FCN、Unet、Unet++:醫(yī)學(xué)圖像分割網(wǎng)絡(luò)一覽
計(jì)算機(jī)視覺|自然語言處理|機(jī)器學(xué)習(xí)|深度學(xué)習(xí)
編者薦語
?文章首先厘清了語義分割、實(shí)例分割和全景分割等定義的區(qū)別。在此基礎(chǔ)上,進(jìn)一步分析了FCN、Unet、Unet++等算法在醫(yī)學(xué)圖像上的適用情況。
作者丨Error@知乎
地址丨h(huán)ttps://zhuanlan.zhihu.com/p/159173338
先上目錄:
相關(guān)知識點(diǎn)解釋 FCN 網(wǎng)絡(luò)算法的理解 Unet 網(wǎng)絡(luò)算法的理解 Unet++ 網(wǎng)絡(luò)算法的理解 Unet+++ 網(wǎng)絡(luò)算法的理解 DeepLab v3+ 算法簡閱 Unet在醫(yī)學(xué)圖像上的適用與CNN分割算法的簡要總結(jié)
語義分割(Semantic Segmentation):就是對一張圖像上的所有像素點(diǎn)進(jìn)行分類。(eg: FCN/Unet/Unet++/...)
實(shí)例分割(Instance Segmentation):可以理解為目標(biāo)檢測和語義分割的結(jié)合。(eg: Mask R-CNN/...)相對目標(biāo)檢測的邊界框,實(shí)例分割可精確到物體的邊緣;相對語義分割,實(shí)例分割需要標(biāo)注出圖上同一物體的不同個(gè)體。
全景分割(Panoptic Segmentation):可以理解為語義分割和實(shí)例分割的結(jié)合。實(shí)例分割只對圖像中的object進(jìn)行檢測,并對檢測到的object進(jìn)行分割;全景分割是對圖中的所有物體包括背景都要進(jìn)行檢測和分割。
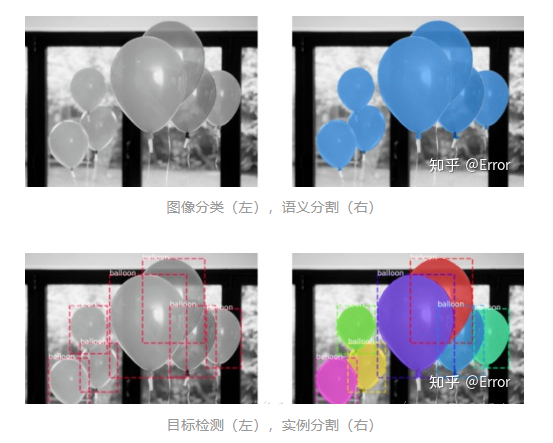
圖像分類:圖像中的氣球是一個(gè)類別。[1]
語義分割:分割出氣球和背景。
目標(biāo)檢測:圖像中有7個(gè)目標(biāo)氣球,并且檢測出每個(gè)氣球的坐標(biāo)位置。
實(shí)例分割:圖像中有7個(gè)不同的氣球,在像素層面給出屬于每個(gè)氣球的像素。
2. CNN特征學(xué)習(xí)的優(yōu)勢
高分辨率特征(較淺的卷積層)感知域較小,有利于feature map和原圖進(jìn)行對齊的,也就是我說的可以提供更多的位置信息。
低分辨率信息(深層的卷積層)由于感知域較大,能夠?qū)W習(xí)到更加抽象一些的特征,可以提供更多的上下文信息,即強(qiáng)語義信息,這有利于像素的精確分類。
3. 上采樣(意義在于將小尺寸的高維度feature map恢復(fù)回去)
上采樣(upsampling)一般包括2種方式:
4. 醫(yī)學(xué)影像語義分割的幾個(gè)評估指標(biāo)[3]
1)Jaccard(IoU)
用于比較有限樣本集之間的相似性與差異性。Jaccard值越大,樣本相似度越高。
關(guān)于對TP、FP、TN、FN的理解,可參考我的另一篇目標(biāo)檢測中mAP計(jì)算的博文:https://zhuanlan.zhihu.com/p/139073511
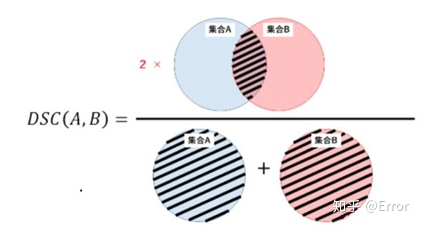
2)Dice相似系數(shù)
一種集合相似度度量指標(biāo),通常用于計(jì)算兩個(gè)樣本的相似度,值的范圍0~1 ,分割結(jié)果最好時(shí)值為1 ,最差時(shí)值為0 。Dice相似系數(shù)對mask的內(nèi)部填充比較敏感。
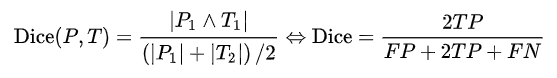
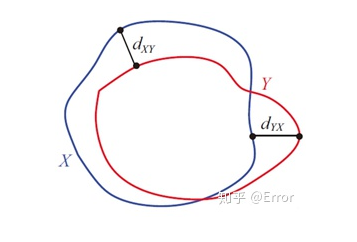
3)Hausdorff 距離(豪斯多夫距離)
描述兩組點(diǎn)集之間相似程度的一種量度,對分割出的邊界比較敏感。
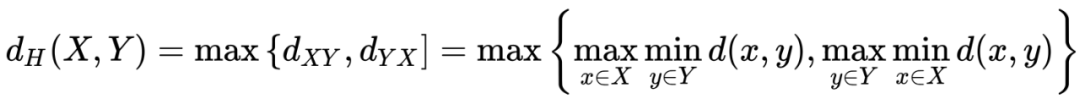
4)F1-score
用來衡量二分類模型精確度的一種指標(biāo),同時(shí)考慮到分類模型的準(zhǔn)確率和召回率,可看做是準(zhǔn)確率和召回率的一種加權(quán)平均。
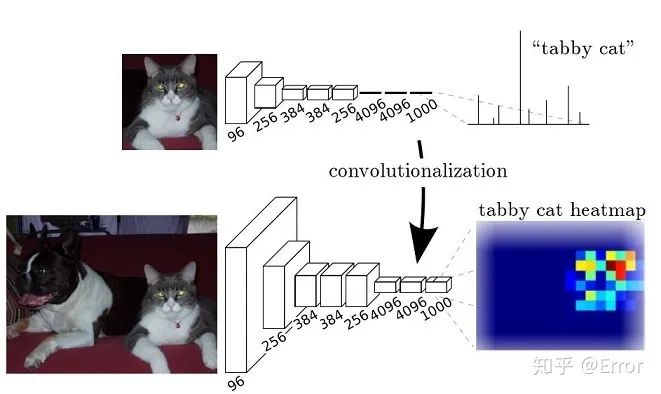
FCN將一般的經(jīng)典的分類網(wǎng)絡(luò)模型(VGG16...)的最后一層的FC層(全連接)換成卷積,這樣可以通過二維的特征圖,后接softmax獲得每個(gè)像素點(diǎn)的分類信息,從而解決了分割問題。
核心思想:
- 不含全連接層(fc)的全卷積(fully conv)網(wǎng)絡(luò)。可適應(yīng)任意尺寸輸入。
- 增大數(shù)據(jù)尺寸的反卷積(deconv)層。能夠輸出精細(xì)的結(jié)果。
- 結(jié)合不同深度層結(jié)果的跳級(skip)結(jié)構(gòu)。同時(shí)確保魯棒性和精確性。
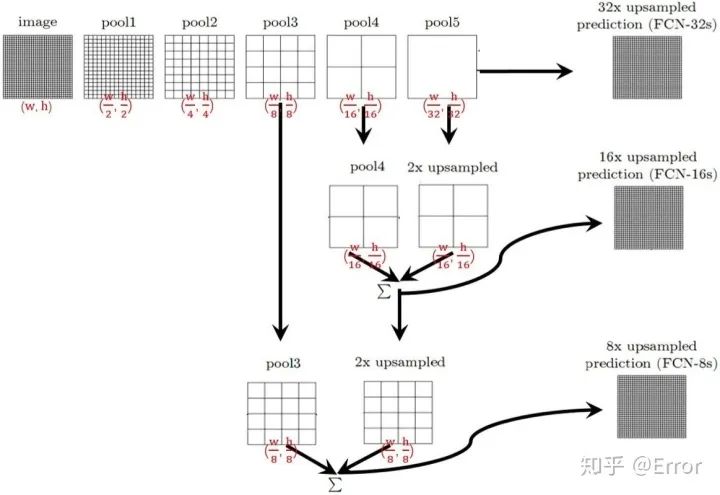
FCN結(jié)構(gòu)示意圖
對于FCN-32s,直接對pool5 feature進(jìn)行32倍上采樣獲得32x upsampled feature,再對32x upsampled feature每個(gè)點(diǎn)做softmax prediction獲得32x upsampled feature prediction(即分割圖)。
對于FCN-16s,首先對pool5 feature進(jìn)行2倍上采樣獲得2x upsampled feature,再把pool4 feature和2x upsampled feature逐點(diǎn)相加,然后對相加的feature進(jìn)行16倍上采樣,并softmax prediction,獲得16x upsampled feature prediction。
對于FCN-8s,首先進(jìn)行pool4+2x upsampled feature逐點(diǎn)相加,然后又進(jìn)行pool3+2x upsampled逐點(diǎn)相加,即進(jìn)行更多次特征融合。

FCN缺點(diǎn):
結(jié)果不夠精細(xì)。進(jìn)行8倍上采樣雖然比32倍的效果好了很多,但是上采樣的結(jié)果還是比較模糊和平滑,對圖像中的細(xì)節(jié)不敏感。
對各個(gè)像素進(jìn)行分類,沒有充分考慮像素與像素之間的關(guān)系。忽略了在通常的基于像素分類的分割方法中使用的空間規(guī)整(spatial regularization)步驟,缺乏空間一致性。
附FCN論文地址:https://arxiv.org/abs/1411.4038
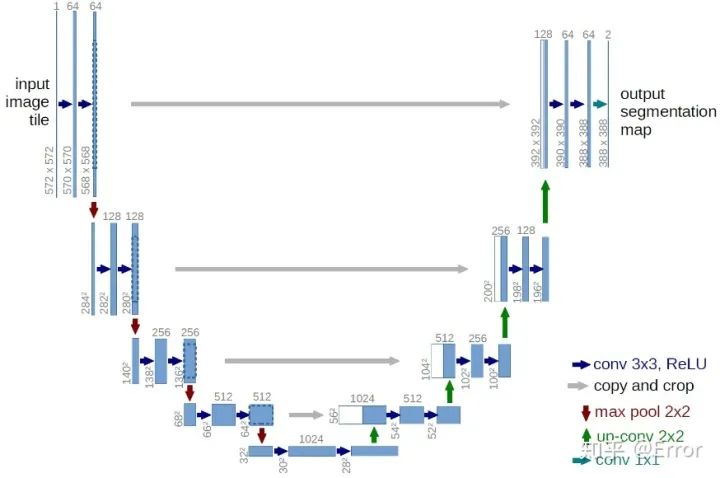
Unet網(wǎng)絡(luò)結(jié)構(gòu)圖
整個(gè)U-Net網(wǎng)絡(luò)結(jié)構(gòu)類似于一個(gè)大型的字母U,與FCN都是很小的分割網(wǎng)絡(luò),既沒有使用空洞卷積,也沒有后接CRF,結(jié)構(gòu)簡單。
1. 首先進(jìn)行Conv+Pooling下采樣;
2. 然后反卷積進(jìn)行上采樣,crop之前的低層feature map,進(jìn)行融合;
3. 再次上采樣。
4. 重復(fù)這個(gè)過程,直到獲得輸出388x388x2的feature map,
5. 最后經(jīng)過softmax獲得output segment map。總體來說與FCN思路非常類似。
UNet的encoder下采樣4次,一共下采樣16倍,對稱地,其decoder也相應(yīng)上采樣4次,將encoder得到的高級語義特征圖恢復(fù)到原圖片的分辨率。
它采用了與FCN不同的特征融合方式:
FCN采用的是逐點(diǎn)相加,對應(yīng)tensorflow的tf.add()函數(shù) U-Net采用的是channel維度拼接融合,對應(yīng)tensorflow的tf.concat()函數(shù)
附Unet論文地址:https://arxiv.org/pdf/1505.04597.pdf
文章對Unet改進(jìn)的點(diǎn)主要是skip connection,作者認(rèn)為skip connection 直接將unet中encoder的淺層特征與decoder的深層特征結(jié)合是不妥當(dāng)?shù)模瑫a(chǎn)生semantic gap。
文中假設(shè):當(dāng)所結(jié)合的淺層特征與深層特征是semantically similar時(shí),網(wǎng)絡(luò)的優(yōu)化問題就會更簡單,因此文章對skip connection的改進(jìn)就是想bridge/reduce 這個(gè)semantic gap。
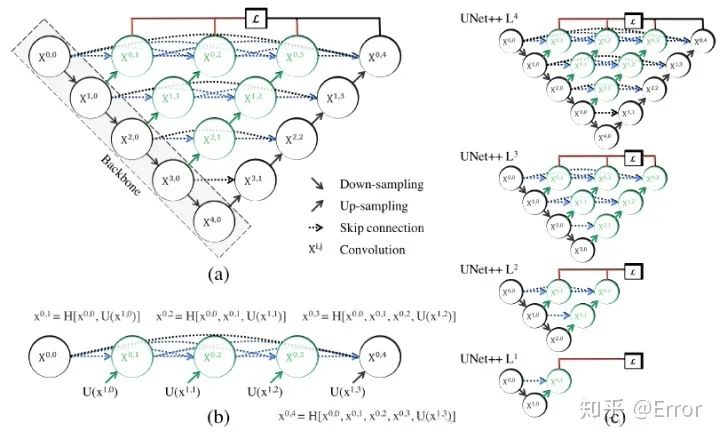
附Unet++論文地址:https://arxiv.org/pdf/1807.10165.pdf
代碼地址:https://github.com/MrGiovanni/UNetPlusPlus
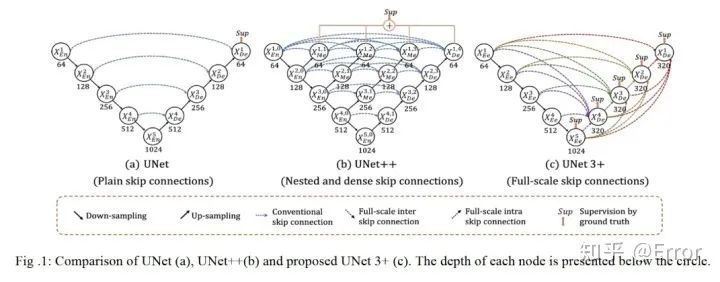
為了彌補(bǔ)UNet和UNet++的缺陷,UNet 3+中的每一個(gè)解碼器層都融合了來自編碼器中的小尺度和同尺度的特征圖,以及來自解碼器的大尺度的特征圖,這些特征圖捕獲了全尺度下的細(xì)粒度語義和粗粒度語義。
附U-net+++論文地址:https://arxiv.org/abs/2004.08790
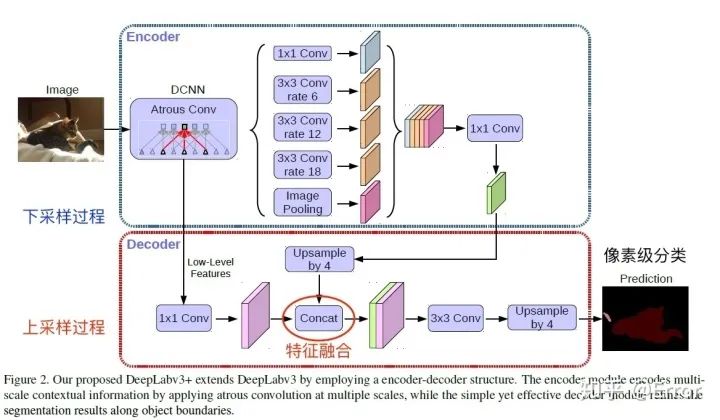
DeepLab v3+結(jié)構(gòu)圖
Encoder部分
Encoder就是原來的DeepLabv3,
需要注意點(diǎn):
1. 輸入尺寸與輸出尺寸比(output stride = 16),最后一個(gè)stage的膨脹率rate為2
2. Atrous Spatial Pyramid Pooling module(ASPP)有四個(gè)不同的rate,額外一個(gè)全局平均池化
Decoder部分
先把encoder的結(jié)果上采樣4倍,然后與resnet中下采樣前的Conv2特征concat一起,再進(jìn)行3x3的卷積,最后上采樣4倍得到最終結(jié)果。
需要注意點(diǎn):融合低層次信息前,先進(jìn)行1x1的卷積,目的是降通道(例如有512個(gè)通道,而encoder結(jié)果只有256個(gè)通道)
附DeepLab v3+論文地址:https://arxiv.org/pdf/1802.02611.pdf
UNet相比于FCN和Deeplab等,共進(jìn)行了4次上采樣,并在同一個(gè)stage使用了skip connection,而不是直接在高級語義特征上進(jìn)行監(jiān)督和loss反傳,這樣就保證了最后恢復(fù)出來的特征圖融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,從而可以進(jìn)行多尺度預(yù)測和DeepSupervision。4次上采樣也使得分割圖恢復(fù)邊緣等信息更加精細(xì)。
2. 為什么適用于醫(yī)學(xué)圖像?[7]
1. 因?yàn)獒t(yī)學(xué)圖像邊界模糊、梯度復(fù)雜,需要較多的高分辨率信息。高分辨率用于精準(zhǔn)分割。
2. 人體內(nèi)部結(jié)構(gòu)相對固定,分割目標(biāo)在人體圖像中的分布很具有規(guī)律,語義簡單明確,低分辨率信息能夠提供這一信息,用于目標(biāo)物體的識別。
UNet結(jié)合了低分辨率信息(提供物體類別識別依據(jù))和高分辨率信息(提供精準(zhǔn)分割定位依據(jù)),完美適用于醫(yī)學(xué)圖像分割。
3. 分割算法改進(jìn)總結(jié):
下采樣+上采樣:Convlution + Deconvlution/Resize 多尺度特征融合:特征逐點(diǎn)相加/特征channel維度拼接 獲得像素級別的segement map:對每一個(gè)像素點(diǎn)進(jìn)行判斷類別
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。
—THE END—
分享
收藏
點(diǎn)贊
在看