
【數(shù)據(jù)競賽】時間序列競賽必看一文!
深度學(xué)習(xí)時間序列概述

本篇綜述是我的個人學(xué)習(xí)記錄,絕大部分內(nèi)容摘自牛津大學(xué)的時間序列綜述,有興趣的朋友可以閱讀文末的原文。
本篇文章我們介紹深度學(xué)習(xí)用于時間序列的一些最新進展,包括:
使用深度學(xué)習(xí)做時間序列的通用方法;例如multi-horizon預(yù)測和不確定性估計; 混合模型的趨勢; 神經(jīng)網(wǎng)絡(luò)用于促進決策支持,特別是通過解釋性和反事實預(yù)測方法; 時間序列的未來研究方向;
One-step ahead函數(shù)表示
其中:
為模型的預(yù)測結(jié)果; , 是標(biāo)簽和額外特征; 是和實體相關(guān)的靜態(tài)元數(shù)據(jù); 是模型學(xué)習(xí)得到的預(yù)測函數(shù);
基礎(chǔ)構(gòu)建框架
:encoder; :decoder;
encoder常見框架
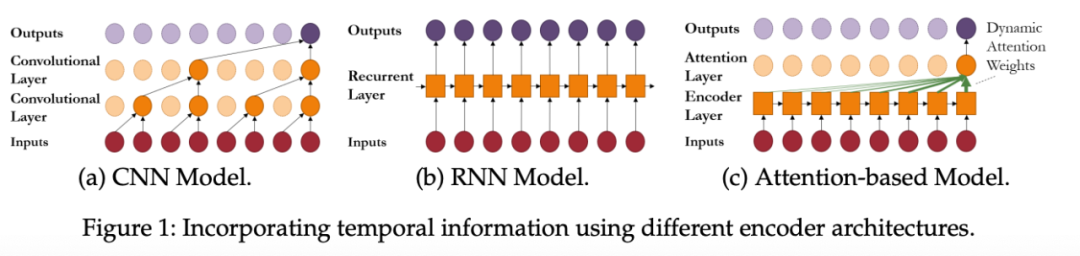
1. CNN網(wǎng)絡(luò)
其中,
是在時間t第層的中間狀態(tài); 是卷積操作; 是固定的filter權(quán)重; 為激活函數(shù);
Dialted 卷積
為特定層的dilation比例, Dialated卷積可以解釋為低層特征的下采樣卷積——可以獲取更遠(yuǎn)的信息。
2. RNN網(wǎng)絡(luò)
其中:
是RNN的中間隱藏狀態(tài); 是學(xué)習(xí)的memory更新函數(shù);
LSTM:
受限于梯度傳播等的問題,傳統(tǒng)的RNN很難學(xué)到較長的序列信息,LSTM被專門設(shè)計用于解決該問題,
其中:
是LSTM的隱藏狀態(tài),為sigmoid激活函數(shù)
其中:
是單個元素的乘積;
3. Attention機制
其中,
key:, query: , value: ;
是attention權(quán)重的向量; 是LSTM的encoder的輸出;
注意力提供了兩大關(guān)鍵好處:
注意力機制可以直接關(guān)注到重要的重要事件; 可以關(guān)注到更遠(yuǎn)的信息;學(xué)習(xí)的長度更遠(yuǎn);
Multi-horizon預(yù)測模型
其中:
是離散的預(yù)測; 是已知的未來輸入(例如日期信息等); 是歷史觀測值;
常見兩種模型策略
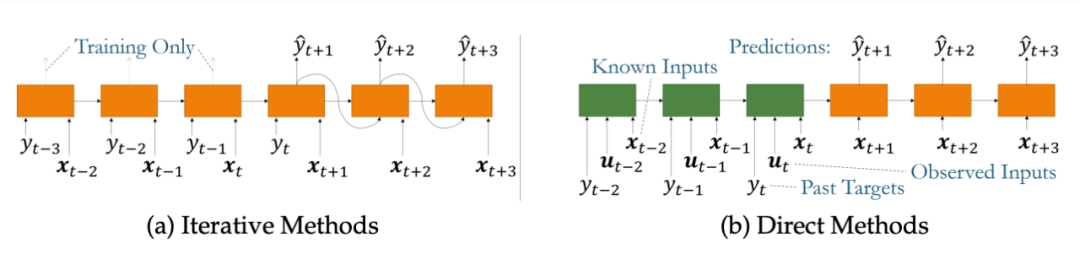
1. 迭代策略
迭代方法可以方便地將標(biāo)準(zhǔn)模型簡化為多步驟預(yù)測。迭代策略最大的問題在于:
由于每個時間步都會產(chǎn)生少量誤差,迭代方法的遞歸結(jié)構(gòu)可能會在較長的預(yù)測期內(nèi)導(dǎo)致較大的誤差累積。
2. 直接的方案
直接的方法通過直接使用所有可用輸入生成預(yù)測,使用encoder作為過往的信息等匯總,decoder將已知的等未來輸入進行組合,直接預(yù)測一個固定長度的輸出向量。
混合模型中融合域知識
在之前的許多問題中,復(fù)雜的深度學(xué)習(xí)方法并不能帶來更準(zhǔn)確的預(yù)測,而簡單的ensembling模型往往做得更好。原因可能在于下面兩點:
深度學(xué)習(xí)的復(fù)雜性使其更容易過度擬合;因此,較簡單的模型可能在低數(shù)據(jù)狀態(tài)下表現(xiàn)更好,這在預(yù)測具有少量歷史觀測值的問題(例如季度宏觀經(jīng)濟預(yù)測)時很突出。 與統(tǒng)計模型的平穩(wěn)性要求類似,機器學(xué)習(xí)模型對輸入的預(yù)處理方式非常敏感,需要盡可能保證訓(xùn)練和測試時的數(shù)據(jù)分布是相似的;
深度學(xué)習(xí)最近在開發(fā)混合模型可以很好地處理該問題,混合的方法將許多量化時間序列模型和深度學(xué)習(xí)方法進行結(jié)合,并取得了非常好的效果,具體地混合模型可以分成兩種方式:
將time-varying的參數(shù)編碼進非概率參數(shù)模型; 概率模型使用的參數(shù)分布的產(chǎn)出;
非概率混合模型
對于參數(shù)時間序列模型,預(yù)測方程通常以分析方式定義,并為未來目標(biāo)提供點預(yù)測。
非概率混合模型修改這些預(yù)測方程,將統(tǒng)計和深度學(xué)習(xí)進行結(jié)合。
ES-RNN就是利用Holt Winters指數(shù)平滑模型的更新方程,將乘法層和季節(jié)性成分與深度學(xué)習(xí)輸出相結(jié)合:
其中:
是th-step-ahead的預(yù)測的最后一層; 是level的成分; 是周期性的成份, ,是實體特定靜態(tài)系數(shù)。
概率混合模型
概率混合模型可以被用于分布建模的應(yīng)用。例如高斯過程和線性狀態(tài)空間等。
使用DNN加速決策
1. 時間序列可解釋性
Post-hoc解釋性技術(shù)
可解釋模型用于解釋經(jīng)過訓(xùn)練的網(wǎng)絡(luò),并在不修改原始權(quán)重的情況下幫助識別重要特征或示例。方法主要可分為兩大類。
在神經(jīng)網(wǎng)絡(luò)的輸入和輸出之間應(yīng)用更簡單的可解釋代理模型,并依靠近似模型提供解釋;最典型的就是LIME,SHAP等; 基于梯度下降的方法;
使用注意力權(quán)重進行解釋
故名思義,就是使用attention的權(quán)重進行解釋。權(quán)重越高,則愈加重要。
2. 反事實預(yù)測&隨時間推移的因果推斷
深度學(xué)習(xí)可以通過在觀測數(shù)據(jù)集之外生成預(yù)測或反事實預(yù)測,幫助促進決策支持。具體的內(nèi)容可以參見相關(guān)的文章。
本文我們介紹了目前深度學(xué)習(xí)最為常見的兩種學(xué)習(xí)預(yù)測框架,基于one-step的和multi-horizon的,以及這兩種框架采用的網(wǎng)絡(luò)結(jié)構(gòu):CNN,RNN,Attention,最后補充介紹了混合深度模型,并簡述了深度學(xué)習(xí)在可解釋性以及加速決策方面的內(nèi)容。
Time Series Forecasting With Deep Learning: A Survey 往期精彩回顧