
6個(gè)冷門但實(shí)用的pandas知識(shí)點(diǎn)

點(diǎn)擊上方"藍(lán)字"關(guān)注我們
記錄? ?分享? ?成長(zhǎng)
1 簡(jiǎn)介
pandas作為開展數(shù)據(jù)分析的利器,蘊(yùn)含了與數(shù)據(jù)處理相關(guān)的豐富多樣的API,使得我們可以靈活方便地對(duì)數(shù)據(jù)進(jìn)行各種加工,但很多pandas中的實(shí)用方法其實(shí)大部分人都是不知道的,今天就來給大家介紹6個(gè)不太為人們所所熟知的實(shí)用pandas小技巧。

2 6個(gè)實(shí)用的pandas小知識(shí)
2.1 Series與DataFrame的互轉(zhuǎn)
很多時(shí)候我們計(jì)算過程中產(chǎn)生的結(jié)果是Series格式的,而接下來的很多操作尤其是使用「鏈?zhǔn)健?/strong>語法時(shí),需要銜接著傳入DataFrame格式的變量,這種時(shí)候我們就可以使用到pandas中Series向DataFrame轉(zhuǎn)換的方法:
「利用to_frame()實(shí)現(xiàn)Series轉(zhuǎn)DataFrame」
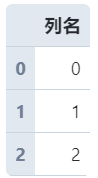
s?=?pd.Series([0,?1,?2])
#?Series轉(zhuǎn)為DataFrame,name參數(shù)用于指定轉(zhuǎn)換后的字段名
s?=?s.to_frame(name='列名')
s
順便介紹一下單列數(shù)據(jù)組成的數(shù)據(jù)框轉(zhuǎn)為Series的方法:
「利用squeeze()實(shí)現(xiàn)單列數(shù)據(jù)DataFrame轉(zhuǎn)Series」
#?只有單列數(shù)據(jù)的DataFrame轉(zhuǎn)為Series
s.squeeze()

2.2 隨機(jī)打亂DataFrame的記錄行順序
有時(shí)候我們需要對(duì)數(shù)據(jù)框整體的行順序進(jìn)行打亂,譬如在訓(xùn)練機(jī)器學(xué)習(xí)模型時(shí),打亂原始數(shù)據(jù)順序后取前若干行作為訓(xùn)練集后若干行作為測(cè)試集,這在pandas中可以利用sample()方法快捷實(shí)現(xiàn)。
sample()方法的本質(zhì)功能是從原始數(shù)據(jù)中抽樣行記錄,默認(rèn)為不放回抽樣,其參數(shù)frac用于控制抽樣比例,我們將其設(shè)置為1則等價(jià)于打亂順序:
df?=?pd.DataFrame({
????'V1':?range(5),
????'V2':?range(5)
})
df.sample(frac=1)

2.3 利用類別型數(shù)據(jù)減少內(nèi)存消耗
當(dāng)我們的數(shù)據(jù)框中某些列是由少數(shù)幾種值大量重復(fù)形成時(shí),會(huì)消耗大量的內(nèi)存,就像下面的例子一樣:
import?numpy?as?np
pool?=?['A',?'B',?'C',?'D']
#?V1列由ABCD大量重復(fù)形成
df?=?pd.DataFrame({
????'V1':?np.random.choice(pool,?1000000)
})
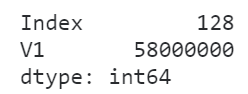
#?查看內(nèi)存使用情況
df.memory_usage(deep=True)
這種時(shí)候我們可以使用到pandas數(shù)據(jù)類型中的類別型來極大程度上減小內(nèi)存消耗:
df['V1']?=?df['V1'].astype('category')
df.memory_usage(deep=True)

可以看到,轉(zhuǎn)換類型之后內(nèi)存消耗減少了將近98.3%!
2.4 pandas中的object類型陷阱
在日常使用pandas處理數(shù)據(jù)的過程中,經(jīng)常會(huì)遇到object這種數(shù)據(jù)類型,很多初學(xué)者都會(huì)把它視為字符串,事實(shí)上object在pandas中可以代表不確定的數(shù)據(jù)類型,即類型為object的Series中可以混雜著多種數(shù)據(jù)類型:
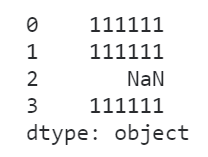
s?=?pd.Series(['111100',?'111100',?111100,?'111100'])
s

查看類型分布:
s.apply(lambda?s:?type(s))

這種情況下,如果貿(mào)然當(dāng)作字符串列來處理,對(duì)應(yīng)的無法處理的元素只會(huì)變成缺失值而不報(bào)錯(cuò),給我們的分析過程帶來隱患:
s.str.replace('00',?'11')
這種時(shí)候就一定要先轉(zhuǎn)成對(duì)應(yīng)的類型,再執(zhí)行相應(yīng)的方法:
s.astype('str').str.replace('00',?'11')

2.5 快速判斷每一列是否有缺失值
在pandas中我們可以對(duì)單個(gè)Series查看hanans屬性來了解其是否包含缺失值,而結(jié)合apply(),我們就可以快速查看整個(gè)數(shù)據(jù)框中哪些列含有缺失值:
df?=?pd.DataFrame({
????'V1':?[1,?2,?None,?4],
????'V2':?[1,?2,?3,?4],
????'V3':?[None,?1,?2,?3]
})
df.apply(lambda?s:?s.hasnans)

2.6 使用rank()計(jì)算排名時(shí)的五種策略
在pandas中我們可以利用rank()方法計(jì)算某一列數(shù)據(jù)對(duì)應(yīng)的排名信息,但在rank()中有參數(shù)method來控制具體的結(jié)果計(jì)算策略,有以下5種策略,在具體使用的時(shí)候要根據(jù)需要靈活選擇:
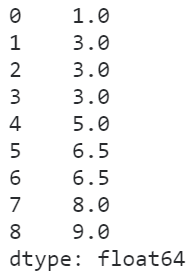
「average」
在average策略下,相同數(shù)值的元素的排名是其內(nèi)部排名的均值:
s?=?pd.Series([1,?2,?2,?2,?3,?4,?4,?5,?6])
s.rank(method='average')
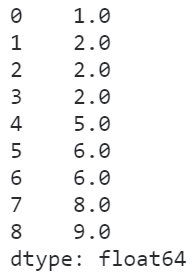
「min」
在min策略下,相同元素的排名為其內(nèi)部排名的最小值:
s.rank(method='min')
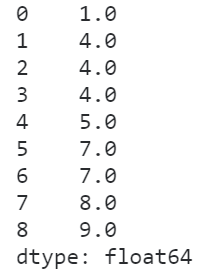
「max」
max策略與min正好相反,取的是相同元素內(nèi)部排名的最大值:
s.rank(method='max')
「dense」
在dense策略下,相當(dāng)于對(duì)序列去重后進(jìn)行排名,再將每個(gè)元素的排名賦給相同的每個(gè)元素,這種方式也是比較貼合實(shí)際需求的:
s.rank(method='dense')

「first」
在first策略下,當(dāng)多個(gè)元素相同時(shí),會(huì)根據(jù)這些相同元素在實(shí)際Series中的順序分配排名:
s?=?pd.Series([2,?2,?2,?1,?3])
s.rank(method='first')

關(guān)于pandas還有很多實(shí)用的小知識(shí),以后會(huì)慢慢給大家不定期分享~歡迎在評(píng)論區(qū)與我進(jìn)行討論

我們的知識(shí)星球【Python大數(shù)據(jù)分析】
限時(shí)優(yōu)惠中(還有4天)!掃碼領(lǐng)券
年費(fèi)立減20,僅需59元~
快來一起玩轉(zhuǎn)數(shù)據(jù)分析吧???
在模仿中精進(jìn)數(shù)據(jù)可視化03:OD數(shù)據(jù)的特殊可視化方式
Python大數(shù)據(jù)分析
data creates?value
掃碼關(guān)注我們