
擼了個搜索引擎系統(tǒng),爽!
作者:愛編程的快樂人
來源:blog.csdn.net/m0_57315623/article/details/123829698
如果用我們的小服務(wù)器去搞百度,搜狗那種引擎肯定是不行的,內(nèi)屬于全站搜索,我們這里做一個站內(nèi)搜索。這個還是可以的,就類似于我們對網(wǎng)站里的資源進行搜索。
搜索引擎怎么搜索
搜索引擎就像一個小蜜蜂每天不停的采摘蜂蜜,就是去爬蟲各個網(wǎng)頁,然后通過爬取之后建立索引,以供于我們?nèi)ニ阉鳌?/span>
這里我們可以使用Python,或者下載文檔壓縮包。這里我們下包把,快多了。本來想搞一個英雄聯(lián)盟的,實在找不見,要是后續(xù)有老鐵找到可以分享一下。
建議大家別爬蟲(要不然被告了,不過我們學(xué)校的官網(wǎng)倒是可以隨便爬,我們當時就是拿這個練手的)
為什么要用索引呢?
因為爬的數(shù)據(jù)太多了,不索引,難道我去遍歷嗎?時間復(fù)雜度太大了。
這里我們需要建立索引,索引分別為正排索引,和倒排索引。

倒排索引就是LOL里面誰有劍
1.蠻王
2.無極劍圣
3.劍姬
故根據(jù)特點選擇英雄
模塊劃分
1.索引模塊
1)掃描下載到的文檔,分析內(nèi)容,構(gòu)建出,正排索引和倒排索引。并且把索引內(nèi)容保存到文件中。
2)加載制作i好的索引。并提供一些API實現(xiàn)查正排和查倒排這樣的功能。
2.搜索模塊
1)調(diào)用索引模塊,實現(xiàn)一個搜索的完整過程。
輸入:用戶的查詢詞
輸出:完整的搜索結(jié)果
3.web模塊
需要實現(xiàn)一個簡單的web程序,能夠通過網(wǎng)頁的形式和用戶進行交互。
包含了前端和后端。
怎么實現(xiàn)分詞
分詞的原理
1.基于詞庫
嘗試把所有的詞都進行窮舉,把這些結(jié)果放到詞典文件中。
2.基于統(tǒng)計
收集到很多的語料庫,進行人工標注,知道了那些字在一起的概率比較大~
java中能夠?qū)崿F(xiàn)分詞的第三方工具也是有很多的
比如ansj(聽說唱的兄弟可能聽過ansj,哈哈)這個就是一個maven中央倉庫的分詞第三方庫。
test包里直接操作:我們使用這個測試代碼直接搞。試一下這個包咋用。
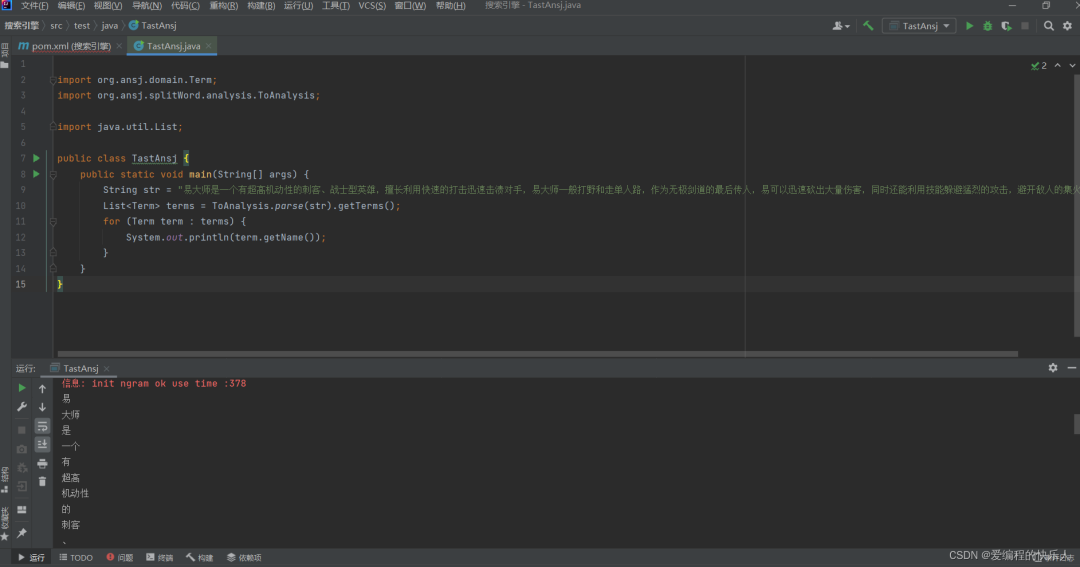
import org.ansj.domain.Term;import org.ansj.splitWord.analysis.ToAnalysis;import java.util.List;public class TastAnsj {public static void main(String[] args) {String str = "易大師是一個有超高機動性的刺客、戰(zhàn)士型英雄,擅長利用快速的打擊迅速擊潰對手,易大師一般打野和走單人路,作為無極劍道的最后傳人,易可以迅速砍出大量傷害,同時還能利用技能躲避猛烈的攻擊,避開敵人的集火。";List<Term> terms = ToAnalysis.parse(str).getTerms();for (Term term : terms) {System.out.println(term.getName());}}}
文件讀取
把剛剛下載好的文檔的路徑復(fù)制到String中并且用常量標記。
這一步是為了用遍歷的方法把所有html文件搞出來,我們這里用了一個遞歸,如果是絕對路徑,就填加到文件鏈表,如果不是就遞歸,繼續(xù)添加里面的值。
import java.io.File;import java.util.ArrayList;//讀取剛剛文檔public class Parser {private static final String INPUT_PATH="D:/test/docs/api";public void run(){//整個Parser類的入口//1.根據(jù)路徑,去枚舉出所有的文件.(html);ArrayList<File> fileList=new ArrayList<>();enumFile(INPUT_PATH,fileList);System.out.println(fileList);System.out.println(fileList.size());//2.針對上面羅列出的文件,打開文件,讀取文件內(nèi)容,并進行解析//3.把在內(nèi)存中構(gòu)造好的索引數(shù)據(jù)結(jié)構(gòu),保定到指定的文件中。}//第一個參數(shù)表示從哪里開始遍歷 //第二個表示結(jié)果。private void enumFile(String inputPath,ArrayList<File>fileList){File rootPath=new File(inputPath);//listFiles 能夠獲取到一層目錄下的文件File[] files= rootPath.listFiles();for(File f:files){//根據(jù)當前f的類型判斷是否遞歸。//如果f是一個普通文件,就把f加入到fileList里面//如果不是就調(diào)用遞歸if(f.isDirectory()){enumFile(f.getAbsolutePath(),fileList);}else {fileList.add(f);}}}public static void main(String[] args) {//通過main方法來實現(xiàn)整個制作索引的過程Parser parser=new Parser();parser.run();}}
我們嘗試運行一下,這里的文件也太多了吧,而且無論是什么都打印出來了。所以我們下一步就是把這些文件進行篩選,選擇有用的。
else {if(f.getAbsolutePath().endsWith(",html"))fileList.add(f);}
這個代碼就是只是針對末尾為html的文件。下圖就是展示結(jié)果。
1. 打開文件,解析內(nèi)容。
這里分為三個分別是解析Title,解析Url,解析內(nèi)容Content
1.1解析Title
f.getName()是直接讀取文件名字的方法。
我們用的name.substring(0,f.getName().length()-5);為什么要用總的文件名字長度減去5呢,因為.HTML剛好就是五。
private String parseTitle(File f) {String name= f.getName();return name.substring(0,f.getName().length()-5);}
1.2解析Url操作
這里的url就是我們平時去一個瀏覽器輸入一個東西下面會有一個url,這個url就是我們的絕對路徑經(jīng)過截取獲得出我們的相對的目錄,然后與我們的http進行拼接,這樣就可以直接得到一個頁面。
private String parseUrl(File f) {String part1="https://docs.oracle.com/javase/8/docs/api/";String part2=f.getAbsolutePath().substring(INPUT_PATH.length());return part1+part2;}
1.3解析內(nèi)容
以<>為開關(guān)進行對數(shù)據(jù)的讀取,以int類型讀取,為什么要用int而不是char呢因為int類型讀完之后就變成-1可以判斷一下是否讀取完畢。
具體代碼如下很容易理解。
private String parseContent(File f) throws IOException {//先按照一個一個字符來讀取,以<>作為開關(guān)try(FileReader fileReader=new FileReader(f)) {//加上一個是否拷貝的開關(guān).boolean isCopy=true;//還需要準備一個結(jié)果保存StringBuilder content=new StringBuilder();while (true){//此處的read的返回值是int,不是char//如果讀到文件末尾,就會返回-1,這是用int的好處;int ret = 0;try {ret = fileReader.read();} catch (IOException e) {e.printStackTrace();}if(ret==-1) {break;}char c=(char) ret;if(isCopy){if(c=='<'){isCopy=false;continue;}//其他字符直接拷貝if(c=='\n'||c=='\r'){c=' ';}content.append(c);}else{if(c=='>'){isCopy=true;}}}return content.toString();} catch (FileNotFoundException e) {e.printStackTrace();}return "";}
這一模塊總的代碼塊如下:
import java.io.File;import java.io.FileNotFoundException;import java.io.FileReader;import java.io.IOException;import java.util.ArrayList;//讀取剛剛文檔public class Parser {private static final String INPUT_PATH="D:/test/docs/api";public void run(){//整個Parser類的入口//1.根據(jù)路徑,去枚舉出所有的文件.(html);ArrayList<File> fileList=new ArrayList<>();enumFile(INPUT_PATH,fileList);System.out.println(fileList);System.out.println(fileList.size());//2.針對上面羅列出的文件,打開文件,讀取文件內(nèi)容,并進行解析for (File f:fileList){System.out.println("開始解析"+f.getAbsolutePath());parseHTML(f);}//3.把在內(nèi)存中構(gòu)造好的索引數(shù)據(jù)結(jié)構(gòu),保定到指定的文件中。}private String parseTitle(File f) {String name= f.getName();return name.substring(0,f.getName().length()-5);}private String parseUrl(File f) {String part1="https://docs.oracle.com/javase/8/docs/api/";String part2=f.getAbsolutePath().substring(INPUT_PATH.length());return part1+part2;}private String parseContent(File f) throws IOException {//先按照一個一個字符來讀取,以<>作為開關(guān)try(FileReader fileReader=new FileReader(f)) {//加上一個是否拷貝的開關(guān).boolean isCopy=true;//還需要準備一個結(jié)果保存StringBuilder content=new StringBuilder();while (true){//此處的read的返回值是int,不是char//如果讀到文件末尾,就會返回-1,這是用int的好處;int ret = 0;try {ret = fileReader.read();} catch (IOException e) {e.printStackTrace();}if(ret==-1) {break;}char c=(char) ret;if(isCopy){if(c=='<'){isCopy=false;continue;}//其他字符直接拷貝if(c=='\n'||c=='\r'){c=' ';}content.append(c);}else{if(c=='>'){isCopy=true;}}}return content.toString();} catch (FileNotFoundException e) {e.printStackTrace();}return "";}private void parseHTML (File f){//解析出標題String title=parseTitle(f);//解析出對應(yīng)的urlString url=parseUrl(f);//解析出對應(yīng)的正文try {String content=parseContent(f);} catch (IOException e) {e.printStackTrace();}}//第一個參數(shù)表示從哪里開始遍歷 //第二個表示結(jié)果。private void enumFile(String inputPath,ArrayList<File>fileList){File rootPath=new File(inputPath);//listFiles 能夠獲取到一層目錄下的文件File[] files= rootPath.listFiles();for(File f:files){//根據(jù)當前f的類型判斷是否遞歸。//如果f是一個普通文件,就把f加入到fileList里面//如果不是就調(diào)用遞歸if(f.isDirectory()){enumFile(f.getAbsolutePath(),fileList);}else {if(f.getAbsolutePath().endsWith(".html"))fileList.add(f);}}}public static void main(String[] args) {//通過main方法來實現(xiàn)整個制作索引的過程Parser parser=new Parser();parser.run();}}
正文結(jié)束
1.救救大齡碼農(nóng)!45歲程序員在國務(wù)院網(wǎng)站求助總理!央媒網(wǎng)評來了...
3.從零開始搭建創(chuàng)業(yè)公司后臺技術(shù)棧
5.37歲程序員被裁,120天沒找到工作,無奈去小公司,結(jié)果懵了...
6.IntelliJ IDEA 2019.3 首個最新訪問版本發(fā)布,新特性搶先看
