
AI | 優(yōu)化背后的數(shù)學(xué)基礎(chǔ)
點擊上方“小白學(xué)視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達


編者按
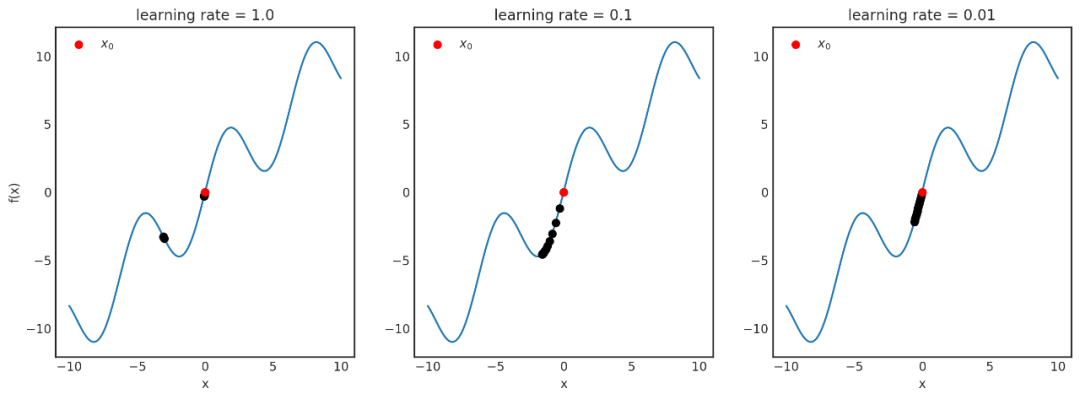
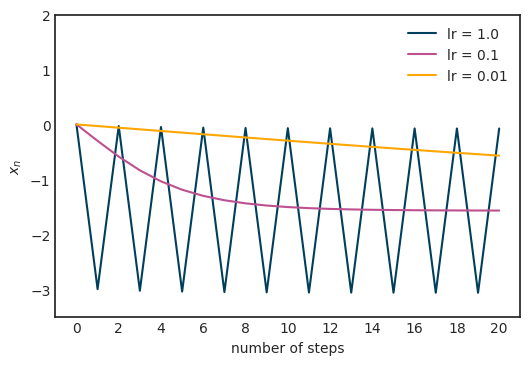
什么是優(yōu)化呢?優(yōu)化就是尋找函數(shù)的極值點。既然是針對函數(shù)的,其背后最重要的數(shù)學(xué)基礎(chǔ)是什么呢?沒錯,就是微積分。那什么是微積分呢?微積分就是一門利用極限研究函數(shù)的科學(xué)。本文從一維函數(shù)的優(yōu)化講起,拓展到多維函數(shù)的優(yōu)化,詳細闡述了優(yōu)化背后的數(shù)學(xué)基礎(chǔ)。
深度學(xué)習(xí)中的優(yōu)化是一項極度復(fù)雜的任務(wù),本文是一份基礎(chǔ)指南,旨在從數(shù)學(xué)的角度深入解讀優(yōu)化器。

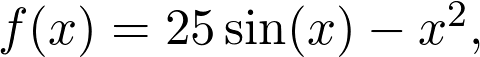
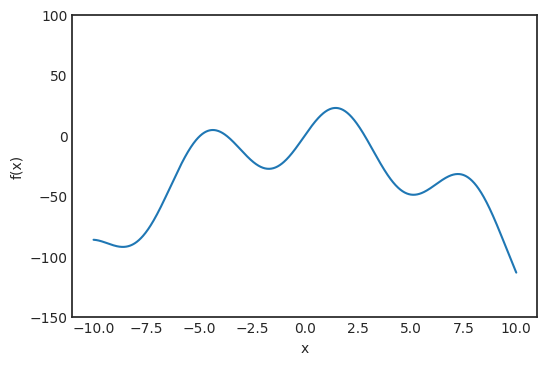
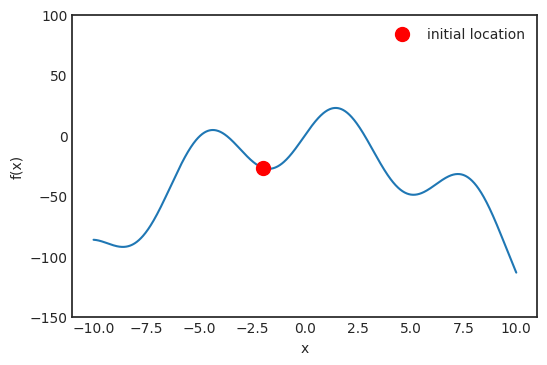
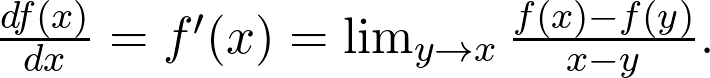
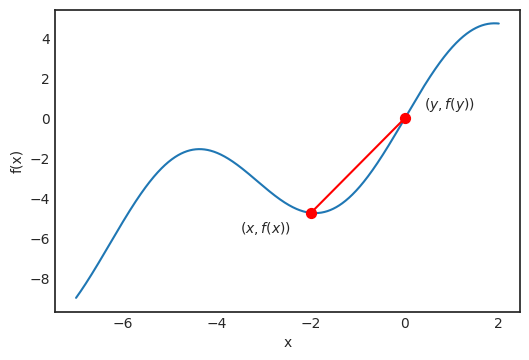
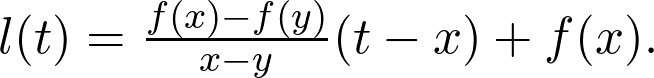
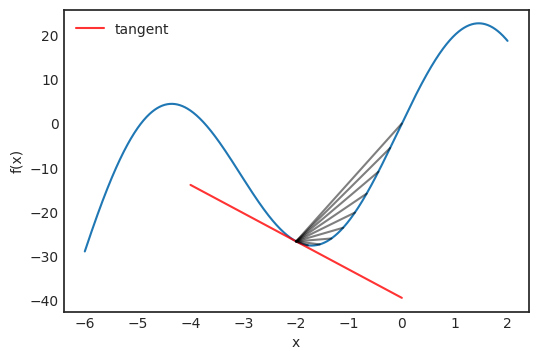
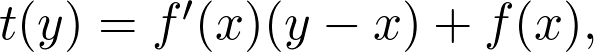
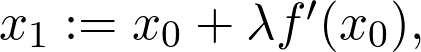
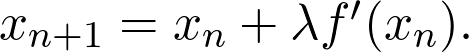
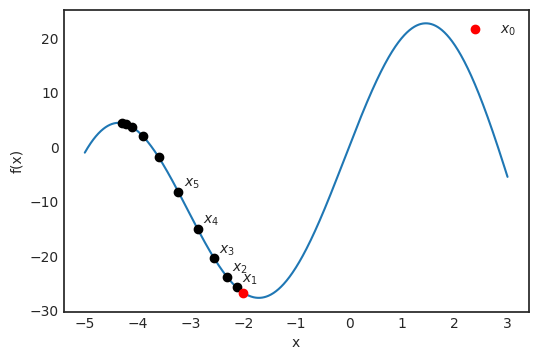

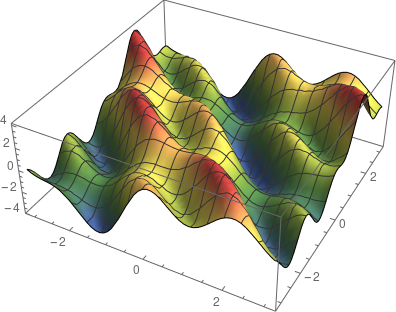
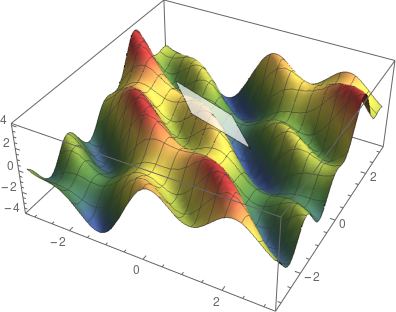
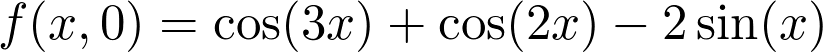
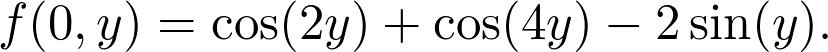

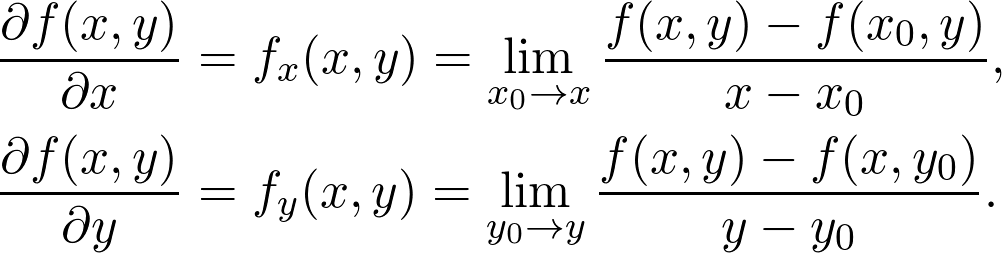
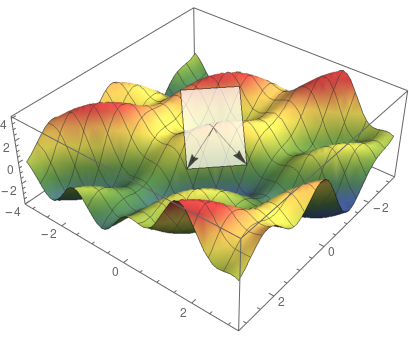
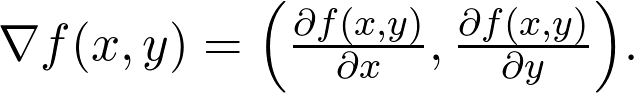
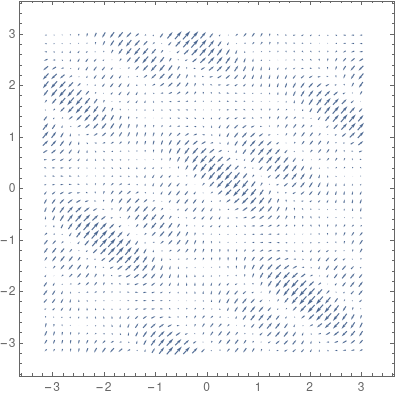
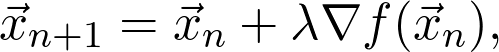
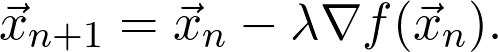
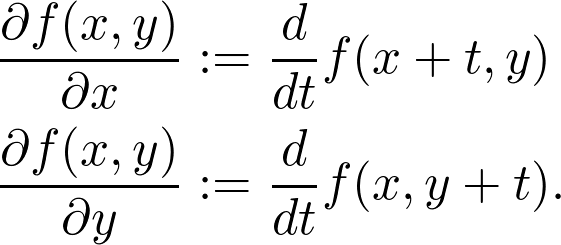

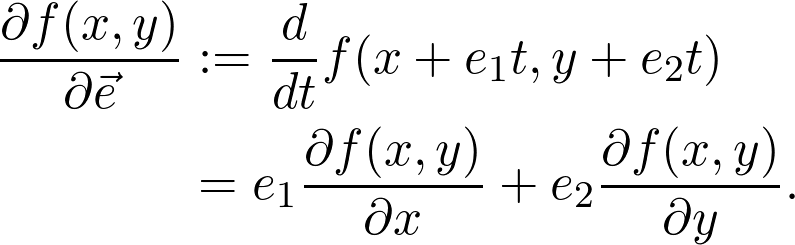
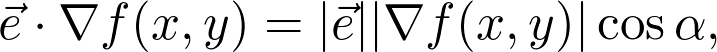

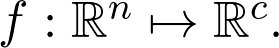
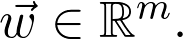
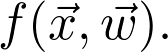
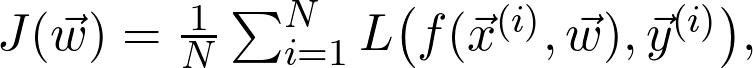
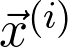 是觀測值為
是觀測值為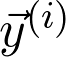 的第 i 個數(shù)據(jù)點
的第 i 個數(shù)據(jù)點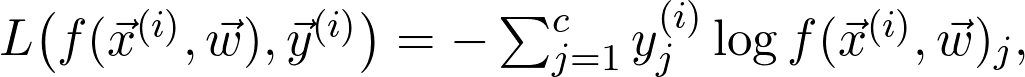
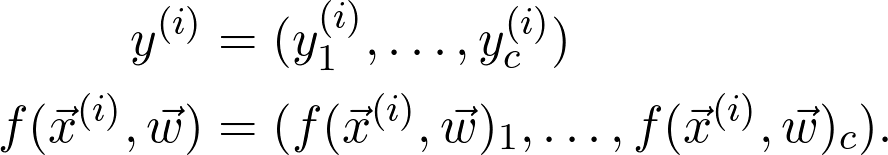
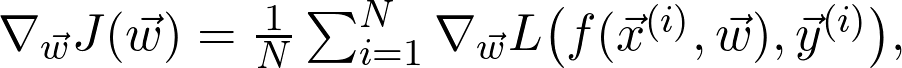
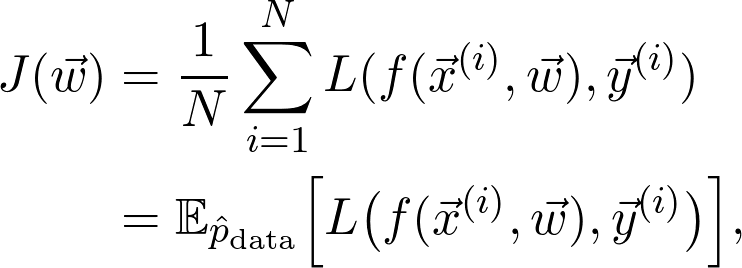
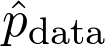 是訓(xùn)練數(shù)據(jù)給出的(經(jīng)驗)概率分布。可以將序列寫成:
是訓(xùn)練數(shù)據(jù)給出的(經(jīng)驗)概率分布。可以將序列寫成: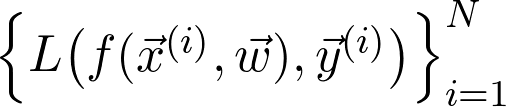
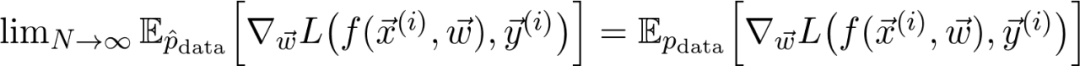
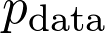 是真正的總體分布(這是未知的)。再詳細點說,因為增加了訓(xùn)練數(shù)據(jù),損失函數(shù)收斂到真實損失。因此,如果對數(shù)據(jù)二次采樣,并計算梯度:
是真正的總體分布(這是未知的)。再詳細點說,因為增加了訓(xùn)練數(shù)據(jù),損失函數(shù)收斂到真實損失。因此,如果對數(shù)據(jù)二次采樣,并計算梯度: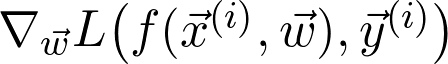
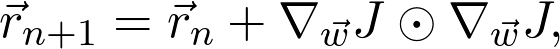
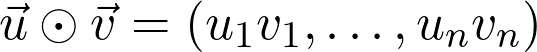
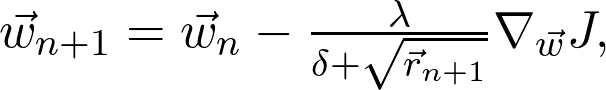
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~
評論
圖片
表情