
保姆級(jí)教程:硬核解讀 Transformer (原理+源碼)
一、前言
大家好,我是 Jack。
本文是圖解 AI 算法系列教程的第二篇,今天的主角是 Transformer。
Transformer 可以做很多有趣而又有意義的事情。
比如我寫過的《用自己訓(xùn)練的AI玩王者榮耀是什么體驗(yàn)?》。
再比如 OpenAI 的 DALL·E,可以魔法一般地按照自然語言文字描述直接生成對(duì)應(yīng)圖片!
輸入文本:鱷梨形狀的扶手椅。
AI 生成的圖像:

兩者都是多模態(tài)的應(yīng)用,這也是各大巨頭的跟進(jìn)方向,可謂大勢(shì)所趨。
Transformer 最初主要應(yīng)用于一些自然語言處理場(chǎng)景,比如翻譯、文本分類、寫小說、寫歌等。
隨著技術(shù)的發(fā)展,Transformer 開始征戰(zhàn)視覺領(lǐng)域,分類、檢測(cè)等任務(wù)均不在話下,逐漸走上了多模態(tài)的道路。

Transformer 近兩年非常火爆,內(nèi)容也很多,要想講清楚,還涉及一些基于該結(jié)構(gòu)的預(yù)訓(xùn)練模型,例如著名的 BERT,GPT,以及剛出的 DALL·E 等。
它們都是基于 Transformer 的上層應(yīng)用,因?yàn)?Transformer 很難訓(xùn)練,巨頭們就肩負(fù)起了造福大眾的使命,開源了各種好用的預(yù)訓(xùn)練模型。
我們都是站在巨人肩膀上學(xué)習(xí),用開源的預(yù)訓(xùn)練模型在一些特定的應(yīng)用場(chǎng)景進(jìn)行遷移學(xué)習(xí)。
篇幅有限,本文先講解 Transformer 的基礎(chǔ)原理,希望每個(gè)人都可以看懂。
后面我會(huì)繼續(xù)寫 BERT、GPT 等內(nèi)容,更新可能慢一些,但是跟著學(xué),絕對(duì)都能有所收獲。
還是那句話:如果你喜歡這個(gè) AI 算法系列教程,一定要讓我知道,轉(zhuǎn)發(fā)在看支持,更文更有動(dòng)力!
二、Transformer
Transformer 是 Google 在 2017 年提出的用于機(jī)器翻譯的模型。

Transformer 的內(nèi)部,在本質(zhì)上是一個(gè) Encoder-Decoder 的結(jié)構(gòu),即 編碼器-解碼器。
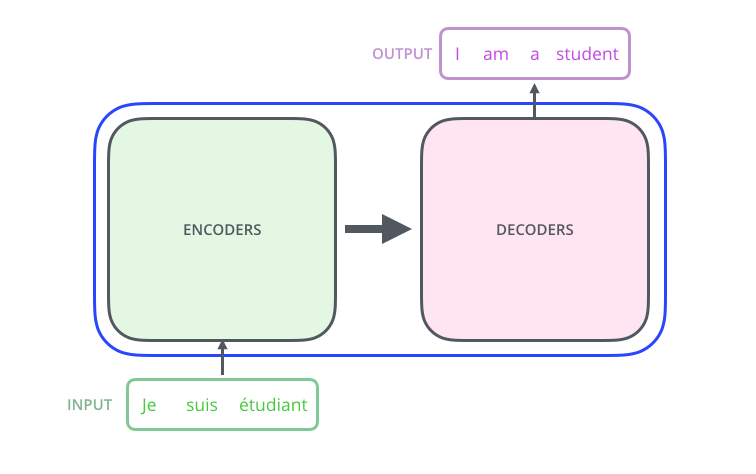
Transformer 中拋棄了傳統(tǒng)的 CNN 和 RNN,整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)完全由 Attention 機(jī)制組成,并且采用了 6 層 Encoder-Decoder 結(jié)構(gòu)。
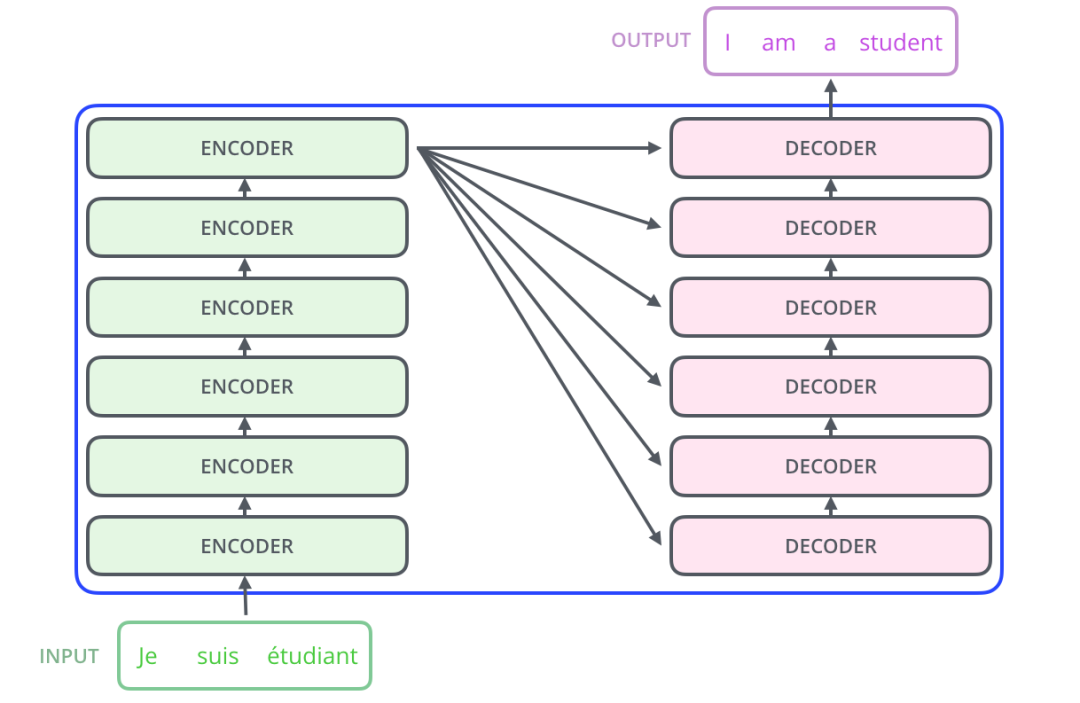
顯然,Transformer 主要分為兩大部分,分別是編碼器和解碼器。
整個(gè) Transformer 是由 6 個(gè)這樣的結(jié)構(gòu)組成,為了方便理解,我們只看其中一個(gè)Encoder-Decoder 結(jié)構(gòu)。
以一個(gè)簡(jiǎn)單的例子進(jìn)行說明:
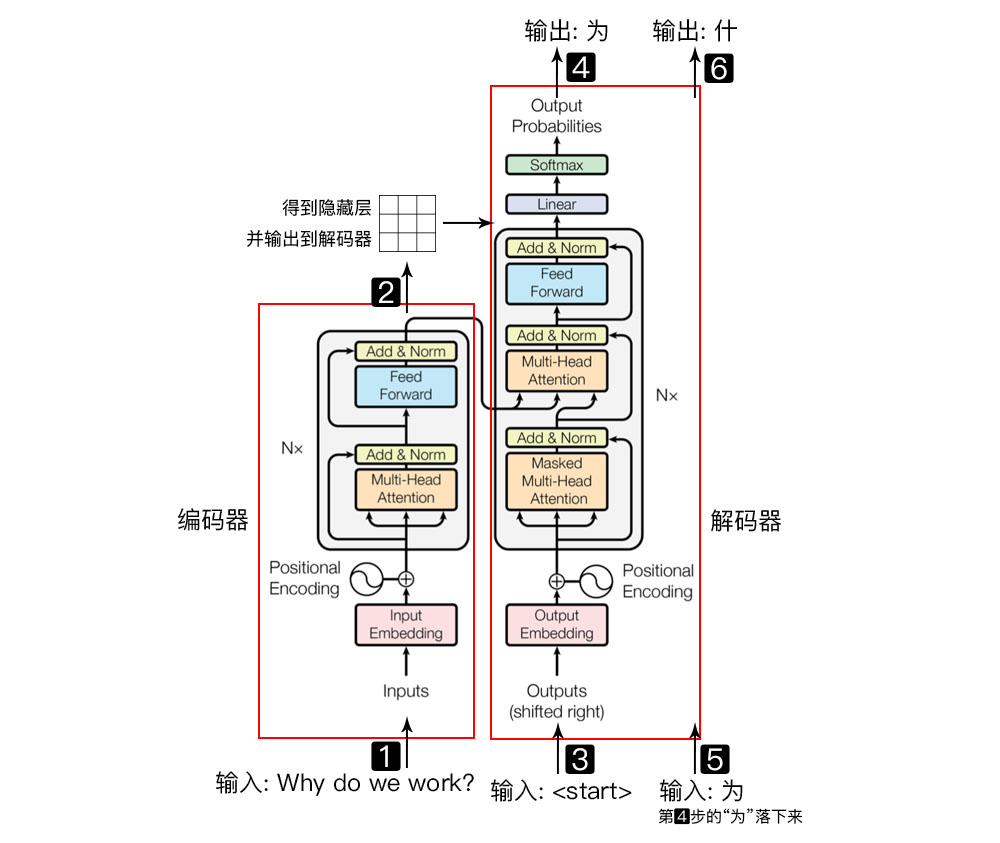
Why do we work?,我們?yōu)槭裁垂ぷ鳎?/p>
左側(cè)紅框是編碼器,右側(cè)紅框是解碼器,
編碼器負(fù)責(zé)把自然語言序列映射成為隱藏層(上圖第2步),即含有自然語言序列的數(shù)學(xué)表達(dá)。
解碼器把隱藏層再映射為自然語言序列,從而使我們可以解決各種問題,如情感分析、機(jī)器翻譯、摘要生成、語義關(guān)系抽取等。
簡(jiǎn)單說下,上圖每一步都做了什么:
輸入自然語言序列到編碼器: Why do we work?(為什么要工作); 編碼器輸出的隱藏層,再輸入到解碼器; 輸入 (起始)符號(hào)到解碼器; 解碼器得到第一個(gè)字"為"; 將得到的第一個(gè)字"為"落下來再輸入到解碼器; 解碼器得到第二個(gè)字"什"; 將得到的第二字再落下來,直到解碼器輸出 (終止符),即序列生成完成。
解碼器和編碼器的結(jié)構(gòu)類似,本文以編碼器部分進(jìn)行講解。即把自然語言序列映射為隱藏層的數(shù)學(xué)表達(dá)的過程,因?yàn)槔斫饬司幋a器中的結(jié)構(gòu),理解解碼器就非常簡(jiǎn)單了。
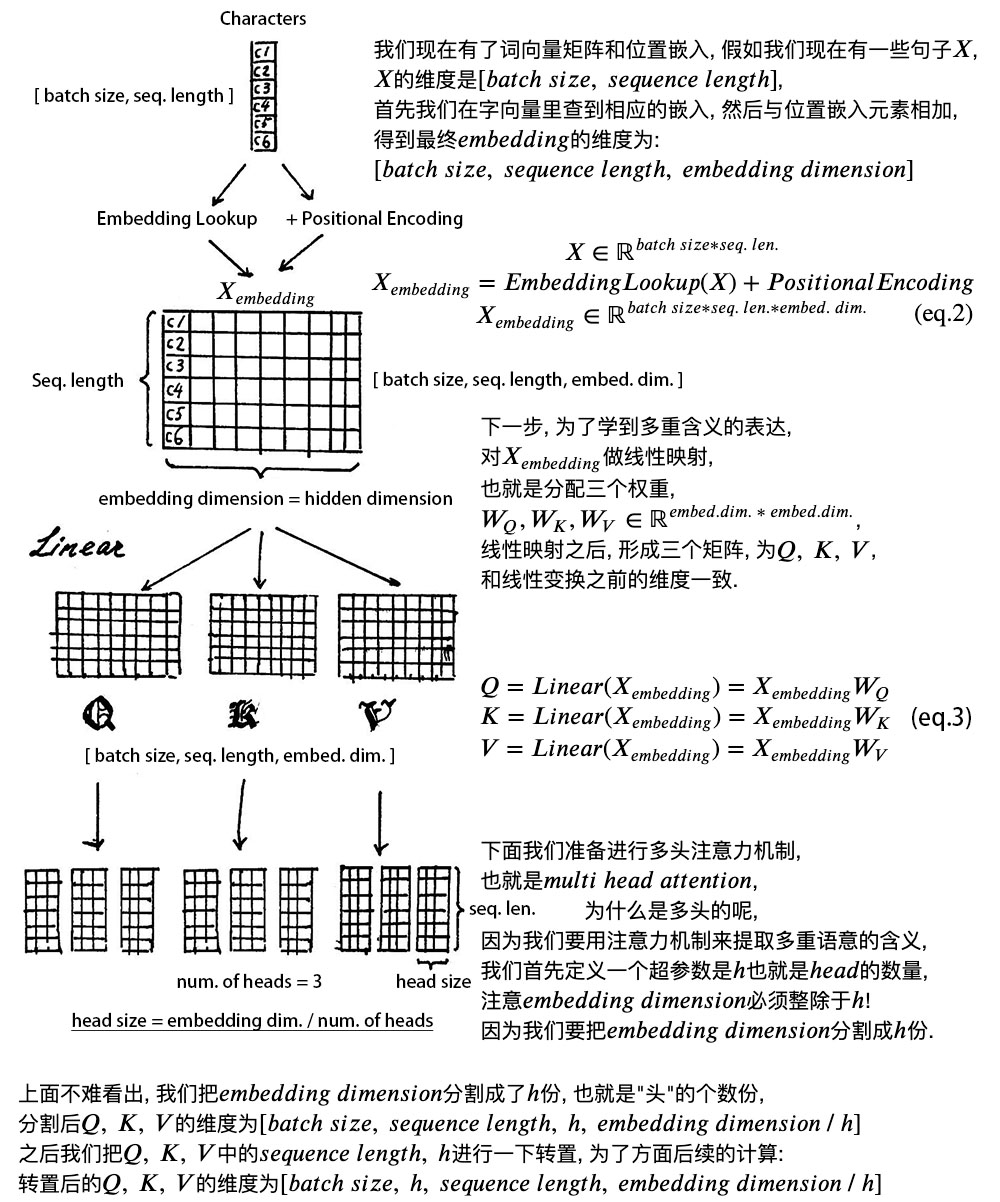
為了方便學(xué)習(xí),我將編碼器分為 4 個(gè)部分,依次講解。
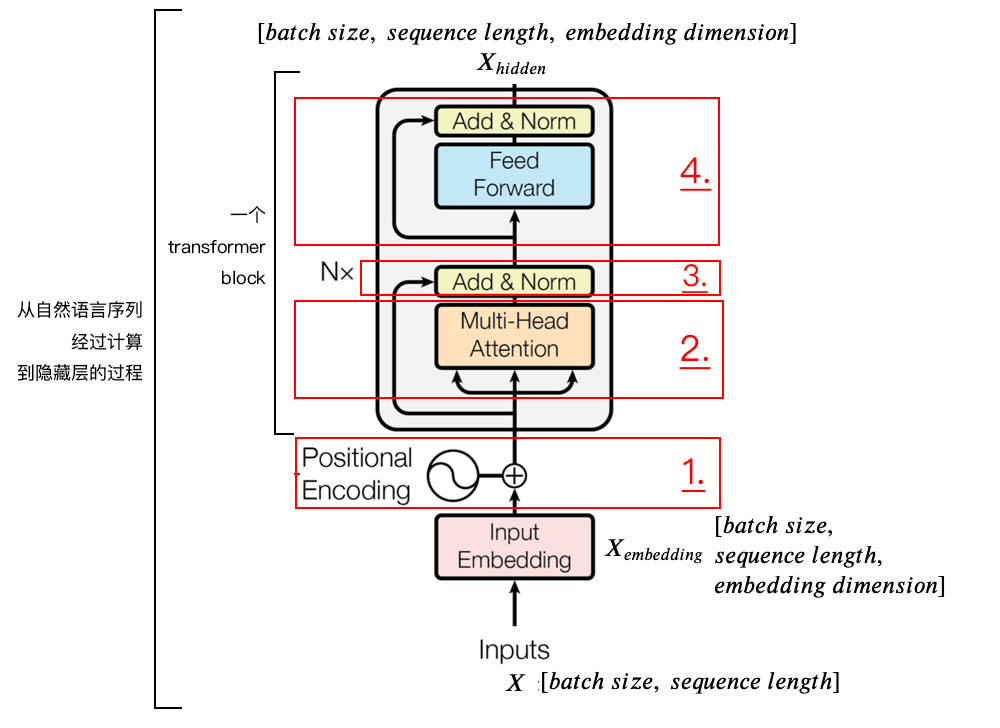
1、位置嵌入(???????????????????? ????????????????)
我們輸入數(shù)據(jù) X 維度為[batch size, sequence length]的數(shù)據(jù),比如我們?yōu)槭裁垂ぷ?/code>。
batch size 就是 batch 的大小,這里只有一句話,所以 batch size 為 1,sequence length 是句子的長(zhǎng)度,一共 7 個(gè)字,所以輸入的數(shù)據(jù)維度是 [1, 7]。
我們不能直接將這句話輸入到編碼器中,因?yàn)?Tranformer 不認(rèn)識(shí),我們需要先進(jìn)行字嵌入,即得到圖中的 。
簡(jiǎn)單點(diǎn)說,就是文字->字向量的轉(zhuǎn)換,這種轉(zhuǎn)換是將文字轉(zhuǎn)換為計(jì)算機(jī)認(rèn)識(shí)的數(shù)學(xué)表示,用到的方法就是 Word2Vec,Word2Vec 的具體細(xì)節(jié),對(duì)于初學(xué)者暫且不用了解,這個(gè)是可以直接使用的。
得到的 的維度是 [batch size, sequence length, embedding dimension],embedding dimension 的大小由 Word2Vec 算法決定,Tranformer 采用 512 長(zhǎng)度的字向量。所以 的維度是 [1, 7, 512]。
至此,輸入的我們?yōu)槭裁垂ぷ?/code>,可以用一個(gè)矩陣來簡(jiǎn)化表示。
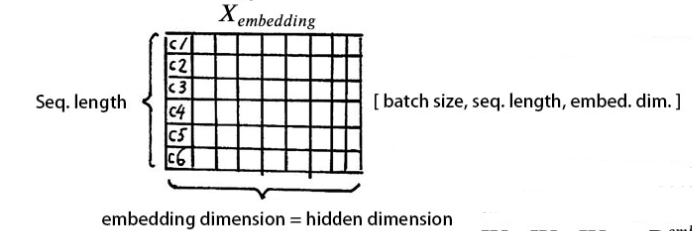
我們知道,文字的先后順序,很重要。
比如吃飯沒、沒吃飯、沒飯吃、飯吃沒、飯沒吃,同樣三個(gè)字,順序顛倒,所表達(dá)的含義就不同了。
文字的位置信息很重要,Tranformer 沒有類似 RNN 的循環(huán)結(jié)構(gòu),沒有捕捉順序序列的能力。
為了保留這種位置信息交給 Tranformer 學(xué)習(xí),我們需要用到位置嵌入。
加入位置信息的方式非常多,最簡(jiǎn)單的可以是直接將絕對(duì)坐標(biāo) 0,1,2 編碼。
Tranformer 采用的是 sin-cos 規(guī)則,使用了 sin 和 cos 函數(shù)的線性變換來提供給模型位置信息:
上式中 pos 指的是句中字的位置,取值范圍是 [0, ?????? ???????????????? ???????????),i 指的是字嵌入的維度, 取值范圍是 [0, ?????????????????? ??????????????????)。 就是 ?????????????????? ?????????????????? 的大小。
上面有 sin 和 cos 一組公式,也就是對(duì)應(yīng)著 ?????????????????? ?????????????????? 維度的一組奇數(shù)和偶數(shù)的序號(hào)的維度,從而產(chǎn)生不同的周期性變化。
可以用代碼,簡(jiǎn)單看下效果。
#?導(dǎo)入依賴庫
import?numpy?as?np
import?matplotlib.pyplot?as?plt
import?seaborn?as?sns
import?math
def?get_positional_encoding(max_seq_len,?embed_dim):
????#?初始化一個(gè)positional?encoding
????#?embed_dim:?字嵌入的維度
????#?max_seq_len:?最大的序列長(zhǎng)度
????positional_encoding?=?np.array([
????????[pos?/?np.power(10000,?2?*?i?/?embed_dim)?for?i?in?range(embed_dim)]
????????if?pos?!=?0?else?np.zeros(embed_dim)?for?pos?in?range(max_seq_len)])
????positional_encoding[1:,?0::2]?=?np.sin(positional_encoding[1:,?0::2])??#?dim?2i?偶數(shù)
????positional_encoding[1:,?1::2]?=?np.cos(positional_encoding[1:,?1::2])??#?dim?2i+1?奇數(shù)
????#?歸一化,?用位置嵌入的每一行除以它的模長(zhǎng)
????#?denominator?=?np.sqrt(np.sum(position_enc**2,?axis=1,?keepdims=True))
????#?position_enc?=?position_enc?/?(denominator?+?1e-8)
????return?positional_encoding
????
positional_encoding?=?get_positional_encoding(max_seq_len=100,?embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal?Function")
plt.xlabel("hidden?dimension")
plt.ylabel("sequence?length")
可以看到,位置嵌入在 ?????????????????? ?????????????????? (也是hidden dimension )維度上隨著維度序號(hào)增大,周期變化會(huì)越來越慢,而產(chǎn)生一種包含位置信息的紋理。
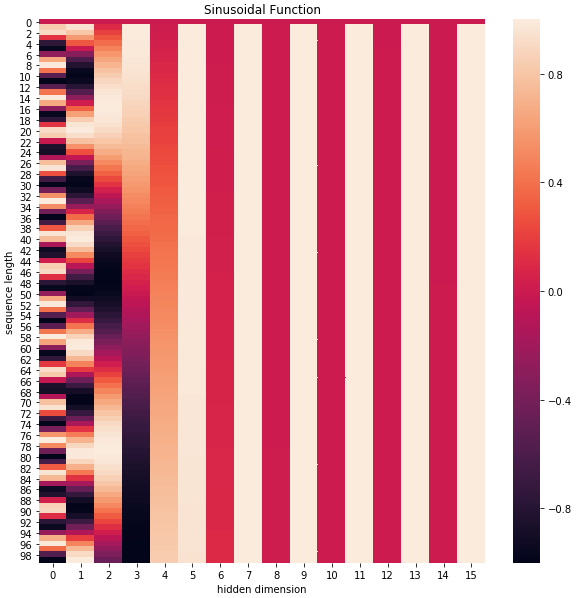
就這樣,產(chǎn)生獨(dú)一的紋理位置信息,模型從而學(xué)到位置之間的依賴關(guān)系和自然語言的時(shí)序特性。
最后,將 和 位置嵌入 相加,送給下一層。
2、自注意力層(???????? ?????????????????? ?????????????????)
直接看下圖筆記,講解的非常詳細(xì)。
多頭的意義在于, 得到的矩陣就叫注意力矩陣,它可以表示每個(gè)字與其他字的相似程度。因?yàn)椋蛄康狞c(diǎn)積值越大,說明兩個(gè)向量越接近。
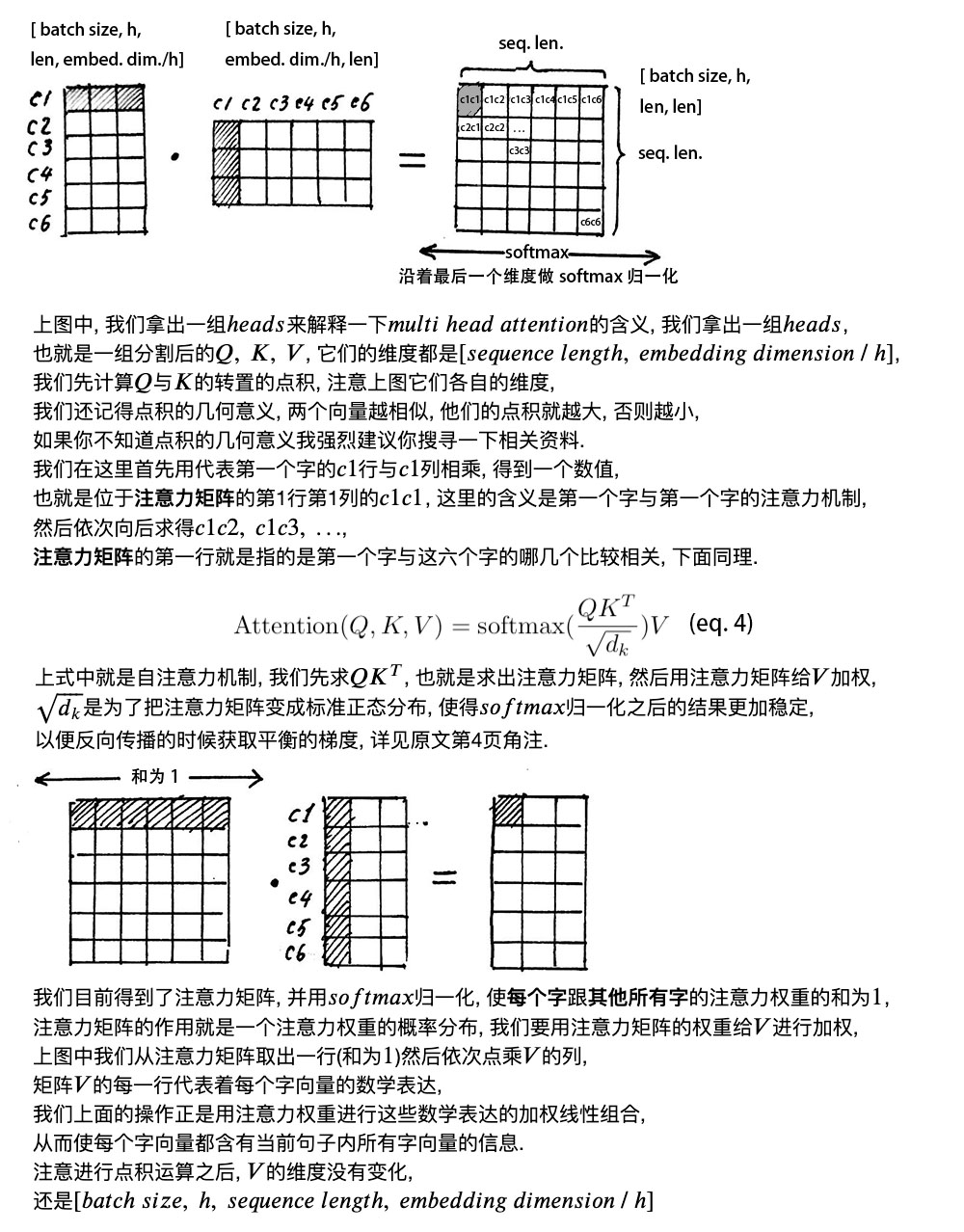
我們的目的是,讓每個(gè)字都含有當(dāng)前這個(gè)句子中的所有字的信息,用注意力層,我們做到了。
需要注意的是,在上面 ???????? ?????????????????? 的計(jì)算過程中,我們通常使用 ???????? ?????????,也就是一次計(jì)算多句話,上文舉例只用了一個(gè)句子。
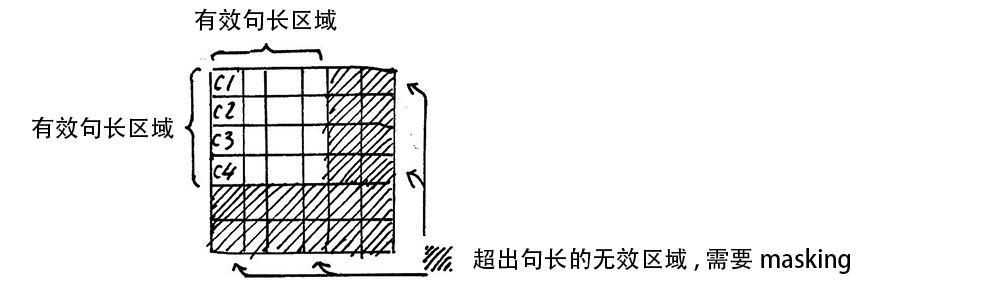
每個(gè)句子的長(zhǎng)度是不一樣的,需要按照最長(zhǎng)的句子的長(zhǎng)度統(tǒng)一處理。對(duì)于短的句子,進(jìn)行 Padding 操作,一般我們用 0 來進(jìn)行填充。
3、殘差鏈接和層歸一化
加入了殘差設(shè)計(jì)和層歸一化操作,目的是為了防止梯度消失,加快收斂。
1) 殘差設(shè)計(jì)
我們?cè)谏弦徊降玫搅私?jīng)過注意力矩陣加權(quán)之后的 ??, 也就是 ??????????????????(??, ??, ??),我們對(duì)它進(jìn)行一下轉(zhuǎn)置,使其和 ???????????????????? 的維度一致, 也就是 [????????? ????????, ???????????????? ???????????, ?????????????????? ??????????????????] ,然后把他們加起來做殘差連接,直接進(jìn)行元素相加,因?yàn)樗麄兊木S度一致:
在之后的運(yùn)算里,每經(jīng)過一個(gè)模塊的運(yùn)算,都要把運(yùn)算之前的值和運(yùn)算之后的值相加,從而得到殘差連接,訓(xùn)練的時(shí)候可以使梯度直接走捷徑反傳到最初始層:
2) 層歸一化
作用是把神經(jīng)網(wǎng)絡(luò)中隱藏層歸一為標(biāo)準(zhǔn)正態(tài)分布,也就是 ??.??.?? 獨(dú)立同分布, 以起到加快訓(xùn)練速度, 加速收斂的作用。
上式中以矩陣的行 (??????) 為單位求均值:
上式中以矩陣的行 (??????) 為單位求方差:
然后用每一行的每一個(gè)元素減去這行的均值,再除以這行的標(biāo)準(zhǔn)差,從而得到歸一化后的數(shù)值,是為了防止除;
之后引入兩個(gè)可訓(xùn)練參數(shù)來彌補(bǔ)歸一化的過程中損失掉的信息,注意表示元素相乘而不是點(diǎn)積,我們一般初始化為全,而為全。
代碼層面非常簡(jiǎn)單,單頭 attention 操作如下:
class?ScaledDotProductAttention(nn.Module):
????'''?Scaled?Dot-Product?Attention?'''
????def?__init__(self,?temperature,?attn_dropout=0.1):
????????super().__init__()
????????self.temperature?=?temperature
????????self.dropout?=?nn.Dropout(attn_dropout)
????def?forward(self,?q,?k,?v,?mask=None):
????????#?self.temperature是論文中的d_k?**?0.5,防止梯度過大
????????#?QxK/sqrt(dk)
????????attn?=?torch.matmul(q?/?self.temperature,?k.transpose(2,?3))
????????if?mask?is?not?None:
????????????#?屏蔽不想要的輸出
????????????attn?=?attn.masked_fill(mask?==?0,?-1e9)
????????#?softmax+dropout
????????attn?=?self.dropout(F.softmax(attn,?dim=-1))
????????#?概率分布xV
????????output?=?torch.matmul(attn,?v)
????????return?output,?attn
Multi-Head Attention 實(shí)現(xiàn)在 ScaledDotProductAttention 基礎(chǔ)上構(gòu)建:
class?MultiHeadAttention(nn.Module):
????'''?Multi-Head?Attention?module?'''
????#?n_head頭的個(gè)數(shù),默認(rèn)是8
????#?d_model編碼向量長(zhǎng)度,例如本文說的512
????#?d_k,?d_v的值一般會(huì)設(shè)置為?n_head?*?d_k=d_model,
????#?此時(shí)concat后正好和原始輸入一樣,當(dāng)然不相同也可以,因?yàn)楹竺嬗衒c層
????#?相當(dāng)于將可學(xué)習(xí)矩陣分成獨(dú)立的n_head份
????def?__init__(self,?n_head,?d_model,?d_k,?d_v,?dropout=0.1):
????????super().__init__()
????????#?假設(shè)n_head=8,d_k=64
????????self.n_head?=?n_head
????????self.d_k?=?d_k
????????self.d_v?=?d_v
????????#?d_model輸入向量,n_head?*?d_k輸出向量
????????#?可學(xué)習(xí)W^Q,W^K,W^V矩陣參數(shù)初始化
????????self.w_qs?=?nn.Linear(d_model,?n_head?*?d_k,?bias=False)
????????self.w_ks?=?nn.Linear(d_model,?n_head?*?d_k,?bias=False)
????????self.w_vs?=?nn.Linear(d_model,?n_head?*?d_v,?bias=False)
????????#?最后的輸出維度變換操作
????????self.fc?=?nn.Linear(n_head?*?d_v,?d_model,?bias=False)
????????#?單頭自注意力
????????self.attention?=?ScaledDotProductAttention(temperature=d_k?**?0.5)
????????self.dropout?=?nn.Dropout(dropout)
????????#?層歸一化
????????self.layer_norm?=?nn.LayerNorm(d_model,?eps=1e-6)
????def?forward(self,?q,?k,?v,?mask=None):
????????#?假設(shè)qkv輸入是(b,100,512),100是訓(xùn)練每個(gè)樣本最大單詞個(gè)數(shù)
????????#?一般qkv相等,即自注意力
????????residual?=?q
????????#?將輸入x和可學(xué)習(xí)矩陣相乘,得到(b,100,512)輸出
????????#?其中512的含義其實(shí)是8x64,8個(gè)head,每個(gè)head的可學(xué)習(xí)矩陣為64維度
????????#?q的輸出是(b,100,8,64),kv也是一樣
????????q?=?self.w_qs(q).view(sz_b,?len_q,?n_head,?d_k)
????????k?=?self.w_ks(k).view(sz_b,?len_k,?n_head,?d_k)
????????v?=?self.w_vs(v).view(sz_b,?len_v,?n_head,?d_v)
????????#?變成(b,8,100,64),方便后面計(jì)算,也就是8個(gè)頭單獨(dú)計(jì)算
????????q,?k,?v?=?q.transpose(1,?2),?k.transpose(1,?2),?v.transpose(1,?2)
????????if?mask?is?not?None:
????????????mask?=?mask.unsqueeze(1)???#?For?head?axis?broadcasting.
????????#?輸出q是(b,8,100,64),維持不變,內(nèi)部計(jì)算流程是:
????????#?q*k轉(zhuǎn)置,除以d_k?**?0.5,輸出維度是b,8,100,100即單詞和單詞直接的相似性
????????#?對(duì)最后一個(gè)維度進(jìn)行softmax操作得到b,8,100,100
????????#?最后乘上V,得到b,8,100,64輸出
????????q,?attn?=?self.attention(q,?k,?v,?mask=mask)
????????#?b,100,8,64-->b,100,512
????????q?=?q.transpose(1,?2).contiguous().view(sz_b,?len_q,?-1)
????????q?=?self.dropout(self.fc(q))
????????#?殘差計(jì)算
????????q?+=?residual
????????#?層歸一化,在512維度計(jì)算均值和方差,進(jìn)行層歸一化
????????q?=?self.layer_norm(q)
????????return?q,?attn
4、前饋網(wǎng)絡(luò)
這個(gè)層就沒啥說的了,非常簡(jiǎn)單,直接看代碼吧:
class?PositionwiseFeedForward(nn.Module):
????'''?A?two-feed-forward-layer?module?'''
????def?__init__(self,?d_in,?d_hid,?dropout=0.1):
????????super().__init__()
????????#?兩個(gè)fc層,對(duì)最后的512維度進(jìn)行變換
????????self.w_1?=?nn.Linear(d_in,?d_hid)?#?position-wise
????????self.w_2?=?nn.Linear(d_hid,?d_in)?#?position-wise
????????self.layer_norm?=?nn.LayerNorm(d_in,?eps=1e-6)
????????self.dropout?=?nn.Dropout(dropout)
????def?forward(self,?x):
????????residual?=?x
????????x?=?self.w_2(F.relu(self.w_1(x)))
????????x?=?self.dropout(x)
????????x?+=?residual
????????x?=?self.layer_norm(x)
????????return?x
最后,回顧下 ?????????????????????? ?????????????? 的整體結(jié)構(gòu)。
經(jīng)過上文的梳理,我們已經(jīng)基本了解了 ?????????????????????? 編碼器的主要構(gòu)成部分,我們下面用公式把一個(gè) ?????????????????????? ?????????? 的計(jì)算過程整理一下:
1) 字向量與位置編碼
2) 自注意力機(jī)制
3) 殘差連接與層歸一化
4) 前向網(wǎng)絡(luò)
其實(shí)就是兩層線性映射并用激活函數(shù)激活,比如說:
5) 重復(fù)3)
三、絮叨
至此,我們已經(jīng)講完了 Transformer 編碼器的全部?jī)?nèi)容,知道了如何獲得自然語言的位置信息,注意力機(jī)制的工作原理等。
本文以原理講解為主,后續(xù)我會(huì)繼續(xù)更新實(shí)戰(zhàn)內(nèi)容,教大家如何訓(xùn)練我們自己的有趣又好玩的模型。
本文硬核,肝了很久,如果喜歡,還望轉(zhuǎn)發(fā)、再看多多支持。
我是 Jack ,我們下期見。
