
盤點(diǎn)Python正則表達(dá)式中的貪婪模式和非貪婪模式
回復(fù)“資源”即可獲贈Python學(xué)習(xí)資料
大家好,我是我是皮皮。
一、前言
前幾天在Python最強(qiáng)王者交流群有個叫【杰】的粉絲問了一個關(guān)于Python正則表達(dá)式的問題,其中涉及到Python正則表達(dá)式中的貪婪模式和非貪婪模式,討論十分火熱,這里拿出來給大家分享下,一起學(xué)習(xí)。
二、解決過程
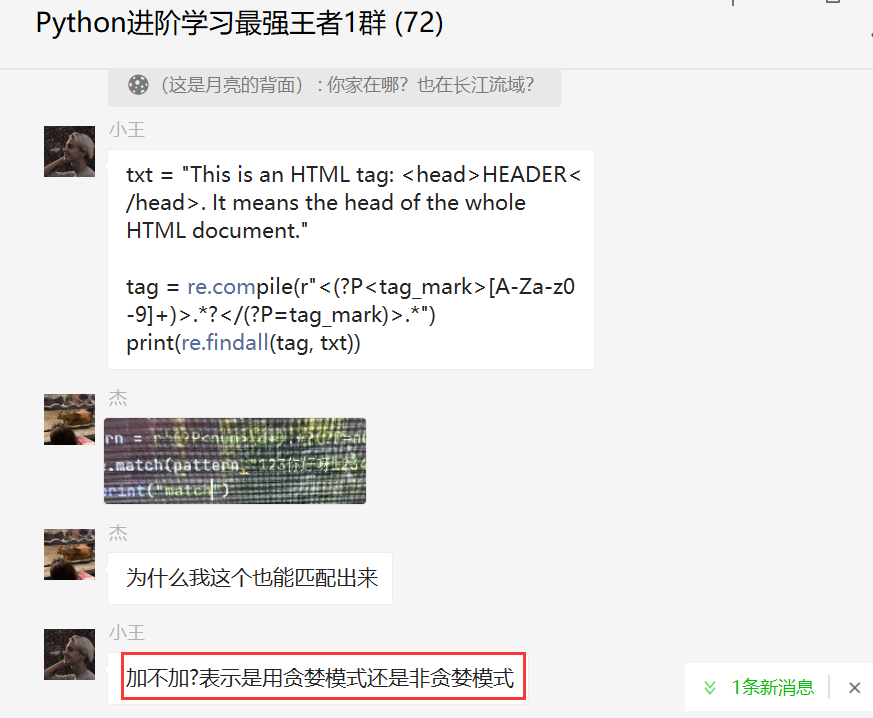
這里分享【小王】大佬的解答,一起來看看吧,下面是他給的一個示例代碼。
import?re
txt?=?"This?is?an?HTML?tag:?HEADER.?It?means?the?head?of?the?whole?HTML?document."
pattern1?=?re.compile(r"<.*>")
pattern2?=?re.compile(r"<.*?>")
result1?=?re.findall(pattern1,?txt)
result2?=?re.findall(pattern2,?txt)
print(result1)
print(result2)
輸出結(jié)果如下圖所示:

關(guān)于輸出的解析如下:
我想匹配HTML標(biāo)簽中的數(shù)據(jù),也就是<>之間的數(shù)據(jù)。
pattern1?=?re.compile(r"<.*>")
pattern2?=?re.compile(r"<.*?>")
這兩種只相差了一個?,但是區(qū)別卻很大。解析如下圖所示:
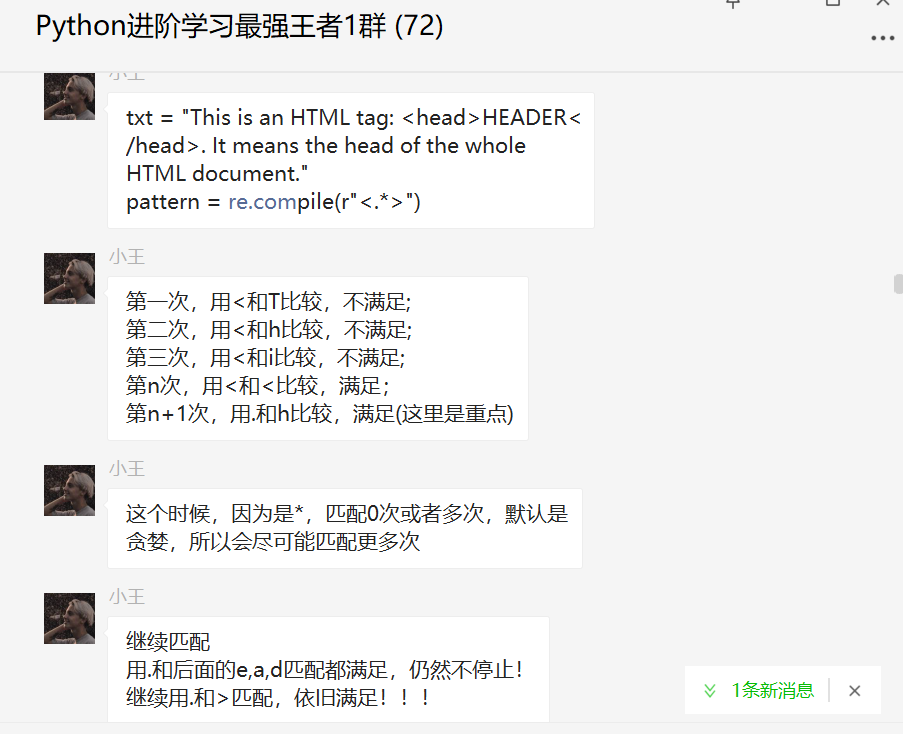
直到什么時候停止呢?
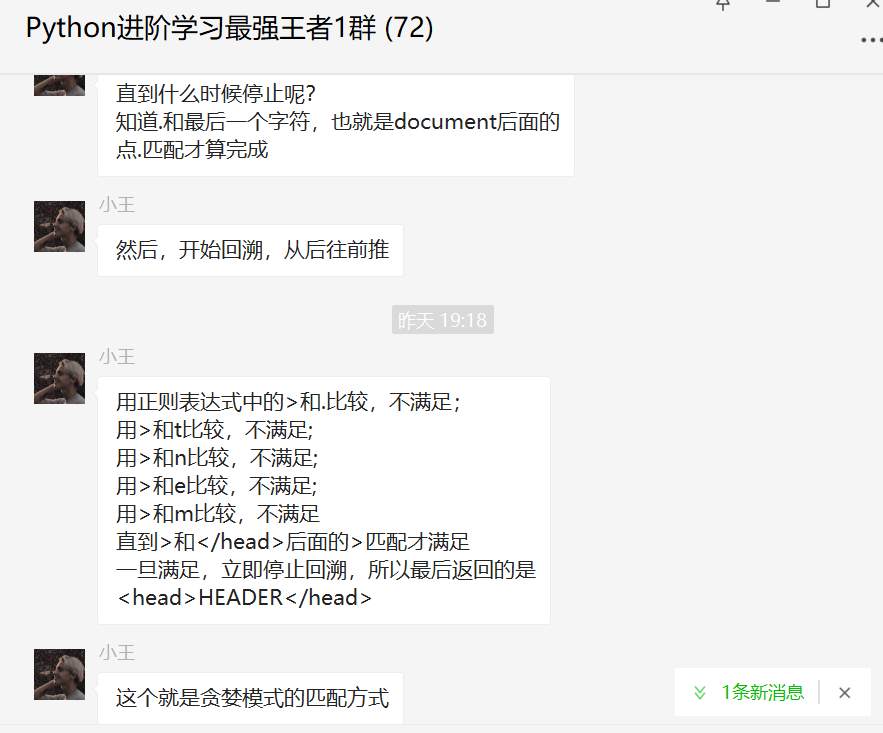
這個就是貪婪模式的匹配方式,那么非貪婪模式呢?

小彩蛋
分享一個【小王】大佬的代碼,實(shí)現(xiàn)的效果是將正則匹配結(jié)果寫成命名分組Python代碼。
常規(guī)寫法如下所示:
import?re
txt?=?"This?is?an?HTML?tag:?HEADER.?It?means?the?head?of?the?whole?HTML?document."
tag?=?re.compile(r"<([A-Za-z0-9]+)>.*?.*")
print(re.findall(tag,?txt))
寫成命名分組的寫法如下所示:
txt?=?"This?is?an?HTML?tag:?HEADER.?It?means?the?head?of?the?whole?HTML?document."
tag?=?re.compile(r"<(?P[A-Za-z0-9]+)>.*?.*" )
print(re.findall(tag,?txt))
總結(jié)
大家好,我是皮皮。這篇文章基于粉絲提問,針對Python正則表達(dá)式中的貪婪模式和非貪婪模式問題,給出了具體說明和演示,順利的幫助粉絲解決了問題。
最后感謝粉絲【杰】提問,感謝【小王】大佬給出的解答和示例,感謝【??(這是月亮的背面)】、【dcpeng】、【wangning】、【Chloé P.】等大佬們參與學(xué)習(xí)交流。
小伙伴們,快快用實(shí)踐一下吧!如果在學(xué)習(xí)過程中,有遇到任何問題,歡迎加我好友,我拉你進(jìn)Python學(xué)習(xí)交流群共同探討學(xué)習(xí)。
-------------------?End?-------------------
往期精彩文章推薦:

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請?jiān)诤笈_回復(fù)【入群】
萬水千山總是情,點(diǎn)個【在看】行不行