè)副本(在Kubernetes概念里沒(méi)有主從副本之分,這里直接沿用Kubernetes的定義)。一般情況下沒(méi)有必要使用這么多位,所以會(huì)根據(jù)部署規(guī)模需要重新定義。12-bit
sequence=(1L<<12)*1000=4096000,即單機(jī)每秒可生成約409W的ID,全局同業(yè)務(wù)集群可產(chǎn)生4096000*1024=419430W=41.9億(TPS)。
從 SnowflakeId 設(shè)計(jì)上可以看出:
??
timestamp在高位,單實(shí)例SnowflakeId是會(huì)保證時(shí)鐘總是向前的(校驗(yàn)本機(jī)時(shí)鐘回?fù)埽允潜緳C(jī)單調(diào)遞增的。受全局時(shí)鐘同步/時(shí)鐘回?fù)苡绊?em>SnowflakeId是全局趨勢(shì)遞增的。??SnowflakeId不對(duì)任何第三方中間件有強(qiáng)依賴關(guān)系,并且性能也非常高。
??位分配方案可以按照業(yè)務(wù)系統(tǒng)需要靈活配置,來(lái)達(dá)到最優(yōu)使用效果。
??強(qiáng)依賴本機(jī)時(shí)鐘,潛在的時(shí)鐘回?fù)軉?wèn)題會(huì)導(dǎo)致ID重復(fù)、處于短暫的不可用狀態(tài)。
??
machineId需要手動(dòng)設(shè)置,實(shí)際部署時(shí)如果采用手動(dòng)分配machineId,會(huì)非常低效。
SnowflakeId之機(jī)器號(hào)分配問(wèn)題
在SnowflakeId中根據(jù)業(yè)務(wù)設(shè)計(jì)的位分配方案確定了基本上就不再有變更了,也很少需要維護(hù)。但是machineId總是需要配置的,而且集群中是不能重復(fù)的,否則分區(qū)原則就會(huì)被破壞而導(dǎo)致ID唯一性原則破壞,當(dāng)集群規(guī)模較大時(shí)machineId的維護(hù)工作是非常繁瑣,低效的。
有一點(diǎn)需要特別說(shuō)明的,SnowflakeId的MachineId是邏輯上的概念,而不是物理概念。
想象一下假設(shè)MachineId是物理上的,那么意味著一臺(tái)機(jī)器擁有只能擁有一個(gè)MachineId,那會(huì)產(chǎn)生什么問(wèn)題呢?
目前 CosId 提供了以下三種
MachineId分配器。
ManualMachineIdDistributor: 手動(dòng)配置
machineId,一般只有在集群規(guī)模非常小的時(shí)候才有可能使用,不推薦。StatefulSetMachineIdDistributor: 使用
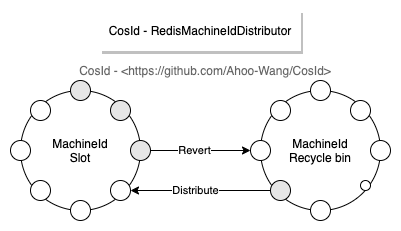
Kubernetes的StatefulSet提供的穩(wěn)定的標(biāo)識(shí)ID(HOSTNAME=service-01)作為機(jī)器號(hào)。RedisMachineIdDistributor: 使用Redis作為機(jī)器號(hào)的分發(fā)存儲(chǔ),同時(shí)還會(huì)存儲(chǔ)
MachineId的上一次時(shí)間戳,用于啟動(dòng)時(shí)時(shí)鐘回?fù)?/strong>的檢查。
SnowflakeId之時(shí)鐘回?fù)軉?wèn)題
時(shí)鐘回?fù)艿闹旅鼏?wèn)題是會(huì)導(dǎo)致ID重復(fù)、沖突(這一點(diǎn)不難理解),ID重復(fù)顯然是不能被容忍的。
在SnowflakeId算法中,按照MachineId分區(qū)ID,我們不難理解的是不同MachineId是不可能產(chǎn)生相同ID的。所以我們解決的時(shí)鐘回?fù)軉?wèn)題是指當(dāng)前MachineId的時(shí)鐘回?fù)軉?wèn)題,而不是所有集群節(jié)點(diǎn)的時(shí)鐘回?fù)軉?wèn)題。
MachineId時(shí)鐘回?fù)軉?wèn)題大體可以分為倆種情況:
運(yùn)行時(shí)時(shí)鐘回?fù)埽杭丛谶\(yùn)行時(shí)獲取的當(dāng)前時(shí)間戳比上一次獲取的時(shí)間戳小。這個(gè)場(chǎng)景的時(shí)鐘回?fù)苁呛苋菀滋幚淼模话?strong>SnowflakeId代碼實(shí)現(xiàn)時(shí)都會(huì)存儲(chǔ)
lastTimestamp用于運(yùn)行時(shí)時(shí)鐘回?fù)艿臋z查,并拋出時(shí)鐘回?fù)墚惓!?/p>時(shí)鐘回?fù)軙r(shí)直接拋出異常是不太好地實(shí)踐,因?yàn)橄掠问褂梅綆缀鯖](méi)有其他處理方案(噢,我還能怎么辦呢,等吧),時(shí)鐘同步是唯一的選擇,當(dāng)只有一種選擇時(shí)就不要再讓用戶選擇了。
ClockSyncSnowflakeId是SnowflakeId的包裝器,當(dāng)發(fā)生時(shí)鐘回?fù)軙r(shí)會(huì)使用ClockBackwardsSynchronizer主動(dòng)等待時(shí)鐘同步來(lái)重新生成ID,提供更加友好的使用體驗(yàn)。啟動(dòng)時(shí)時(shí)鐘回?fù)埽杭丛趩?dòng)服務(wù)實(shí)例時(shí)獲取的當(dāng)前時(shí)鐘比上次關(guān)閉服務(wù)時(shí)小。此時(shí)的
lastTimestamp是無(wú)法存儲(chǔ)在進(jìn)程內(nèi)存中的。當(dāng)獲取的外部存儲(chǔ)的機(jī)器狀態(tài)大于當(dāng)前時(shí)鐘時(shí)鐘時(shí),會(huì)使用ClockBackwardsSynchronizer主動(dòng)同步時(shí)鐘。LocalMachineStateStorage:使用本地文件存儲(chǔ)
MachineState(機(jī)器號(hào)、最近一次時(shí)間戳)。因?yàn)槭褂玫氖潜镜匚募灾挥挟?dāng)實(shí)例的部署環(huán)境是穩(wěn)定的,LocalMachineStateStorage才適用。RedisMachineIdDistributor:將
MachineState存儲(chǔ)在Redis分布式緩存中,這樣可以保證總是可以獲取到上次服務(wù)實(shí)例停機(jī)時(shí)機(jī)器狀態(tài)。
SnowflakeId之JavaScript數(shù)值溢出問(wèn)題
JavaScript的Number.MAX_SAFE_INTEGER只有53-bit,如果直接將63位的SnowflakeId返回給前端,那么會(huì)產(chǎn)生值溢出的情況(所以這里我們應(yīng)該知道后端傳給前端的long值溢出問(wèn)題,遲早會(huì)出現(xiàn),只不過(guò)SnowflakeId出現(xiàn)得更快而已)。
很顯然溢出是不能被接受的,一般可以使用以下倆種處理方案:
將生成的63-bit
SnowflakeId轉(zhuǎn)換為String類型。直接將
long轉(zhuǎn)換成String。使用
SnowflakeFriendlyId將SnowflakeId轉(zhuǎn)換成比較友好的字符串表示:{timestamp}-{machineId}-{sequence} -> 20210623131730192-1-0自定義
SnowflakeId位分配來(lái)縮短SnowflakeId的位數(shù)(53-bit)使ID提供給前端時(shí)不溢出使用
SafeJavaScriptSnowflakeId(JavaScript安全的SnowflakeId)
號(hào)段模式(SegmentId)
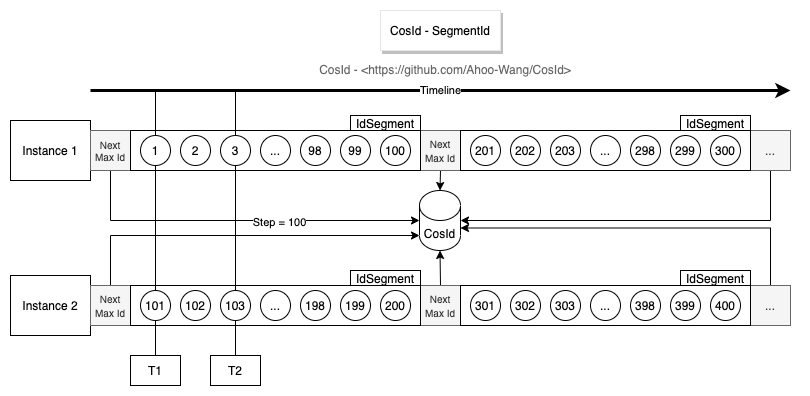
從上面的設(shè)計(jì)圖中,不難看出號(hào)段模式基本設(shè)計(jì)思路是通過(guò)每次獲取一定長(zhǎng)度(Step)的可用ID(Id段/號(hào)段),來(lái)降低網(wǎng)絡(luò)IO請(qǐng)求次數(shù),提升性能。
??強(qiáng)依賴第三方號(hào)段分發(fā)器,可用性受到第三方分發(fā)器影響。
??每次號(hào)段用完時(shí)獲取
NextMaxId需要進(jìn)行網(wǎng)絡(luò)IO請(qǐng)求,此時(shí)的性能會(huì)比較低。單實(shí)例ID單調(diào)遞增,全局趨勢(shì)遞增。
從設(shè)計(jì)圖中不難看出Instance 1每次獲取的
NextMaxId,一定比上一次大,意味著下一次的號(hào)段一定比上一次大,所以從單實(shí)例上來(lái)看是單調(diào)遞增的。多實(shí)例各自持有的不同的號(hào)段,意味著同一時(shí)刻不同實(shí)例生成的ID是亂序的,但是整體趨勢(shì)的遞增的,所以全局趨勢(shì)遞增。
ID亂序程度受到Step長(zhǎng)度以及集群規(guī)模影響(從趨勢(shì)遞增圖中不難看出)。
號(hào)段分發(fā)器T1時(shí)刻給Instance 1分發(fā)了
ID=1,T2時(shí)刻給Instance 2分發(fā)了ID=2。因?yàn)闄C(jī)器性能、網(wǎng)絡(luò)等原因,Instance 2網(wǎng)絡(luò)IO寫(xiě)請(qǐng)求先于Instance 1到達(dá)。那么這個(gè)時(shí)候?qū)τ跀?shù)據(jù)庫(kù)來(lái)說(shuō),ID依然是亂序的。假設(shè)集群中只有一個(gè)實(shí)例時(shí)號(hào)段模式就是單調(diào)遞增的。
Step越小,亂序程度越小。當(dāng)Step=1時(shí),將無(wú)限接近單調(diào)遞增。需要注意的是這里是無(wú)限接近而非等于單調(diào)遞增,具體原因你可以思考一下這樣一個(gè)場(chǎng)景:
號(hào)段鏈模式(SegmentChainId)
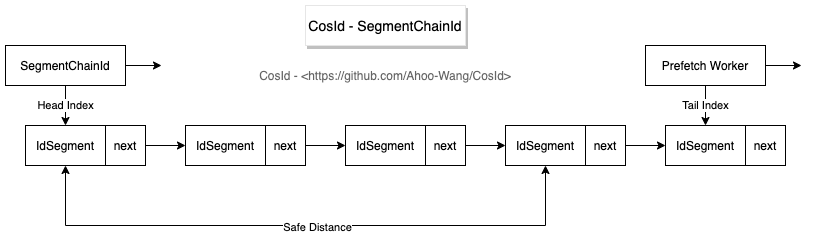
SegmentChainId是SegmentId增強(qiáng)版,相比于SegmentId有以下優(yōu)勢(shì):
穩(wěn)定性:SegmentId的穩(wěn)定性問(wèn)題(P9999=46.624(us/op))主要是因?yàn)樘?hào)段用完之后同步進(jìn)行
NextMaxId的獲取導(dǎo)致的(會(huì)產(chǎn)生網(wǎng)絡(luò)IO)。SegmentChainId (P9999=0.208(us/op))引入了新的角色PrefetchWorker用以維護(hù)和保證安全距離,理想情況下使得獲取ID的線程幾乎完全不需要進(jìn)行同步的等待
NextMaxId獲取,性能可達(dá)到近似AtomicLong的 TPS 性能:12743W+/s JMH 基準(zhǔn)測(cè)試 。適應(yīng)性:從SegmentId介紹中我們知道了影響ID亂序的因素有倆個(gè):集群規(guī)模、
Step大小。集群規(guī)模是我們不能控制的,但是Step是可以調(diào)節(jié)的。Step應(yīng)該近可能小才能使得ID單調(diào)遞增的可能性增大。Step太小會(huì)影響吞吐量,那么我們?nèi)绾魏侠碓O(shè)置Step呢?答案是我們無(wú)法準(zhǔn)確預(yù)估所有時(shí)點(diǎn)的吞吐量需求,那么最好的辦法是吞吐量需求高時(shí),Step自動(dòng)增大,吞吐量低時(shí)Step自動(dòng)收縮。SegmentChainId引入了饑餓狀態(tài)的概念,PrefetchWorker會(huì)根據(jù)饑餓狀態(tài)檢測(cè)當(dāng)前安全距離是否需要膨脹或者收縮,以便獲得吞吐量與有序性之間的權(quán)衡,這便是SegmentChainId的自適應(yīng)性。
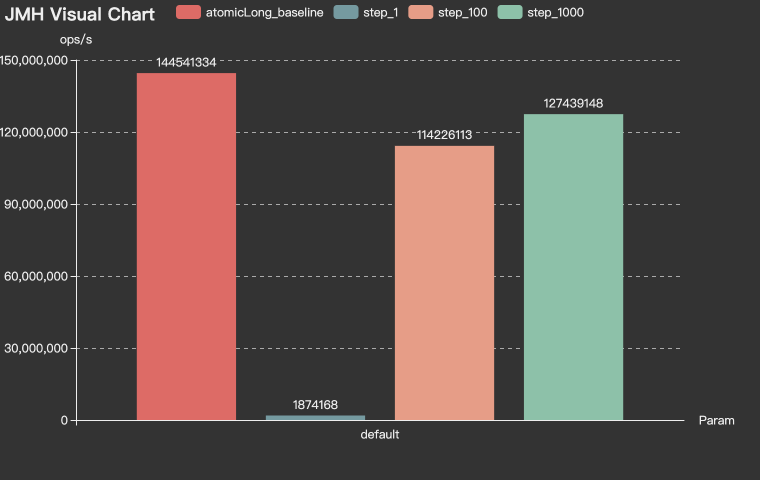
SegmentChainId-吞吐量 (ops/s)
SegmentChainId-每次操作耗時(shí)的百分位數(shù)
基準(zhǔn)測(cè)試報(bào)告運(yùn)行環(huán)境說(shuō)明
基準(zhǔn)測(cè)試運(yùn)行環(huán)境:筆記本開(kāi)發(fā)機(jī)(MacBook-Pro-(M1))
所有基準(zhǔn)測(cè)試都在開(kāi)發(fā)筆記本上執(zhí)行。
作者 | Ahoo-Wang
來(lái)源 | cnblogs.com/Ahoo-Wang/p/distributed-id.html
