
短視頻中解決音視頻混音出現(xiàn)雜音的問題
1 你用過音視頻合成嗎?
現(xiàn)在抖音快手各種短視頻也算是深入人心了,短視頻剪輯中有一個非常重要的功能,就是音視頻合成,選擇一段視頻和一段音頻,然后將它們合成一個新的視頻,新生成的視頻中會有兩個音頻的混音。
下面我們來拆分一下音視頻合成的做法:
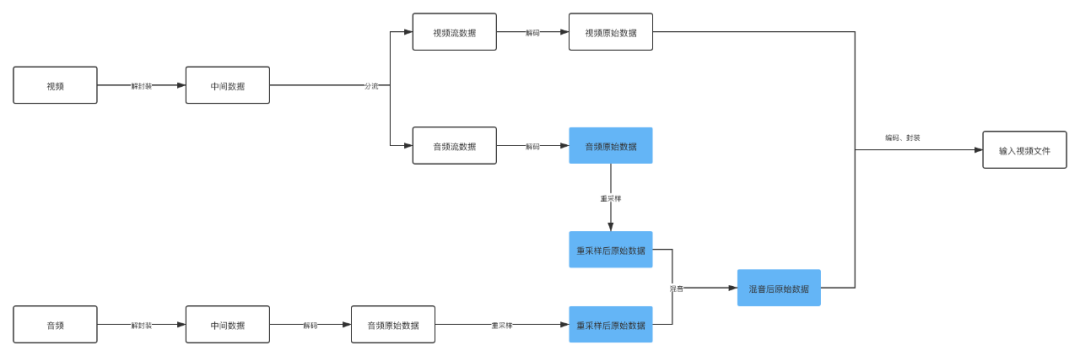
圖中著重標記的幾個流程可以看出來這是音頻視頻合成的重點,其實容易出錯也是在這個地方。
重采樣,這是一個什么知識點?在介紹重采樣之前,可以先介紹介紹一下音頻的一些性質(zhì)了。
2 音頻采集的指標
2.1 采樣率
采樣率就是俗稱的取樣頻率,指每秒鐘取得聲音樣本的次數(shù),采樣頻率越高,聲音的質(zhì)量就越好,聲音的還原也就越真實,但是采樣頻率比較高占用的資源就比較高。
我們知道人耳正常情況下只能接收20Hz ~ 20kHz 音頻范圍聲音,超過20kHz成為超聲波,低于20Hz成為低聲波,我們都是聽不到的,這兒是說的聲音的頻率和采樣率關(guān)系不大。
言歸正傳,過高的采樣率確實可以將聲音刻畫的比較細致,但是對人耳意義不大,所以還是要做好權(quán)衡,根據(jù)實際的應用來選擇合適的采樣率。
| 采樣率 | 使用場景 |
| 8000 Hz | 家用電話的采樣率 |
| 44100 Hz | 音樂CD的采樣率 |
| 48000 Hz | 標準的音頻采樣率,目前手機大多數(shù)采用這個采樣率 |
| 96000 Hz | 藍光視頻的采樣率 |
其他的采樣很多,不一一介紹了,大家感興趣可以參考:
https://en.wikipedia.org/wiki/Sampling_%28signal_processing%29
2.2 采樣位數(shù)
采樣位數(shù)就是采樣值或者取樣值,本質(zhì)就是將采樣樣本幅度量化,這是用來衡量聲音波動變化的一個參數(shù),也可以被認為是聲音的“分辨率”,它的數(shù)值越大,說明聲音的“分辨率”越高,能發(fā)出的聲音能力就越強,越細膩。
每個采樣數(shù)據(jù)記錄的是振幅,采樣精度取決于采樣位數(shù)的大小:
1字節(jié):8bit,只能記錄256個數(shù),振幅只能劃分為256個等級。
2字節(jié):16bit,可以細化到65536個數(shù),正常的CD就是這個標準。
4字節(jié):32bit,可以細分到4294967296個數(shù),劃分比較細致,人耳識別不了這么細致的聲音。
2.3 采樣通道數(shù)
通道數(shù)就是聲音采集的渠道有多少。常用的有立體聲和單聲道。
mono:單聲道
stereo:雙聲道
4.1聲道:有4個發(fā)聲點,前左、前右、后左、后右,同時增加一個低音道,增強對低頻信號的處理。
5.1聲道:基于4.1聲道,同時增加一個中置單元,這個中置單元負責傳送低于80Hz的聲音信號,增加了人聲,一般用在電影院里面。
7.1聲道:在聽者的周圍建立起一套前后場相對平衡的聲場,7.1聲道在5.1聲道的基礎(chǔ)上加上了雙路中后置,可以在聽者在任意角度都能聽到一致的聲音。
3 聲音的三個基本屬性
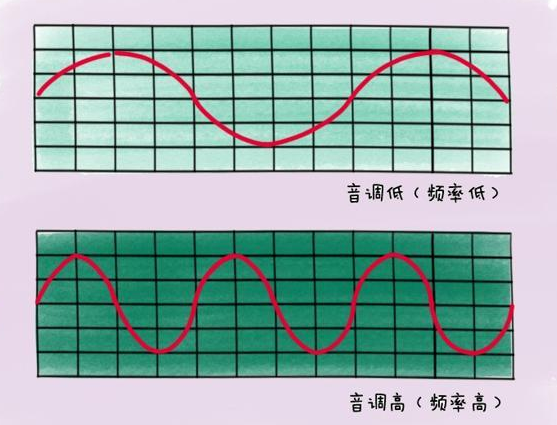
3.1 音調(diào)
聲音頻率的高低叫做音調(diào)(Pitch),是聲音的三個主要的主觀屬性,即音量(響度)、音調(diào)、音色(也稱音品) 之一。表示人的聽覺分辨一個聲音的調(diào)子高低的程度。音調(diào)主要由聲音的頻率決定,同時也與聲音強度有關(guān)
波長長短是衡量聲音音調(diào)的因素:
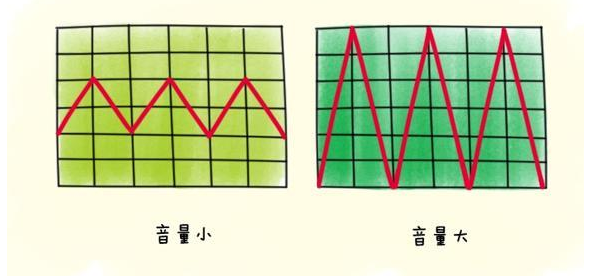
3.2 響度
人主觀上感覺聲音的大小(俗稱音量),由“振幅”(amplitude)和人離聲源的距離決定,振幅越大響度越大,人和聲源的距離越小,響度越大。(單位:分貝dB)
聲波的振幅表示聲音的音量大小:
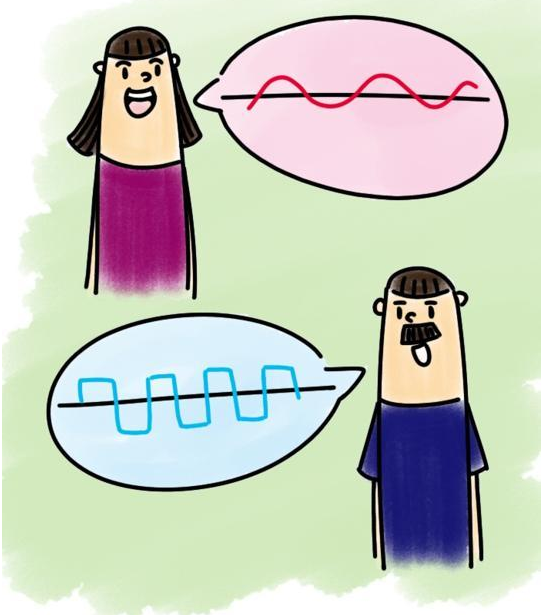
3.3 音色
又稱音品,波形決定了聲音的音色。聲音因不同物體材料的特性而具有不同特性,音色本身是一種抽象的東西,但波形是把這個抽象直觀的表現(xiàn)。音色不同,波形則不同。典型的音色波形有方波,鋸齒波,正弦波,脈沖波等。不同的音色,通過波形,完全可以分辨的。
音色主要和聲波的波紋有關(guān):
4 為什么需要重采樣
因為不同的平臺不能支持所有的采樣率,所以移植到其他平臺播放的時候,如果不支持當前的音頻采樣率,就需要對音頻采樣率進行重新采樣,就像視頻的重新編解碼一樣的。不然播放音頻會出現(xiàn)問題。無法將聲音的原本特性還原出來。
在音視頻編輯中,經(jīng)常用到的混音,就需要用到重采樣的功能,保證兩個音頻混合起來,音頻的采樣率一定要標準化,是一樣的采樣率,這樣播放出來的音頻才不能失真。
但是音頻采樣率一樣就一定不會出現(xiàn)問題嗎?
5 一個雜音的例子
需要合成的視頻:
https://github.com/JeffMony/JianYing/blob/main/jeffmony_voice.mp4
Duration: 00:00:11.35, start: 0.000000, bitrate: 21123 kb/sStream #0:0(eng): Video: h264 (High) (avc1 / 0x31637661), yuvj420p(pc, bt470bg/bt470bg/smpte170m), 1920x1080, 20341 kb/s, SAR 1:1 DAR 16:9, 30.02 fps, 30 tbr, 90k tbn, 180k tbc (default)Metadata:rotate : 90creation_time : 2021-08-04T07:59:58.000000Zhandler_name : VideoHandlevendor_id : [0][0][0][0]Side data:displaymatrix: rotation of -90.00 degreesStream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 320 kb/s (default)Metadata:creation_time : 2021-08-04T07:59:58.000000Zhandler_name : SoundHandlevendor_id : [0][0][0][0]
需要合成的音頻:
https://github.com/JeffMony/JianYing/blob/main/output.aac
Duration: 00:02:38.18, bitrate: 33 kb/sStream #0:0: Audio: aac (HE-AACv2), 44100 Hz, stereo, fltp, 33 kb/s
如果按照的正常的方式將它們合成:
https://github.com/JeffMony/JianYing/blob/main/output1.mp4
Duration: 00:00:09.99, start: 0.000000, bitrate: 5938 kb/sStream #0:0(und): Video: h264 (Constrained Baseline) (avc1 / 0x31637661), yuv420p, 720x1280, 5814 kb/s, 30.12 fps, 30 tbr, 10k tbn, 60 tbc (default)Metadata:handler_name : VideoHandlervendor_id : [0][0][0][0]Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, mono, fltp, 128 kb/s (default)Metadata:handler_name : SoundHandlervendor_id : [0][0][0][0]
這兒大家可以直接將例子下載下來看看,不好傳視頻和音頻,所以大家將就看吧。
輸入的視頻中的音頻采樣率是48000 Hz,輸入的音頻采樣率是44100 Hz,最后合成后視頻中音頻的采樣率是44100 Hz,看上去實現(xiàn)了重采樣了,但是輸出的視頻雜音非常嚴重,完全無法聽。
這兒就要多問一句了,為什么呢?
6 問題剖析
我們這兒是將音頻統(tǒng)一按照44100 Hz重采樣,然后混音處理。從48000 Hz 重采樣至 44100 Hz,相同的buffer size的大小降低采樣率之后buffer size也會降低,而我們要做混音的時,需要兩個buffer都填充滿,這種情況下有一個音頻的buffer沒有填充滿。
就像下面的示意圖:
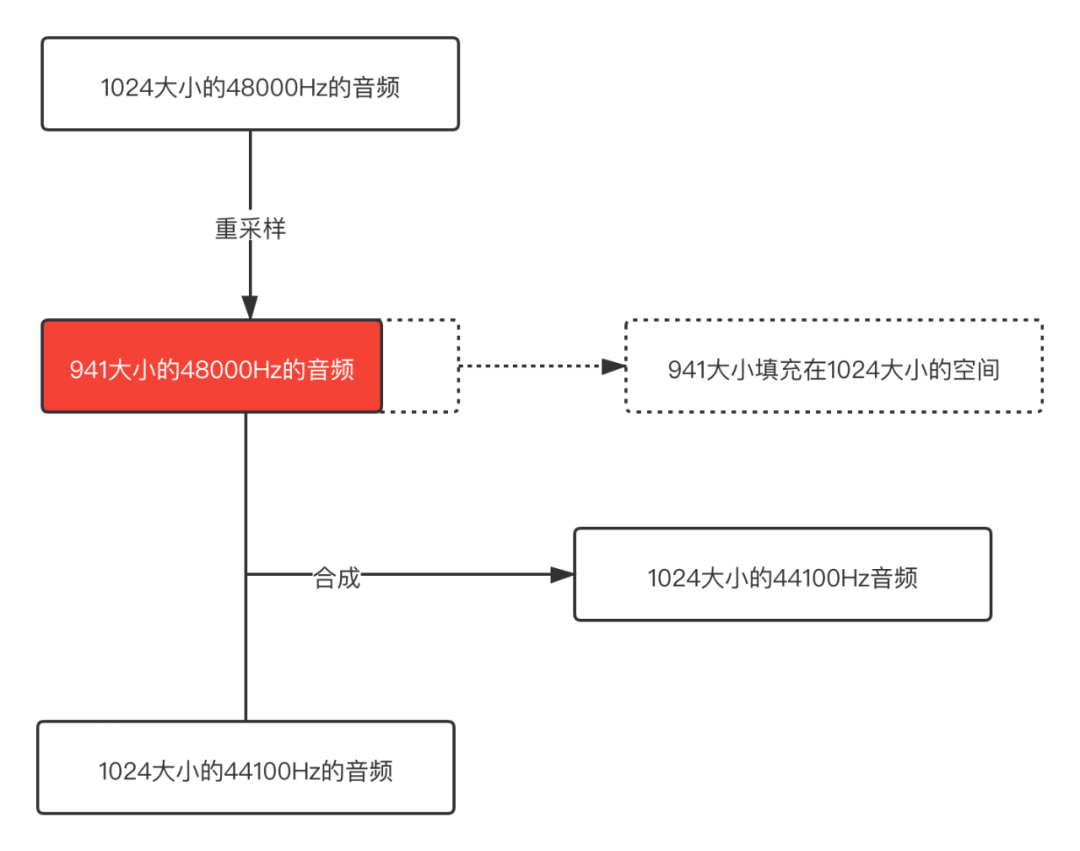
從這個示意圖可以很明顯的看出問題,48000 Hz重采樣之后的音頻buffer size已經(jīng)變小了,但是用這個buffer和44100 Hz正常的buffer合并,那其中一個音頻后面就是一段空數(shù)據(jù),所以合成之后肯定會出現(xiàn)雜音的。
既然知道了是什么問題,那我們可以在合成之前將buffer填充滿,然后再混音處理,這樣就不會出現(xiàn)這個問題了。示意圖如下:
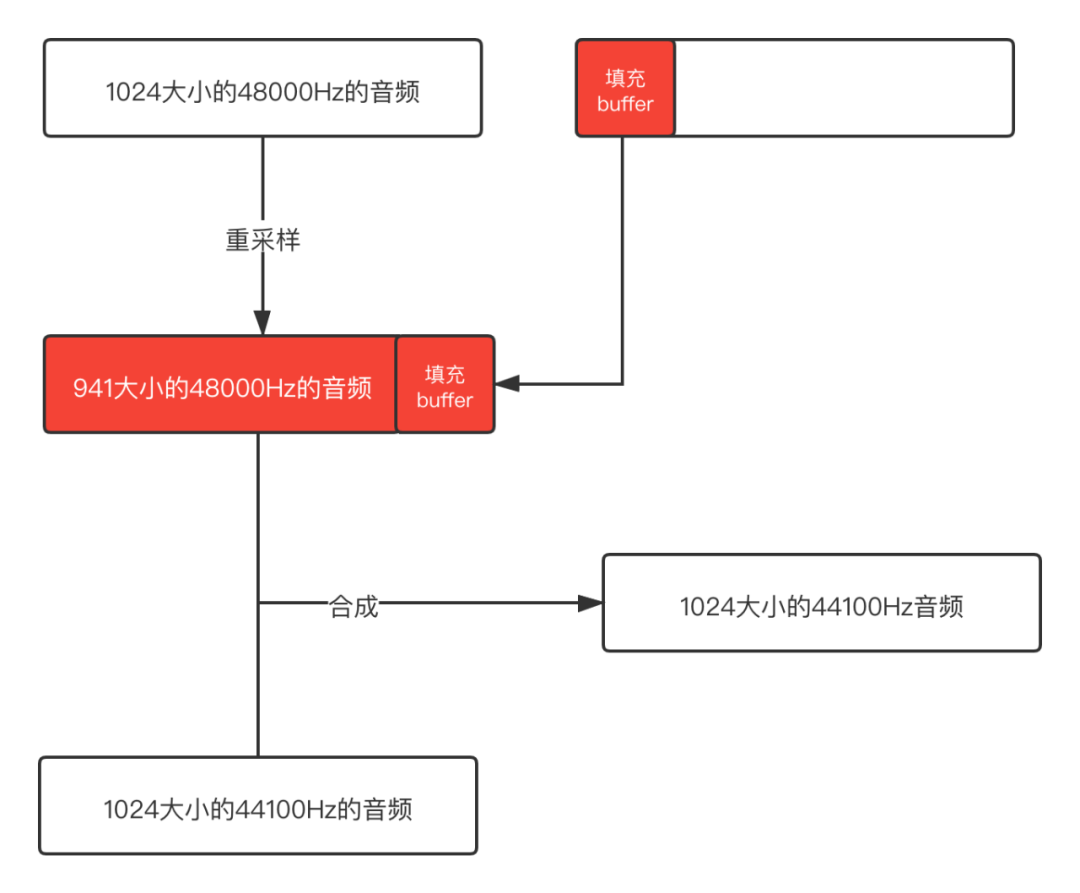
后面依次填充不滿的buffer,這樣得到的就是完整的buffer了,不會有冗余的數(shù)據(jù),混音之后輸出的音頻是正常的。
下面展示一下混音之后正常輸出的文件:
https://github.com/JeffMony/JianYing/blob/main/output3.mp4
7 混音算法介紹
聲音是由于物體的振動對周圍的空氣產(chǎn)生壓力而傳播的一種壓力波,轉(zhuǎn)成電信號后經(jīng)過抽樣,量化,仍然是連續(xù)平滑的波形信號,量化后的波形信號的頻率與聲音的頻率對應,振幅與聲音的音量對應,量化的語音信號的疊加等價于空氣中聲波的疊加,所以當采樣率一致時,混音可以實現(xiàn)為將各對應信號的采樣數(shù)據(jù)線性疊加。反應到音頻數(shù)據(jù)上,也就是把同一個聲道的數(shù)值進行簡單的相加而問題的關(guān)鍵就是如何處理疊加后溢出問題。(通常的語音數(shù)據(jù)為16bit 容納的范圍是有限的 -32768 到 32767之間 所以單純的線性疊加是有可能出現(xiàn)溢出問題的。直接截斷會產(chǎn)生噪音。所以需要平滑過度)
所以在進行混音之前要先保證需要混合的音頻 采樣率、通道數(shù)、采樣精度一樣。
7.1 平均法
將每一路的語音線性相加,再除以通道數(shù),該方法雖然不會引入噪聲,但是隨著通道數(shù)成員的增多,各路語音的衰減將愈加嚴重。具體體現(xiàn)在隨著通道數(shù)成員的增多,各路音量會逐步變小。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音頻長度// 音軌疊加short[] realMixAudio = new short[coloum];int mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])/2;realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.2 歸一化
全部乘個系數(shù)因子,使幅值歸一化,但是個人認為這個歸一化因子是不好確認的。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音頻長度float f = divisor;//歸一化因子// 音軌疊加short[] realMixAudio = new short[coloum];float mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])*f;realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.3 改進后的歸一化
使用可變的衰減因子對語音進行衰減,該衰減因子代表了語音的權(quán)重,該衰減因子隨著數(shù)據(jù)的變化而變化,當數(shù)據(jù)溢出時,則相應的使衰減因子變小,使后續(xù)的數(shù)據(jù)在衰減后處于臨界值以內(nèi),沒有溢出時,讓衰減因子慢慢增大,使數(shù)據(jù)變化相對平滑。
public static short[] mixRawAudioBytes(short[][] inputAudios) {int coloum = finalLength;//最終合成的音頻長度float f = 1;//衰減因子 初始值為1//混音溢出邊界int MAX = 32767;int MIN = -32768;// 音軌疊加short[] realMixAudio = new short[coloum];float mixVal;for (int trackOffset = 0; trackOffset < coloum; ++trackOffset) {mixVal = (inputAudios[0][trackOffset]+inputAudios[1][trackOffset])*f;if (mixVal>MAX){f = MAX/mixVal;mixVal = MAX;}if (mixVal<MIN){f = MIN/mixVal;mixVal = MIN;}if (f < 1){//SETPSIZE為f的變化步長,通常的取值為(1-f)/VALUE,此處取SETPSIZE 為 32 VALUE值可以取 8, 16, 32,64,128.f += (1 - f) / 32;}realMixAudio[trackOffset] = (short) (mixVal);}return realMixAudio;}
7.4 newlc算法
if A < 0 && B < 0
Y = A + B - (A * B / (-(2 pow(n-1) -1)))
else
Y = A + B - (A * B / (2 pow(n-1))
void Mix(char sourseFile[10][SIZE_AUDIO_FRAME],int number,char *objectFile){//歸一化混音int const MAX=32767;int const MIN=-32768;double f=1;int output;int i = 0,j = 0;for (i=0;i<SIZE_AUDIO_FRAME/2;i++){int temp=0;for (j=0;j<number;j++){temp+=*(short*)(sourseFile[j]+i*2);}output=(int)(temp*f);if (output>MAX){f=(double)MAX/(double)(output);output=MAX;}if (output<MIN){f=(double)MIN/(double)(output);output=MIN;}if (f<1){f+=((double)1-f)/(double)32;}*(short*)(objectFile+i*2)=(short)output;}}
參考文章:
https://www.git2get.com/av/104606126.html
https://blog.csdn.net/dxpqxb/article/details/78329403