
文生圖模型之Emu:開啟微調(diào)時代
 點藍色字關(guān)注 “機器學(xué)習(xí)算法工程師 ”
點藍色字關(guān)注 “機器學(xué)習(xí)算法工程師 ”
設(shè)為 星標(biāo) ,干貨直達!
Meta在Meta Connect 2023大會上發(fā)布了自家的文生圖模型Emu:Expressive Media Universe。值得可敬的是,Meta同時也公布了Emu的技術(shù)論文,這真要比OpenAI良心多了,要知道OpenAI近發(fā)布的DALLE 3是一點技術(shù)細節(jié)也沒公開。這篇文章將簡單解讀一下Emu的技術(shù)報告。
寫在前面
首先,Emu在技術(shù)上并沒有太大的創(chuàng)新,它的模型架構(gòu)還是基于Stable Diffusion。Emu最大的貢獻是發(fā)現(xiàn)文生圖模型在經(jīng)過大規(guī)模預(yù)訓(xùn)練之后,使用極少量的高質(zhì)量數(shù)據(jù)進行微調(diào)就可以大幅度提升生成圖像的質(zhì)量,而且不丟失泛化性。論文里面將這個微調(diào)稱為quality-tuning,它的目標(biāo)就是提升模型生成圖像的美學(xué)質(zhì)量。這個quality-tuning可以類比為LLMs中的instruction-tuning。大語言模型經(jīng)過instruction-tuning之后文生生成質(zhì)量也有一個明顯的提升。而且這里的quality-tuning和LLMs中的instruction-tuning在方法上有很多類似之處:首先是都需要高質(zhì)量數(shù)據(jù),而且質(zhì)量往往比數(shù)量更重要,比如Llama2使用27K高質(zhì)量文本進行微調(diào),這里的Emu僅需要2000張高質(zhì)量圖像(之前Meta的工作LIMA: Less Is More for Alignment使用1000個高質(zhì)量文本就夠了);二是經(jīng)過微調(diào)后,基本沒有丟失泛化性,即原來預(yù)訓(xùn)練階段學(xué)習(xí)的知識沒有遺忘。雖然Meta在論文中強調(diào)他們第一個指出quality-tuning對文生圖模型生成圖像質(zhì)量的重要性。但其實自從Stable Diffusion開源之后,社區(qū)其實已經(jīng)進行了大量的quality-tuning工作(即所謂的煉丹),比如C站上海量的基于開源Stable Diffusion微調(diào)的模型,只不過學(xué)術(shù)界一直沒有特別重視quality-tuning。盡管quality-tuning和instruction-tuning在技術(shù)上沒太多復(fù)雜性,但是要想得到好的微調(diào)模型,還是需要比較高超的“煉丹術(shù)”。所以,Meta的Emu的技術(shù)報告還是有一定的學(xué)習(xí)價值,特別是在構(gòu)建高質(zhì)量圖像數(shù)據(jù)方面。
模型結(jié)構(gòu)
Emu和Stable Diffusion一樣基于latent diffusion,擴散模型的UNet參數(shù)量為2.8B,比SDXL還大一些,這是通過增加UNet的通道數(shù)和每個stage的block數(shù)量來實現(xiàn)(即增加網(wǎng)絡(luò)的深度和寬度)。至于text encoder,Emu是選用了OpenAI的CLIP ViT-L和谷歌的T5-XXL(SDXL則是使用CLIP ViT-L和OpenCLIP ViT-G),根據(jù)之前Imagen的實驗,采用純文本訓(xùn)練的T5-XXL有助于提升文本理解能力(即生成的圖像與輸入文本prompt更一致)。Emu在模型結(jié)構(gòu)上相比Stable Diffusion的一個改動是采用了**channel數(shù)為16的AE (autoencoder)**。Stable Diffusion所采用的AE一直是4-channel的,對于512x512x3的圖像,latent的維度為64x64x4,其中下采樣率為8,而channel數(shù)為4。這個AE的壓縮率還是比較大的,所以會造成圖像的細節(jié)丟失,具體表現(xiàn)就是小物體容易出現(xiàn)畸變,比如較小的文字和人臉,這也是為什么SDXL直接生成1024x1024的圖像原因之一,因為可以在一定程度上避免AE容易畸變的問題。如果將latent的channel數(shù)增加到16,那么畸變問題就基本上緩解了,下面為一個具體的對比(用AE重建的圖像): 可以看到4 channel的AE明顯可以看到文字的畸變,但是16 channel的AE的文字基本無變形了。從定量指標(biāo)對比來看,16 channel的AE的PSNR也是明顯高于4 channel的AE:
可以看到4 channel的AE明顯可以看到文字的畸變,但是16 channel的AE的文字基本無變形了。從定量指標(biāo)對比來看,16 channel的AE的PSNR也是明顯高于4 channel的AE:
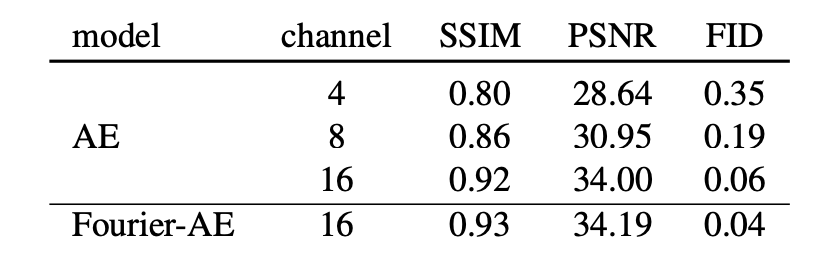 這里的Fourier-AE是使用傅立葉特征變換使RGB圖像的輸入特征維度增加,從而更好地增強細節(jié),同時增加了對抗損失。Fourier-AE相比原始的AE只有微弱提升,所以增加channel數(shù)量才是最重要的。不過,使用16 channel的AE,擴散模型的訓(xùn)練難度會有一定增加。
這里的Fourier-AE是使用傅立葉特征變換使RGB圖像的輸入特征維度增加,從而更好地增強細節(jié),同時增加了對抗損失。Fourier-AE相比原始的AE只有微弱提升,所以增加channel數(shù)量才是最重要的。不過,使用16 channel的AE,擴散模型的訓(xùn)練難度會有一定增加。
Pre-training
Emu的預(yù)訓(xùn)練數(shù)據(jù)集包含11億個圖像,但是Meta并沒有說明這么大的數(shù)據(jù)集是如何構(gòu)建的(估計是擔(dān)心版權(quán)問題),可能是基于LAION-2B數(shù)據(jù)集,也有可能是自制的。Emu和SDXL一樣都是最終生成1024x1024的圖像,所以也采用了和SDXL類似的漸進式訓(xùn)練方案:256x256 -> 512x512 -> 1024x1024。在最后的1024x1024訓(xùn)練階段(論文并沒有說明是否和SDXL一樣采用了多尺度訓(xùn)練,但很可能只是固定在1024x1024上訓(xùn)練),同樣采用了系數(shù)為0.02的noise offset,這個是用來解決模型只能生成中等亮度的圖像這個問題,這個對于生成高對比度圖像是比較重要的。預(yù)訓(xùn)練可以看成是一個知識學(xué)習(xí)階段,通過大量的數(shù)據(jù)讓模型可以輸入任意的文本來生成圖像,但是由于預(yù)訓(xùn)練階段所采用的數(shù)據(jù)往往噪音很大,所以預(yù)訓(xùn)練后得到模型往往生成的圖像比較一般。這就需要后面的quality-tuning來提升模型生成圖像的質(zhì)量。
Quality-tuning
對于quality-tuning,最重要的是構(gòu)建高質(zhì)量圖像數(shù)據(jù)集,對比Meta總結(jié)了三個要點:
- 用于quality-tuning的數(shù)據(jù)集可以很小,Emu最終只用了2000個高質(zhì)量圖像;
- 數(shù)據(jù)集中的圖像質(zhì)量要很高,所以很難全自動構(gòu)建,需要一定的人工;
- 盡管數(shù)據(jù)集中包含的圖像比較少,quality-tuning不僅可以大大提升模型生成圖像的美學(xué)質(zhì)量,而且也沒有出現(xiàn)過擬合。
為了構(gòu)建quality-tuning的數(shù)據(jù)集,Meta從數(shù)十億張圖像開始,經(jīng)過自動篩查和人工篩查,最終只得到2000張高質(zhì)量圖像。這個篩選還是相當(dāng)兇殘的,也怪不得論文的題目用了“大海撈針”(Needles in a Haystack)來描述這個過程。第一步是自動篩選,這個過程是使用一些自動化的方法來進行數(shù)據(jù)過濾,不涉及到人工。首先是使用一些常規(guī)的過濾器進行過濾,主要包括:攻擊性內(nèi)容刪除(即NSFW檢測),美學(xué)評分過濾(應(yīng)該類似laion aesthetic score),通過OCR來過濾掉文字過多的圖像,通過CLIP score來過濾掉文本和圖像一致性差的圖像。這些都是文生圖模型訓(xùn)練最常采用的數(shù)據(jù)過濾方法,這個過程將數(shù)十億張圖像(這個數(shù)據(jù)的來源也未交代,應(yīng)該就是預(yù)訓(xùn)練數(shù)據(jù))減少到只有幾億。然后再通過圖像的大小和長寬比來過濾圖像,這個也是常規(guī)做法。接著是采用一個圖像分類器來獲取圖像的所屬領(lǐng)域和類別,比如肖像、食物、動物、風(fēng)景、汽車等,這個主要為了平衡數(shù)據(jù)集的分布以保證多樣性。最后是基于圖像的自有屬性比如喜歡數(shù)來將數(shù)據(jù)量減少至200K(從這里可以猜測Meta可能是基于自己的社交產(chǎn)品來構(gòu)建的數(shù)據(jù)集,畢竟喜歡數(shù)這些屬于比較隱私的數(shù)據(jù))。第二步是人工篩選,這個過程主要包括兩個階段。第一個階段是訓(xùn)練了一個通用的標(biāo)注器(應(yīng)該類似LAION Aesthetics Predictor,就是先人工標(biāo)注一部分?jǐn)?shù)據(jù),然后訓(xùn)練一個打分模型)來將候選圖像進一步減少到20K,畢竟第一階段得到的200K還是池子有點大,所以還需要這樣一個半自動化篩選來先排除一些低質(zhì)量圖像。第二個階段就是完全的人工了,這里是讓一些對攝影原則有深入理解的專業(yè)人士來進行高質(zhì)量圖像篩選,而篩選標(biāo)準(zhǔn)是基于攝影的基本原則,這個就非常專業(yè)了,具體包括:
- 構(gòu)圖(composition):構(gòu)圖這個東西有點抽象,大致是一個好的構(gòu)圖會主體比較突出而且畫面比較均衡。攝影有很多構(gòu)圖法,比如論文里面所提到的“三分構(gòu)圖法”,就是用兩條豎線和兩條橫線分割畫面得到4個交叉點,將畫面重點或者主體放在4個交叉點中的一個,比如下圖中的樹:
 對于構(gòu)圖,論文也舉了一些反例,比如拍攝主體都在集中在畫面的一側(cè),拍攝角度不好,拍攝對象被遮擋,或者周圍不重要的物體分散了拍攝對象的注意力,這些都造成了視覺失衡。
對于構(gòu)圖,論文也舉了一些反例,比如拍攝主體都在集中在畫面的一側(cè),拍攝角度不好,拍攝對象被遮擋,或者周圍不重要的物體分散了拍攝對象的注意力,這些都造成了視覺失衡。
- 燈光(lighting):這里主要是找那些具有平衡曝光的動態(tài)燈光,比如來自某個角度的燈光突出了所選的主體(有點難理解)。反例是人工或暗淡的燈光,以及過暗或過曝的燈光。
- 顏色和對比度(color and contrast)。正例是色彩鮮艷和對比高的圖像。反例是單色圖像或單一顏色占主導(dǎo)的圖像。
- 主體和背景(subject and background):主體應(yīng)該要突出,而且細節(jié)豐富;背景要簡潔也不能過分簡單或者單調(diào),而且要和主體之間有一定的深度感。
- 額外的主觀評價(additional subjective assessments):除此之外,還通過設(shè)置額外的問題還收集篩選員對圖像的主體評價,比如這個圖像是否是您見過的針對該特定內(nèi)容的最佳照片之一嗎?
從上述的篩選原則可以看到,這件事真的只有靠專業(yè)人士來完成,普通人沒有經(jīng)過學(xué)習(xí)和訓(xùn)練估計做不了這個工作。下圖為篩選出來的一些示例圖,可以看到圖像的視覺質(zhì)量確實比較高: 經(jīng)過人工篩選后最后只得到了2000張圖像,對于每個圖像,需要人工來生成文本描述。一個細節(jié)是這2000張圖像中有一部分圖像的分辨率是低于1024x1024的,所以需要采用一個超分模型來提升圖像的分辨率,這是采用的超分模型是參考Imagen訓(xùn)練的pixel diffusion upsampler(不太明白為啥在篩選時不增加對分辨率的嚴(yán)格控制,而是要采用超分)。在quality-tuning階段,訓(xùn)練的batch size比較小只有64(預(yù)訓(xùn)練階段的batch size一般較大,常用的是2048),同時采用0.1的noise offset。另外一個重要的點是訓(xùn)練步數(shù)不能太大,這里采用的是15K,在很小的數(shù)據(jù)集上微調(diào)模型如果訓(xùn)練足夠久必然是會過擬合的,這個訓(xùn)練步數(shù)需要做一定的實驗才能確定。另外一個比較重要的參數(shù)是學(xué)習(xí)速率,在微調(diào)的時候?qū)W習(xí)速率一般也要采用相對小的值,不過論文并沒有特別說明。
經(jīng)過人工篩選后最后只得到了2000張圖像,對于每個圖像,需要人工來生成文本描述。一個細節(jié)是這2000張圖像中有一部分圖像的分辨率是低于1024x1024的,所以需要采用一個超分模型來提升圖像的分辨率,這是采用的超分模型是參考Imagen訓(xùn)練的pixel diffusion upsampler(不太明白為啥在篩選時不增加對分辨率的嚴(yán)格控制,而是要采用超分)。在quality-tuning階段,訓(xùn)練的batch size比較小只有64(預(yù)訓(xùn)練階段的batch size一般較大,常用的是2048),同時采用0.1的noise offset。另外一個重要的點是訓(xùn)練步數(shù)不能太大,這里采用的是15K,在很小的數(shù)據(jù)集上微調(diào)模型如果訓(xùn)練足夠久必然是會過擬合的,這個訓(xùn)練步數(shù)需要做一定的實驗才能確定。另外一個比較重要的參數(shù)是學(xué)習(xí)速率,在微調(diào)的時候?qū)W習(xí)速率一般也要采用相對小的值,不過論文并沒有特別說明。
模型評測
文生圖模型的評測一般包括兩個方面:生成圖像的質(zhì)量,以及生成的圖像和文本的一致性。Emu論文中采用的兩個評測指標(biāo):visual appeal和text faithfulness,其實對應(yīng)的就是上述兩者。Imagen論文中的叫法是sample quality和image-text alignment,雖然大家的叫法不同,但是所表述的含義都是一樣的。對于圖像質(zhì)量,常采用的指標(biāo)是FID,但是這個指標(biāo)往往和人工評測結(jié)果相關(guān)性較弱,所以FID越低不代表模型生成的圖像質(zhì)量就高;對于圖像和文本的一致性,常采用的指標(biāo)是CLIP score,但是這個指標(biāo)也不是那么可靠。鑒于此,Emu直接采用了人工評測(SDXL也是直接采用人工評測),這里是單獨對兩個方面分別評測,就是說在評測圖像質(zhì)量時,讓參與者忽略圖像和文本的一致性,而反之亦然。評測共采用了兩套文本prompts:一個是包含1600個prompts的PartiPrompts,一個是自己構(gòu)建的包含2100個prompts的OUI Prompts。前者是谷歌的Parti中所采用的評測集,而后者是Meta基于真實應(yīng)用場景所收集的評測集,它包含了大家比較常用的類別和概念,具體分布如下所示: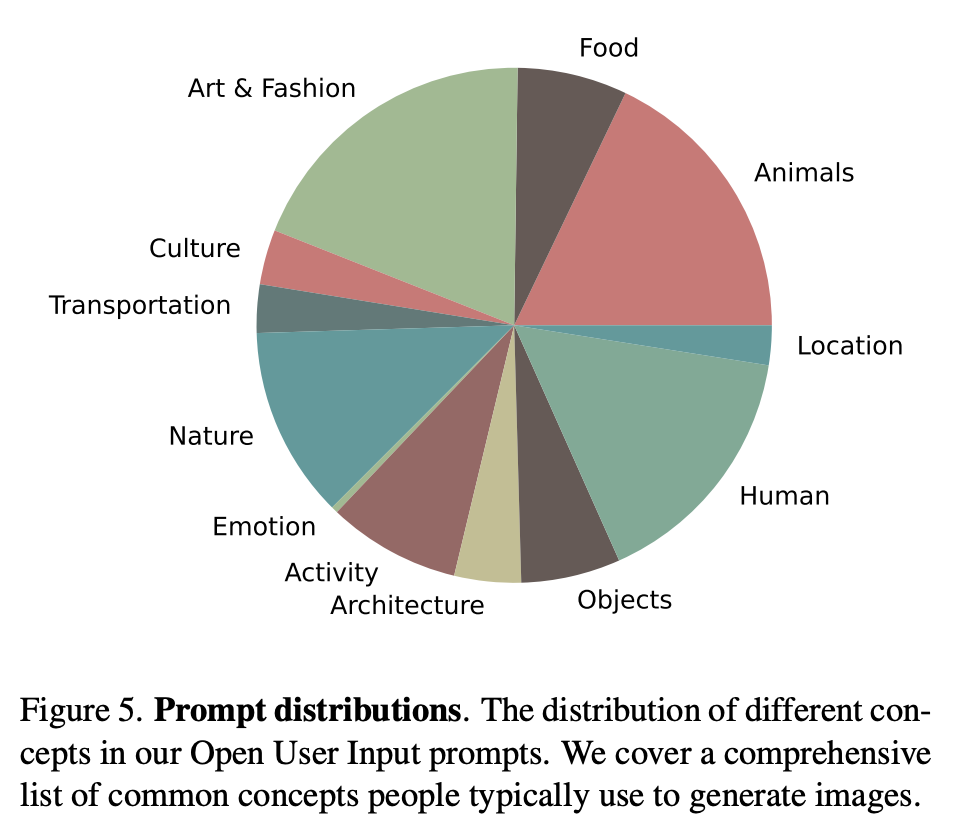 這里首先對比的是quality-tuning前后的模型,如下圖所示,可以看到在兩個評測集上,quality-tuning之后的模型在圖像質(zhì)量有明顯的提升,同時在圖像和文本的一致性上也有一定的提升。這說明適當(dāng)?shù)膓uality-tuning可以在提升生成圖像質(zhì)量的同時不丟失原來的泛化性。(這里的stylized prompts是評測集中風(fēng)格化的子集,比如草圖和漫畫,這個對比可以說明提升是比較全面的)。
這里首先對比的是quality-tuning前后的模型,如下圖所示,可以看到在兩個評測集上,quality-tuning之后的模型在圖像質(zhì)量有明顯的提升,同時在圖像和文本的一致性上也有一定的提升。這說明適當(dāng)?shù)膓uality-tuning可以在提升生成圖像質(zhì)量的同時不丟失原來的泛化性。(這里的stylized prompts是評測集中風(fēng)格化的子集,比如草圖和漫畫,這個對比可以說明提升是比較全面的)。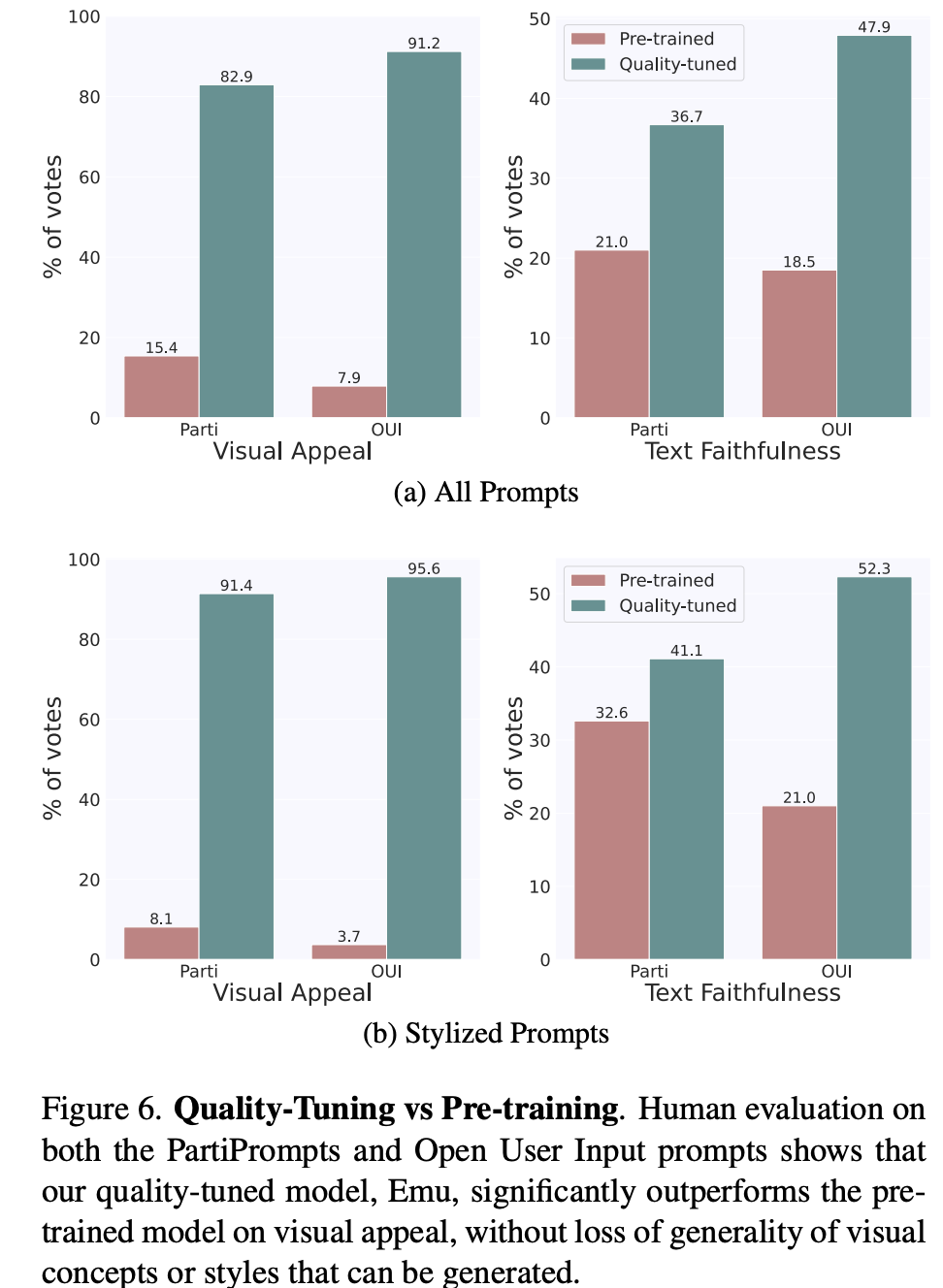 對于圖像和文本的一致性方面的提升,這應(yīng)該是歸功于這2000張高質(zhì)量圖像的文本描述是人工生成的,相比預(yù)訓(xùn)練數(shù)據(jù)集的標(biāo)注噪音很小。下面展示了幾個具體的生成圖像對比,可以看到經(jīng)過quality-tuning之后,生成圖像的質(zhì)量確實有明顯的提升,而且美感也和用于quality-tuning訓(xùn)練的高質(zhì)量圖像比較類似。
對于圖像和文本的一致性方面的提升,這應(yīng)該是歸功于這2000張高質(zhì)量圖像的文本描述是人工生成的,相比預(yù)訓(xùn)練數(shù)據(jù)集的標(biāo)注噪音很小。下面展示了幾個具體的生成圖像對比,可以看到經(jīng)過quality-tuning之后,生成圖像的質(zhì)量確實有明顯的提升,而且美感也和用于quality-tuning訓(xùn)練的高質(zhì)量圖像比較類似。 論文還將Emu和SDXL進行了對比,可以看到Emu在圖像質(zhì)量上也明顯優(yōu)于SDXL(畢竟SDXL沒有進行quality-tuning)。
論文還將Emu和SDXL進行了對比,可以看到Emu在圖像質(zhì)量上也明顯優(yōu)于SDXL(畢竟SDXL沒有進行quality-tuning)。
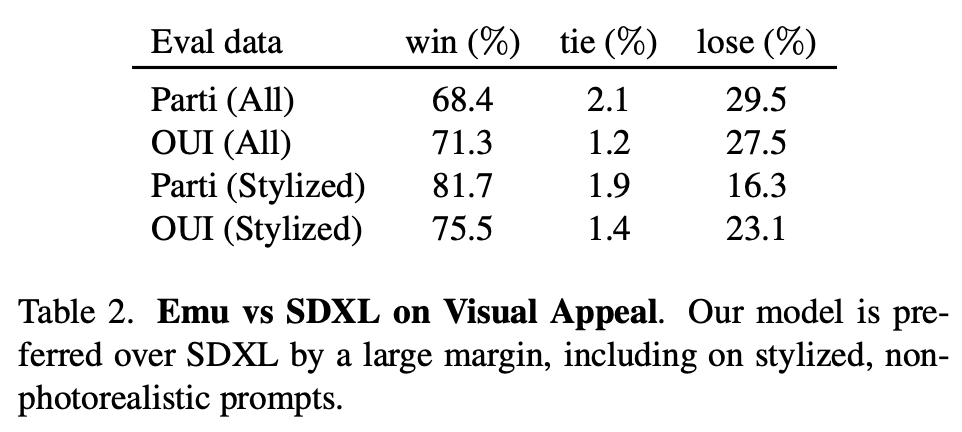 另外,論文還進行了數(shù)據(jù)量的實驗,如下表所示,可以看到只需要100張高質(zhì)量圖像,模型的生成質(zhì)量就有一個明顯的提升,這說明數(shù)據(jù)并不需要太多。不過,這里缺少的是數(shù)據(jù)量更大(超過2000張)的實驗,2000可能并不是最佳值。
另外,論文還進行了數(shù)據(jù)量的實驗,如下表所示,可以看到只需要100張高質(zhì)量圖像,模型的生成質(zhì)量就有一個明顯的提升,這說明數(shù)據(jù)并不需要太多。不過,這里缺少的是數(shù)據(jù)量更大(超過2000張)的實驗,2000可能并不是最佳值。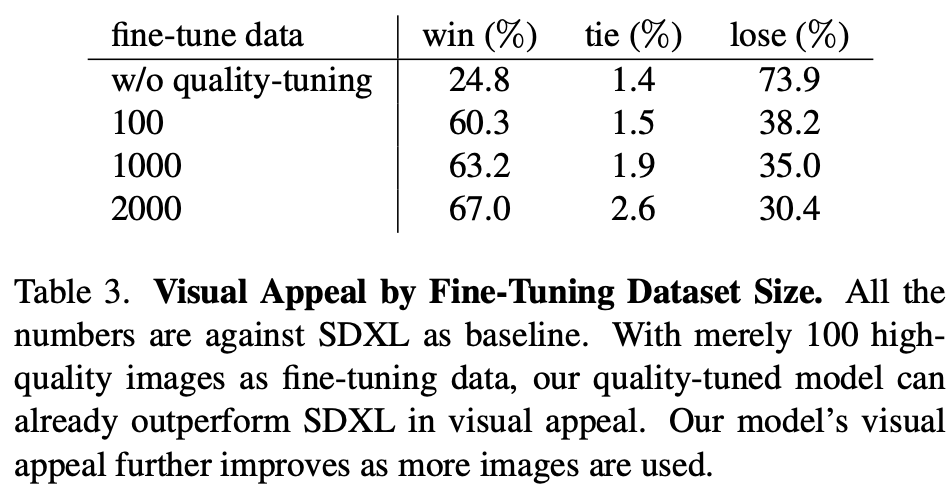
quality-tuning是通用的,它不僅可以應(yīng)用在latent diffusion文生圖模型上,也可以應(yīng)用在pixel diffusion(參考谷歌的Imagen)和masked generative transformer(參考谷歌的Muse)架構(gòu)上: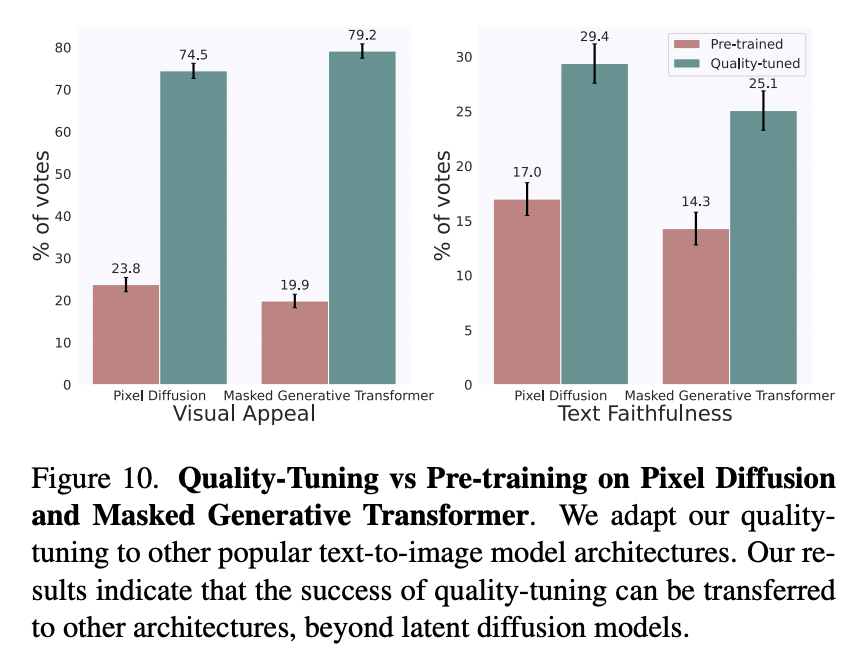 下面展示了更多的生成樣例,可以看出生成圖像的質(zhì)量還是非常高的:
下面展示了更多的生成樣例,可以看出生成圖像的質(zhì)量還是非常高的:
 image.png
image.png
結(jié)語
正如前言所說,學(xué)術(shù)界在文生圖方面的大部分的工作主要是提升基底模型(即pre-training模型)以及一些個性化生成(如DreamBooth)和可控生成(如ControlNet),但是對于quality-tuning方面卻比較少(雖然之前有少部分工作通過強化學(xué)習(xí)來提升模型,但并沒有太驚艷),而社區(qū)早已經(jīng)大量使用quality-tuning了,相信這個工作之后會有更多的關(guān)于quality-tuning的學(xué)術(shù)論文。另外我也非常贊同論文中所提到的一個觀點:
Our hypothesis is that a strongly pre-trained model is already capable of generating highly aesthetic images, but the generation process is not properly guided towards always producing images with these statistics. Quality-tuning effectively restricts outputs to a high-quality subset.
這就是說預(yù)訓(xùn)練模型其實很強大,它本身已經(jīng)具有生成高質(zhì)量樣本的能力,但是由于預(yù)訓(xùn)練數(shù)據(jù)往往噪音很大,使得預(yù)訓(xùn)練模型在實際生成中往往更容易生成低質(zhì)量樣本。而quality-tuning所做的就是通過適當(dāng)?shù)奈⒄{(diào)將預(yù)訓(xùn)練模型收縮到高質(zhì)量空間,這個引導(dǎo)可能并不需要太大的數(shù)據(jù)量。對于LLMs,我覺得這個觀點也是適用的。所以,預(yù)訓(xùn)練模型其實還是相當(dāng)重要的,它其實在一定程度上決定了上限,因為基于少量數(shù)據(jù)的微調(diào)只是一種引導(dǎo),并不太可能在模型中引入新的知識。當(dāng)然,要找到這個高質(zhì)量空間,還是需要比較多的tricks,煉丹也是很重要。
參考
- https://ai.meta.com/research/publications/emu-enhancing-image-generation-models-using-photogenic-needles-in-a-haystack/
- Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
推薦閱讀
使用PyTorch 2.0加速Transformer:訓(xùn)練推理均拿下!
機器學(xué)習(xí)算法工程師
一個用心的公眾號
