
CVPR 2021論文視角:計算機(jī)視覺現(xiàn)狀
點擊上方“機(jī)器學(xué)習(xí)與生成對抗網(wǎng)絡(luò)”,關(guān)注星標(biāo)
獲取有趣、好玩的前沿干貨!
本文根據(jù)今年的CVPR錄用結(jié)果總結(jié)出了一些CV領(lǐng)域相關(guān)的發(fā)展現(xiàn)狀。
計算機(jī)視覺(Computer Vision, CV)是人工智能領(lǐng)域的一個領(lǐng)域,致力于讓計算機(jī)能夠像人類一樣識別和處理圖像和視頻中的物體。以前,計算機(jī)視覺只能在有限的能力下工作。但由于深度學(xué)習(xí)的進(jìn)步,該領(lǐng)域近年來取得了巨大的飛躍,現(xiàn)在正在迅速改變不同的行業(yè)!

CV的變化如此之快,實際上僅去年一年,我們就經(jīng)歷了10年的變化,發(fā)表了超過4.5萬篇論文,OpenAI (iGPT[18]和CLIP[10])和谷歌(v - g /14[19])等大型科技公司發(fā)布了許多怪物模型!跟上這個領(lǐng)域?qū)γ總€人來說都是一個挑戰(zhàn)!
在這篇文章中,你可以閱讀我們的CVPR會議總結(jié)。CVPR (Computer Vision and Pattern Recognition,計算機(jī)視覺與模式識別)是計算機(jī)視覺領(lǐng)域最重要的會議之一。今年,CVPR共舉辦了83個研討會,30個教程,50多個贊助者,12次會議共發(fā)表了超過1600篇論文(其中7093篇論文,錄收率約23%)。
最近的趨勢
在2021年的CVPR上,CV的各個子領(lǐng)域都顯示出了有希望的改進(jìn)。在過去幾年中,包括分割和對象分類在內(nèi)的一些主題一直是人們關(guān)注的焦點,但最近又出現(xiàn)了一些新主題,并在2021年登上了中心舞臺。我們的總結(jié)集中在以下主題:
使用對抗性例子學(xué)習(xí)
自監(jiān)督和對比學(xué)習(xí)
視覺語言模型
有限數(shù)據(jù)學(xué)習(xí)
我們還分享了對CV很重要的兩個行業(yè)的見解:
零售
自主駕駛
使用對抗性示例學(xué)習(xí)概述
深度學(xué)習(xí)和計算機(jī)視覺系統(tǒng)在各種任務(wù)上都取得了成功,但它們也有缺點。最近引起研究界注意的一個問題是這些系統(tǒng)對對抗樣本的敏感性。一個對抗性的例子是一個嘈雜的圖像,旨在欺騙系統(tǒng)做出錯誤的預(yù)測 [1]。為了在現(xiàn)實世界中部署這些系統(tǒng),它們必須能夠檢測到這些示例。為此,最近的工作探索了通過在訓(xùn)練過程中包含對抗性示例來使這些系統(tǒng)更強(qiáng)大對抗對抗性攻擊的可能性。
使用對抗樣本學(xué)習(xí)的利弊
優(yōu)點:傳統(tǒng)的深度學(xué)習(xí)方法對數(shù)據(jù)集中的每個訓(xùn)練樣本均等地加權(quán),而不管標(biāo)簽的正確性。這可能會使學(xué)習(xí)過程脫軌,尤其是在標(biāo)簽包含噪聲的情況下。通過對抗性學(xué)習(xí),當(dāng)加入不同級別的噪聲時,每個樣本的可靠性可以根據(jù)其預(yù)測標(biāo)簽的穩(wěn)定性來估計。這使模型能夠識別和關(guān)注對噪聲更具彈性的樣本,從而降低其對對抗性示例的敏感性。此外,在訓(xùn)練機(jī)制中包含對抗性示例已被證明超過了標(biāo)準(zhǔn)任務(wù)的基準(zhǔn),例如對象分類和檢測。這在半監(jiān)督設(shè)置中很有用,即當(dāng)標(biāo)記數(shù)據(jù)供應(yīng)有限時。
缺點:對抗性訓(xùn)練涉及設(shè)置“epsilon”參數(shù),該參數(shù)控制添加到每個樣本的噪聲量。過高的“epsilon”可能會阻礙學(xué)習(xí)過程。此外,[2] 中所做的實驗表明,隨著大型標(biāo)記數(shù)據(jù)集的可用,監(jiān)督學(xué)習(xí)技術(shù)的性能趕上了對抗性訓(xùn)練技術(shù),使得對抗性訓(xùn)練的優(yōu)勢變得不那么深刻。
使用對抗樣本學(xué)習(xí)的最新技術(shù)
SENTRY:此方法在遷移學(xué)習(xí)的設(shè)置中使用對抗性示例。遷移學(xué)習(xí)是深度學(xué)習(xí)的領(lǐng)域,其中在源分布上訓(xùn)練的模型在不同的目標(biāo)分布上進(jìn)行微調(diào)和評估。在目標(biāo)分布中,SENTRY 解決了分配給所有樣本的權(quán)重相等的問題。它使用“預(yù)測一致性”方法識別可靠的目標(biāo)實例。在這種方法中,模型的預(yù)測置信度在被認(rèn)為可靠的高度一致的目標(biāo)實例上增加。更具體地說,一個實例,連同它自身的幾個增強(qiáng)版本,被輸入到一個模型集合中。評估每個模型的預(yù)測的一致性。如果更多模型的預(yù)測一致,則目標(biāo)實例是可靠的,因此應(yīng)該用于最小化熵?fù)p失。如果預(yù)測不一致,則目標(biāo)實例不可靠,因此應(yīng)忽略。按照這種方法,SENTRY 在 DomainNet [3] 上實現(xiàn)了 SOTA,這是一個標(biāo)準(zhǔn)數(shù)據(jù)集,用于評估模型的遷移學(xué)習(xí)能力。

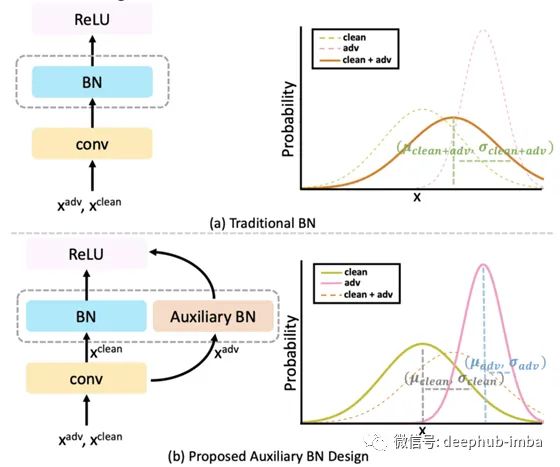
AdvProp:在訓(xùn)練中包含對抗性示例已被證明可以提高模型性能并導(dǎo)致更符合人類解釋的特征 [4]。這項工作探索了干凈和對抗性圖像的聯(lián)合訓(xùn)練模型。以前的工作探索了對抗樣本的預(yù)訓(xùn)練模型,然后對干凈的圖像進(jìn)行微調(diào)。雖然這提高了分類性能,但模型變得容易受到“災(zāi)難性遺忘”的影響,其中模型忘記了它在預(yù)訓(xùn)練階段(在域轉(zhuǎn)移的情況下)學(xué)習(xí)的特征。為了解決這個問題,提出了輔助批量歸一化(BN)層來專門對對抗樣本進(jìn)行歸一化。另一方面,正常的 BN 層用于標(biāo)準(zhǔn)化干凈的圖像。這允許歸一化層根據(jù)干凈樣本和對抗樣本的不同分布而表現(xiàn)不同。在推理過程中,輔助 BN 層被刪除,而正常的 BN 層用于預(yù)測。這種訓(xùn)練機(jī)制與作為主干架構(gòu)的 EfficientNet 一起在 ImageNet 分類精度上實現(xiàn)了前 1 名的 SOTA 性能。此外,AdvProp 在更難的 ImageNet 版本上實現(xiàn)了 SOTA 性能:ImageNet-a、ImageNet-c 和 Stylized ImageNet。此外,在訓(xùn)練中包括對抗樣本也實現(xiàn)了目標(biāo)檢測的 SOTA [5]。
自監(jiān)督和對比學(xué)習(xí)概述
深度學(xué)習(xí)需要干凈的標(biāo)記數(shù)據(jù),這對于許多應(yīng)用程序來說很難獲得。注釋大量數(shù)據(jù)需要大量的人力勞動,這是耗時且昂貴的。此外,數(shù)據(jù)分布在現(xiàn)實世界中一直在變化,這意味著模型必須不斷地根據(jù)不斷變化的數(shù)據(jù)進(jìn)行訓(xùn)練。自監(jiān)督方法通過使用大量原始未標(biāo)記數(shù)據(jù)來訓(xùn)練模型來解決其中的一些挑戰(zhàn)。在這種情況下,監(jiān)督是由數(shù)據(jù)本身(不是人工注釋)提供的,目標(biāo)是完成一個間接任務(wù)。間接任務(wù)通常是啟發(fā)式的(例如,旋轉(zhuǎn)預(yù)測),其中輸入和輸出都來自未標(biāo)記的數(shù)據(jù)。定義間接任務(wù)的目標(biāo)是使模型能夠?qū)W習(xí)相關(guān)特征,這些特征稍后可用于下游任務(wù)(通常有一些注釋可用)。自監(jiān)督學(xué)習(xí)在 2020 年變得更加流行,當(dāng)時它終于開始趕上全監(jiān)督方法的性能。有貢獻(xiàn)的一項特殊技術(shù)是對比學(xué)習(xí) (Contrastive Learning)。
CL 的靈感來自一個古老的想法 [6],即相似的項目應(yīng)該在嵌入空間中保持靠近,而不同的項目應(yīng)該相距很遠(yuǎn)。為了實現(xiàn)這一點,CL 形成了樣本對。對于給定的樣本,使用樣本項和它的增強(qiáng)版本創(chuàng)建一個正對。類似地,使用相同的項目和不同的項目創(chuàng)建負(fù)對。然后,學(xué)習(xí)特征使得正對在嵌入空間中很近,而負(fù)對相距很遠(yuǎn)。這允許相似的項目在嵌入空間中聚集在一起。聚類中心可以表示語義或?qū)ο箢悺S捎跊]有使用標(biāo)簽,CL 可以利用大量未標(biāo)記的原始數(shù)據(jù)。
自我監(jiān)督和對比學(xué)習(xí)的利弊
優(yōu)點:自監(jiān)督學(xué)習(xí)是一種數(shù)據(jù)高效的學(xué)習(xí)范式。監(jiān)督學(xué)習(xí)方法教會模型擅長特定任務(wù)。另一方面,自監(jiān)督學(xué)習(xí)允許學(xué)習(xí)不專門用于解決特定任務(wù)的一般表示,而是為各種下游任務(wù)封裝更豐富的統(tǒng)計數(shù)據(jù)。在所有自監(jiān)督方法中,使用 CL 進(jìn)一步提高了提取特征的質(zhì)量。自監(jiān)督學(xué)習(xí)的數(shù)據(jù)效率特性使其有利于遷移學(xué)習(xí)應(yīng)用。
缺點:自監(jiān)督學(xué)習(xí)的大部分成功都?xì)w功于精心選擇的圖像增強(qiáng),例如縮放、模糊和裁剪。因此,為特定任務(wù)選擇正確的增強(qiáng)集和程度可能是一個具有挑戰(zhàn)性的過程。此外,CL 可能會誤導(dǎo)模型區(qū)分包含相同對象的兩個圖像。例如,對于一匹馬的圖像,為了創(chuàng)建負(fù)對,CL 可能會選擇另一個也包含一匹馬的圖像。在這種情況下,模型認(rèn)為是負(fù)對的實際上是正對。
最先進(jìn)的自我監(jiān)督和對比學(xué)習(xí)
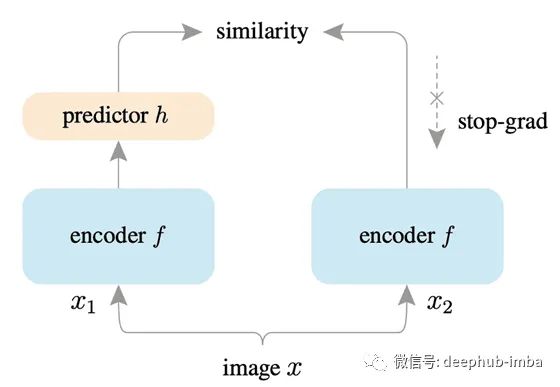
SimSiam: Exploring Simple Siamese Representation Learning:Siamese 網(wǎng)絡(luò)框架是一種在自監(jiān)督學(xué)習(xí)中廣受歡迎的架構(gòu)。與創(chuàng)建正負(fù)對的 CL 不同,該框架僅最大化圖像增強(qiáng)之間的相似性,這有助于學(xué)習(xí)有用的表示。自監(jiān)督學(xué)習(xí)中的并行工作使用對比損失,這些工作的成功依賴于 (i) 負(fù)對 [7] 的使用,(ii) 批次大小,以及 (iii) 動量編碼器 [8]。然而,SimSiam 不依賴于這些因素,使其對超參數(shù)的選擇更加穩(wěn)健。此外,SimSiam 使用“stop-gradient”技術(shù)來防止特征崩潰。特征崩潰是一種現(xiàn)象,模型在不學(xué)習(xí)有用表示的情況下學(xué)習(xí)了最小化目標(biāo)函數(shù)的捷徑。因此,學(xué)習(xí)到的特征是不可泛化的。通過避免特征崩潰,SimSiam 在 ImageNet 和后續(xù)下游任務(wù)(例如 COCO 對象檢測和實例分割)上取得了有競爭力的結(jié)果。
DINO:自監(jiān)督視覺Transformers的新興特性:DINO 建立在 SwAV [9] 之上,包括無標(biāo)簽的自蒸餾。使用的主干架構(gòu)是Transformers [10],它已被證明優(yōu)于卷積網(wǎng)絡(luò)。使用transformers + DINO框架,改進(jìn)了圖像分類任務(wù)的SOTA。DINO 可應(yīng)用于復(fù)制檢測和圖像檢索等應(yīng)用。給定一個查詢圖像,盡可能快地檢索該圖像的所有可能副本。此外,DINO 免費(fèi)提供分段功能。與監(jiān)督方法相比,在 DINO 中學(xué)習(xí)的特征已被證明在顯著圖生成方面表現(xiàn)更好。最后,通過仔細(xì)的閾值設(shè)置,DINO 可以開箱即用地應(yīng)用于每幀視頻對象分割,而無需進(jìn)行時間一致性訓(xùn)練。


視覺語言模型概述
Vision-Language (VL) 涉及對圖像和文本模式有共同理解的訓(xùn)練系統(tǒng)。VL 類似于人類與世界互動的方式;視覺是人類如何感知世界的很大一部分,而語言是人類交流方式的很大一部分。VL 模型學(xué)習(xí)不同數(shù)據(jù)模態(tài)的聯(lián)合嵌入空間。對于訓(xùn)練,使用圖像和文本對,其中文本通常描述圖像。該領(lǐng)域的大部分最新工作都使用基于轉(zhuǎn)換器的自監(jiān)督學(xué)習(xí)來從數(shù)據(jù)中提取特征。另一方面,視頻-文本對已開始用于學(xué)習(xí)更豐富和更密集的表示。然而,它仍然是一個具有巨大潛力的新興領(lǐng)域。
視覺語言模型的優(yōu)缺點
優(yōu)點:VL 使用不同形式的數(shù)據(jù),可以更好地進(jìn)行特征映射和提取。此外,可以使用大量數(shù)據(jù)樣本(例如 YouTube 視頻和自動生成的注釋)來訓(xùn)練這些系統(tǒng)。與自監(jiān)督學(xué)習(xí)類似,學(xué)習(xí)到的特征是通用的,可用于多個下游任務(wù),例如
圖像字幕 (IC)
視覺問答 (VQA)
視覺蘊(yùn)涵
圖文檢索
此外,VL 模型可用于學(xué)習(xí)更好的視覺特征和增強(qiáng)語言表示,如
OpenAI-CLIP [11]
Google ALIGN [12]
OpenAI-DALL-E [13]
Vokenization [14]
缺點:VL 模型專門使用英語來創(chuàng)建圖像-文本對。因此,多語種工作在這一領(lǐng)域仍需取得進(jìn)展。至于視頻文本模型,沒有足夠的統(tǒng)一基準(zhǔn)來評估它們。而且,類似于基于圖像-文本的 VL 模型,視頻-文本模型也可以通過更多地關(guān)注多語言功能來使不同的語言受益。
最先進(jìn)的視覺語言模型
VinVL:重新審視視覺語言模型中的視覺表示:VinVL 改進(jìn)了 VL 任務(wù)的視覺表示。VL 模型通常具有對象檢測器模型和語言提取器模型,然后是融合模型。融合模型負(fù)責(zé)合并視覺和語言嵌入。以前的 VL 模型主要側(cè)重于改進(jìn)視覺語言融合模型 [15],同時保持對象檢測模型不變。VinVL 表明視覺特征在 VL 模型中非常重要,并提出了改進(jìn)的對象檢測模型。對象檢測模型檢測幾乎覆蓋圖像所有語義區(qū)域的邊界框,而不是僅覆蓋重要對象的傳統(tǒng)邊界框。最后,視覺特征通過轉(zhuǎn)換器 [16] 與語言嵌入融合。在對多個數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練后,VinVL 針對多個下游任務(wù)(VQA、IC 等)進(jìn)行了微調(diào),并在七個公共基準(zhǔn)上實現(xiàn)了 SOTA 性能。性能提升可歸因于改進(jìn)的對象檢測模型。

有限數(shù)據(jù)學(xué)習(xí)概述
監(jiān)督學(xué)習(xí)方法需要大量數(shù)據(jù),其性能在很大程度上取決于訓(xùn)練數(shù)據(jù)的質(zhì)量和大小。然而,在現(xiàn)實世界中,大量標(biāo)記數(shù)據(jù)的獲取通常很昂貴或不容易獲得。當(dāng)考慮需要基于專家知識(例如醫(yī)學(xué)成像)進(jìn)行注釋的視覺類、很少出現(xiàn)的類或標(biāo)記需要大量工作(例如圖像分割)的任務(wù)時,這個問題變得更加嚴(yán)重。在過去的十年中,出現(xiàn)了各種研究領(lǐng)域來應(yīng)對這些挑戰(zhàn)。弱監(jiān)督學(xué)習(xí)、遷移學(xué)習(xí)和自/半監(jiān)督等領(lǐng)域試圖通過使 ML 模型從有限、弱或嘈雜的監(jiān)督中學(xué)習(xí)來克服這些挑戰(zhàn)。由于上面已經(jīng)介紹了自/半監(jiān)督,這里我們主要關(guān)注弱監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí)。
有限數(shù)據(jù)學(xué)習(xí)的利弊
優(yōu)點:弱監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí)有助于減少訓(xùn)練 CV 模型所需的標(biāo)記數(shù)據(jù)量,從而增加這些模型在工業(yè)中的應(yīng)用和采用。弱監(jiān)督學(xué)習(xí)還可以幫助模型在存在噪聲標(biāo)簽的情況下表現(xiàn)得更好,這在現(xiàn)實世界中經(jīng)常出現(xiàn)。此外,基于實例的遷移學(xué)習(xí)方法可用于克服現(xiàn)實世界數(shù)據(jù)集自然產(chǎn)生的類不平衡挑戰(zhàn)(例如,視覺世界的長尾分布[17])。
缺點:弱監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí)都是相對較新的領(lǐng)域,仍需要時間才能在工業(yè)中使用。這些方法通常是根據(jù)從受控環(huán)境收集的基準(zhǔn)來開發(fā)和評估的,因此在實際環(huán)境中進(jìn)行測試時,它們的性能通常會下降。此外,這些領(lǐng)域中最有趣的論文都是基于研究環(huán)境中的假設(shè)而開發(fā)的,但不一定在現(xiàn)實環(huán)境中。在使用這些論文解決實際問題時,請注意這些論文中隱含和顯式的假設(shè)。
使用有限數(shù)據(jù)進(jìn)行最先進(jìn)的學(xué)習(xí)
WyPR:弱監(jiān)督點識別:WyPR 以點云為輸入,共同解決分割、提議生成和檢測。共同完成這些任務(wù)有幾個好處,包括:
將語義分割作為檢測的替代任務(wù)可以提供點級預(yù)測,形成自下而上的解決方案
這些任務(wù)是互利的,例如,檢測結(jié)果可用于細(xì)化分割
多任務(wù)設(shè)置可以實現(xiàn)更好的表征學(xué)習(xí)。
WyPR 使用多實例學(xué)習(xí) (MIL) 和自我訓(xùn)練技術(shù)進(jìn)行訓(xùn)練,并在任務(wù)和轉(zhuǎn)換中定義了額外的一致性損失。WyPR 在 ScanNet 數(shù)據(jù)上的性能比之前的分割方法高 6.3% mIoU。同樣,它在 ScanNet 上的提議生成和檢測方面優(yōu)于先前的提議方法。

DatasetGAN:
DatasetGAN 使用生成對抗網(wǎng)絡(luò) (GAN) 和小樣本學(xué)習(xí)(遷移學(xué)習(xí)的一個子領(lǐng)域)來生成真實的訓(xùn)練數(shù)據(jù)——圖像和標(biāo)簽。該方法建立在 StyleGAN[20] 之上,StyleGAN[20] 是用于生成逼真圖像的最新模型。StyleGAN 默認(rèn)只生成圖像。為了使 StyleGAN 能夠在圖像之外生成標(biāo)簽(例如語義分割圖),他們在 StyleGAN 的合成塊中添加了一個標(biāo)簽分支。標(biāo)簽分支只是幾層多層感知器,在這項工作中用 16 個標(biāo)記樣本進(jìn)行訓(xùn)練。論文表明,即使只有一個標(biāo)記示例,該方法也能獲得合理的結(jié)果,并且當(dāng)提供 30 個標(biāo)記示例時,它達(dá)到了全監(jiān)督方法的性能。此外,作者表明相同的想法可用于生成帶有標(biāo)簽的合成視頻 [21]。

零售行業(yè)
從自助結(jié)賬到產(chǎn)品推薦,CV 在過去幾年幫助零售公司取得了重要進(jìn)展。以下是一些使用簡歷來提升零售體驗的公司和初創(chuàng)公司的例子:
Grabango 是一家位于伯克利的零售視覺初創(chuàng)公司,它正在應(yīng)用 CV 進(jìn)行無摩擦結(jié)賬,類似于 AmazonGo。這家初創(chuàng)公司的目標(biāo)是生成一個虛擬購物籃,用于識別購物者選擇的商品,簡化結(jié)賬流程。為了實現(xiàn)自助結(jié)賬,由加州大學(xué)伯克利分校的 Trevor Darrell 教授領(lǐng)導(dǎo)的數(shù)據(jù)科學(xué)團(tuán)隊將問題分解為三個部分:跟蹤,跟蹤店內(nèi)顧客的動向,檢測諸如取走/保留商品等事件。貨架和預(yù)測產(chǎn)品 ID。Grabango 在商店中放置了數(shù)以千計的傳感器、訪問大量歷史數(shù)據(jù)以及來自 BAIR(伯克利人工智能研究)的專門研究人員團(tuán)隊,Grabango 正在使自助結(jié)賬成為現(xiàn)實。
Facebook AI Research (FAIR):通過從 Facebook Marketplace 訪問數(shù)百萬個零售數(shù)據(jù)點,F(xiàn)acebook 能夠創(chuàng)建 CV 模型,根據(jù)文本描述向用戶推薦產(chǎn)品。簡而言之,用戶輸入他們想要購買的產(chǎn)品的描述。Facebook 使用此描述作為查詢來獲取并向用戶顯示最相關(guān)的產(chǎn)品圖片。在幕后,F(xiàn)acebook 使用 GrokNet,這是一個訓(xùn)練用于大規(guī)模產(chǎn)品識別的 CV 模型。使用著名的 ArcFace 模型和 Catalyzer 的改進(jìn),GrokNet 在產(chǎn)品推薦任務(wù)上取得了令人印象深刻的結(jié)果。
自動駕駛
幾年來,自動駕駛汽車一直是人們關(guān)注的焦點。谷歌、特斯拉、優(yōu)步、豐田和 Waabi 等多家公司和初創(chuàng)公司投資于自動駕駛汽車。雖然實現(xiàn) 5 級自治的基本原則(即汽車在無人干預(yù)的情況下自動駕駛)保持一致,但該領(lǐng)域的領(lǐng)導(dǎo)者對哪些傳感器性能更好有不同的看法。自動駕駛汽車廣泛使用傳感器來獲取有關(guān)其周圍環(huán)境的數(shù)據(jù)。然后將這些數(shù)據(jù)饋送到 CV 模型以獲得自動駕駛所需的預(yù)測。一些公司將僅使用攝像頭的傳感器作為黃金標(biāo)準(zhǔn),而另一些公司則更喜歡將攝像頭和雷達(dá)傳感器混合使用。
特斯拉:由 Andrej Karpathy 博士領(lǐng)導(dǎo)的自動駕駛團(tuán)隊僅使用攝像頭傳感器進(jìn)行預(yù)測。該團(tuán)隊通過實驗展示了使用攝像頭傳感器而不是雷達(dá)的好處。特斯拉首席執(zhí)行官埃隆馬斯克甚至發(fā)了推文!此外,該團(tuán)隊認(rèn)為攝像頭傳感器比雷達(dá)便宜,這使得它們在大規(guī)模生產(chǎn)時更經(jīng)濟(jì)。與其競爭對手相比,特斯拉已經(jīng)在街上擁有數(shù)千輛自動駕駛汽車。這使他們能夠收集訓(xùn)練期間未考慮的獨特駕駛條件的實時數(shù)據(jù)。為此,特斯拉擁有一個名為“車隊”的基礎(chǔ)設(shè)施,其唯一目的是從世界不同地區(qū)收集有關(guān)不同駕駛條件的數(shù)據(jù)。以“大數(shù)據(jù)=自動駕駛解決”的理念,特斯拉在自動駕駛行業(yè)的研發(fā)中處于領(lǐng)先地位。
Waabi:由自動駕駛行業(yè)專家兼首席執(zhí)行官 Raquel Urtasun 博士領(lǐng)導(dǎo),Waabi 是一家總部位于多倫多的初創(chuàng)公司,專注于長途卡車駕駛。Waabi 使用一套傳感器在卡車周圍創(chuàng)建導(dǎo)航環(huán)境。使用概率模型,環(huán)境能夠模擬和合成現(xiàn)實生活中遇到的不同交通狀況和場景。從這個環(huán)境中采樣不同的路徑軌跡,然后輸入到為特定任務(wù)設(shè)計的 CV 模型。Waabi 認(rèn)為,獲取真實交通中可能發(fā)生的所有可能場景的實時數(shù)據(jù)是很困難的。在這里,模擬環(huán)境可用于創(chuàng)建多個邊緣情況場景,然后可用于訓(xùn)練模型。
引用
僅分享,版權(quán)屬于原作者;侵刪
猜您喜歡:
等你著陸!【GAN生成對抗網(wǎng)絡(luò)】知識星球!
CVPR 2021 | GAN的說話人驅(qū)動、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
CVPR 2021生成對抗網(wǎng)絡(luò)GAN部分論文匯總
最新最全20篇!基于 StyleGAN 改進(jìn)或應(yīng)用相關(guān)論文
附下載 | 經(jīng)典《Think Python》中文版
附下載 | 最新2020李沐《動手學(xué)深度學(xué)習(xí)》
附下載 | 《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》