
一次簡單的Java服務(wù)性能優(yōu)化,實現(xiàn)壓測 QPS 翻倍
點擊上方“碼農(nóng)突圍”,馬上關(guān)注
這里是碼農(nóng)充電第一站,回復(fù)“666”,獲取一份專屬大禮包 真愛,請設(shè)置“星標(biāo)”或點個“在看

背景
服務(wù)器高CPU、高負載
jtop,jtop 只是一個 jar 包,它的項目地址在?yujikiriki/jtop, 我們可以很方便地把它復(fù)制到服務(wù)器上,獲取到 java 應(yīng)用的 pid 后,使用?java -jar jtop.jar [options] ?即可輸出 JVM 內(nèi)部統(tǒng)計信息。-stack n打印出最耗 CPU 的 5 種線程棧。Heap?Memory:?INIT=134217728??USED=230791968??COMMITED=450363392??MAX=1908932608
NonHeap?Memory:?INIT=2555904??USED=24834632??COMMITED=26411008??MAX=-1
GC?PS?Scavenge??VALID??[PS?Eden?Space,?PS?Survivor?Space]??GC=161??GCT=440
GC?PS?MarkSweep??VALID??[PS?Eden?Space,?PS?Survivor?Space,?PS?Old?Gen]??GC=2??GCT=532
ClassLoading?LOADED=3118??TOTAL_LOADED=3118??UNLOADED=0
Total?threads:?608??CPU=2454?(106.88%)??USER=2142?(93.30%)
NEW=0??RUNNABLE=6??BLOCKED=0??WAITING=2??TIMED_WAITING=600??TERMINATED=0
main??TID=1??STATE=RUNNABLE??CPU_TIME=2039?(88.79%)??USER_TIME=1970?(85.79%)?Allocted:?640318696
????com.google.common.util.concurrent.RateLimiter.tryAcquire(RateLimiter.java:337)
????io.zhenbianshu.TestFuturePool.main(TestFuturePool.java:23)
RMI?TCP?Connection(2)-127.0.0.1??TID=2555??STATE=RUNNABLE??CPU_TIME=89?(3.89%)??USER_TIME=85?(3.70%)?Allocted:?7943616
????sun.management.ThreadImpl.dumpThreads0(Native?Method)
????sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)
????me.hatter.tools.jtop.rmi.RmiServer.listThreadInfos(RmiServer.java:59)
????me.hatter.tools.jtop.management.JTopImpl.listThreadInfos(JTopImpl.java:48)
????sun.reflect.NativeMethodAccessorImpl.invoke0(Native?Method)
????...?...
熔斷框架優(yōu)化
resilience4j?和阿里開源的 sentinel,但由于部門內(nèi)技術(shù)棧是 Hystrix,而且它也沒有明顯的短板,就接著用下去了。響應(yīng)時間不正常
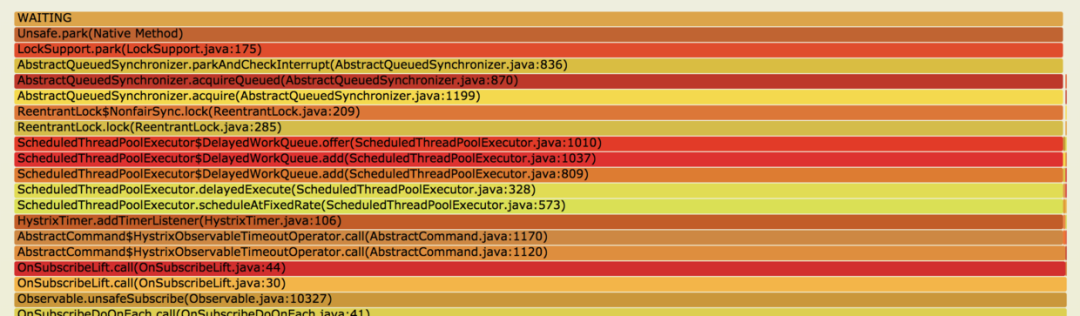
LockSupport.park(LockSupport.java:175)?處,這些線程都被鎖住了,向下看來源發(fā)現(xiàn)是?HystrixTimer.addTimerListener(HystrixTimer.java:106), 再向下就是我們的業(yè)務(wù)代碼了。????@HystrixCommand(
????????????fallbackMethod?=?"fallBackGetXXXConfig",
????????????commandProperties?=?{
????????????????????@HystrixProperty(name?=?"execution.isolation.thread.timeoutInMilliseconds",?value?=?"200"),
????????????????????@HystrixProperty(name?=?"circuitBreaker.errorThresholdPercentage",?value?=?"50")},
????????????threadPoolProperties?=?{
????????????????????@HystrixProperty(name?=?"coreSize",?value?=?"200"),
????????????????????@HystrixProperty(name?=?"maximumSize",?value?=?"500"),
????????????????????@HystrixProperty(name?=?"allowMaximumSizeToDivergeFromCoreSize",?value?=?"true")})
????public?XXXConfig?getXXXConfig(Long?uid)?{
????????try?{
????????????return?XXXConfigCache.get(uid);
????????}?catch?(Exception?e)?{
????????????return?EMPTY_XXX_CONFIG;
????????}
????}
服務(wù)隔離和降級
hystrix-metrics-event-stream?包并添加一個接口來輸出 Metrics 信息,再啟動?hystrix-dashboard?客戶端并填入服務(wù)端地址即可。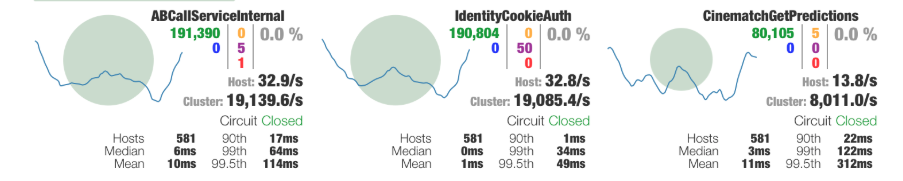
2000*50/1000=100?得到適合的信號量限制,如果被拒絕的錯誤數(shù)過多,可以再添加一些冗余。熔斷時高負載導(dǎo)致無法恢復(fù)
Spring 數(shù)據(jù)綁定異常
at?java.lang.Throwable.fillInStackTrace(Native?Method)
at?java.lang.Throwable.fillInStackTrace(Throwable.java:783)
??-?locked?<0x00000006a697a0b8>?(a?org.springframework.beans.NotWritablePropertyException)
??...
org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426)
at?org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278)
??...
at?org.springframework.validation.DataBinder.doBind(DataBinder.java:735)
at?org.springframework.web.bind.WebDataBinder.doBind(WebDataBinder.java:197)
at?org.springframework.web.bind.ServletRequestDataBinder.bind(ServletRequestDataBinder.java:107)
at?org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:161)
?...
at?org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991)
??List ?propertyAccessExceptions?=?null;
??List?propertyValues?=?(pvs?instanceof?MutablePropertyValues??
??????((MutablePropertyValues)?pvs).getPropertyValueList()?:?Arrays.asList(pvs.getPropertyValues()));
??for?(PropertyValue?pv?:?propertyValues)?{
????try?{
??????//?This?method?may?throw?any?BeansException,?which?won't?be?caught
??????//?here,?if?there?is?a?critical?failure?such?as?no?matching?field.
??????//?We?can?attempt?to?deal?only?with?less?serious?exceptions.
??????setPropertyValue(pv);
????}
????catch?(NotWritablePropertyException?ex)?{
??????if?(!ignoreUnknown)?{
????????throw?ex;
??????}
??????//?Otherwise,?just?ignore?it?and?continue...
????}
????...?...
??}
?@RequestMapping("test.json")
?public?Map?testApi(@RequestParam(name?=?"id")?String?id,?ApiContext?apiContext)?{}
小結(jié)
-?END - 最近熱文
? ?女程序員做了個夢,神評論。。。 ? ?「老司機」蓋茨再上熱搜!被曝婚外情史將近20年,公然給女下屬發(fā)郵件調(diào)情 ? ?獎金100萬!北大“韋神”,獲獎了! ? ?26歲應(yīng)屆博士被聘985博導(dǎo)!入職半年實現(xiàn)學(xué)院頂會論文零的突破
評論
圖片
表情