
【干貨】文本生成圖像的前世今生!
目前多模態(tài)任務(wù)成為行業(yè)熱點(diǎn),本文梳理了較為優(yōu)秀的多模態(tài)文本圖像模型:DALL·E、CLIP、GLIDE、DALL·E 2 (unCLIP)的模型框架、優(yōu)缺點(diǎn),及其迭代關(guān)系。






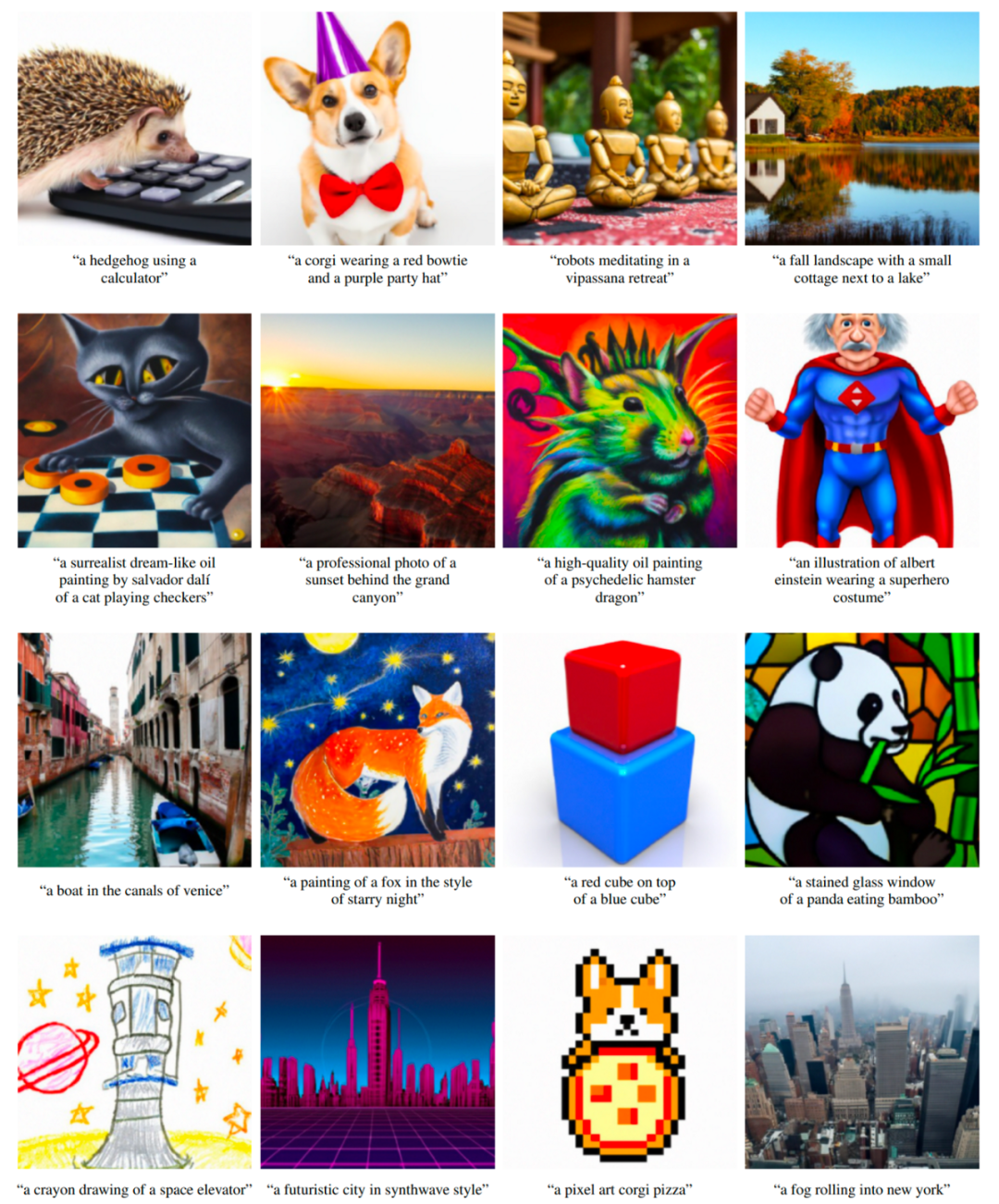


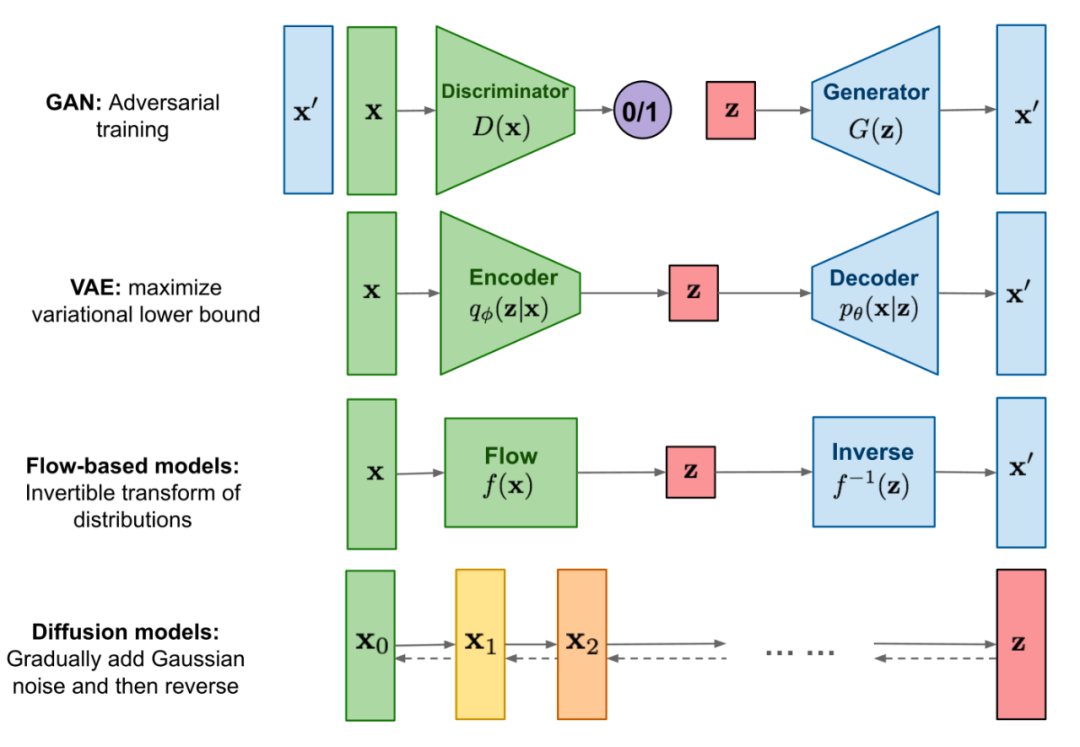
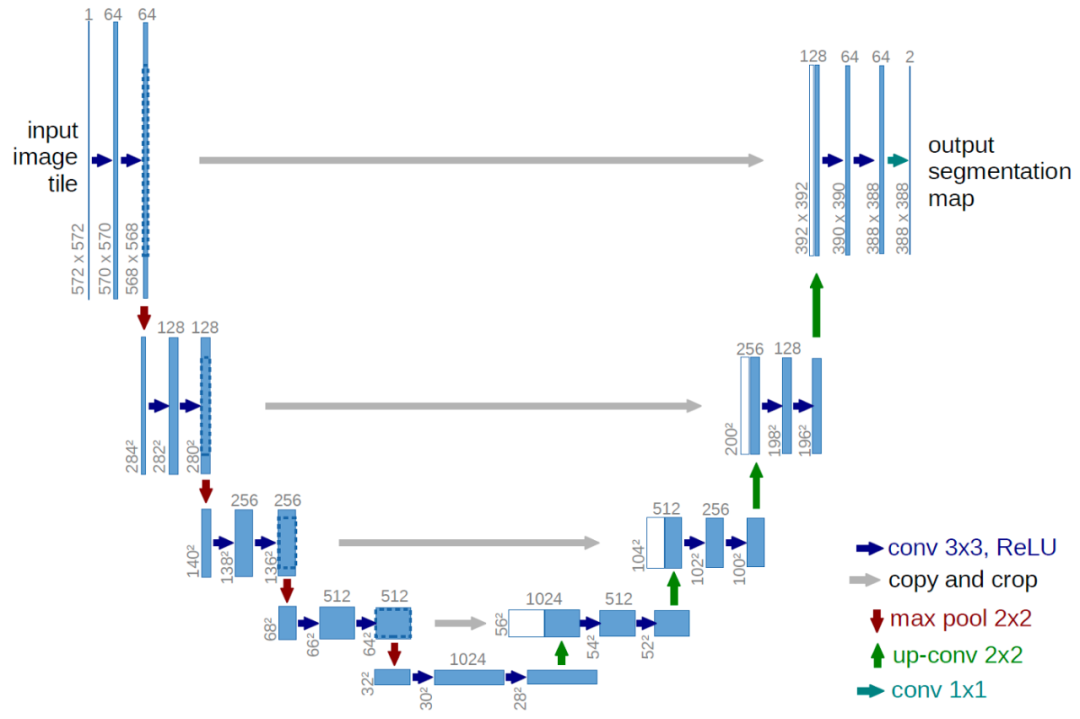
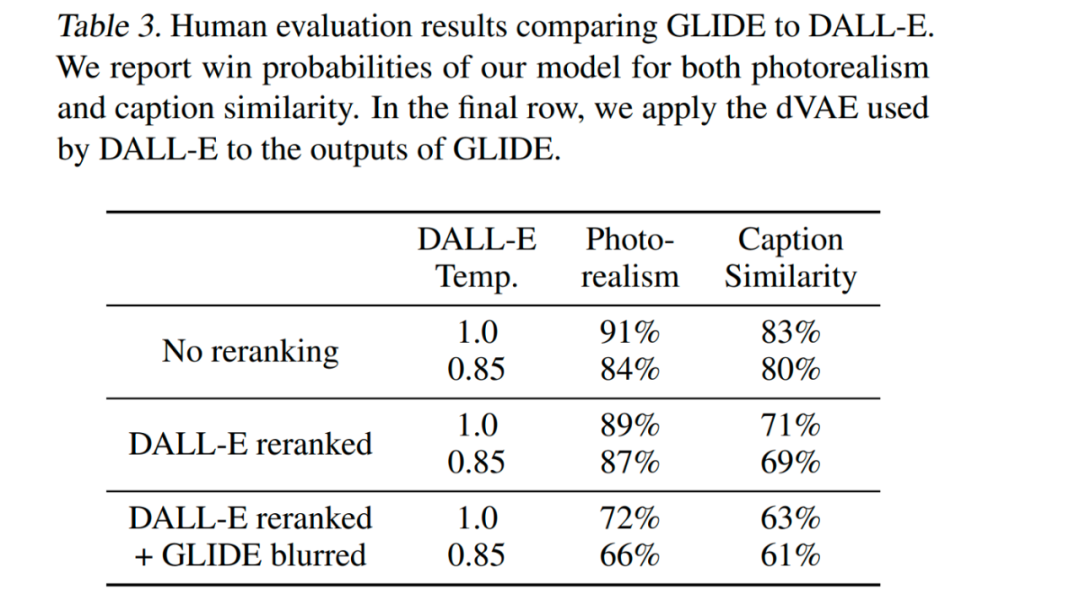







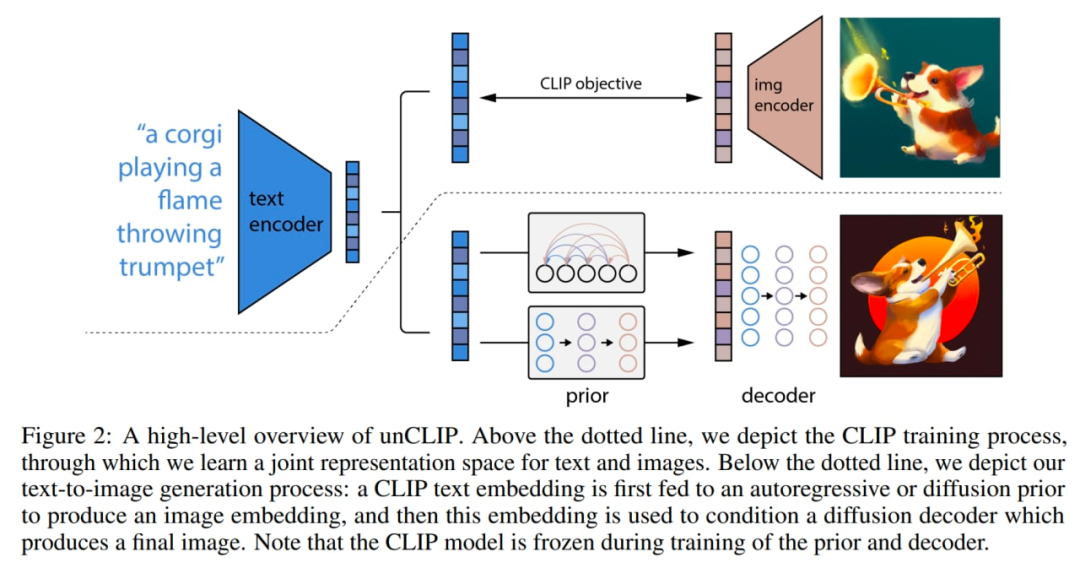
編碼的文本
CLIP 文本嵌入
擴(kuò)散時(shí)間步長(zhǎng)的嵌入
噪聲 CLIP 圖像嵌入
最終的嵌入,其來(lái)自 Transformer 的輸出用于預(yù)測(cè)無(wú)噪聲 CLIP 圖像嵌入。









??THE END?
轉(zhuǎn)載請(qǐng)聯(lián)系原公眾號(hào)獲得授權(quán)
投稿或?qū)で髨?bào)道:[email protected]

點(diǎn)個(gè)在看 paper不斷!
評(píng)論
圖片
表情