
送你一份 SQL 進(jìn)階技巧
由于工作需要,最近做了很多 BI 取數(shù)的工作,需要用到一些比較高級的 SQL 技巧,總結(jié)了一下工作中用到的一些比較騷的進(jìn)階技巧,特此記錄一下,以方便自己查閱,主要目錄如下:
SQL 的書寫規(guī)范 SQL 的一些進(jìn)階使用技巧 SQL 的優(yōu)化方法
SQL 的書寫規(guī)范
在介紹一些技巧之前,有必要強(qiáng)調(diào)一下規(guī)范,這一點我發(fā)現(xiàn)工作中經(jīng)常被人忽略,其實遵循好的規(guī)范可讀性會好很多,應(yīng)該遵循哪些規(guī)范呢
1、 表名要有意義,且標(biāo)準(zhǔn) SQL 中規(guī)定表名的第一個字符應(yīng)該是字母。
2、注釋,有單行注釋和多行注釋,如下
-- 單行注釋
-- 從SomeTable中查詢col_1
SELECT col_1
FROM SomeTable;
/*
多行注釋
從 SomeTable 中查詢 col_1
*/
SELECT col_1
FROM SomeTable;
多行注釋很多人不知道,這種寫法不僅可以用來添加真正的注釋,也可以用來注釋代碼,非常方便
3、縮進(jìn)
就像寫 Java,Python 等編程語言一樣 ,SQL 也應(yīng)該有縮進(jìn),良好的縮進(jìn)對提升代碼的可讀性幫助很大,以下分別是好的縮進(jìn)與壞的縮進(jìn)示例
-- 好的縮進(jìn)
SELECT col_1,
col_2,
col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1,
col_2,
col_3
-- 壞的示例
SELECT col1_1, col_2, col_3, COUNT(*)
FROM tbl_A
WHERE col1_1 = 'a'
AND col1_2 = (
SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
) GROUP BY col_1, col_2, col_3
4、空格
代碼中應(yīng)該適當(dāng)留有一些空格,如果一點不留,代碼都湊到一起, 邏輯單元不明確,閱讀的人也會產(chǎn)生額外的壓力,以下分別是是好的與壞的示例
-- 好的示例
SELECT col_1
FROM tbl_A A, tbl_B B
WHERE ( A.col_1 >= 100 OR A.col_2 IN ( 'a', 'b' ) )
AND A.col_3 = B.col_3;
-- 壞的示例
SELECT col_1
FROM tbl_A A,tbl_B B
WHERE (A.col_1>=100 OR A.col_2 IN ('a','b'))
AND A.col_3=B.col_3;
5、大小寫
關(guān)鍵字使用大小寫,表名列名使用小寫,如下
SELECT col_1, col_2, col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1, col_2, col_3
花了這么多時間強(qiáng)調(diào)規(guī)范,有必要嗎,有!好的規(guī)范讓代碼的可讀性更好,更有利于團(tuán)隊合作,之后的 SQL 示例都會遵循這些規(guī)范。
SQL 的一些進(jìn)階使用技巧
一、巧用 CASE WHEN 進(jìn)行統(tǒng)計
來看看如何巧用 CASE WHEN 進(jìn)行定制化統(tǒng)計,假設(shè)我們有如下的需求,希望根據(jù)左邊各個市的人口統(tǒng)計每個省的人口
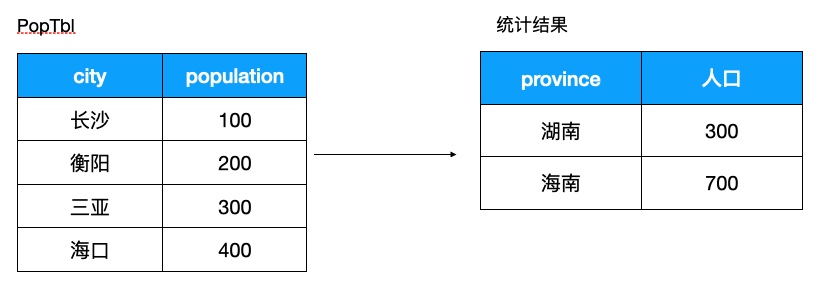
使用 CASE WHEN 如下
SELECT CASE pref_name
WHEN '長沙' THEN '湖南'
WHEN '衡陽' THEN '湖南'
WHEN '海口' THEN '海南'
WHEN '三亞' THEN '海南'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
GROUP BY district;
二、巧用 CASE WHEN 進(jìn)行更新
現(xiàn)在某公司員人工資信息表如下:
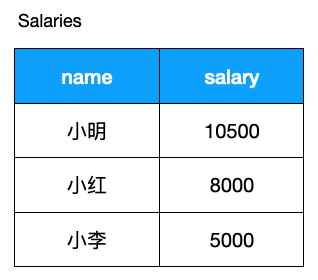
現(xiàn)在公司出臺了一個奇葩的規(guī)定
對當(dāng)前工資為 1 萬以上的員工,降薪 10%。 對當(dāng)前工資低于 1 萬的員工,加薪 20%。
一些人不假思索可能寫出了以下的 SQL:
--條件1
UPDATE Salaries
SET salary = salary * 0.9 WHERE salary >= 10000;
--條件2
UPDATE Salaries
SET salary = salary * 1.2
WHERE salary < 10000;
這么做其實是有問題的, 什么問題,對小明來說,他的工資是 10500,執(zhí)行第一個 SQL 后,工資變?yōu)?10500 * 0.9 = 9450, 緊接著又執(zhí)行條件 2, 工資變?yōu)榱?9450 * 1.2 = 11340,反而漲薪了!
如果用 CASE WHEN 可以解決此類問題,如下:
UPDATE Salaries
SET salary = CASE WHEN salary >= 10000 THEN salary * 0.9
WHEN salary < 10000 THEN salary * 1.2
ELSE salary END;
三、巧用 HAVING 子句
一般 HAVING 是與 GROUP BY 結(jié)合使用的,但其實它是可以獨立使用的, 假設(shè)有如下表,第一列 seq 叫連續(xù)編號,但其實有些編號是缺失的,怎么知道編號是否缺失呢,
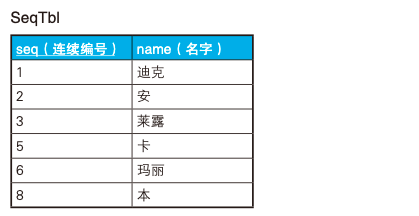
用 HAVING 表示如下:
SELECT '存在缺失的編號' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
四、自連接
針對相同的表進(jìn)行的連接被稱為“自連接”(self join),這個技巧常常被人們忽視,其實是有挺多妙用的
1、刪除重復(fù)行
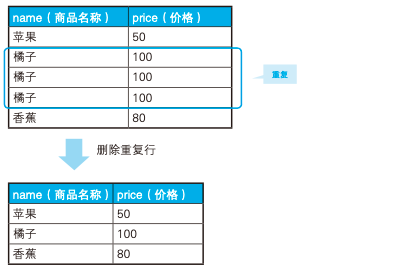
上圖中有三個橘子,需要把這些重復(fù)的行給刪掉,用如下自連接可以解決:
DELETE FROM Products P1
WHERE id < ( SELECT MAX(P2.id)
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price );
2、排序
在 db 中,我們經(jīng)常需要按分?jǐn)?shù),人數(shù),銷售額等進(jìn)行排名,有 Oracle, DB2 中可以使用 RANK 函數(shù)進(jìn)行排名,不過在 MySQL 中 RANK 函數(shù)未實現(xiàn),這種情況我們可以使用自連接來實現(xiàn),如對以下 Products 表按價格高低進(jìn)行排名
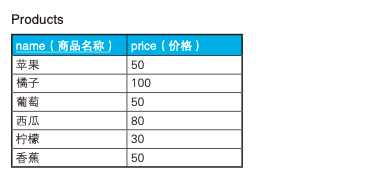
使用自連接可以這么寫:
-- 排序從 1 開始。如果已出現(xiàn)相同位次,則跳過之后的位次
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
結(jié)果如下:
name price rank
----- ------ ------
橘子 100 1
西瓜 80 2
蘋果 50 3
葡萄 50 3
香蕉 50 3
檸檬 30 6
五、巧用 COALESCE 函數(shù)
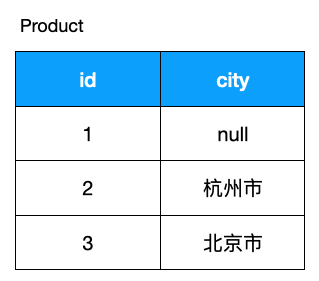
此函數(shù)作用返回參數(shù)中的第一個非空表達(dá)式,假設(shè)有如下商品,我們重新格式化一樣,如果 city 為 null,代表商品不在此城市發(fā)行,但我們在展示結(jié)果的時候不想展示 null,而想展示 'N/A', 可以這么做:
SELECT
COALESCE(city, 'N/A')
FROM
customers;
SQL 性能優(yōu)化技巧
一、參數(shù)是子查詢時,使用 EXISTS 代替 IN
如果 IN 的參數(shù)是(1,2,3)這樣的值列表時,沒啥問題,但如果參數(shù)是子查詢時,就需要注意了。比如,現(xiàn)在有如下兩個表:
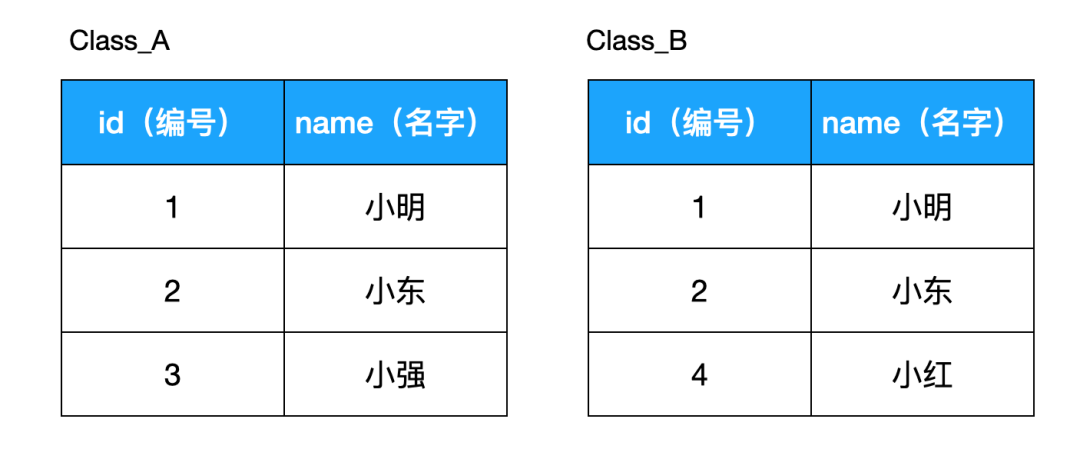
現(xiàn)在我們要查出同時存在于兩個表的員工,即田中和鈴木,則以下用 IN 和 EXISTS 返回的結(jié)果是一樣,但是用 EXISTS 的 SQL 會更快:
-- 慢
SELECT *
FROM Class_A
WHERE id IN (SELECT id
FROM CLASS_B);
-- 快
SELECT *
FROM Class_A A
WHERE EXISTS
(SELECT *
FROM Class_B B
WHERE A.id = B.id);
為啥使用 EXISTS 的 SQL 運行更快呢,有兩個原因
可以`用到索引,如果連接列 (id) 上建立了索引,那么查詢 Class_B 時不用查實際的表,只需查索引就可以了。 如果使用 EXISTS,那么只要查到一行數(shù)據(jù)滿足條件就會終止查詢, 不用像使用 IN 時一樣掃描全表。在這一點上 NOT EXISTS 也一樣
另外如果 IN 后面如果跟著的是子查詢,由于 SQL 會先執(zhí)行 IN 后面的子查詢,會將子查詢的結(jié)果保存在一張臨時的工作表里(內(nèi)聯(lián)視圖),然后掃描整個視圖,顯然掃描整個視圖這個工作很多時候是非常耗時的,而用 EXISTS 不會生成臨時表。
當(dāng)然了,如果 IN 的參數(shù)是子查詢時,也可以用連接來代替,如下:
-- 使用連接代替 IN SELECT A.id, A.name
FROM Class_A A INNER JOIN Class_B B ON A.id = B.id;
用到了 「id」列上的索引,而且由于沒有子查詢,也不會生成臨時表
二、避免排序
SQL 是聲明式語言,即對用戶來說,只關(guān)心它能做什么,不用關(guān)心它怎么做。這樣可能會產(chǎn)生潛在的性能問題:排序,會產(chǎn)生排序的代表性運算有下面這些
GROUP BY 子句 ORDER BY 子句 聚合函數(shù)(SUM、COUNT、AVG、MAX、MIN) DISTINCT 集合運算符(UNION、INTERSECT、EXCEPT) 窗口函數(shù)(RANK、ROW_NUMBER 等)
如果在內(nèi)存中排序還好,但如果內(nèi)存不夠?qū)е滦枰谟脖P上排序上的話,性能就會急劇下降,所以我們需要減少不必要的排序。怎樣做可以減少排序呢。
1、 使用集合運算符的 ALL 可選項
SQL 中有 UNION,INTERSECT,EXCEPT 三個集合運算符,默認(rèn)情況下,這些運算符會為了避免重復(fù)數(shù)據(jù)而進(jìn)行排序,對比一下使用 UNION 運算符加和不加 ALL 的情況:
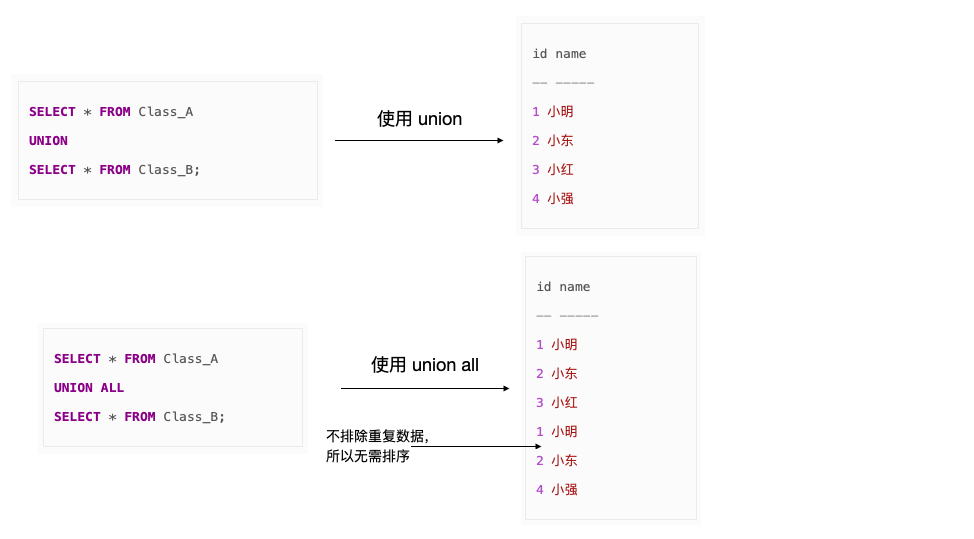
注意:加 ALL 是優(yōu)化性能非常有效的手段,不過前提是不在乎結(jié)果是否有重復(fù)數(shù)據(jù)。
2、使用 EXISTS 代表 DISTINCT
為了排除重復(fù)數(shù)據(jù), DISTINCT 也會對結(jié)果進(jìn)行排序,如果需要對兩張表的連接結(jié)果進(jìn)行去重,可以考慮用 EXISTS 代替 DISTINCT,這樣可以避免排序。
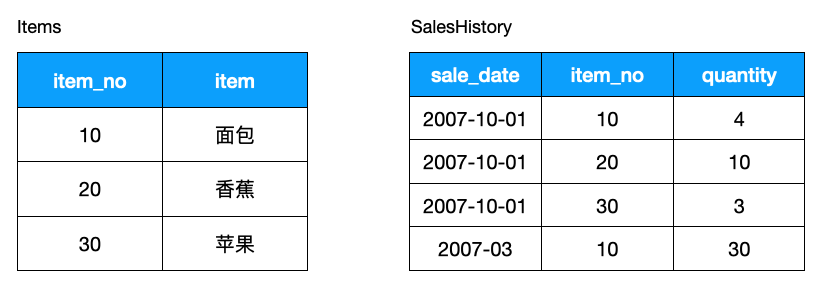
如何找出有銷售記錄的商品,使用如下 DISTINCT 可以:
SELECT DISTINCT I.item_no
FROM Items I INNER JOIN SalesHistory SH
ON I. item_no = SH. item_no;
不過更好的方式是使用 EXISTS:
SELECT item_no FROM Items I
WHERE EXISTS
(SELECT *
FROM SalesHistory SH
WHERE I.item_no = SH.item_no);
既用到了索引,又避免了排序?qū)π阅艿膿p耗。
二、在極值函數(shù)中使用索引(MAX/MIN)
使用 MAX/ MIN 都會對進(jìn)行排序,如果參數(shù)字段上沒加索引會導(dǎo)致全表掃描,如果建有索引,則只需要掃描索引即可,對比如下
-- 這樣寫需要掃描全表
SELECT MAX(item)
FROM Items;
-- 這樣寫能用到索引
SELECT MAX(item_no)
FROM Items;
注意:極值函數(shù)參數(shù)推薦為索引列中并不是不需要排序,而是優(yōu)化了排序前的查找速度(畢竟索引本身就是有序排列的)。
三、能寫在 WHERE 子句里的條件不要寫在 HAVING 子句里
下列 SQL 語句返回的結(jié)果是一樣的:
-- 聚合后使用 HAVING 子句過濾
SELECT sale_date, SUM(quantity)
FROM SalesHistory GROUP BY sale_date
HAVING sale_date = '2007-10-01';
-- 聚合前使用 WHERE 子句過濾
SELECT sale_date, SUM(quantity)
FROM SalesHistory
WHERE sale_date = '2007-10-01'
GROUP BY sale_date;
使用第二條語句效率更高,原因主要有兩點
使用 GROUP BY 子句進(jìn)行聚合時會進(jìn)行排序,如果事先通過 WHERE 子句能篩選出一部分行,能減輕排序的負(fù)擔(dān) 在 WHERE 子句中可以使用索引,而 HAVING 子句是針對聚合后生成的視頻進(jìn)行篩選的,但很多時候聚合后生成的視圖并沒有保留原表的索引結(jié)構(gòu)
四、在 GROUP BY 子句和 ORDER BY 子句中使用索引
GROUP BY 子句和 ORDER BY 子句一般都會進(jìn)行排序,以對行進(jìn)行排列和替換,不過如果指定帶有索引的列作為這兩者的參數(shù)列,由于用到了索引,可以實現(xiàn)高速查詢,由于索引是有序的,排序本身都會被省略掉
五、使用索引時,條件表達(dá)式的左側(cè)應(yīng)該是原始字段
假設(shè)我們在 col 列上建立了索引,則下面這些 SQL 語句無法用到索引
SELECT *
FROM SomeTable
WHERE col * 1.1 > 100;
SELECT *
FROM SomeTable
WHERE SUBSTR(col, 1, 1) = 'a';
以上第一個 SQL 在索引列上進(jìn)行了運算, 第二個 SQL 對索引列使用了函數(shù),均無法用到索引,正確方式是把列單獨放在左側(cè),如下:
SELECT *
FROM SomeTable
WHERE col_1 > 100 / 1.1;
當(dāng)然如果需要對此列使用函數(shù),則無法避免在左側(cè)運算,可以考慮使用函數(shù)索引,不過一般不推薦隨意這么做。
六、盡量避免使用否定形式
如下的幾種否定形式不能用到索引:
<> != NOT IN
所以以下 了SQL 語句會導(dǎo)致全表掃描
SELECT *
FROM SomeTable
WHERE col_1 <> 100;
可以改成以下形式
SELECT *
FROM SomeTable
WHERE col_1 > 100 or col_1 < 100;
七、進(jìn)行默認(rèn)的類型轉(zhuǎn)換
假設(shè) col 是 char 類型,則推薦使用以下第二,三條 SQL 的寫法,不推薦第一條 SQL 的寫法
× SELECT * FROM SomeTable WHERE col_1 = 10;
○ SELECT * FROM SomeTable WHERE col_1 = '10';
○ SELECT * FROM SomeTable WHERE col_1 = CAST(10, AS CHAR(2));
雖然第一條 SQL 會默認(rèn)把 10 轉(zhuǎn)成 '10',但這種默認(rèn)類型轉(zhuǎn)換不僅會增加額外的性能開銷,還會導(dǎo)致索引不可用,所以建議使用的時候進(jìn)行類型轉(zhuǎn)換。
八、減少中間表
在 SQL 中,子查詢的結(jié)果會產(chǎn)生一張新表,不過如果不加限制大量使用中間表的話,會帶來兩個問題,一是展示數(shù)據(jù)需要消耗內(nèi)存資源,二是原始表中的索引不容易用到,所以盡量減少中間表也可以提升性能。
九、靈活使用 HAVING 子句
這一點與上面第八條相呼應(yīng),對聚合結(jié)果指定篩選條件時,使用 HAVING 是基本的原則,可能一些工程師會傾向于使用下面這樣的寫法:
SELECT *
FROM (SELECT sale_date, MAX(quantity) AS max_qty
FROM SalesHistory
GROUP BY sale_date) TMP
WHERE max_qty >= 10;
雖然上面這樣的寫法能達(dá)到目的,但會生成 TMP 這張臨時表,所以應(yīng)該使用下面這樣的寫法:
SELECT sale_date, MAX(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;
HAVING 子句和聚合操作是同時執(zhí)行的,所以比起生成中間表后再執(zhí)行 HAVING 子句,效率會更高,代碼也更簡潔
十、需要對多個字段使用 IN 謂詞時,將它們匯總到一處
一個表的多個字段可能都使用了 IN 謂詞,如下:
SELECT id, state, city
FROM Addresses1 A1
WHERE state IN (SELECT state
FROM Addresses2 A2
WHERE A1.id = A2.id)
AND city IN (SELECT city
FROM Addresses2 A2
WHERE A1.id = A2.id);
這段代碼用到了兩個子查詢,也就產(chǎn)生了兩個中間表,可以像下面這樣寫
SELECT *
FROM Addresses1 A1
WHERE id || state || city
IN (SELECT id || state|| city
FROM Addresses2 A2);
這樣子查詢不用考慮關(guān)聯(lián)性,沒有中間表產(chǎn)生,而且只執(zhí)行一次即可。
總結(jié)
本文一開始花了挺大的篇幅來講解 SQL 的規(guī)范,請大家務(wù)必重視這部分內(nèi)部,良好的規(guī)范有利于團(tuán)隊協(xié)作,對于代碼的閱讀也比較友好。
之后介紹了一些 SQL 的比較高級的用法,巧用這些技巧確實能達(dá)到事半功倍的效果,由于本文篇幅有限只是介紹了一部分,下篇我們會再介紹一些其他的技巧,敬請期待哦
巨人的肩膀
<<SQL 進(jìn)階教程>>
我是岳哥,最后給大家分享我寫的SQL兩件套:《SQL基礎(chǔ)知識第二版》和《SQL高級知識第二版》的PDF電子版。里面有各個語法的解釋、大量的實例講解和批注等等,非常通俗易懂,方便大家跟著一起來實操。
有需要的讀者可以下載學(xué)習(xí),在下面的公眾號「數(shù)據(jù)前線」(非本號)后臺回復(fù)關(guān)鍵字:SQL,就行
數(shù)據(jù)前線
——End——
后臺回復(fù)關(guān)鍵字:1024,獲取一份精心整理的技術(shù)干貨
后臺回復(fù)關(guān)鍵字:進(jìn)群,帶你進(jìn)入高手如云的交流群。
推薦閱讀

