
15000字《2021科技趨勢報(bào)告》重磅發(fā)布:正視中國AI優(yōu)勢,預(yù)言未來

導(dǎo)讀:近日,未來今日研究所(Future Today Institute)發(fā)布了《2021 年科技趨勢報(bào)告》,報(bào)告分析了多個(gè)行業(yè)的近 500 種科技趨勢,并對未來一年將影響商業(yè)、政治、教育、媒體和社會(huì)的戰(zhàn)略趨勢做出了具體的描述。
正如這份科技趨勢所述,未來的世界將深受人工智能、5G、區(qū)塊鏈等技術(shù)的影響。

▲2021 科技趨勢報(bào)告封面 (來源:FTI)
動(dòng)蕩的美國大選、極端天氣事件和新冠肺炎繼續(xù)考驗(yàn)著人們的決心和韌性。人工智能、合成生物學(xué)、超大規(guī)模計(jì)算、機(jī)器人和太空任務(wù)等前沿技術(shù)也正在挑戰(zhàn)著我們對人類潛力的假設(shè)。
在全球封鎖狀態(tài)下,人們學(xué)會(huì)了如何在餐桌上工作,如何在空閑的房間里做決策,如何遠(yuǎn)程互相支持。但是這種改變才剛剛開始,人們比以往任何時(shí)候都更需要掌握技術(shù)趨勢的潛在近期和長期影響。
20 世紀(jì) 20 年代始于混亂,第一次世界大戰(zhàn)和西班牙大流感導(dǎo)致了災(zāi)難性破壞,但是無線電、冰箱、真空吸塵器、移動(dòng)裝配線和電子動(dòng)力傳輸?shù)燃夹g(shù)奇跡產(chǎn)生了新的增長。
這些場景與當(dāng)今世界存在著太多驚人的相似之處。新的危機(jī)中,人工智能等一系列科技的力量帶動(dòng)了新的發(fā)展。由于人工智能現(xiàn)在已經(jīng)被應(yīng)用于大多數(shù)行業(yè),在新版的科技趨勢報(bào)告中,F(xiàn)TI 首先介紹了人工智能領(lǐng)域的發(fā)展趨勢。
趨勢報(bào)告內(nèi)容表明,人工智能正以驚人的速度從學(xué)術(shù)界轉(zhuǎn)向企業(yè)。同時(shí),以亞馬遜網(wǎng)絡(luò)服務(wù)、Azure 和谷歌云為代表的低代碼和無代碼產(chǎn)品,將滲透到日常生活中,使人們能夠創(chuàng)建自己的人工智能應(yīng)用程序,并輕松地部署它們。
但是從另一方面看,人工智能社區(qū)仍然使用封閉源代碼模式運(yùn)行。研究人員不愿意公布他們的完整代碼,導(dǎo)致透明度和再現(xiàn)性降低,問責(zé)制度模糊不清。
研究報(bào)告還對中國的人工智能發(fā)展現(xiàn)狀做出了一系列分析。分析認(rèn)為,中國已經(jīng)成為人工智能研發(fā)強(qiáng)國,并且明確指出中國日益增長的人工智能力量不是軍事、經(jīng)濟(jì)和外交等方面的威脅。
除了上述這些內(nèi)容,報(bào)告還從多方面展示了人工智能領(lǐng)域未來的發(fā)展趨勢。無論是對于人工智能企業(yè)、人工智能研究者,還是人工智能學(xué)習(xí)者,這都是一份比較詳盡的報(bào)告。
限于篇幅,學(xué)術(shù)頭條精選了報(bào)告中關(guān)于人工智能的部分內(nèi)容進(jìn)行翻譯,希望對讀者有參考價(jià)值。報(bào)告全文可在公眾號后臺對話框回復(fù)2021科技趨勢查看。


▲人工智能科技趨勢總覽
00 人工智能綜述
1. 關(guān)鍵見解
人工智能代表了計(jì)算的第三個(gè)時(shí)代,通常它被定義為機(jī)器執(zhí)行認(rèn)知功能的能力與人類一樣好或比人類更好。這些功能包括感知、學(xué)習(xí)、推理、解決問題、理解上下文、做出推理和預(yù)測以及鍛煉創(chuàng)造力。
2. 突破性影響
突破性研究、業(yè)務(wù)用例、數(shù)據(jù)爆炸式增長以及計(jì)算能力和存儲的改進(jìn)的融合正在推動(dòng)人工智能的進(jìn)步。從 2021 年到 2027 年,全球人工智能市場預(yù)計(jì)將以 42.2% 的年復(fù)合增長率繼續(xù)增長。
3. 超級玩家
Broad Institute、Clarifai、Clearview AI、DeepMind、Disperse、Graphcore、HiSilicon Technologies、Kasisto、LabGenius、Mohamed bin Zayed University of Artificial Intelligence、Niantic、Nvidia、OpenAI、OpenMined、Persado、PolyAI、Recursion、SenseTime、Scale AI、Syntiant。
4. 機(jī)器學(xué)習(xí)
機(jī)器學(xué)習(xí)使用數(shù)據(jù)對如何實(shí)現(xiàn)既定目標(biāo)做出預(yù)測和建議。機(jī)器學(xué)習(xí)的類型包括有監(jiān)督的、無監(jiān)督的和強(qiáng)化的。
在監(jiān)督學(xué)習(xí)中,算法使用訓(xùn)練數(shù)據(jù)來學(xué)習(xí)已建立的參數(shù)之間的關(guān)系。
在無監(jiān)督學(xué)習(xí)中,數(shù)據(jù)被提供給沒有特定輸出參數(shù)的算法。
在強(qiáng)化學(xué)習(xí)中,一種算法通過重復(fù)運(yùn)行計(jì)算來學(xué)習(xí)執(zhí)行一項(xiàng)任務(wù),以此來實(shí)現(xiàn)一個(gè)既定的目標(biāo)。
5. 深度學(xué)習(xí)
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)相對較新的分支。程序員使用特殊的深度學(xué)習(xí)算法以及大量的數(shù)據(jù)來實(shí)現(xiàn)系統(tǒng)的自主學(xué)習(xí)。深度學(xué)習(xí)的出現(xiàn)意味著越來越多的人類過程將被自動(dòng)化。常見的深度學(xué)習(xí)類型包括卷積神經(jīng)網(wǎng)絡(luò)、遞歸神經(jīng)網(wǎng)絡(luò)、變壓器神經(jīng)網(wǎng)絡(luò)和生成對抗網(wǎng)絡(luò) (GANs)。
卷積神經(jīng)網(wǎng)絡(luò) (CNN) 是多層的,具有卷積層、匯集層和完全連接層。每個(gè)人使用數(shù)據(jù)執(zhí)行不同的任務(wù),輸出是分類。
遞歸神經(jīng)網(wǎng)絡(luò) (RNNs) 是多層神經(jīng)網(wǎng)絡(luò),在輸入層、隱藏層和輸出層之間移動(dòng)和存儲信息,多用來為預(yù)測建立序列數(shù)據(jù)模型。
生成對抗網(wǎng)絡(luò) (GANs) 是無監(jiān)督的深度學(xué)習(xí)系統(tǒng),由兩個(gè)相互競爭的發(fā)生器和鑒別器組成。
變壓器是一種神經(jīng)網(wǎng)絡(luò)架構(gòu),當(dāng)單詞出現(xiàn)在特定的上下文中時(shí),它會(huì)學(xué)習(xí)單詞的含義。
6. 強(qiáng)弱 AI
人工智能有兩種 — 弱 (或 “狹義”) 和強(qiáng) (或 “廣義”),沒有單一的標(biāo)準(zhǔn)來區(qū)分弱 AI 和強(qiáng) AI。這對于研究人工智能發(fā)展的研究人員和必須對人工智能做出決策的經(jīng)理來說是有問題的。事實(shí)上,我們已經(jīng)開始看到現(xiàn)實(shí)世界中運(yùn)行人工智能的例子。
DeepMind 的一些項(xiàng)目已經(jīng)證實(shí)了人工智能在某些領(lǐng)域比人類做的更好。雖然我們還沒有看到擬人化的人工智能走出 DeepMind 的實(shí)驗(yàn)室,但我們應(yīng)該把這些項(xiàng)目視為今天的弱人工智能和明天的強(qiáng)人工智能之間漫長過渡的一部分。
01 AI 與企業(yè)
1. MLOps 的興起
2020 年,一些增長最快的 GitHub 項(xiàng)目是 MLOps,即處理工具、基礎(chǔ)設(shè)施和操作的項(xiàng)目。展望未來,MLOps 將描述一套結(jié)合機(jī)器學(xué)習(xí)、傳統(tǒng)開發(fā)和數(shù)據(jù)工程的最佳實(shí)踐。
2. 低代碼或無代碼機(jī)器學(xué)習(xí)
機(jī)器學(xué)習(xí)正在轉(zhuǎn)變,因?yàn)樾缕脚_允許企業(yè)利用人工智能的力量來構(gòu)建應(yīng)用程序,而不需要知道具體的代碼。
3. 網(wǎng)絡(luò)規(guī)模的內(nèi)容分析
由于先進(jìn)的自然語言處理收集和分類,挖掘非常大的非結(jié)構(gòu)化數(shù)據(jù)集現(xiàn)在變得更加容易。經(jīng)過識別關(guān)鍵字的訓(xùn)練,特殊的算法可以快速地對信息進(jìn)行排序、分類和標(biāo)記。
4. 模擬同情和情感
人工智能現(xiàn)在可以測量表示一個(gè)人情緒狀態(tài)的生物標(biāo)記,如焦慮、悲傷或眩暈。精確檢測人類情感具有挑戰(zhàn)性,但是擁有足夠大數(shù)據(jù)集的公司正在開發(fā)精確的模型。

▲通過測量某些生物標(biāo)記,人工智能可以檢測人們的情緒并做出相應(yīng)的反應(yīng)
5. 人工情感智能
研究團(tuán)隊(duì)正在教授機(jī)器無條件的愛、積極的傾聽和同理心。在未來,機(jī)器將令人信服地展示人類的情感,如愛、快樂、恐懼和悲傷。這項(xiàng)技術(shù)最終可能會(huì)出現(xiàn)在醫(yī)院、學(xué)校和監(jiān)獄,為病人、學(xué)生和囚犯提供情感支持機(jī)器人。
在我們?nèi)找婢o密聯(lián)系的世界里,人們感到更加孤立。未來與大規(guī)模精神健康危機(jī)作斗爭的政府可能會(huì)轉(zhuǎn)向情感支持機(jī)器人來大規(guī)模解決這個(gè)問題。
6. 無服務(wù)器計(jì)算
AWS、阿里巴巴云、微軟的 Azure、谷歌云和百度云正在為開發(fā)人員推出新的產(chǎn)品,目標(biāo)是讓廣大人工智能初創(chuàng)企業(yè)更容易、更實(shí)惠地將他們的想法推向市場。一些其他企業(yè)也正在加入這個(gè)領(lǐng)域。
7. 云中 AI
人工智能生態(tài)系統(tǒng)中的企業(yè)領(lǐng)導(dǎo)者一直在競相獲取人工智能云共享,并成為遠(yuǎn)程服務(wù)器上最值得信任的人工智能提供商。企業(yè)客戶可能會(huì)堅(jiān)持他們最初的供應(yīng)商,因?yàn)闄C(jī)器學(xué)習(xí)系統(tǒng)隨著時(shí)間的推移,收集的數(shù)據(jù)越來越多,變得越來越好。
8. 邊緣計(jì)算
物聯(lián)網(wǎng)及其數(shù)十億臺設(shè)備,加上 5G 網(wǎng)絡(luò)和不斷增強(qiáng)的計(jì)算能力,使得邊緣大規(guī)模人工智能成為可能。在設(shè)備上直接處理數(shù)據(jù)在未來對醫(yī)療保健、汽車和制造應(yīng)用非常重要,因?yàn)樗赡芨臁⒏踩?/span>
9. 先進(jìn)人工智能芯片
神經(jīng)網(wǎng)絡(luò)長期以來需要大量的計(jì)算能力,需要很長時(shí)間來訓(xùn)練,并且依賴于消耗數(shù)百千瓦功率的數(shù)據(jù)中心和計(jì)算機(jī)。這一切都開始改變了。
包括華為、蘋果、微軟、Facebook、Alphabet、IBM、英偉達(dá)、英特爾和高通在內(nèi)的大型科技公司,都在開發(fā)新的系統(tǒng)架構(gòu)和 SoCs,這意味著芯片更容易在人工智能項(xiàng)目中工作,并且應(yīng)該保證更快、更安全的處理。

▲三星的下一代 Exynos 芯片將有一個(gè) AMD 圖形處理單元 (GPU)
10. 數(shù)字孿生
數(shù)字孿生是現(xiàn)實(shí)世界環(huán)境、產(chǎn)品或資產(chǎn)的虛擬表示,用于各種目的。隨著低代碼和無代碼系統(tǒng)變得越來越普遍,公司應(yīng)該能夠構(gòu)建和部署數(shù)字孿生來模擬一系列廣泛的過程,這將導(dǎo)致現(xiàn)代化進(jìn)程的支出減少。
11. 辨別真假
在過去的一年里,研究人員展示了人工智能是如何被用來編寫如此優(yōu)異的文本,以至于人類無法分辨它是否機(jī)器編寫的。事實(shí)證明,人工智能也可以用來檢測文本是何時(shí)由機(jī)器生成的,即使我們?nèi)祟悷o法識別偽造的文本。
12. 面向 ESGs 的自然語言處理
企業(yè)社會(huì)責(zé)任標(biāo)準(zhǔn)必須量化并明確表述,但衡量績效可能很困難,因?yàn)樯婕霸S多無形資產(chǎn)或抽象概念。自然語言處理正被用于識別、標(biāo)記和分類來自各種來源的關(guān)于公司 ESG 聲譽(yù)的文檔。
13. 智能光學(xué)字符識別
一個(gè)持續(xù)的挑戰(zhàn)是讓機(jī)器認(rèn)識到我們在寫作中表達(dá)自己的各種方式。光學(xué)字符識別 (OCR) 以固定的、可識別的格式工作。但是,光學(xué)字符識別通常不夠智能,無法識別不同的字體、獨(dú)特的符號或只針對一家公司的電子表格字段。研究人員正在訓(xùn)練人工智能系統(tǒng)識別模式,即使它們出現(xiàn)在不尋常的地方。
14. 機(jī)器人過程自動(dòng)化
機(jī)器人過程自動(dòng)化 (RPA) 可以自動(dòng)化辦公室內(nèi)的某些任務(wù)和過程,并允許員工將時(shí)間花在更高價(jià)值的工作上。這是企業(yè)中最常用的人工智能技術(shù)。
15. 海量翻譯系統(tǒng)
Facebook 的人工智能實(shí)驗(yàn)室使用從網(wǎng)絡(luò)上自動(dòng)收集的 75 億對句子來訓(xùn)練該模型。FastText 語言模型識別語言,無監(jiān)督學(xué)習(xí)模型根據(jù)句子的含義匹配句子。目標(biāo)是提高同聲傳譯。
16. 預(yù)測系統(tǒng)和站點(diǎn)故障
計(jì)算機(jī)視覺可以預(yù)測和識別物理位置的故障。高科技工廠、航空公司制造商和建筑工地使用圖像識別系統(tǒng)來監(jiān)控項(xiàng)目并自動(dòng)警告問題。這是通過將現(xiàn)實(shí)世界的數(shù)據(jù)與數(shù)字雙胞胎的數(shù)據(jù)進(jìn)行比較來實(shí)現(xiàn)的。
17. 人工智能責(zé)任險(xiǎn)
當(dāng)機(jī)器表現(xiàn)不好時(shí),誰該受責(zé)備?例如,如果機(jī)器學(xué)習(xí)使一家公司容易受到向系統(tǒng)注入虛假訓(xùn)練數(shù)據(jù)的攻擊者的攻擊,會(huì)發(fā)生什么?這些問題可能會(huì)讓一家公司面臨訴訟風(fēng)險(xiǎn)。新的保險(xiǎn)模式將有助于解決這些問題。保險(xiǎn)商開始將人工智能納入網(wǎng)絡(luò)保險(xiǎn)計(jì)劃。
18. 操縱 AI 以獲得競爭優(yōu)勢
亞馬遜、谷歌和 Facebook 在過去幾年都因操縱搜索系統(tǒng)以優(yōu)先考慮對公司更有利可圖的結(jié)果而受到抨擊。搜索算法的調(diào)整對互聯(lián)網(wǎng)用戶看到的內(nèi)容有著重大影響,無論是新聞、產(chǎn)品還是廣告。這也在一定程度上導(dǎo)致了針對這些公司的持續(xù)反壟斷訴訟。
19. 全球投資 AI 熱潮
全球都在競相資助 AI 研究和收購 AI 初創(chuàng)企業(yè)。根據(jù)國家風(fēng)險(xiǎn)投資協(xié)會(huì)的數(shù)據(jù),2020 年第一季度,285 家美國 AI 初創(chuàng)公司籌集了 69 億美元。隨著 Covid 成為全球流行病,投資減少了,但包括蘋果、谷歌和微軟在內(nèi)的科技巨頭仍在收購 AI 公司。
20. 算法市場
大型科技公司、初創(chuàng)公司和開發(fā)者社區(qū)使用算法市場來分享和銷售他們的作品。
2018 年,微軟斥資 75 億美元收購 GitHub,這是一個(gè)流行的開發(fā)平臺,允許任何人托管和審查代碼,與其他開發(fā)人員合作,并構(gòu)建各種項(xiàng)目。AWS 擁有自己的市場,提供計(jì)算機(jī)視覺、語音識別和文本的模型和算法,其銷售者包括英特爾、CloudSight 和許多其他公司。
21. 100 年軟件
與其他工程工具相比,傳統(tǒng)軟件的保質(zhì)期短且不可預(yù)測。這導(dǎo)致令人頭痛的問題和昂貴的升級,通常會(huì)導(dǎo)致停機(jī)。
自 2015 年以來,美國國防高級研究計(jì)劃局 (DARPA) 資助了一百多年來使軟件可行的研究。這些系統(tǒng)將使用人工智能來動(dòng)態(tài)適應(yīng)環(huán)境和資源的變化。他們需要一種新穎的設(shè)計(jì)方法,使用人工智能來發(fā)現(xiàn)和顯示應(yīng)用程序的操作以及與其他系統(tǒng)的交互。
02 AI 與醫(yī)療、健康、科學(xué)
1. AI 加速科學(xué)發(fā)現(xiàn)
運(yùn)行幾個(gè)變量的實(shí)驗(yàn)通常需要對測量、材料和輸入進(jìn)行有條理的調(diào)整。研究生們可能會(huì)花費(fèi)數(shù)百個(gè)乏味的小時(shí)反復(fù)進(jìn)行小調(diào)整,直到找到解決方案,這是對他們認(rèn)知能力的浪費(fèi)。研究實(shí)驗(yàn)室現(xiàn)在使用人工智能系統(tǒng)來加速科學(xué)發(fā)現(xiàn)的過程。
2. AI 首次藥物發(fā)現(xiàn)
新冠肺炎加快了人工智能在藥物發(fā)現(xiàn)中的應(yīng)用。一個(gè)國際團(tuán)隊(duì)在不到 48 小時(shí)的時(shí)間內(nèi)合成了 2000 個(gè)分子的候選物,其中包括了一種 Covid 抗病毒藥物 —— 這一過程可能需要人類研究人員一個(gè)月或更長時(shí)間。倡導(dǎo)者說,人工智能將使藥物開發(fā)和臨床試驗(yàn)更加有效,從而降低藥物價(jià)格,為更個(gè)性化的藥物鋪平道路。
▲AI 用于提高新藥發(fā)現(xiàn)的速度和效率
3. AI 改善患者護(hù)理
新的醫(yī)療算法解決了美國的患者護(hù)理水平。不同的患者對癥狀的體驗(yàn)不同,他們的護(hù)理基于他們?nèi)绾蚊枋鲎约旱陌Y狀以及醫(yī)生如何解釋這些癥狀。研究人員正在訓(xùn)練深度學(xué)習(xí)模型,并發(fā)現(xiàn)病人護(hù)理中的差距。
4. AI 在醫(yī)學(xué)影像中的應(yīng)用
放射學(xué)家和病理學(xué)家越來越依賴人工智能來幫助他們進(jìn)行診斷醫(yī)學(xué)成像。到目前為止,大多數(shù)獲得批準(zhǔn)的設(shè)備都增強(qiáng)了檢查圖像和進(jìn)行診斷的過程。但是新興的自主產(chǎn)品正在進(jìn)入臨床環(huán)境。
5. 自然語言處理算法檢測病毒突變
自然語言處理 (NLP) 算法通常用于文本、單詞和句子,被用來解釋病毒的遺傳變化。蛋白質(zhì)序列和遺傳密碼可以使用自然語言處理技術(shù)來建模,并且可以像在文字處理軟件中寫單詞和句子一樣進(jìn)行操作。
麻省理工學(xué)院的研究人員使用自然語言處理對病毒逃逸進(jìn)行建模,通過在突變發(fā)生前使用這種模型,公共衛(wèi)生官員可以制定策略,并潛在地防止新的病毒傳播。
6. 無測試診斷
多個(gè)研究院所的科學(xué)家們及健康科學(xué)公司 ZOE 共同開發(fā)一個(gè)應(yīng)用程序來研究 Covid 癥狀并跟蹤病毒的傳播。它收集并使用人工智能來分析來自 400 萬全球貢獻(xiàn)者的數(shù)據(jù),以發(fā)現(xiàn)新的癥狀,預(yù)測 Covid 熱點(diǎn),并最終預(yù)測 Covid 病例,而無需物理測試。
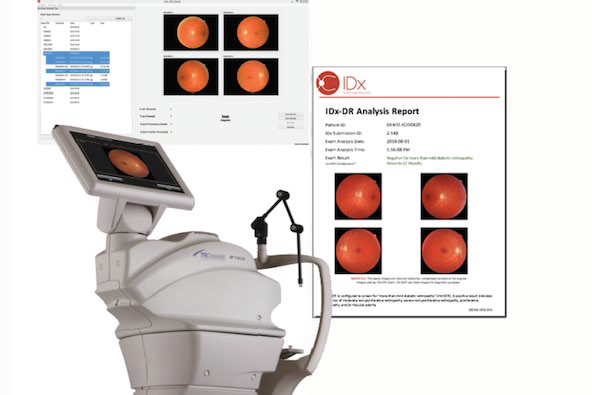
▲美國食品和藥物管理局(FDA)批準(zhǔn)第一個(gè)提供診斷決策的自主人工智能系統(tǒng) IDx-DR
7. 蛋白質(zhì)折疊
2020 年 11 月,DeepMind 的人工智能發(fā)布了一項(xiàng)重大公告:它成功地從蛋白質(zhì)的氨基酸序列中確定了蛋白質(zhì)的 3D 形狀。
預(yù)測蛋白質(zhì)結(jié)構(gòu)一直困擾著生物學(xué)家。AlphaFold 此前曾擊敗過其他團(tuán)隊(duì),但它在去年的 CASP 上工作得如此之快、如此之準(zhǔn)確,以至于它預(yù)示著這項(xiàng)技術(shù)將在不久的將來被其他科學(xué)家定期使用。
8. 夢想交流
科學(xué)家發(fā)現(xiàn)了如何在清醒夢者之間建立雙向溝通渠道。清醒夢者意識到自己睡著了,可以控制自己的夢境。并基于現(xiàn)有研究證明,做夢時(shí)有新的方式發(fā)送和接收實(shí)時(shí)信息。
9. 思維探測
深度神經(jīng)網(wǎng)絡(luò)被用來使用無線信號分析情緒狀態(tài)。研究實(shí)驗(yàn)室正在開發(fā)新技術(shù)來解讀我們的思想。這有商業(yè)含義:人力資源部門可以決定員工對公司政策的真實(shí)看法,律師可以決定陪審員在案件中的傾向,房地產(chǎn)經(jīng)紀(jì)人可以判斷購房者的嚴(yán)重程度。
03 AI 與消費(fèi)者
1. 零用戶界面
現(xiàn)代界面能夠以更少的直接動(dòng)作為我們做更多的事情,但仍然吸引著我們的注意力。零用戶界面 — 承諾優(yōu)先考慮這些決定,代表我們委托它們,甚至根據(jù)情況自主地為我們回答。許多這種無形的決策將在沒有直接監(jiān)督或來自人們的投入的情況下發(fā)生。
2. 消費(fèi)者級 AI 應(yīng)用
已經(jīng)出現(xiàn)了從專業(yè)研究人員使用的高度技術(shù)性的人工智能應(yīng)用程序到面向精通技術(shù)的消費(fèi)者的更輕量級、用戶友好的應(yīng)用程序的轉(zhuǎn)變。新的自動(dòng)化機(jī)器學(xué)習(xí)平臺使非專家構(gòu)建和部署預(yù)測模型成為可能。平臺希望在不久的將來,我們將使用各種人工智能應(yīng)用程序作為我們?nèi)粘9ぷ鞯囊徊糠郑拖裎覀兘裉焓褂梦④涋k公軟件和谷歌文檔一樣。
3. 無處不在的數(shù)字助理
數(shù)字助理 (DaS) 使用語義和自然語言處理以及我們的數(shù)據(jù)來預(yù)測我們接下來想要或需要做什么,有時(shí)甚至在我們知道要問什么之前。新聞機(jī)構(gòu)、娛樂公司、營銷人員、信用卡公司、銀行、地方當(dāng)局、政治活動(dòng)和許多其他人可以利用 DAs 來顯示和傳遞關(guān)鍵信息。

▲阿里巴巴的天貓精靈使用自然語言處理
4. 虛假娛樂深度
REFACE 是一個(gè)面部交換應(yīng)用程序,可以將您的面部變形為名人的身體,并創(chuàng)建 GIF 在社交媒體上共享。Jiggy 是一個(gè)能讓任何人跳舞的假貨。就目前而言,它們都產(chǎn)生了看起來像被操縱過的圖像和禮物。但是隨著技術(shù)變得如此容易使用,我們還要多久才能區(qū)分真假?
5. 個(gè)人數(shù)字雙胞胎
許多初創(chuàng)公司正在構(gòu)建可定制、可培訓(xùn)的平臺,能夠向你學(xué)習(xí) —— 然后通過個(gè)人數(shù)字雙胞胎在網(wǎng)上代表你。在不久的將來,包括健康和教育在內(nèi)的一系列領(lǐng)域的專業(yè)人士可能會(huì)擁有數(shù)字雙胞胎。
04 AI 與研究
1. 封閉源代碼
代碼對于可再現(xiàn)性、可問責(zé)性和透明度非常重要,并且是推動(dòng)更大的人工智能社區(qū)改進(jìn)的關(guān)鍵。但是當(dāng)學(xué)術(shù)研究人員發(fā)表論文時(shí),他們通常不會(huì)包含所有的代碼。給出的理由是:他們使用的代碼與其他專有研究混合在一起,因此無法發(fā)布,這也正是企業(yè)的做法。
2. 框架整合
谷歌的 TensorFlow 和 Facebook 的 PyTorch 是研究人員使用的兩個(gè)流行框架,不同框架的相對流行通常反映了商業(yè)應(yīng)用領(lǐng)域的趨勢。
在過去的四年里,F(xiàn)acebook 似乎取得了進(jìn)展。在提到研究人員使用的框架的會(huì)議論文中,75% 引用了 PyTorch,161 位發(fā)表的 TensorFlow 論文比 PyTorch 論文多的研究人員中,55% 的人轉(zhuǎn)向了 PyTorch。
3. 培訓(xùn)模型的成本
訓(xùn)練一個(gè)模特要花很多錢。幾個(gè)變量影響這些成本,所有這些成本在過去幾年都有所增加。對于較小的研究團(tuán)體和公司來說,成本是難以承受的。人工智能領(lǐng)域的一些人轉(zhuǎn)而允許大型科技公司預(yù)先培訓(xùn)和發(fā)布大型模型。
4. 自然語言處理基準(zhǔn)
通用語言理解評估基準(zhǔn)是用于訓(xùn)練、評估和分析自然語言理解系統(tǒng)的資源集合。人類基線分?jǐn)?shù)為 87,自然語言處理系統(tǒng)在 2020 年 8 月增至 90.6,超過人類。SuperGLUE 基準(zhǔn)是對更困難的語言理解任務(wù)、改進(jìn)的資源和新的公共排行榜的新度量。
預(yù)計(jì)到 2021 年底,這一新的基準(zhǔn)也將被超越。

▲SuperGLUE 將在 2021 年底被打破
5. 機(jī)器閱讀理解
對于人工智能研究人員來說,機(jī)器閱讀理解一直是一個(gè)具有挑戰(zhàn)性的目標(biāo),但也是一個(gè)重要的目標(biāo)。MRC 使系統(tǒng)能夠在篩選龐大數(shù)據(jù)集的同時(shí)閱讀、推斷意義并立即給出答案。2019 年,中國的阿里巴巴在接受微軟機(jī)器閱讀理解數(shù)據(jù)集 (簡稱 MARCO MS) 測試時(shí)表現(xiàn)優(yōu)于人類。
6. AI 自我總結(jié)
新的 AI 模型可以總結(jié)科學(xué)文獻(xiàn),包括關(guān)于自身的研究。艾倫人工智能研究所 (AI2) 在語義學(xué)者中使用了這個(gè)模型,語義學(xué)者是一個(gè)人工智能驅(qū)動(dòng)的科學(xué)論文搜索引擎,提供人工智能論文的簡短摘要。這項(xiàng)工作之所以令人印象深刻,是因?yàn)樗軌驕?zhǔn)確高效地壓縮長論文。
7. 無培訓(xùn) AI
訓(xùn)練機(jī)器人做不止一件事是困難的,但是一種新的模型在一個(gè)游戲中讓相同的機(jī)器人手臂相互對抗。這是多任務(wù)學(xué)習(xí)的一個(gè)例子,一種深度學(xué)習(xí)模式,在這種模式下,機(jī)器在進(jìn)步的同時(shí)學(xué)習(xí)不同的技能。OpenAI 的模型允許機(jī)器人解決新的問題,而不需要再培訓(xùn)。
8. 圖形神經(jīng)網(wǎng)絡(luò)
圖形神經(jīng)網(wǎng)絡(luò) (GNNs) 構(gòu)成了一種特殊類型的深度神經(jīng)網(wǎng)絡(luò),它對圖形作為輸入進(jìn)行操作。神經(jīng)網(wǎng)絡(luò)被用于檢測氣味 —— 在分子水平上預(yù)測氣味 —— 以及廣泛的化學(xué)和生物過程。例如,布羅德研究所的研究人員使用它們來發(fā)現(xiàn)沒有毒副作用的抗生素化合物。
9. 聯(lián)合學(xué)習(xí)
聯(lián)合學(xué)習(xí)是一種將機(jī)器學(xué)習(xí)推向邊緣的技術(shù)。這是由谷歌研究人員在 2016 年推出的一個(gè)新框架,它使算法可以在不損害用戶隱私的情況下使用手機(jī)和智能手表等設(shè)備上的數(shù)據(jù)。這個(gè)領(lǐng)域的研究急劇增加。
10. GP 模型
高斯過程是許多現(xiàn)實(shí)世界建模問題的黃金標(biāo)準(zhǔn),尤其是在模型的成功取決于其忠實(shí)表示預(yù)測不確定性的能力的情況下。得益于神經(jīng)網(wǎng)絡(luò)的改進(jìn),全球定位系統(tǒng)變得更加精確和易于訓(xùn)練。
11. GPT-3 的影響
GPT-3 是由 OpenAI 在去年發(fā)布的,但是 AI 表現(xiàn)出強(qiáng)烈的反穆斯林偏見。在該模型的許多使用案例中,穆斯林暴力偏見始終如一地、創(chuàng)造性地出現(xiàn)。這是偏見如何潛入我們自動(dòng)化系統(tǒng)的又一個(gè)例子。如果不加以控制,隨著人工智能的成熟,它將在整個(gè)社會(huì)造成問題。
12. Vokenization
像 GPT-3 這樣的模型是在句法和語法上訓(xùn)練的,而不是創(chuàng)造力或常識。人類以多層次、多維度的方式學(xué)習(xí),因此一種稱為 vokenization 的新技術(shù)通過將語言 “標(biāo)記” 與相關(guān)圖像進(jìn)行上下文映射,來外推僅包含語言的數(shù)據(jù)。
13. 機(jī)器圖像完成
如果一個(gè)計(jì)算機(jī)系統(tǒng)可以訪問足夠多的圖像 —— 比如說,數(shù)百萬張 —— 它就可以修補(bǔ)和填充圖片中的漏洞。這種能力對于專業(yè)攝影師以及每個(gè)想拍出更好自拍的人都有實(shí)際應(yīng)用。隨著這種技術(shù)變得司空見慣,將會(huì)有重大的偏見和其他陷阱需要克服。
14. 使用單個(gè)圖像的預(yù)測模型
計(jì)算機(jī)視覺系統(tǒng)變得越來越智能。神經(jīng)網(wǎng)絡(luò)可以從單一的彩色圖像預(yù)測幾何形狀。這項(xiàng)研究有一天將使機(jī)器人能夠更容易地在人類環(huán)境中導(dǎo)航 —— 并通過從我們的肢體語言中獲取線索來與我們?nèi)祟惢?dòng)。零售業(yè)、制造業(yè)和教育背景可能尤其相關(guān)。
15. 遠(yuǎn)程學(xué)習(xí)的無模型方法
夢想家是一種強(qiáng)化學(xué)習(xí) (RL) 代理,它使用世界模型來學(xué)習(xí)長期預(yù)測,通過模型預(yù)測采用反向傳播。它可以從原始圖像中創(chuàng)建模型,并使用圖形處理單元 (GPU) 并行從數(shù)千個(gè)預(yù)測序列中學(xué)習(xí)。這種新方法使用一個(gè)想象的世界來解決長期任務(wù)。
16. 實(shí)時(shí)機(jī)器學(xué)習(xí)
人工智能面臨的一大挑戰(zhàn)是構(gòu)建能夠主動(dòng)收集和解釋數(shù)據(jù)、發(fā)現(xiàn)模式和整合上下文并最終實(shí)時(shí)學(xué)習(xí)的機(jī)器。對實(shí)時(shí)機(jī)器學(xué)習(xí) (RTML) 的新研究表明,使用連續(xù)的數(shù)據(jù)流和實(shí)時(shí)調(diào)整模型是可能的。這標(biāo)志著數(shù)據(jù)移動(dòng)方式和我們檢索信息方式的巨大變化。
17. 自動(dòng)機(jī)器學(xué)習(xí)
一些組織希望擺脫傳統(tǒng)的機(jī)器學(xué)習(xí)方法,這種方法既耗時(shí)又困難,需要數(shù)據(jù)科學(xué)家、人工智能領(lǐng)域的專家和工程師。自動(dòng)機(jī)器學(xué)習(xí) (AutoML) 是一種新的方法:將原始數(shù)據(jù)和模型匹配在一起以揭示最相關(guān)信息的過程。谷歌、亞馬遜和微軟現(xiàn)在提供大量的自動(dòng)產(chǎn)品和服務(wù)。
18. 人機(jī)混合視覺
沒有人類的幫助,人工智能還不能完全發(fā)揮作用。混合智能系統(tǒng)將人類和人工智能系統(tǒng)結(jié)合起來,以實(shí)現(xiàn)更高的準(zhǔn)確性。微軟研究人員提出了潘多拉,一套用于理解系統(tǒng)故障的混合人機(jī)方法和工具。潘多拉利用人類和系統(tǒng)生成的觀察來解釋與輸入內(nèi)容和系統(tǒng)架構(gòu)相關(guān)的故障。
19. 神經(jīng)符號
研究人員正在研究使用神經(jīng)網(wǎng)絡(luò)將學(xué)習(xí)和邏輯結(jié)合起來的新方法,這種網(wǎng)絡(luò)將通過符號來理解數(shù)據(jù),而不是總是依賴人類程序員為他們排序、標(biāo)記和編目數(shù)據(jù)。符號算法將有助于這一過程,這最終將導(dǎo)致一個(gè)健壯的系統(tǒng),不總是需要一個(gè)人來訓(xùn)練。
20. 通用強(qiáng)化學(xué)習(xí)算法
研究人員正在開發(fā)可以學(xué)習(xí)多項(xiàng)任務(wù)的單一算法。2020 年 1 月,DeepMind 發(fā)表了一項(xiàng)新的研究,表明強(qiáng)化學(xué)習(xí)技術(shù)如何可以用來提高我們對心理健康和動(dòng)機(jī)的理解。
21. 持續(xù)學(xué)習(xí)
目前,深度學(xué)習(xí)技術(shù)正在幫助系統(tǒng)學(xué)習(xí)以類似人類可以做的方式解決復(fù)雜的任務(wù)。
他們需要一個(gè)嚴(yán)格的順序:收集數(shù)據(jù),確定目標(biāo),部署算法。這個(gè)過程需要人,并且可能很耗時(shí),尤其是在需要監(jiān)督訓(xùn)練的早期階段。持續(xù)學(xué)習(xí)更多的是關(guān)于自我調(diào)節(jié)和增量技能的培養(yǎng)和發(fā)展,研究人員將繼續(xù)推進(jìn)這一領(lǐng)域可能的極限。
22. Franken 算法的擴(kuò)散
雖然一個(gè)單一的算法可能很容易描述和部署,如預(yù)期的那樣,算法系統(tǒng)一起工作有時(shí)會(huì)帶來問題。開發(fā)人員并不總是事先知道一個(gè)算法將如何與其他算法一起工作。
有時(shí),幾個(gè)開發(fā)團(tuán)隊(duì)在獨(dú)立地處理不同的算法和數(shù)據(jù)集,一旦部署完成,他們只能看到彼此的工作。對于 Facebook 這樣的大公司來說,這尤其具有挑戰(zhàn)性,因?yàn)樗鼈冊谌魏谓o定的時(shí)間都有數(shù)十億個(gè)算法在一起工作。
23. 專有的、自主開發(fā)的 AI 語言
Python、Julia、Lisp 標(biāo)志著人工智能生態(tài)系統(tǒng)的未來可能會(huì)出現(xiàn)分裂,這與當(dāng)前 iOS/Android 的競爭或長期的 Mac/PC 戰(zhàn)爭并無不同。企業(yè)會(huì)發(fā)現(xiàn)在人工智能框架和語言之間切換越來越成本高昂和困難。
05 AI 與人才
1. AI 人才流失
人工智能研究人員從學(xué)術(shù)界流失到公司的速度驚人。原因很簡單:薪酬待遇。
頂尖學(xué)者獲得豐厚的薪水和福利,他們可以在類似的終身環(huán)境中工作,這種環(huán)境是精心培養(yǎng)的,以代表他們在學(xué)術(shù)界的經(jīng)驗(yàn)。今天挖墻腳的部門,可能會(huì)搶奪未來 AI 專家的未來。沒有偉大的學(xué)者,誰來培養(yǎng)下一代創(chuàng)新者?
2. AI 大學(xué)
專門致力于人工智能的新機(jī)構(gòu)正在世界各地推出。在阿拉伯聯(lián)合酋長國,新的人工智能大學(xué)于去年成立。MBZUAI 是世界上第一所研究生水平的研究型人工智能大學(xué)。人工智能大學(xué)由哈佛大學(xué)和加州大學(xué)洛杉磯分校共同創(chuàng)建,是一個(gè)機(jī)器學(xué)習(xí)和人工智能培訓(xùn)的在線項(xiàng)目。
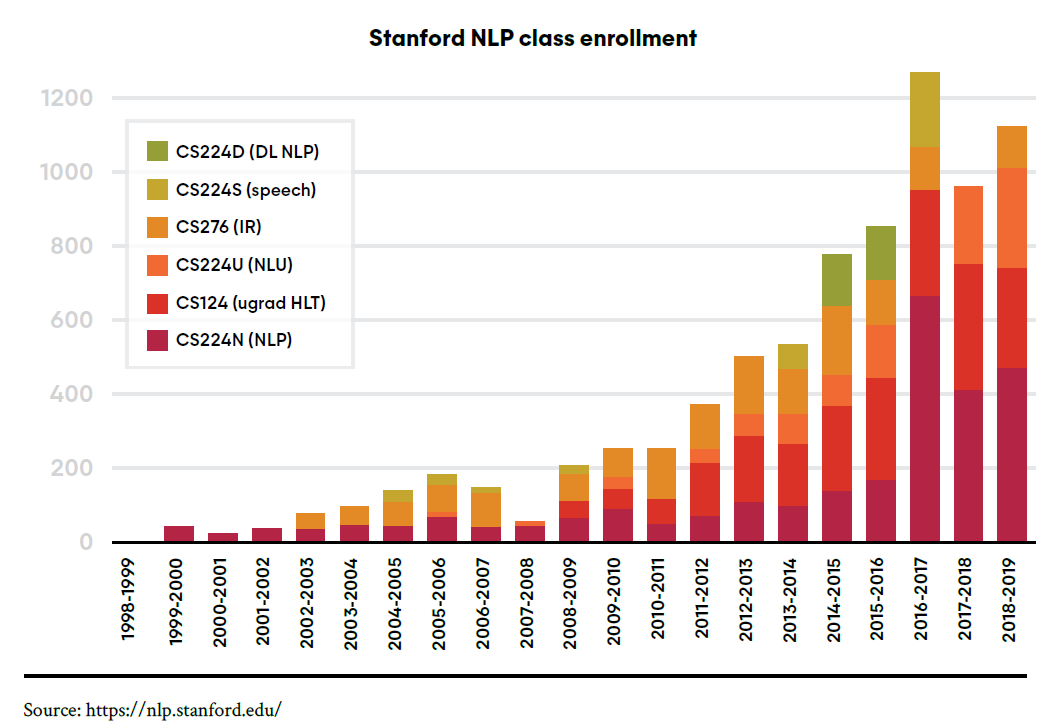
▲斯坦福大學(xué)自然語言處理課程的注冊人數(shù)是 2004 年的 10 倍
3. 對 AI 的需求正在增長
多年來,人工智能人才的需求超過了供應(yīng)。在美國,去年與人工智能相關(guān)的職位發(fā)布比與人工智能相關(guān)的職位查看多近三倍。雖然學(xué)校正在增加項(xiàng)目,增加招生,增加班級,但對人工智能技能的新需求太多,訓(xùn)練有素的工人遠(yuǎn)遠(yuǎn)不夠。隨著需求的增長,招聘過程需要更長時(shí)間,成本也越來越高。
4. 企業(yè) AI 實(shí)驗(yàn)室
人工智能實(shí)驗(yàn)室遍布世界各地,集中在北美、歐洲和亞洲。Facebook、谷歌、IBM 和微軟運(yùn)營著 62 個(gè)致力于人工智能研發(fā)的實(shí)驗(yàn)室,其中大多數(shù)在美國以外,因?yàn)榭梢越佑|到人才。
5. 面試 AI
識別系統(tǒng)現(xiàn)在可以用來觀察你被面試的情況,并衡量你的熱情、堅(jiān)韌和沉著。算法分析數(shù)百個(gè)細(xì)節(jié),如你的語氣,你的面部表情和你的習(xí)慣,以最好地預(yù)測你將如何適應(yīng)一個(gè)社區(qū)的文化。
06 AI 與創(chuàng)造性
1. 輔助創(chuàng)造力
生成性敵對網(wǎng)絡(luò) (GANs) 的能力遠(yuǎn)遠(yuǎn)超過生成深度偽造視頻。研究人員正在與藝術(shù)家和音樂家合作,以產(chǎn)生全新的創(chuàng)造性表達(dá)形式。從合成非洲部落面具到建造幻想、虛構(gòu)的星系,人工智能被用來探索新的想法。
2. 用于內(nèi)容的生成算法
“野蠻司法” 在 YouTube 上播出,由一名合成記者弗 Fred Sassy 擔(dān)任主角,他看起來很像前總統(tǒng)特朗普,只是聲音和發(fā)型不同,足以逃避法律挑戰(zhàn)。劇集中出現(xiàn)了 Gore,Mark Zuckerberg,Jared Kushner 和其他人的虛假人物。
3. 從短視頻生成虛擬環(huán)境
Nvidia 正在教人工智能從短視頻剪輯中構(gòu)建逼真的 3D 環(huán)境。該方法建立在以前對 GANs 的研究基礎(chǔ)上。自動(dòng)生成的虛擬環(huán)境可以用于幻想和超級英雄電影,并可以降低電視制作和游戲開發(fā)的成本。
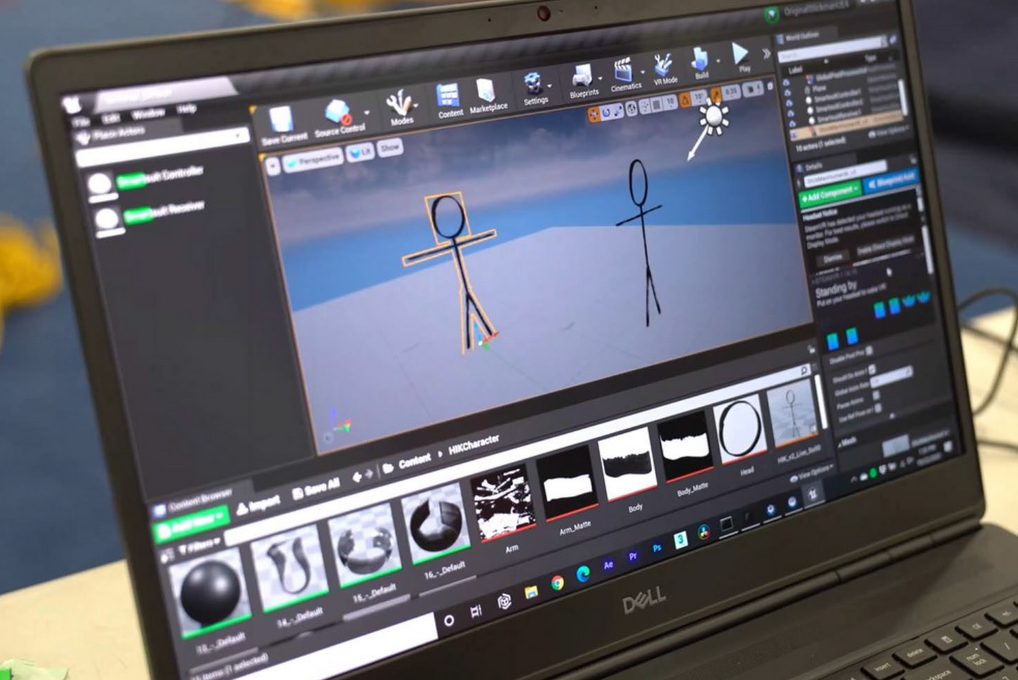
▲創(chuàng)意工作室 SoKrispyMedia 制作以戰(zhàn)斗中的棍形人物為特色的短片,它依靠實(shí)時(shí)渲染來獲得逼真的結(jié)果 (來源:Nvidia)
4. 自動(dòng)化版本控制
總部位于瑞士的塔梅迪亞的記者們在他們國家 2018 年的選舉中,一個(gè)名為鳶的決策樹算法生成了自動(dòng)化的文章,詳細(xì)描述了私人媒體集團(tuán)旗下 30 家報(bào)紙覆蓋的每個(gè)城市的投票結(jié)果。這些文章有一個(gè)特殊的署名,提醒讀者它們是由一種算法寫的。
隨著更多實(shí)驗(yàn)的進(jìn)行,我們預(yù)計(jì)新聞和娛樂媒體公司將開發(fā)同一內(nèi)容的多個(gè)版本,以覆蓋更廣泛的受眾或大規(guī)模制作大量內(nèi)容。
5. 自動(dòng)語音克隆和配音
類似人工智能和描述性人工智能在內(nèi)的人工智能公司的承諾使得克隆聲音成為可能。這意味著很快你可能會(huì)在電影中看到像 Phoebe Waller-Bridge 這樣的明星,還會(huì)聽到她用自己的聲音說葡萄牙語。然而,這項(xiàng)技術(shù)顯然有黑暗的一面,導(dǎo)致了語音詐騙的出現(xiàn)。

▲自動(dòng)點(diǎn)唱機(jī)是一個(gè)神經(jīng)網(wǎng)絡(luò),它產(chǎn)生音樂,包括初級歌唱,作為各種流派和藝術(shù)家風(fēng)格的原始音頻
6. 自動(dòng)環(huán)境噪聲配音
人們一直在訓(xùn)練計(jì)算機(jī)觀看視頻,并預(yù)測我們物理世界中相應(yīng)的聲音。這項(xiàng)研究的重點(diǎn)正在麻省理工學(xué)院的計(jì)算機(jī)科學(xué)和人工智能實(shí)驗(yàn)室進(jìn)行,應(yīng)該有助于系統(tǒng)理解物體在物理領(lǐng)域是如何相互作用的。許多項(xiàng)目正在進(jìn)行中,以使自動(dòng)生成聲音、視頻甚至故事情節(jié)變得更加容易。
07 AI 與安全
1. AI 民族主義
政府正在對并購和投資活動(dòng)實(shí)施新的限制,以確保公司開發(fā)的人工智能不會(huì)幫助外國對手。去年,美國參議院提出的一項(xiàng)兩黨法案被稱為 “永無止境邊境法案”,該法案明確將人工智能界定為美國和中國之間的一場競賽。

▲美國眾議院通過了永無止境邊境法案
2. 國家 AI 戰(zhàn)略
新一波國家將在 2021 年和 2022 年推出國家人工智能戰(zhàn)略。中國通過了新一代人工智能發(fā)展計(jì)劃,設(shè)定了新的基準(zhǔn),要在 10 年內(nèi)成為世界上占主導(dǎo)地位的人工智能玩家。在美國,許多公共和私人團(tuán)體代表國家獨(dú)立研究人工智能的未來。然而,這些努力缺乏機(jī)構(gòu)間協(xié)作和協(xié)調(diào)努力,以精簡目標(biāo)、成果、研發(fā)努力和資金。
3. 作為關(guān)鍵基礎(chǔ)設(shè)施的 AI
政府研究人員正在探索引領(lǐng)關(guān)鍵系統(tǒng)應(yīng)用人工智能開發(fā)的方法:公路和鐵路運(yùn)輸系統(tǒng);發(fā)電和配電;和消防車等公共安全車輛的路線預(yù)測。人們不再回避人工智能系統(tǒng),而是對使用該技術(shù)來預(yù)防災(zāi)難和提高安全性產(chǎn)生了新的興趣。
4. 基于國家的防護(hù)和法規(guī)
從自動(dòng)駕駛汽車事故到通過虛假信息活動(dòng)干擾選舉,再到通過面部識別和自動(dòng)監(jiān)控增強(qiáng)的政治鎮(zhèn)壓,過去幾年的重大事件極大地緩解了人工智能的危險(xiǎn)。對于一項(xiàng)觸及人類方方面面的技術(shù)來說,現(xiàn)在幾乎沒有防護(hù)存在,各國都在競相開發(fā)和發(fā)布自己的人工智能戰(zhàn)略和指南。
5. 監(jiān)管 DeepFake
美國和其他地方將在 2021 年出臺新的措施來監(jiān)管深度假貨的生產(chǎn)和分銷。夏威夷州議會(huì)的一項(xiàng)法案試圖禁止未經(jīng)授權(quán)的 DeepFake 應(yīng)用程序和工具。如果通過,DeepFake 將被視為 C 級重罪。這些倡議可能會(huì)遇到禁止 DeepFake 侵犯言論自由權(quán)的爭論。
6. 讓 AI 自我解釋
計(jì)算機(jī)科學(xué)家、記者和法律學(xué)者越來越擔(dān)心人工智能系統(tǒng)不應(yīng)該如此神秘,監(jiān)管機(jī)構(gòu)正在密切關(guān)注。總的來說,必須克服一些挑戰(zhàn)。要求人工智能透明可能會(huì)泄露公司的商業(yè)秘密。要求系統(tǒng)在工作時(shí)解釋他們的決策過程也會(huì)降低輸出的速度和質(zhì)量。在未來的幾年里,不同的國家可能會(huì)頒布新的規(guī)定要求 AI 自我解釋。
7. 新戰(zhàn)略技術(shù)聯(lián)盟
國家間新的戰(zhàn)略技術(shù)聯(lián)盟將有助于推動(dòng)未來的研發(fā),但也可能使現(xiàn)有的地緣政治聯(lián)盟緊張或加劇緊張局勢。可能的合作伙伴包括美國、德國、日本、印度、韓國、英國、法國和加拿大 —— 剩下中國和俄羅斯將分別合作。后兩個(gè)國家已經(jīng)宣布了衛(wèi)星和深空探測技術(shù)聯(lián)盟。

▲網(wǎng)絡(luò)戰(zhàn)將在未來十年改變戰(zhàn)爭藝術(shù)
8. 新型軍工聯(lián)合體
在過去的幾年里,美國一些最大的人工智能公司已經(jīng)與軍方合作,推進(jìn)研發(fā)并提高效率。事實(shí)上,沒有外部公司的幫助,公共部門無法推進(jìn)其技術(shù)。另外,還有很多錢可以賺。
9. 算法戰(zhàn)爭
未來的戰(zhàn)爭將以代碼形式進(jìn)行,使用數(shù)據(jù)和算法作為強(qiáng)大的武器。當(dāng)前的全球秩序正在由人工智能塑造,在人工智能研究方面領(lǐng)先世界的國家在開發(fā)至少包括一些自主功能的武器系統(tǒng)。
08 中國的 AI 規(guī)則
1. 中國人工智能現(xiàn)況
如果你認(rèn)為中國是一個(gè)復(fù)制而不是創(chuàng)新的國家,那就再想想。中國是人工智能的全球領(lǐng)導(dǎo)者,在許多領(lǐng)域都取得了巨大的進(jìn)步。企業(yè)和政府已經(jīng)合作制定了一項(xiàng)全面的計(jì)劃,到 2030 年使中國成為世界主要的人工智能創(chuàng)新中心,并且已經(jīng)朝著這個(gè)目標(biāo)取得了重大進(jìn)展。
中國比西方有著不可思議的優(yōu)勢。這也給了中國三大公司百度、阿里巴巴和騰訊超能力。總的來說,它們被稱為最佳可得技術(shù),它們都是該國資本充足、高度組織化的人工智能計(jì)劃的一部分。
中國人的回報(bào)不僅僅是典型的投資回報(bào),中國公司也期待知識產(chǎn)權(quán)。總部位于中國的人工智能初創(chuàng)公司現(xiàn)在占全球人工智能投資的近一半。
2. 受中國教育的研究人員突起
總部位于保爾森研究所 (Paulson Institute) 的智庫宏論道 (MacroPolo) 的一項(xiàng)新研究顯示,受中國教育的研究人員主導(dǎo)了著名的國際人工智能會(huì)議神經(jīng)科 (NeurIPS) 接受的論文。宏論道促進(jìn)了美中之間的建設(shè)性合作。近三分之一的論文來自中國——比任何其他國家都多。
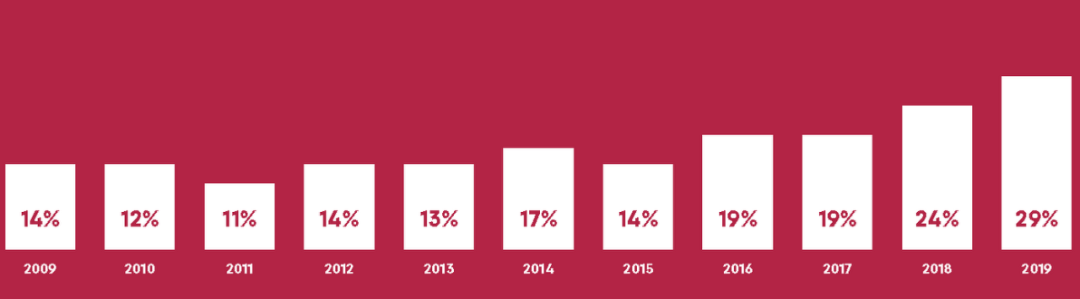
▲NeurIPS 接受的論文有近三分之一的論文來自中國
09 AI 與社會(huì)
1. 倫理沖突
2020 年 12 月 2 日,谷歌倫理人工智能團(tuán)隊(duì)的共同創(chuàng)始人 Timnit Gebru 發(fā)布了一條推特,說她被解雇了。她因在偏見和面部識別方面的開創(chuàng)性研究而聞名,在更廣泛的人工智能社區(qū)中廣受尊重。
Facebook 成立了一個(gè)獨(dú)立的監(jiān)督委員會(huì),有權(quán)否決內(nèi)容審核準(zhǔn)則,甚至否決馬克?扎克伯格本人。
2021 年 1 月,該委員會(huì)對有爭議的內(nèi)容做出了第一次裁決,推翻了它所看到的五起案件中的四起。但 Facebook 上每天都有數(shù)十億條帖子,還有數(shù)不清的內(nèi)容投訴——這意味著監(jiān)督委員會(huì)以傳統(tǒng)政府的速度運(yùn)作。我們預(yù)計(jì) 2021 年會(huì)有更多的道德沖突。

▲算法偏見的先驅(qū)研究者 Timnit Gebru
2. 環(huán)境監(jiān)測
關(guān)起門來發(fā)生的事情可能不會(huì)保密太久,高管們應(yīng)該警惕新的環(huán)境監(jiān)控方法。麻省理工學(xué)院的科學(xué)家發(fā)現(xiàn)了如何使用計(jì)算機(jī)視覺來跟蹤室內(nèi)的數(shù)據(jù),這對從事敏感項(xiàng)目的公司來說可能不是好消息。從事信息安全和風(fēng)險(xiǎn)管理的人應(yīng)該特別注意計(jì)算機(jī)視覺的進(jìn)步。
3. 市場整合
隨著人工智能生態(tài)系統(tǒng)的繁榮,大量收購也意味著整合。大公司現(xiàn)在早在初創(chuàng)公司成熟之前就將其搶購一空。只有九家大公司主宰著人工智能領(lǐng)域:美國的谷歌、亞馬遜、微軟、IBM、Facebook 和蘋果,中國的百度、阿里巴巴和騰訊。
在投資方面,高通、騰訊、英特爾投資、谷歌風(fēng)險(xiǎn)投資、英偉達(dá)、Salesforce、三星風(fēng)險(xiǎn)投資、阿里巴巴、蘋果、百度、花旗和智能手機(jī)為增長提供了大量資金。
4. 分散
人工智能生態(tài)系統(tǒng)跨越數(shù)百家公司。他們正在構(gòu)建網(wǎng)絡(luò)基礎(chǔ)設(shè)施、定制芯片組和消費(fèi)應(yīng)用等。與此同時(shí),大量的政策團(tuán)體、倡導(dǎo)組織和政府正在制定指導(dǎo)方針、規(guī)范和標(biāo)準(zhǔn)以及政策框架,希望能夠指導(dǎo)人工智能的未來發(fā)展。因此,生態(tài)系統(tǒng)在兩個(gè)方面是分散的:基礎(chǔ)設(shè)施標(biāo)準(zhǔn)和治理。
5. AI 偏見問題
眾所周知,人工智能有一個(gè)嚴(yán)重的多方面的偏見問題。隨著計(jì)算機(jī)系統(tǒng)越來越擅長決策,算法可能會(huì)將我們每個(gè)人分成對我們來說沒有任何明顯意義的組,但可能會(huì)產(chǎn)生巨大的影響。
越來越多的數(shù)據(jù)在你不知情的情況下被收集并出售給第三方。隨著時(shí)間的推移,這些偏見會(huì)自我強(qiáng)化。隨著 AI 應(yīng)用越來越普遍,偏向的負(fù)面影響會(huì)更大。
6. 有問題的培訓(xùn)數(shù)據(jù)
開發(fā)人員社區(qū)中遇到了一些挑戰(zhàn)。即已經(jīng)很難從真實(shí)的人那里獲得真實(shí)的數(shù)據(jù)來訓(xùn)練系統(tǒng),并且隨著新的隱私限制,開發(fā)人員選擇更多地依賴公共的數(shù)據(jù)集,這些數(shù)據(jù)集可能存在問題。
7. AI 捕捉欺騙行為
AI 正被用來捕捉欺騙行為。ECRI 研究所的 CrossCheq 使用機(jī)器學(xué)習(xí)和數(shù)據(jù)分析來尋找招聘過程中的夸張和誤導(dǎo)信息。哥本哈根大學(xué)的研究人員創(chuàng)建了一個(gè)機(jī)器學(xué)習(xí)系統(tǒng),以 90% 的準(zhǔn)確率發(fā)現(xiàn)論文中的作弊行為。
8. 針對弱勢群體的算法測試
經(jīng)過正確訓(xùn)練的機(jī)器學(xué)習(xí)系統(tǒng)可以幫助找到失蹤的兒童并發(fā)現(xiàn)虐待行為。問題是,這些系統(tǒng)使用來自弱勢群體的數(shù)據(jù)來進(jìn)行培訓(xùn)。圖像識別是一個(gè)特別棘手的挑戰(zhàn),因?yàn)檠芯咳藛T需要大型數(shù)據(jù)集來完成他們的工作,經(jīng)常是未經(jīng)同意使用圖片。
9. AI 故意隱藏?cái)?shù)據(jù)
斯坦福大學(xué)和谷歌的研究人員發(fā)現(xiàn),旨在將衛(wèi)星圖像轉(zhuǎn)化為可用地圖的人工智能隱瞞了某些數(shù)據(jù)。
最初,他們使用了一張網(wǎng)絡(luò)沒有看到的航拍照片。最終的圖像看起來非常接近原始圖像。但是在更深入的研究中,研究人員發(fā)現(xiàn)原始圖像和生成圖像中的許多細(xì)節(jié)在人工智能制作的地圖中是不可見的。事實(shí)證明,系統(tǒng)學(xué)會(huì)了將原始圖像的信息隱藏在它生成的圖像中。
10. 未曝光的 AI 事故
2018 年和 2019 年眾多 AI 相關(guān)事故中,只有少數(shù)成為頭條。但還有無數(shù)次沒有導(dǎo)致死亡的事件公眾并不知道。目前,研究人員沒有義務(wù)報(bào)告涉及我們數(shù)據(jù)或人工智能過程的事故或事件,除非違反了法律。
雖然大公司必須告知消費(fèi)者他們的個(gè)人數(shù)據(jù)是否被盜,但它們不需要公開記錄算法學(xué)會(huì)基于種族或性別歧視他人的情況。
11. 數(shù)字紅利
人工智能將不可避免地導(dǎo)致全球勞動(dòng)力的轉(zhuǎn)移,導(dǎo)致許多行業(yè)的失業(yè)。牛津大學(xué)人類研究所的研究人員、今日未來研究所的研究人員和前美國總統(tǒng)候選人楊安澤都發(fā)表了概述不同版本的 “數(shù)字紅利” 的著作 —— 這是公司向社會(huì)償還部分人工智能利潤的一種方式。
12. 信任優(yōu)先
人工智能系統(tǒng)依賴于我們的信任。如果我們不再相信他們的成果,幾十年的研究和技術(shù)進(jìn)步將會(huì)付諸東流。政府、企業(yè)、非營利組織等各個(gè)部門的領(lǐng)導(dǎo)者必須對所使用的數(shù)據(jù)和算法有信心。建立信任和問責(zé)制需要透明度。
此外,雇傭倫理學(xué)家直接與經(jīng)理和開發(fā)人員合作,并確保開發(fā)人員本身是多樣化的,代表不同的種族、民族和性別,將減少人工智能系統(tǒng)中固有的偏見。
人工智能在多個(gè)維度上影響著每一項(xiàng)業(yè)務(wù)。人工智能是大多數(shù)組織的基石,從員工自動(dòng)化到數(shù)字化,再到員工分配等等。
人工智能也是創(chuàng)新和創(chuàng)造過程的添加劑。創(chuàng)新團(tuán)隊(duì)可以利用深度學(xué)習(xí)來開發(fā)新產(chǎn)品,了解市場,預(yù)測即將發(fā)生的事情。特別是隨著無代碼和低代碼應(yīng)用程序變得更加廣泛,創(chuàng)新團(tuán)隊(duì)將為決策管理、一般性頭腦風(fēng)暴和產(chǎn)生新想法的強(qiáng)大方法構(gòu)建強(qiáng)大的系統(tǒng)。
同時(shí),人工智能又面臨了許多風(fēng)險(xiǎn)。新法規(guī)可能會(huì)抑制研究、創(chuàng)新和產(chǎn)品開發(fā)。地緣政治緊張和人工智能民族主義將開始以新的方式引導(dǎo)外國投資。面部識別中的偏見應(yīng)該是大家都關(guān)心的。應(yīng)開發(fā)風(fēng)險(xiǎn)模型來確定可信的近期情景,以便領(lǐng)導(dǎo)者能夠相應(yīng)地調(diào)整策略。
最后,這份報(bào)告還涵蓋了包括 5G、區(qū)塊鏈在內(nèi)的其他眾多領(lǐng)域的技術(shù)趨勢,但是由于篇幅所限,在這里不能一一翻譯整理,感興趣的朋友可以在公眾號后臺對話框回復(fù)2021科技趨勢查看報(bào)告完整版。
(原報(bào)告篇幅較多,解讀內(nèi)容難免有紕漏,請大家多指正)
資料來源:
https://futuretodayinstitute.com/trends/

