
Python解析庫lxml與xpath用法總結(jié)
點擊上方“IT共享之家”,進(jìn)行關(guān)注
回復(fù)“資料”可獲贈Python學(xué)習(xí)福利
本文主要圍繞以xpath和lxml庫進(jìn)行展開:
一、xpath 概念、xpath節(jié)點、xpath語法、xpath軸、xpath運算符
二、lxml的安裝、lxml的使用、lxml案例
一、xpath
1.xpath概念
XPath 是一門在 XML 文檔中查找信息的語言。XPath 使用路徑表達(dá)式在 XML 文檔中進(jìn)行導(dǎo)航 。XPath 包含一個標(biāo)準(zhǔn)函數(shù)庫 。XPath 是 XSLT 中的主要元素 。XPath 是一個 W3C 標(biāo)準(zhǔn) 。
2.xpath節(jié)點
xpath有七種類型的節(jié)點:元素、屬性、文本、命名空間、處理指令、注釋以及文檔(根)節(jié)點。
節(jié)點關(guān)系:父、子、兄弟、先輩、后輩。
3.xpath語法
xpath語法在W3c網(wǎng)站上有詳細(xì)的介紹,這里截取部分知識,供大家學(xué)習(xí)。
XPath 使用路徑表達(dá)式在 XML 文檔中選取節(jié)點。節(jié)點是通過沿著路徑或者 step 來選取的。下面列出了最有用的路徑表達(dá)式:
| 表達(dá)式 | 描述 |
|---|---|
| nodename | 選取此節(jié)點的所有子節(jié)點。 |
| / | 從根節(jié)點選取。 |
| // | 從匹配選擇的當(dāng)前節(jié)點選擇文檔中的節(jié)點,而不考慮它們的位置。 |
| . | 選取當(dāng)前節(jié)點。 |
| .. | 選取當(dāng)前節(jié)點的父節(jié)點。 |
| @ | 選取屬性。 |
在下面的表格中,我們已列出了一些路徑表達(dá)式以及表達(dá)式的結(jié)果:
| 路徑表達(dá)式 | 結(jié)果 |
|---|---|
| bookstore | 選取 bookstore 元素的所有子節(jié)點。 |
| /bookstore | 選取根元素 bookstore。注釋:假如路徑起始于正斜杠( / ),則此路徑始終代表到某元素的絕對路徑! |
| bookstore/book | 選取屬于 bookstore 的子元素的所有 book 元素。 |
| //book | 選取所有 book 子元素,而不管它們在文檔中的位置。 |
| bookstore//book | 選擇屬于 bookstore 元素的后代的所有 book 元素,而不管它們位于 bookstore 之下的什么位置。 |
| //@lang | 選取名為 lang 的所有屬性。 |
謂語(Predicates)
謂語用來查找某個特定的節(jié)點或者包含某個指定的值的節(jié)點。
謂語被嵌在方括號中。
在下面的表格中,我們列出了帶有謂語的一些路徑表達(dá)式,以及表達(dá)式的結(jié)果:
| 路徑表達(dá)式 | 結(jié)果 |
|---|---|
| /bookstore/book[1] | 選取屬于 bookstore 子元素的第一個 book 元素。 |
| /bookstore/book[last()] | 選取屬于 bookstore 子元素的最后一個 book 元素。 |
| /bookstore/book[last()-1] | 選取屬于 bookstore 子元素的倒數(shù)第二個 book 元素。 |
| /bookstore/book[position()<3] | 選取最前面的兩個屬于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 選取所有擁有名為 lang 的屬性的 title 元素。 |
| //title[@lang='eng'] | 選取所有 title 元素,且這些元素?fù)碛兄禐?eng 的 lang 屬性。 |
| /bookstore/book[price>35.00] | 選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大于 35.00。 |
| /bookstore/book[price>35.00]/title | 選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大于 ?35.00。 |
選取未知節(jié)點
XPath 通配符可用來選取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素節(jié)點。 |
| @* | 匹配任何屬性節(jié)點。 |
| node() | 匹配任何類型的節(jié)點。 |
在下面的表格中,我們列出了一些路徑表達(dá)式,以及這些表達(dá)式的結(jié)果:
| 路徑表達(dá)式 | 結(jié)果 |
|---|---|
| /bookstore/* | 選取 bookstore 元素的所有子元素。 |
| //* | 選取文檔中的所有元素。 |
| //title[@*] | 選取所有帶有屬性的 title 元素。 |
選取若干路徑
通過在路徑表達(dá)式中使用"|"運算符,您可以選取若干個路徑。
在下面的表格中,我們列出了一些路徑表達(dá)式,以及這些表達(dá)式的結(jié)果:
| 路徑表達(dá)式 | 結(jié)果 |
|---|---|
| //book/title | //book/price | 選取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 選取文檔中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 選取屬于 bookstore 元素的 book 元素的所有 title 元素,以及文檔中所有的 price ?元素。 |
4.xpath 軸
軸可定義相對于當(dāng)前節(jié)點的節(jié)點集。
| 軸名稱 | 結(jié)果 |
|---|---|
| ancestor | 選取當(dāng)前節(jié)點的所有先輩(父、祖父等)。 |
| ancestor-or-self | 選取當(dāng)前節(jié)點的所有先輩(父、祖父等)以及當(dāng)前節(jié)點本身。 |
| attribute | 選取當(dāng)前節(jié)點的所有屬性。 |
| child | 選取當(dāng)前節(jié)點的所有子元素。 |
| descendant | 選取當(dāng)前節(jié)點的所有后代元素(子、孫等)。 |
| descendant-or-self | 選取當(dāng)前節(jié)點的所有后代元素(子、孫等)以及當(dāng)前節(jié)點本身。 |
| following | 選取文檔中當(dāng)前節(jié)點的結(jié)束標(biāo)簽之后的所有節(jié)點。 |
| namespace | 選取當(dāng)前節(jié)點的所有命名空間節(jié)點。 |
| parent | 選取當(dāng)前節(jié)點的父節(jié)點。 |
| preceding | 選取文檔中當(dāng)前節(jié)點的開始標(biāo)簽之前的所有節(jié)點。 |
| preceding-sibling | 選取當(dāng)前節(jié)點之前的所有同級節(jié)點。 |
| self | 選取當(dāng)前節(jié)點。 |
5.xpath運算符
下面列出了可用在 XPath 表達(dá)式中的運算符:
| 運算符 | 描述 | 實例 | 返回值 |
|---|---|---|---|
| | | 計算兩個節(jié)點集 | //book | //cd | 返回所有擁有 book 和 cd 元素的節(jié)點集 |
| + | 加法 | 6 + 4 | 10 |
| - | 減法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,則返回 true。如果 price 是 9.90,則返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,則返回 true。如果 price 是 9.70,則返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,則返回 true。如果 price 是 9.50,則返回 false。 |
| and | 與 | price>9.00 and price<9.90 | 如果 price 是 9.80,則返回 true。如果 price 是 8.50,則返回 false。 |
| mod | 計算除法的余數(shù) | 5 mod 2 | 1 |
好了,xpath的內(nèi)容就這么多了。接下來我們要介紹一個神器lxml,他的速度很快,曾經(jīng)一直是我使用beautifulsoup時最鐘愛的解析器,沒有之一,因為他的速度的確比其他的html.parser 和html5lib快了許多。
二、lxml
1.lxml安裝
lxml 是一個xpath格式解析模塊,安裝很方便,直接pip install lxml 或者easy_install lxml即可。
2.lxml 使用
lxml提供了兩種解析網(wǎng)頁的方式,一種是你解析自己寫的離線網(wǎng)頁時,另一種 則是解析線上網(wǎng)頁。
導(dǎo)入包:
from lxml import etree1.解析離線網(wǎng)頁:
html=etree.parse('xx.html',etree.HTMLParser())aa=html.xpath('//*[@id="s_xmancard_news"]/div/div[2]/div/div[1]/h2/a[1]/@href')print(aa)
2.解析在線網(wǎng)頁:
from lxml import etreeimport requestsrep=requests.get('https://www.baidu.com')html=etree.HTML(rep.text)aa=html.xpath('//*[@id="s_xmancard_news"]/div/div[2]/div/div[1]/h2/a[1]/@href')print(aa)
那么我們怎么獲取這些標(biāo)簽和標(biāo)簽對應(yīng)的屬性值了,很簡單,首先獲取標(biāo)簽只需你這樣做:
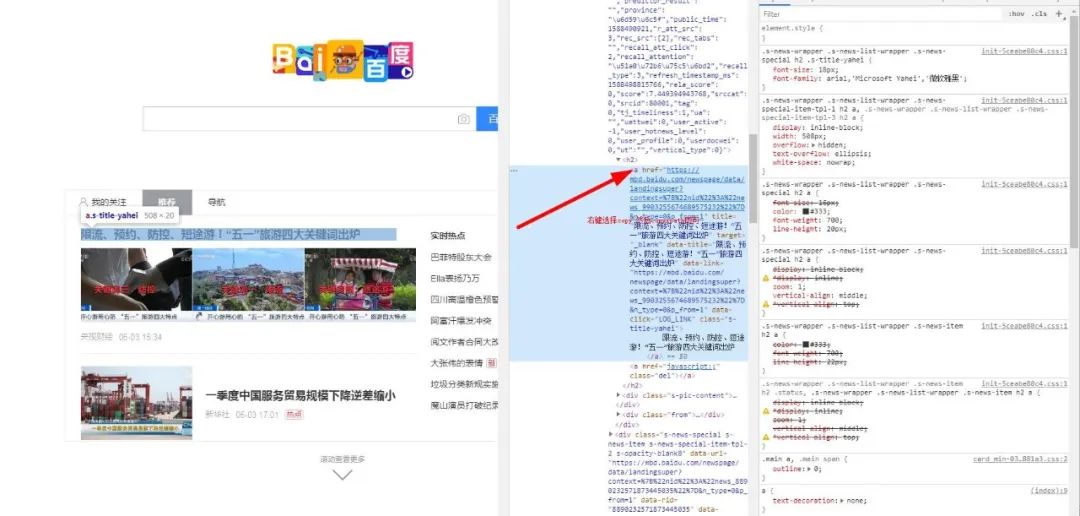
然后我們可以,比方說,你要獲取a標(biāo)簽內(nèi)的文本和它的屬性href所對應(yīng)的值,有兩種方法,
1.表達(dá)式內(nèi)獲取
aa=html.xpath('//*[@id="s_xmancard_news"]/div/div[2]/div/div[1]/h2/a[1]/text()')ab=html.xpath('//*[@id="s_xmancard_news"]/div/div[2]/div/div[1]/h2/a[1]/@href')
2.表達(dá)式外獲取
aa=html.xpath('//*[@id="s_xmancard_news"]/div/div[2]/div/div[1]/h2/a[1]')aa.textaa.attrib.get('href')
這樣就完成了獲取,怎么樣,是不是很簡單了,哈哈哈。
下面再來lxml的解析規(guī)則:
| 表達(dá)式 | 描述 |
|---|---|
| nodename | 選取此節(jié)點的所有子節(jié)點 |
| / | 從當(dāng)前節(jié)點選取直接子節(jié)點 |
| // | 從當(dāng)前節(jié)點選取子孫節(jié)點 |
| . | 選取當(dāng)前節(jié)點 |
| .. | 選取當(dāng)前節(jié)點的父節(jié)點 |
| @ | 選取屬性 |
html = lxml.etree.HTML(text)#使用text構(gòu)造一個XPath解析對象,etree模塊可以自動修正HTML文本html = lxml.etree.parse('./ex.html',etree.HTMLParser())#直接讀取文本進(jìn)行解析from lxml import etreeresult = html.xpath('//*')#選取所有節(jié)點result = html.xpath('//li')#獲取所有l(wèi)i節(jié)點result = html.xpath('//li/a')#獲取所有l(wèi)i節(jié)點的直接a子節(jié)點result = html.xpath('//li//a')#獲取所有l(wèi)i節(jié)點的所有a子孫節(jié)點result = html.xpath('//a[@href="link.html"]/../@class')#獲取所有href屬性為link.html的a節(jié)點的父節(jié)點的class屬性result = html.xpath('//li[@class="ni"]')#獲取所有class屬性為ni的li節(jié)點result = html.xpath('//li/text()')#獲取所有l(wèi)i節(jié)點的文本result = html.xpath('//li/a/@href')#獲取所有l(wèi)i節(jié)點的a節(jié)點的href屬性result = html.xpath('//li[contains(@class,"li")]/a/text())#當(dāng)li的class屬性有多個值時,需用contains函數(shù)完成匹配result = html.xpath('//li[contains(@class,"li") and @name="item"]/a/text()')#多屬性匹配result = html.xpath('//li[1]/a/text()')result = html.xpath('//li[last()]/a/text()')result = html.xpath('//li[position()<3]/a/text()')result = html.xpath('//li[last()-2]/a/text()')#按序選擇,中括號內(nèi)為XPath提供的函數(shù)result = html.xpath('//li[1]/ancestor::*')#獲取祖先節(jié)點result = html.xpath('//li[1]/ancestor::div')result = html.xpath('//li[1]/attribute::*')#獲取屬性值result = html.xpath('//li[1]/child::a[@href="link1.html"]')#獲取直接子節(jié)點result = html.xpath('//li[1]/descendant::span')#獲取所有子孫節(jié)點result = html.xpath('//li[1]/following::*[2]')#獲取當(dāng)前節(jié)點之后的所有節(jié)點的第二個result = html.xpath('//li[1]/following-sibling::*')#獲取后續(xù)所有同級節(jié)點
3.lxml案例
為了偷懶,小編決定還是采用urllib那篇文章的代碼,哈哈哈,機(jī)智如我。
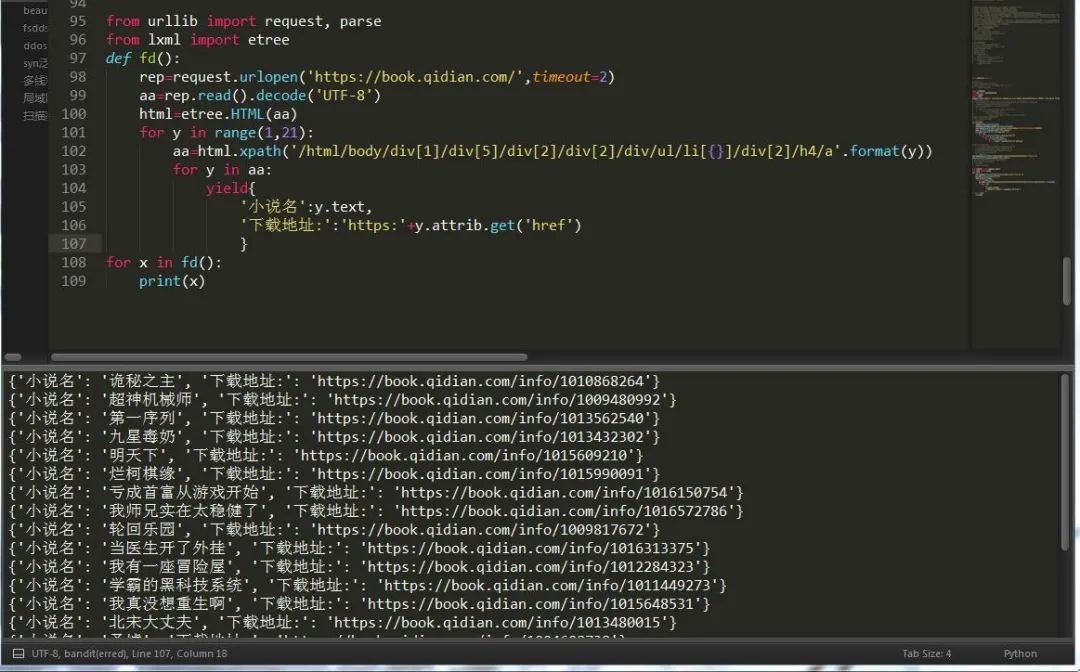
好了,今天就講這么多,大家感興趣的話可以多多關(guān)注哦,精彩不停息!!!!
本文參考文獻(xiàn):
https://www.w3school.com.cn/看完本文有收獲?請轉(zhuǎn)發(fā)分享給更多的人
IT共享之家
入群請在微信后臺回復(fù)【入群】
-------------------?End?-------------------
往期精彩文章推薦: