
6個(gè)實(shí)例,8段代碼,詳解Python中的for循環(huán)

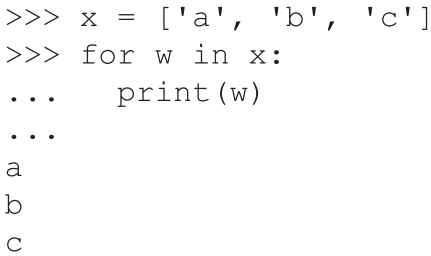


清單1 StringToNums.py
line = '1 2 3 4 10e abc'
sum = 0
invalidStr = ""
print('String of numbers:',line)
for str in line.split(" "):
try:
sum = sum + eval(str)
except:
invalidStr = invalidStr + str + ' '
print('sum:', sum)
if(invalidStr != ""):
print('Invalid strings:',invalidStr)
else:
print('All substrings are valid numbers')

清單2 Nth_exponet.py
maxPower = 4
maxCount = 4
def pwr(num):
prod = 1
for n in range(1,maxPower+1):
prod = prod*num
print(num,'to the power',n, 'equals',prod)
print('-----------')
for num in range(1,maxCount+1):
pwr(num)

清單3 Triangular1.py
max = 8
for x in range(1,max+1):
for y in range(1,x+1):
print(y,'', end='')
print()
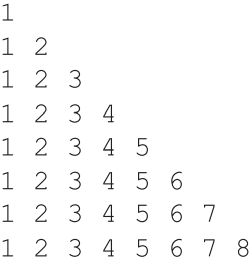
清單4 Compare2.py
x = 'This is a string that contains abc and Abc'
y = 'abc'
identical = 0
casematch = 0
for w in x.split():
if(w == y):
identical = identical + 1
elif (w.lower() == y.lower()):
casematch = casematch + 1
if(identical > 0):
print('found identical matches:', identical)
if(casematch > 0):
print('found case matches:', casematch)
if(casematch == 0 and identical == 0):
print('no matches found')

清單5 FixedColumnCount1.py
import string
wordCount = 0
str1 = 'this is a string with a set of words in it'
print('Left-justified strings:')
print('-----------------------')
for w in str1.split():
print('%-10s' % w)
wordCount = wordCount + 1
if(wordCount % 2 == 0):
print("")
print("\n")
print('Right-justified strings:')
print('------------------------')
wordCount = 0
for w in str1.split():
print('%10s' % w)
wordCount = wordCount + 1
if(wordCount % 2 == 0):
print()

清單6 FixedColumnWidth1.py
import string
left = 0
right = 0
columnWidth = 8
str1 = 'this is a string with a set of words in it and it will be split into a fixed column width'
strLen = len(str1)
print('Left-justified column:')
print('----------------------')
rowCount = int(strLen/columnWidth)
for i in range(0,rowCount):
left = i*columnWidth
right = (i+1)*columnWidth-1
word = str1[left:right]
print("%-10s" % word)
# check for a 'partial row'
if(rowCount*columnWidth < strLen):
left = rowCount*columnWidth-1;
right = strLen
word = str1[left:right]
print("%-10s" % word)

清單7 CompareStrings1.py
text1 = 'a b c d'
text2 = 'a b c e d'
if(text2.find(text1) >= 0):
print('text1 is a substring of text2')
else:
print('text1 is not a substring of text2')
subStr = True
for w in text1.split():
if(text2.find(w) == -1):
subStr = False
break
if(subStr == True):
print('Every word in text1 is a word in text2')
else:
print('Not every word in text1 is a word in text2')

清單8 StringChars1.py
text = 'abcdef'
for ch in text:
print('char:',ch,'ord value:',ord(ch))
print
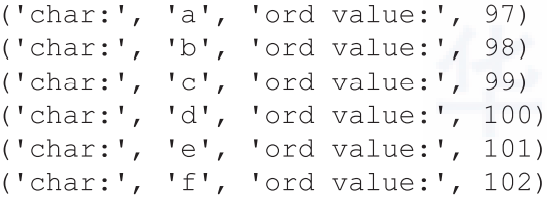

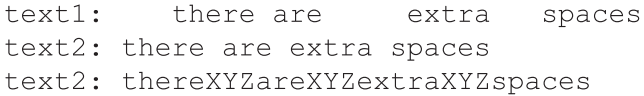


劃重點(diǎn)??
干貨直達(dá)??
評論
圖片
表情