
關(guān)于構(gòu)建與優(yōu)化數(shù)據(jù)倉庫架構(gòu)與模型設(shè)計
技術(shù)架構(gòu)選型 數(shù)倉分層 數(shù)據(jù)模型 層次調(diào)用規(guī)范
https://help.aliyun.com/document_detail/154238.html
技術(shù)架構(gòu)選型
教程本身是以阿里云 MaxCompute 為例,實際上,流程和方法論是通用的。
在數(shù)據(jù)模型設(shè)計之前,需要首先完成技術(shù)架構(gòu)的選型。本教程中使用阿里云大數(shù)據(jù)產(chǎn)品MaxCompute配合DataWorks,完成整體的數(shù)據(jù)建模和研發(fā)流程。實際的方法論可以完全應(yīng)用于阿里云Dataphin。

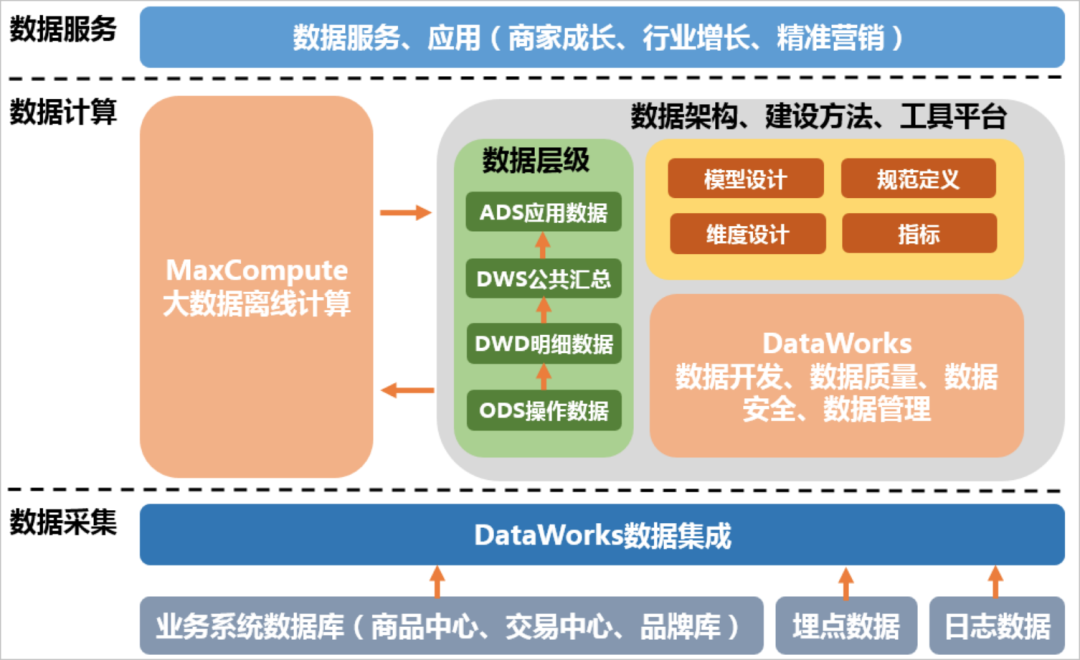
完整的技術(shù)架構(gòu)圖如下圖所示。
其中,DataWorks的數(shù)據(jù)集成負(fù)責(zé)完成數(shù)據(jù)的采集和基本的ETL【可以基于開源的相關(guān)技術(shù)組件構(gòu)建數(shù)據(jù)采集和ETL基礎(chǔ)平臺】。MaxCompute作為整個大數(shù)據(jù)開發(fā)過程中的離線計算引擎。DataWorks則包括數(shù)據(jù)開發(fā)、數(shù)據(jù)質(zhì)量、數(shù)據(jù)安全、數(shù)據(jù)管理等在內(nèi)的一系列功能。
數(shù)倉分層
在阿里巴巴的數(shù)據(jù)體系中,我們建議將數(shù)據(jù)倉庫分為三層,自下而上為:數(shù)據(jù)引入層(ODS,Operation Data Store)、數(shù)據(jù)公共層(CDM,Common Data Model)和數(shù)據(jù)應(yīng)用層(ADS,Application Data Service)。
數(shù)據(jù)倉庫的分層和各層級用途如下圖所示。

數(shù)據(jù)引入層ODS(Operation Data Store):存放未經(jīng)過處理的原始數(shù)據(jù)至數(shù)據(jù)倉庫系統(tǒng),結(jié)構(gòu)上與源系統(tǒng)保持一致,是 數(shù)據(jù)倉庫的數(shù)據(jù)準(zhǔn)備區(qū)。主要完成基礎(chǔ)數(shù)據(jù)引入到MaxCompute的職責(zé),同時記錄基礎(chǔ)數(shù)據(jù)的歷史變化。數(shù)據(jù)公共層CDM(Common Data Model,又稱通用數(shù)據(jù)模型層),包括 DIM維度表、DWD和DWS,由ODS層數(shù)據(jù)加工而成。主要完成數(shù)據(jù)加工與整合,建立一致性的維度,構(gòu)建可復(fù)用的面向分析和統(tǒng)計的明細(xì)事實表,以及匯總公共粒度的指標(biāo)。
公共維度層(DIM):基于維度建模理念思想,建立整個企業(yè)的一致性維度。降低數(shù)據(jù)計算口徑和算法不統(tǒng)一風(fēng)險。公共維度層的表通常也被稱為邏輯維度表,維度和維度邏輯表通常一一對應(yīng)。
公共匯總粒度事實層(DWS):以分析的主題對象作為建模驅(qū)動,基于上層的應(yīng)用和產(chǎn)品的指標(biāo)需求,構(gòu)建公共粒度的匯總指標(biāo)事實表,以寬表化手段物理化模型。構(gòu)建命名規(guī)范、口徑一致的統(tǒng)計指標(biāo),為上層提供公共指標(biāo),建立匯總寬表、明細(xì)事實表。
公共匯總粒度事實層的表通常也被稱為匯總邏輯表,用于存放派生指標(biāo)數(shù)據(jù)。明細(xì)粒度事實層(DWD):以業(yè)務(wù)過程作為建模驅(qū)動,基于每個具體的業(yè)務(wù)過程特點,構(gòu)建最細(xì)粒度的明細(xì)層事實表。可以結(jié)合企業(yè)的數(shù)據(jù)使用特點,將明細(xì)事實表的某些重要維度屬性字段做適當(dāng)冗余,即寬表化處理。明細(xì)粒度事實層的表通常也被稱為邏輯事實表。
數(shù)據(jù)應(yīng)用層ADS(Application Data Service):存放數(shù)據(jù)產(chǎn)品個性化的統(tǒng)計指標(biāo)數(shù)據(jù)。根據(jù)CDM與ODS層加工生成。
該數(shù)據(jù)分類架構(gòu)在ODS層分為三部分:數(shù)據(jù)準(zhǔn)備區(qū)、離線數(shù)據(jù)和準(zhǔn)實時數(shù)據(jù)區(qū)。整體數(shù)據(jù)分類架構(gòu)如下圖所示。
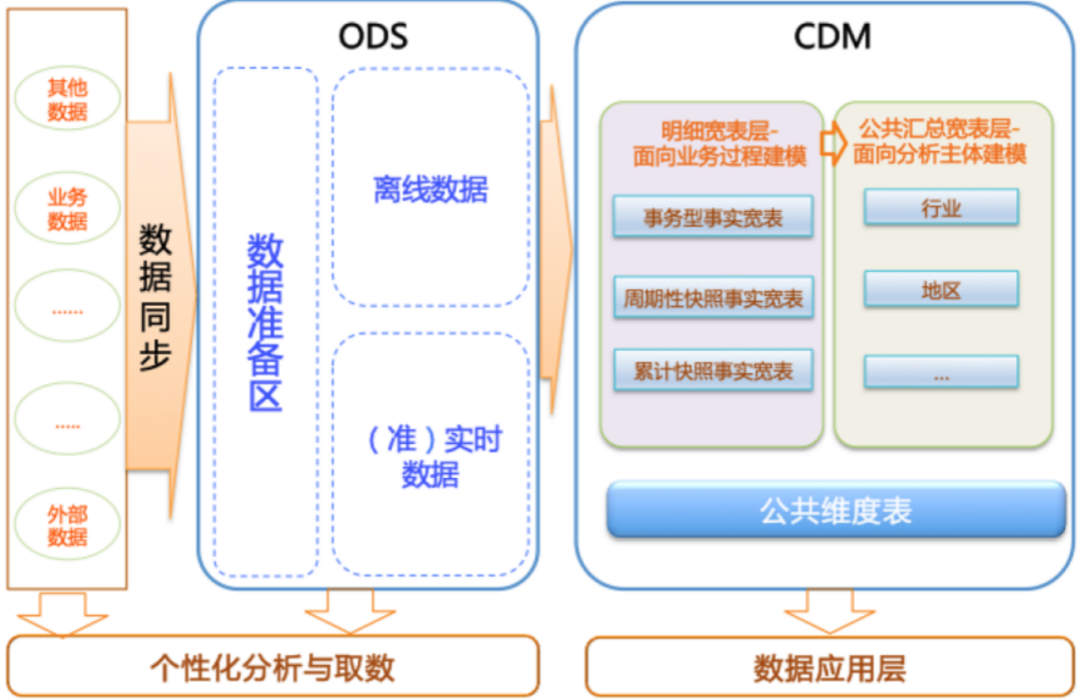
在本教程中,從交易數(shù)據(jù)系統(tǒng)的數(shù)據(jù)經(jīng)過DataWorks數(shù)據(jù)集成,同步到數(shù)據(jù)倉庫的ODS層。經(jīng)過數(shù)據(jù)開發(fā)形成事實寬表后,再以商品、地域等為維度進(jìn)行公共匯總。
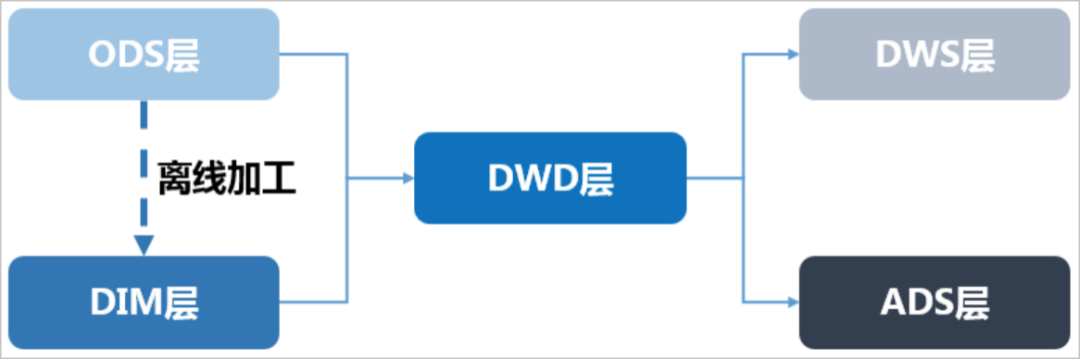
整體的數(shù)據(jù)流向如下圖所示。其中,ODS層到DIM層的ETL(萃取(Extract)、轉(zhuǎn)置(Transform)及加載(Load))處理是在MaxCompute中進(jìn)行的,處理完成后會同步到所有存儲系統(tǒng)。
ODS層和DWD層會放在數(shù)據(jù)中間件中,供下游訂閱使用。而DWS層和ADS層的數(shù)據(jù)通常會落地到在線存儲系統(tǒng)中,下游通過接口調(diào)用的形式使用。
數(shù)據(jù)模型
1. 數(shù)據(jù)引入層(ODS)
ODS層存放您從業(yè)務(wù)系統(tǒng)獲取的最原始的數(shù)據(jù),是其他上層數(shù)據(jù)的源數(shù)據(jù)。業(yè)務(wù)數(shù)據(jù)系統(tǒng)中的數(shù)據(jù)通常為非常細(xì)節(jié)的數(shù)據(jù),經(jīng)過長時間累積,且訪問頻率很高,是面向應(yīng)用的數(shù)據(jù)。
數(shù)據(jù)引入層表設(shè)計
本教程中,在ODS層主要包括的數(shù)據(jù)有:交易系統(tǒng)訂單詳情、用戶信息詳情、商品詳情等。這些數(shù)據(jù)未經(jīng)處理,是最原始的數(shù)據(jù)。邏輯上,這些數(shù)據(jù)都是以二維表的形式存儲。雖然嚴(yán)格的說ODS層不屬于數(shù)倉建模的范疇,但是合理的規(guī)劃ODS層并做好數(shù)據(jù)同步也非常重要。
教程中,使用了6張ODS表:
記錄用于拍賣的商品信息:s_auction。
記錄用于正常售賣的商品信息:s_sale。
記錄用戶詳細(xì)信息:s_users_extra。
記錄新增的商品成交訂單信息:s_biz_order_delta。
記錄新增的物流訂單信息:s_logistics_order_delta。
記錄新增的支付訂單信息:s_pay_order_delta。
說明:
通過_delta來標(biāo)識該表為增量表。
表中某些字段的名稱剛好和關(guān)鍵字重名了,可以通過添加_col1后綴解決。
建表示例(s_auction)
CREATE TABLE IF NOT EXISTS s_auction
(
id STRING COMMENT '商品ID',
title STRING COMMENT '商品名',
gmt_modified STRING COMMENT '商品最后修改日期',
price DOUBLE COMMENT '商品成交價格,單位元',
starts STRING COMMENT '商品上架時間',
minimum_bid DOUBLE COMMENT '拍賣商品起拍價,單位元',
duration STRING COMMENT '有效期,銷售周期,單位天',
incrementnum DOUBLE COMMENT '拍賣價格的增價幅度',
city STRING COMMENT '商品所在城市',
prov STRING COMMENT '商品所在省份',
ends STRING COMMENT '銷售結(jié)束時間',
quantity BIGINT COMMENT '數(shù)量',
stuff_status BIGINT COMMENT '商品新舊程度 0 全新 1 閑置 2 二手',
auction_status BIGINT COMMENT '商品狀態(tài) 0 正常 1 用戶刪除 2 下架 3 從未上架',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
commodity_id BIGINT COMMENT '品類ID',
commodity_name STRING COMMENT '品類名稱',
umid STRING COMMENT '買家umid'
)
COMMENT '商品拍賣ODS'
PARTITIONED BY (ds STRING COMMENT '格式:YYYYMMDD')
LIFECYCLE 400;數(shù)據(jù)引入層存儲
為了滿足歷史數(shù)據(jù)分析需求,您可以在ODS層表中添加時間維度作為分區(qū)字段。實際應(yīng)用中,您可以選擇采用增量、全量存儲或拉鏈存儲的方式。
增量存儲
以天為單位的增量存儲,以業(yè)務(wù)日期作為分區(qū),每個分區(qū)存放日增量的業(yè)務(wù)數(shù)據(jù)。舉例如下:
1月1日,用戶A訪問了A公司電商店鋪B,A公司電商日志產(chǎn)生一條記錄t1。1月2日,用戶A又訪問了A公司電商店鋪C,A公司電商日志產(chǎn)生一條記錄t2。采用增量存儲方式,t1將存儲在1月1日這個分區(qū)中,t2將存儲在1月2日這個分區(qū)中。
1月1日,用戶A在A公司電商網(wǎng)購買了B商品,交易日志將生成一條記錄t1。1月2日,用戶A又將B商品退貨了,交易日志將更新t1記錄。采用增量存儲方式,初始購買的t1記錄將存儲在1月1日這個分區(qū)中,更新后的t1將存儲在1月2日這個分區(qū)中。
交易、日志等
事務(wù)性較強的ODS表適合增量存儲方式。這類表數(shù)據(jù)量較大,采用全量存儲的方式存儲成本壓力大。此外,這類表的下游應(yīng)用對于歷史全量數(shù)據(jù)訪問的需求較小(此類需求可通過數(shù)據(jù)倉庫后續(xù)匯總后得到)。例如,日志類ODS表沒有數(shù)據(jù)更新的業(yè)務(wù)過程,因此所有增量分區(qū)UNION在一起就是一份全量數(shù)據(jù)。
全量存儲
以天為單位的全量存儲,以業(yè)務(wù)日期作為分區(qū),每個分區(qū)存放截止到業(yè)務(wù)日期為止的全量業(yè)務(wù)數(shù)據(jù)。
例如,1月1日,賣家A在A公司電商網(wǎng)發(fā)布了B、C兩個商品,前端商品表將生成兩條記錄t1、t2。1月2日,賣家A將B商品下架了,同時又發(fā)布了商品D,前端商品表將更新記錄t1,同時新生成記錄t3。采用全量存儲方式, 在1月1日這個分區(qū)中存儲t1和t2兩條記錄,在1月2日這個分區(qū)中存儲更新后的t1以及t2、t3記錄。
對于小數(shù)據(jù)量的緩慢變化維度數(shù)據(jù),例如商品類目,可直接使用全量存儲。
拉鏈存儲 拉鏈存儲通過 新增兩個時間戳字段(start_dt和end_dt),將所有以天為粒度的變更數(shù)據(jù)都記錄下來,通常分區(qū)字段也是這兩個時間戳字段。
拉鏈存儲舉例如下。
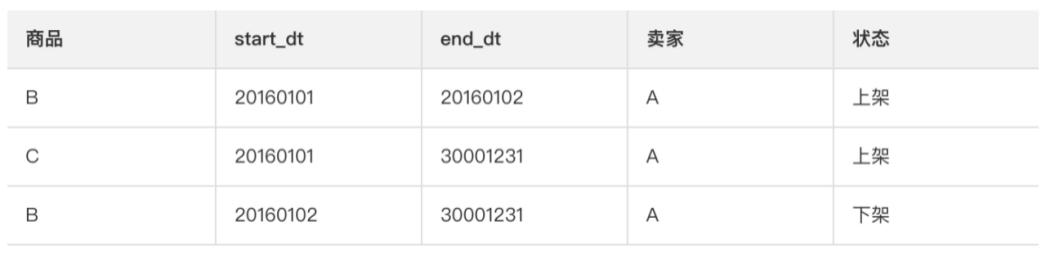
這樣,下游應(yīng)用可以通過限制時間戳字段來獲取歷史數(shù)據(jù)。例如,用戶訪問1月1日數(shù)據(jù),只需限制start_dt<=20160101并且 end_dt>20160101。
緩慢變化維度
MaxCompute不推薦使用代理鍵,推薦使用自然鍵作為維度主鍵,主要原因有兩點:
MaxCompute是分布式計算引擎,生成全局唯一的代理鍵工作量非常大。當(dāng)遇到大數(shù)據(jù)量情況下,這項工作就會更加復(fù)雜,且沒有必要。 使用代理鍵會增加ETL的復(fù)雜性,從而增加ETL任務(wù)的開發(fā)和維護(hù)成本。
在不使用代理鍵的情況下,緩慢變化維度可以通過快照方式處理。
快照方式下數(shù)據(jù)的計算周期通常為每天一次。基于該周期,處理維度變化的方式為每天一份全量快照。
例如商品維度,每天保留一份全量商品快照數(shù)據(jù)。任意一天的事實表均可以取到當(dāng)天的商品信息,也可以取到最新的商品信息,通過限定日期,采用自然鍵進(jìn)行關(guān)聯(lián)即可。該方式的優(yōu)勢主要有以下兩點:
處理緩慢變化維度的方式簡單有效,開發(fā)和維護(hù)成本低。 使用方便,易于理解。數(shù)據(jù)使用方只需要限定日期即可取到當(dāng)天的快照數(shù)據(jù)。任意一天的事實快照與任意一天的維度快照通過維度的自然鍵進(jìn)行關(guān)聯(lián)即可。
該方法的弊端主要是存儲空間的極大浪費。例如某維度每天的變化量占總體數(shù)據(jù)量比例很低,極端情況下,每天無變化,這種情況下存儲浪費嚴(yán)重。
該方法主要實現(xiàn)了通過犧牲存儲獲取ETL效率的優(yōu)化和邏輯上的簡化。請避免過度使用該方法,且必須要有對應(yīng)的數(shù)據(jù)生命周期制度,清除無用的歷史數(shù)據(jù)。
數(shù)據(jù)同步加載與處理
ODS的數(shù)據(jù)需要由各數(shù)據(jù)源系統(tǒng)同步到MaxCompute,才能用于進(jìn)一步的數(shù)據(jù)開發(fā)。本教程建議您使用DataWorks數(shù)據(jù)集成功能完成數(shù)據(jù)同步。在使用數(shù)據(jù)集成的過程中,建議您遵循以下規(guī)范:
一個系統(tǒng)的源表只允許同步到MaxCompute一次,保持表結(jié)構(gòu)的一致性。 數(shù)據(jù)集成僅用于離線全量數(shù)據(jù)同步,實時增量數(shù)據(jù)同步需要您使用數(shù)據(jù)傳輸服務(wù)DTS實現(xiàn),詳情請參見數(shù)據(jù)傳輸服務(wù)DTS。 數(shù)據(jù)集成全量同步的數(shù)據(jù)直接進(jìn)入全量表的當(dāng)日分區(qū)。 ODS層的表建議以統(tǒng)計日期及時間分區(qū)表的方式存儲,便于管理數(shù)據(jù)的存儲成本和策略控制。 數(shù)據(jù)集成可以自適應(yīng)處理源系統(tǒng)字段的變更: 如果源系統(tǒng)字段的目標(biāo)表在MaxCompute上不存在,可以由數(shù)據(jù)集成自動添加不存在的表字段。 如果目標(biāo)表的字段在源系統(tǒng)不存在,數(shù)據(jù)集成填充NULL。
2. 公共維度匯總層(DIM)
公共維度匯總層(DIM)基于維度建模理念,建立整個企業(yè)的一致性維度。
公共維度匯總層(DIM)主要由維度表(維表)構(gòu)成。維度是邏輯概念,是衡量和觀察業(yè)務(wù)的角度。維表是根據(jù)維度及其屬性將數(shù)據(jù)平臺上構(gòu)建的表物理化的表,采用寬表設(shè)計的原則。因此,構(gòu)建公共維度匯總層(DIM)首先需要定義維度。
定義維度
在劃分數(shù)據(jù)域、構(gòu)建總線矩陣時,需要結(jié)合對業(yè)務(wù)過程的分析定義維度。以本教程中A電商公司的營銷業(yè)務(wù)板塊為例,在交易數(shù)據(jù)域中,我們重點考察確認(rèn)收貨(交易成功)的業(yè)務(wù)過程。
在確認(rèn)收貨的業(yè)務(wù)過程中,主要有商品和收貨地點(本教程中,假設(shè)收貨和購買是同一個地點)兩個維度所依賴的業(yè)務(wù)角度。
從商品角度可以定義出以下維度:
商品ID
商品名稱
商品價格
商品新舊程度:0-全新、1-閑置、 2-二手
商品類目ID
商品類目名稱
品類ID
品類名稱
買家ID
商品狀態(tài):0-正常、1-用戶刪除、2-下架、3-從未上架
商品所在城市
商品所在省份
從地域角度,可以定義出以下維度:
買家ID
城市code
城市名稱
省份code
省份名稱
作為維度建模的核心,在企業(yè)級數(shù)據(jù)倉庫中必須保證維度的唯一性。以A公司的商品維度為例,有且只允許有一種維度定義。例如,省份code這個維度,對于任何業(yè)務(wù)過程所傳達(dá)的信息都是一致的。
設(shè)計維表
完成維度定義后,您就可以對維度進(jìn)行補充,進(jìn)而生成維表了。
維表的設(shè)計需要注意:
建議維表 單表信息不超過1000萬條。維表與其他表進(jìn)行Join時,建議 使用Map Join。避免過于頻繁的更新維表的數(shù)據(jù)。
在設(shè)計維表時,您需要從下列方面進(jìn)行考慮:
維表中數(shù)據(jù)的穩(wěn)定性。例如A公司電商會員通常不會出現(xiàn)消亡,但會員數(shù)據(jù)可能在任何時候更新,此時要考慮創(chuàng)建單個分區(qū)存儲全量數(shù)據(jù)。如果存在不會更新的記錄,您可能需要 分別創(chuàng)建歷史表與日常表。日常表用于存放當(dāng)前有效的記錄,保持表的數(shù)據(jù)量不會膨脹;歷史表根據(jù)消亡時間插入對應(yīng)分區(qū),使用單個分區(qū)存放分區(qū)對應(yīng)時間的消亡記錄。是否需要垂直拆分。如果一個維表存在大量屬性不被使用,或由于承載過多屬性字段導(dǎo)致查詢變慢,則需考慮對字段進(jìn)行拆分,創(chuàng)建多個維表。 是否需要水平拆分。如果記錄之間有明顯的界限,可以考慮拆成多個表或設(shè)計成多級分區(qū)。 核心的維表產(chǎn)出時間通常有嚴(yán)格的要求。
設(shè)計維表的主要步驟如下:
完成維度的初步定義,并保證維度的一致性。 確定主維表(中心事實表,教程中采用 星型模型)。此處的主維表通常是數(shù)據(jù)引入層(ODS)表,直接與業(yè)務(wù)系統(tǒng)同步。例如,s_auction是與前臺商品中心系統(tǒng)同步的商品表,此表即是主維表。確定相關(guān)維表。數(shù)據(jù)倉庫是業(yè)務(wù)源系統(tǒng)的數(shù)據(jù)整合,不同業(yè)務(wù)系統(tǒng)或者同一業(yè)務(wù)系統(tǒng)中的表之間存在關(guān)聯(lián)性。根據(jù)對業(yè)務(wù)的梳理,確定哪些表和主維表存在關(guān)聯(lián)關(guān)系,并選擇其中的某些表用于生成維度屬性。以商品維度為例,根據(jù)對業(yè)務(wù)邏輯的梳理,可以得到商品與類目、賣家、店鋪等維度存在關(guān)聯(lián)關(guān)系。 確定維度屬性,主要包括兩個階段。第一個階段是從主維表中選擇維度屬性或生成新的維度屬性;第二個階段是從相關(guān)維表中選擇維度屬性或生成新的維度屬性。以商品維度為例,從主維表(s_auction)和類目 、賣家、店鋪等相關(guān)維表中選擇維度屬性或生成新的維度屬性。 盡可能生成豐富的維度屬性。 盡可能多地給出富有意義的文字性描述。 區(qū)分?jǐn)?shù)值型屬性和事實。 盡量沉淀出通用的維度屬性。
公共維度匯總層(DIM)維表規(guī)范
公共維度匯總層(DIM)維表命名規(guī)范:dim_{業(yè)務(wù)板塊名稱/pub}_{維度定義}[_{自定義命名標(biāo)簽}],所謂pub是與具體業(yè)務(wù)板塊無關(guān)或各個業(yè)務(wù)板塊都可公用的維度,如時間維度。
舉例如下:
公共區(qū)域維表dim_pub_area A公司電商板塊的商品全量表dim_asale_itm
建表示例
CREATE TABLE IF NOT EXISTS dim_asale_itm
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名稱',
item_price DOUBLE COMMENT '商品成交價格_元',
item_stuff_status BIGINT COMMENT '商品新舊程度_0全新1閑置2二手',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
commodity_id BIGINT COMMENT '品類ID',
commodity_name STRING COMMENT '品類名稱',
umid STRING COMMENT '買家ID',
item_status BIGINT COMMENT '商品狀態(tài)_0正常1用戶刪除2下架3未上架',
city STRING COMMENT '商品所在城市',
prov STRING COMMENT '商品所在省份'
)
COMMENT '商品全量表'
PARTITIONED BY (ds STRING COMMENT '日期,yyyymmdd');
CREATE TABLE IF NOT EXISTS dim_pub_area
(
buyer_id STRING COMMENT '買家ID',
city_code STRING COMMENT '城市code',
city_name STRING COMMENT '城市名稱',
prov_code STRING COMMENT '省份code',
prov_name STRING COMMENT '省份名稱'
)
COMMENT '公共區(qū)域維表'
PARTITIONED BY (ds STRING COMMENT '日期分區(qū),格式y(tǒng)yyymmdd')
LIFECYCLE 3600;3. 明細(xì)粒度事實層(DWD)
明細(xì)粒度事實層以業(yè)務(wù)過程驅(qū)動建模,基于每個具體的業(yè)務(wù)過程特點,構(gòu)建最細(xì)粒度的明細(xì)層事實表。您可以結(jié)合企業(yè)的數(shù)據(jù)使用特點,將明細(xì)事實表的某些重要維度屬性字段做適當(dāng)冗余,即寬表化處理。
公共匯總粒度事實層(DWS)和明細(xì)粒度事實層(DWD)的事實表作為數(shù)據(jù)倉庫維度建模的核心,需緊繞業(yè)務(wù)過程來設(shè)計。通過獲取描述業(yè)務(wù)過程的度量來描述業(yè)務(wù)過程,包括引用的維度和與業(yè)務(wù)過程有關(guān)的度量。度量通常為數(shù)值型數(shù)據(jù),作為事實邏輯表的依據(jù)。事實邏輯表的描述信息是事實屬性,事實屬性中的外鍵字段通過對應(yīng)維度進(jìn)行關(guān)聯(lián)。
事實表中一條記錄所表達(dá)的業(yè)務(wù)細(xì)節(jié)程度被稱為粒度。通常粒度可以通過兩種方式來表述:一種是維度屬性組合所表示的細(xì)節(jié)程度,一種是所表示的具體業(yè)務(wù)含義。
作為度量業(yè)務(wù)過程的事實,通常為整型或浮點型的十進(jìn)制數(shù)值,有可加性、半可加性和不可加性三種類型:
可加性事實是指可以按照與事實表關(guān)聯(lián)的任意維度進(jìn)行匯總。 半可加性事實只能按照特定維度匯總,不能對所有維度匯總。例如庫存可以按照地點和商品進(jìn)行匯總,而按時間維度把一年中每個月的庫存累加則毫無意義。 完全不可加性,例如比率型事實。對于不可加性的事實,可分解為可加的組件來實現(xiàn)聚集。
事實表相對維表通常更加細(xì)長,行增加速度也更快。維度屬性可以存儲到事實表中,這種存儲到事實表中的維度列稱為維度退化,可加快查詢速度。與其他存儲在維表中的維度一樣,維度退化可以用來進(jìn)行事實表的過濾查詢、實現(xiàn)聚合操作等。
明細(xì)粒度事實層(DWD)通常分為三種:事務(wù)事實表、周期快照事實表和累積快照事實表,詳情請參見數(shù)倉建設(shè)指南。

事務(wù)事實表用來描述業(yè)務(wù)過程,跟蹤空間或時間上某點的度量事件,保存的是最原子的數(shù)據(jù),也稱為原子事實表。 周期快照事實表以具有規(guī)律性的、可預(yù)見的時間間隔記錄事實。 累積快照事實表用來表述過程開始和結(jié)束之間的關(guān)鍵步驟事件,覆蓋過程的整個生命周期,通常具有多個日期字段來記錄關(guān)鍵時間點。當(dāng)累積快照事實表隨著生命周期不斷變化時,記錄也會隨著過程的變化而被修改。
明細(xì)粒度事實表設(shè)計原則
明細(xì)粒度事實表設(shè)計原則如下所示:
通常,一個明細(xì)粒度事實表僅和一個維度關(guān)聯(lián)。 盡可能包含所有與業(yè)務(wù)過程相關(guān)的事實 。 只選擇與業(yè)務(wù)過程相關(guān)的事實。 分解不可加性事實為可加的組件。 在選擇維度和事實之前必須先聲明粒度。 在同一個事實表中不能有多種不同粒度的事實。 事實的單位要保持一致。 謹(jǐn)慎處理Null值。 使用退化維度提高事實表的易用性。 明細(xì)粒度事實表整體設(shè)計流程如下圖所示。

在一致性度量中已定義好了交易業(yè)務(wù)過程及其度量。明細(xì)事實表注意針對業(yè)務(wù)過程進(jìn)行模型設(shè)計。明細(xì)事實表的設(shè)計可以分為四個步驟:
選擇業(yè)務(wù)過程、確定粒度、選擇維度、確定事實(度量)。粒度主要是在維度未展開的情況下記錄業(yè)務(wù)活動的語義描述。在您建設(shè)明細(xì)事實表時,需要選擇基于現(xiàn)有的表進(jìn)行明細(xì)層數(shù)據(jù)的開發(fā),清楚所建表記錄存儲的是什么粒度的數(shù)據(jù)。
明細(xì)粒度事實層(DWD)規(guī)范
通常您需要遵照的命名規(guī)范為:dwd_{業(yè)務(wù)板塊/pub}_{數(shù)據(jù)域縮寫}_{業(yè)務(wù)過程縮寫}[_{自定義表命名標(biāo)簽縮寫}] _{單分區(qū)增量全量標(biāo)識},pub表示數(shù)據(jù)包括多個業(yè)務(wù)板塊的數(shù)據(jù)。單分區(qū)增量全量標(biāo)識通常為:i表示增量,f表示全量。例如:dwd_asale_trd_ordcrt_trip_di(A電商公司航旅機票訂單下單事實表,日刷新增量)及dwd_asale_itm_item_df(A電商商品快照事實表,日刷新全量)。
本教程中,DWD層主要由三個表構(gòu)成:
交易商品信息事實表:dwd_asale_trd_itm_di。
交易會員信息事實表:ods_asale_trd_mbr_di。
交易訂單信息事實表:dwd_asale_trd_ord_di。
建表示例(dwd_asale_trd_itm_di)
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名稱',
item_price DOUBLE COMMENT '商品價格',
item_stuff_status BIGINT COMMENT '商品新舊程度_0全新1閑置2二手',
item_prov STRING COMMENT '商品省份',
item_city STRING COMMENT '商品城市',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
commodity_id BIGINT COMMENT '品類ID',
commodity_name STRING COMMENT '品類名稱',
buyer_id BIGINT COMMENT '買家ID',
)
COMMENT '交易商品信息事實表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;4. 公共匯總粒度事實層(DWS)
明細(xì)粒度 ==> 匯總粒度
公共匯總粒度事實層以分析的主題對象作為建模驅(qū)動,基于上層的應(yīng)用和產(chǎn)品的指標(biāo)需求構(gòu)建公共粒度的匯總指標(biāo)事實表。公共匯總層的一個表通常會對應(yīng)一個派生指標(biāo)。
公共匯總事實表設(shè)計原則
聚集是指針對原始明細(xì)粒度的數(shù)據(jù)進(jìn)行匯總。DWS公共匯總層是面向分析對象的主題聚集建模。在本教程中,最終的分析目標(biāo)為:最近一天某個類目(例如:廚具)商品在各省的銷售總額、該類目Top10銷售額商品名稱、各省用戶購買力分布。因此,我們可以以最終交易成功的商品、類目、買家等角度對最近一天的數(shù)據(jù)進(jìn)行匯總。
聚集是不跨越事實的。聚集是針對原始星形模型進(jìn)行的匯總。為獲取和查詢與原始模型一致的結(jié)果,聚集的維度和度量必須與原始模型保持一致,因此聚集是不跨越事實的。 聚集會帶來查詢性能的提升,但聚集也會增加ETL維護(hù)的難度。當(dāng)子類目對應(yīng)的一級類目發(fā)生變更時,先前存在的、已經(jīng)被匯總到聚集表中的數(shù)據(jù)需要被重新調(diào)整。
此外,進(jìn)行DWS層設(shè)計時還需遵循以下原則:
數(shù)據(jù)公用性: 需考慮匯總的聚集是否可以提供給第三方使用。您可以判斷,基于某個維度的聚集是否經(jīng)常用于數(shù)據(jù)分析中。如果答案是肯定的,就有必要把明細(xì)數(shù)據(jù)經(jīng)過匯總沉淀到聚集表中。 不跨數(shù)據(jù)域: 數(shù)據(jù)域是在較高層次上對數(shù)據(jù)進(jìn)行分類聚集的抽象。數(shù)據(jù)域通常以業(yè)務(wù)過程進(jìn)行分類,例如交易統(tǒng)一劃到交易域下,商品的新增、修改放到商品域下。 區(qū)分統(tǒng)計周期: 在表的命名上要能說明數(shù)據(jù)的統(tǒng)計周期,例如 _1d表示最近1天,td表示截至當(dāng)天,nd表示最近N天。
公共匯總事實表規(guī)范
公共匯總事實表命名規(guī)范:dws_{業(yè)務(wù)板塊縮寫/pub}_{數(shù)據(jù)域縮寫}_{數(shù)據(jù)粒度縮寫}[_{自定義表命名標(biāo)簽縮寫}]_{統(tǒng)計時間周期范圍縮寫}。關(guān)于統(tǒng)計實際周期范圍縮寫,缺省情況下,離線計算應(yīng)該包括最近一天(_1d),最近N天(_nd)和歷史截至當(dāng)天(_td)三個表。
如果出現(xiàn)_nd的表字段過多需要拆分時,只允許以一個統(tǒng)計周期單元作為原子拆分。即一個統(tǒng)計周期拆分一個表,例如最近7天(_1w)拆分一個表。不允許拆分出來的一個表存儲多個統(tǒng)計周期。
對于小時表(無論是天刷新還是小時刷新),都用_hh來表示。對于分鐘表(無論是天刷新還是小時刷新),都用_mm來表示。
舉例如下:dws_asale_trd_byr_subpay_1d(A電商公司買家粒度交易分階段付款一日匯總事實表)
dws_asale_trd_byr_subpay_td(A電商公司買家粒度分階段付款截至當(dāng)日匯總表)
dws_asale_trd_byr_cod_nd(A電商公司買家粒度貨到付款交易匯總事實表)
dws_asale_itm_slr_td(A電商公司賣家粒度商品截至當(dāng)日存量匯總表)
dws_asale_itm_slr_hh(A電商公司賣家粒度商品小時匯總表)---維度為小時
dws_asale_itm_slr_mm(A電商公司賣家粒度商品分鐘匯總表)---維度為分鐘
建表示例
滿足業(yè)務(wù)需求的DWS層建表語句如下
CREATE TABLE IF NOT EXISTS dws_asale_trd_byr_ord_1d
(
buyer_id BIGINT COMMENT '買家ID',
buyer_nick STRING COMMENT '買家昵稱',
mord_prov STRING COMMENT '收貨人省份',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天訂單已經(jīng)確認(rèn)收貨的金額總和'
)
COMMENT '買家粒度所有交易最近一天匯總事實表'
PARTITIONED BY (ds STRING COMMENT '分區(qū)字段YYYYMMDD')
LIFECYCLE 36000;
CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名稱',
cate_id BIGINT COMMENT '商品類目ID',
cate_name STRING COMMENT '商品類目名稱',
mord_prov STRING COMMENT '收貨人省份',
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天訂單已經(jīng)確認(rèn)收貨的金額總和'
)
COMMENT '商品粒度交易最近一天匯總事實表'
PARTITIONED BY (ds STRING COMMENT '分區(qū)字段YYYYMMDD')
LIFECYCLE 36000;層次調(diào)用規(guī)范
在完成數(shù)據(jù)倉庫的分層后,您需要對各層次的數(shù)據(jù)之間的調(diào)用關(guān)系作出約定。
ADS應(yīng)用層優(yōu)先調(diào)用數(shù)據(jù)倉庫公共層數(shù)據(jù)。如果已經(jīng)存在CDM層數(shù)據(jù),不允許ADS應(yīng)用層跨過CDM中間層從ODS層重復(fù)加工數(shù)據(jù)。CDM中間層應(yīng)該積極了解應(yīng)用層數(shù)據(jù)的建設(shè)需求,將公用的數(shù)據(jù)沉淀到公共層,為其他數(shù)據(jù)層次提供數(shù)據(jù)服務(wù)。同時,ADS應(yīng)用層也需積極配合CDM中間層進(jìn)行持續(xù)的數(shù)據(jù)公共建設(shè)的改造。避免出現(xiàn)過度的ODS層引用、不合理的數(shù)據(jù)復(fù)制和子集合冗余。總體遵循的層次調(diào)用原則如下:
ODS層數(shù)據(jù)不能直接被應(yīng)用層任務(wù)引用。如果中間層沒有沉淀的ODS層數(shù)據(jù),則通過CDM層的視圖訪問。CDM層視圖必須使用調(diào)度程序進(jìn)行封裝,保持視圖的可維護(hù)性與可管理性。 CDM層任務(wù)的深度不宜過大(建議不超過10層)。 一個計算刷新任務(wù)只允許一個輸出表,特殊情況除外。 如果多個任務(wù)刷新輸出一個表(不同任務(wù)插入不同的分區(qū)),DataWorks上需要建立一個虛擬任務(wù),依賴多個任務(wù)的刷新和輸出。通常,下游應(yīng)該依賴此虛擬任務(wù)。 CDM匯總層優(yōu)先調(diào)用CDM明細(xì)層,可累加指標(biāo)計算。CDM匯總層盡量優(yōu)先調(diào)用已經(jīng)產(chǎn)出的粗粒度匯總層,避免大量匯總層數(shù)據(jù)直接從海量的明細(xì)數(shù)據(jù)層中計算得出。 CDM明細(xì)層累計快照事實表優(yōu)先調(diào)用CDM事務(wù)型事實表,保持?jǐn)?shù)據(jù)的一致性產(chǎn)出。 有針對性地建設(shè)CDM公共匯總層,避免應(yīng)用層過度引用和依賴CDM層明細(xì)數(shù)據(jù)。