
說說 Redis 主從哨兵集群 ~
前言碎語
說起 Redis 應(yīng)該沒有人會陌生了吧,作為開發(fā)中最最最最最最最常用的 nosql,它的重要性不言而喻。
Redis有三種集群模式,第一個就是主從模式,第二種“哨兵”模式,第三種是 Cluster 集群模式。(準確的說應(yīng)該是四種,單機模式,但是基本上只適用于自己玩玩,這里就不說了)
今天就和大家細細聊聊這三種模式。
主從復(fù)制
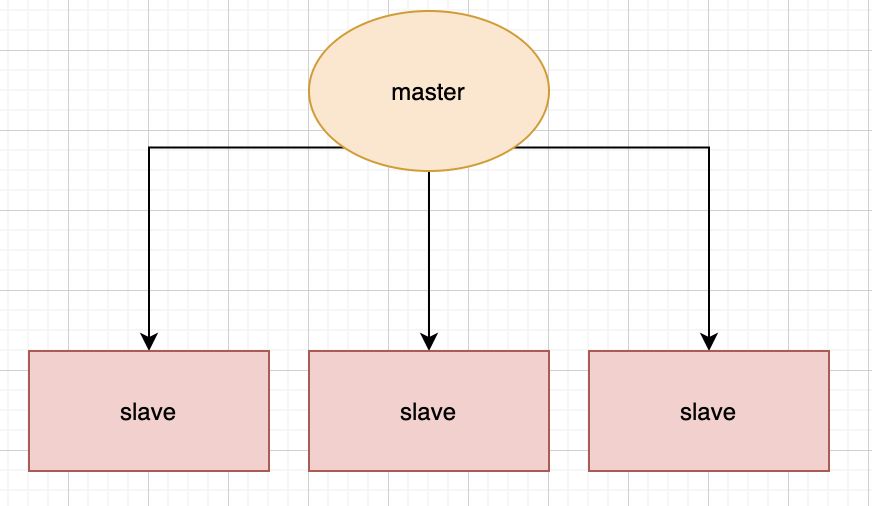
當其中一臺服務(wù)器更新之后,服務(wù)器會自動的將這臺更新的數(shù)據(jù)同步到另外一臺服務(wù)器上。
通過持久化的功能,redis可以保證就算是服務(wù)宕機重啟了,也只有少量的數(shù)據(jù)會丟失。但是在真實的使用場景當中,如果真的只有一臺服務(wù)器,并且恰好宕機了,那么就會導(dǎo)致整個服務(wù)都不可用,因此redis提供了集群的方式來部署,可以避免這種問題。
在主從復(fù)制這種集群部署模式中,我們會將數(shù)據(jù)庫分為兩類,第一種稱為主數(shù)據(jù)庫(master),另一種稱為從數(shù)據(jù)庫(slave)。
主數(shù)據(jù)庫會負責(zé)我們整個系統(tǒng)中的讀寫操作,從數(shù)據(jù)庫會負責(zé)我們整個數(shù)據(jù)庫中的讀操作。
其中在職場開發(fā)中的真實情況是,我們會讓主數(shù)據(jù)庫只負責(zé)寫操作,讓從數(shù)據(jù)庫只負責(zé)讀操作,就是為了讀寫分離,減輕服務(wù)器的壓力。
但是我在實際開發(fā)中會遇到一種情況,該數(shù)據(jù)是個熱點數(shù)據(jù),我們知道,數(shù)據(jù)同步一定是會耗時的,那么當一個熱點數(shù)據(jù)進入master中,而slave沒有來得及更新,再去讀這個數(shù)據(jù)就會造成數(shù)據(jù)不一致現(xiàn)象,所以當時我的方案就是直接去讀master節(jié)點,這個邏輯同樣適用于mysql主從中出現(xiàn)的問題。
主從同步原理
當一個從數(shù)據(jù)庫啟動時,它會向主數(shù)據(jù)庫發(fā)送一個SYNC命令 master收到后,在后臺保存快照,也就是我們說的RDB持久化,當然保存快照是需要消耗時間的,并且redis是單線程的(redis后面也支持了多線程,這里我們先不講),在保存快照期間redis收到的命令會緩存起來,快照完成后會將緩存的命令以及快照一起打包發(fā)給slave節(jié)點,從而保證主從數(shù)據(jù)庫的一致性。 從數(shù)據(jù)庫接受到快照以及緩存的命令后會將這部分數(shù)據(jù)寫入到硬盤上的臨時文件當中,寫入完成后會用這份文件去替換掉RDB快照文件,當然,這個操作是不會阻塞的,可以繼續(xù)接收命令執(zhí)行,具體原因其實就是fork了一個子進程,用子進程去完成了這些功能。
因為不會阻塞,所以,這部分初始化完成后,當主數(shù)據(jù)庫執(zhí)行了改變數(shù)據(jù)的命令后,會異步的給slave,這也就是我們說的復(fù)制同步階段,這個階段會貫穿在整個主從同步的過程中,直到主從同步結(jié)束后,復(fù)制同步才會終止。
那么我上文提到的數(shù)據(jù)不一致的現(xiàn)象又是怎么回事呢?
是因為redis采用了樂觀復(fù)制的策略:
容忍一定時間內(nèi)主從數(shù)據(jù)庫的數(shù)據(jù)是不一致的,但是會保證最終的結(jié)果一致。
所以當主從復(fù)制發(fā)生時,正常情況下的命令都會在主數(shù)據(jù)庫完成,然后直接反回給客戶端,這樣我們的性能就不會受到影響了,因為這里是主數(shù)據(jù)庫先完成命令,那么就會產(chǎn)生其他問題。
舉個例子,假如現(xiàn)在有1個master,6個slave,現(xiàn)在只有兩個slave完成了同步,master寫了新命令,在master準備將此命令傳輸給其他slave時,此刻其他的slave斷電了,那么就會造成數(shù)據(jù)不一致的現(xiàn)象發(fā)生。
所以redis針對這種情況作了兩個配置
min-slaves-to-write????2???(只有2個及以上的從數(shù)據(jù)庫連接到了主數(shù)據(jù)庫時,master庫才是可寫的)
min-slaves-max-lag???10??(10秒slave沒有和master進行交互就認為丟失鏈接)
無硬盤復(fù)制
我們剛剛說了主從之間是通過RDB快照來交互的,雖然看來邏輯很簡單,但是還是會存在一些問題:
1.master禁用了RDB快照時,發(fā)生了主從同步(復(fù)制初始化)操作,也會生成RDB快照,但是之后如果master發(fā)成了重啟,就會用RDB快照去恢復(fù)數(shù)據(jù),這份數(shù)據(jù)可能已經(jīng)很久了,中間就會丟失數(shù)據(jù) 2.在這種一主多從的結(jié)構(gòu)中,master每次和slave同步數(shù)據(jù)都要進行一次快照,從而在硬盤中生成RDB文件,會影響性能
為了解決這種問題,redis在后續(xù)的更新中也加入了無硬盤復(fù)制功能,也就是說直接通過網(wǎng)絡(luò)發(fā)送給slave,避免了和硬盤交互,但是也是有io消耗的。
增量復(fù)制
為什么會有增量復(fù)制?
剛剛我們說了復(fù)制的原理,但是他的缺點是很明顯的,就是在斷開主從鏈接后,即使你只發(fā)生了一條數(shù)據(jù)變化,也需要將所有的數(shù)據(jù)通過SYNC命令用RDB將所有的數(shù)據(jù)同步給slave,但是其實并不需要同步所有的數(shù)據(jù),只需要將改變的這小部分數(shù)據(jù)同步給slave就好了
所以為了解決這個問題,redis就有了增量復(fù)制。
這個原理其實是很簡單的,學(xué)過kafka 的小伙伴應(yīng)該知道,kafka消費是通過偏移量來計算的,redis的增量復(fù)制也是如此。
master會記下每個slave的id,在復(fù)制期間,如果有新消息,會將新消息(其實是新的命令,當然只包括讓數(shù)據(jù)放生變動的命令,如 set ?這種 )存放在一個固定大小的循環(huán)隊列中,這個大小是可以配置的,當然這時候發(fā)送的就是PSYNC命令了,然后master會在復(fù)制完成后將這部分數(shù)據(jù)發(fā)送給slave,這樣就在很大程度上保證了數(shù)據(jù)一致性。
哨兵模式
上文咱們說主從復(fù)制,在這種一主多從的結(jié)構(gòu)中,我們讓主從數(shù)據(jù)庫做到了讀寫分離,也讓從數(shù)據(jù)庫能夠完成數(shù)據(jù)備份的功能,可是也留下了一個比較嚴重的問題,當master掛了之后,只能由運維人員重新選擇一個slave升級成master,然后繼續(xù)提供服務(wù)。
想想一下,你國慶正放假,躺在三亞的海邊沐浴著陽光,享受著香檳,突然你們boss給你來了個電話,說線上的master掛了,是不是會心里一句mmp???,所以,redis為了你考慮,在redis2.6版本中,他來了他來了--------哨兵模式
什么是哨兵?
顧名思義,哨兵其實就是放哨的,它主要會有完成兩個功能。
1.監(jiān)控整個主數(shù)據(jù)庫和從數(shù)據(jù)庫,觀察它們是否正常運行
2.當主數(shù)據(jù)庫發(fā)生異常時,自動的將從數(shù)據(jù)庫升級為主數(shù)據(jù)庫,繼續(xù)保證整個服務(wù)的穩(wěn)定
哨兵其實是一個獨立的進程,如下圖
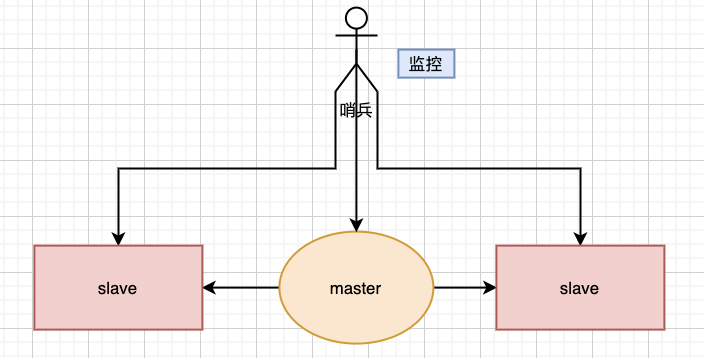
當然,上圖只是一個哨兵存在時的情況,但在現(xiàn)實中還會有兩個,甚至更多哨兵存在的情況
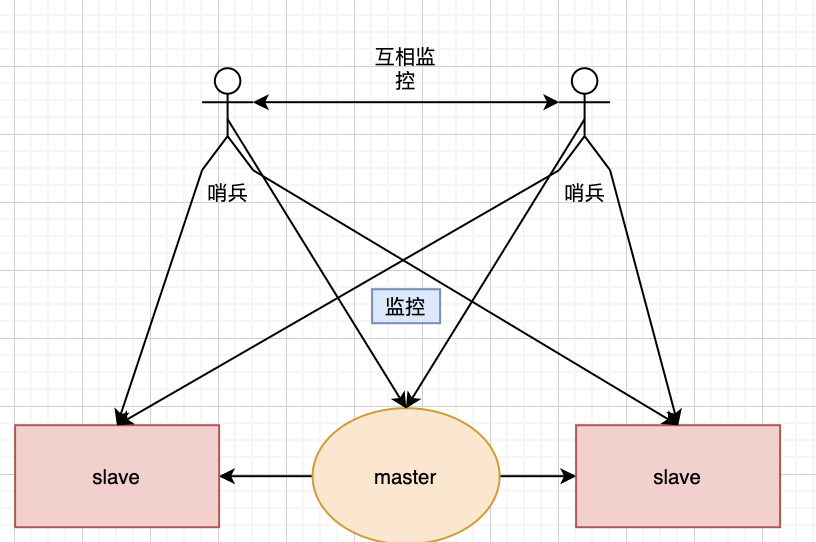
實現(xiàn)原理
當一個哨兵進程啟動時,它會先通過配置文件,找我們的主數(shù)據(jù)庫,當然,我們這里也只需要配置其監(jiān)控的主數(shù)據(jù)庫就好,之后哨兵會自動發(fā)現(xiàn)所有復(fù)制該主數(shù)據(jù)庫的從數(shù)據(jù)庫,當然一個哨兵是可以監(jiān)控多個redis系統(tǒng)的,同時,多個哨兵也可以同時監(jiān)控一個redis系統(tǒng)的,這里moon先給大家灌輸下這個概念,大家理解下,詳細的我會在后文提到。
哨兵進程啟動后后會和master建立兩條鏈接
1.用來獲取其他同樣在監(jiān)控著此redis系統(tǒng)的哨兵信息 2.發(fā)送一個info命令來獲取此redis系統(tǒng)master本身的信息
當和master完成鏈接建立后,該哨兵就會定時的做以下三件事情
1.每10秒會向master和slave發(fā)送info命令 2.每2秒會向master和slave發(fā)送自己的信息 3.每1秒會向master,slave以及其他同樣在監(jiān)控著此redis系統(tǒng)的哨兵發(fā)送ping命令
以上三個操作可是說是哨兵的核心了,下面就著重介紹一下這三個命令
首先,info命令可以讓哨兵獲取到當前數(shù)據(jù)庫的信息,比如運行id,復(fù)制信息等等,從而實現(xiàn)新節(jié)點的自動發(fā)現(xiàn),從數(shù)據(jù)庫的信息正是從info命令中獲取的,獲取從數(shù)據(jù)庫信息后,就會和從數(shù)據(jù)庫建立兩條鏈接,和主數(shù)據(jù)庫建立的鏈接是完全一樣的,之后就會每10s向主從數(shù)據(jù)庫發(fā)送info命令,當有新的從數(shù)據(jù)庫加入時,就會從info命令中發(fā)現(xiàn)了,從而將這個新的slave加入自己的監(jiān)控列表中。
當然如果有新的哨兵加入到了監(jiān)控中,其他哨兵也是從這個info命令中獲取的。
于此,就完成了對數(shù)據(jù)庫以及其他哨兵的自動發(fā)現(xiàn)和監(jiān)控,是不是很easy呢??
以上講了自動發(fā)現(xiàn)數(shù)據(jù)庫和其他的哨兵節(jié)點,之后哨兵就開始了它的工作,就是去監(jiān)控這些數(shù)據(jù)庫和節(jié)點有沒有停止,哨兵就會每隔一段時間向這些節(jié)點發(fā)送PING命令,如果一段時間沒有收到回復(fù)后,那么這個哨兵就會認為該節(jié)點已經(jīng)掛了,我們將其稱為主觀下線。
如果該節(jié)點是master,哨兵就會向其他節(jié)點詢問,看其他節(jié)點時候也認為該master掛了,我們可以認為他們在投票,當票數(shù)達到了一定的次數(shù),那么哨兵就認為該節(jié)點真的掛了,我們成為客觀下線,然后哨兵之間就會選舉,選出一個領(lǐng)頭的哨兵對主從數(shù)據(jù)庫發(fā)起故障的修復(fù)。
哨兵選舉過程
1.第一個發(fā)現(xiàn)該master掛了的哨兵,向每個哨兵發(fā)送命令,讓對方選舉自己成為領(lǐng)頭哨兵 2.其他哨兵如果沒有選舉過他人,就會將這一票投給第一個發(fā)現(xiàn)該master掛了的哨兵 3.第一個發(fā)現(xiàn)該master掛了的哨兵如果發(fā)現(xiàn)由超過一半哨兵投給自己,并且其數(shù)量也超過了設(shè)定的quoram參數(shù),那么該哨兵就成了領(lǐng)頭哨兵 4.如果多個哨兵同時參與這個選舉,那么就會重復(fù)該過程,知道選出一個領(lǐng)頭哨兵
選出領(lǐng)頭哨兵后,就開始了故障修復(fù),會從選出一個從數(shù)據(jù)庫作為新的master
master選舉過程
1.從所有在線的從數(shù)據(jù)庫中,選擇優(yōu)先級最高的從數(shù)據(jù)庫 2.如果有多個優(yōu)先級高的從數(shù)據(jù)庫,那么就會判斷其偏移量,選擇偏移量最小的從數(shù)據(jù)庫,這里的偏移量就是增量復(fù)制的 3.如果還是有相同條件的從數(shù)據(jù)庫,就會選擇運行id較小的從數(shù)據(jù)庫升級為master
cluster集群模式
在redis3.0版本中支持了cluster集群部署的方式,這種集群部署的方式能自動將數(shù)據(jù)進行分片,每個master上放一部分數(shù)據(jù),提供了內(nèi)置的高可用服務(wù),即使某個master掛了,服務(wù)還可以正常地提供,我們先來看張圖:
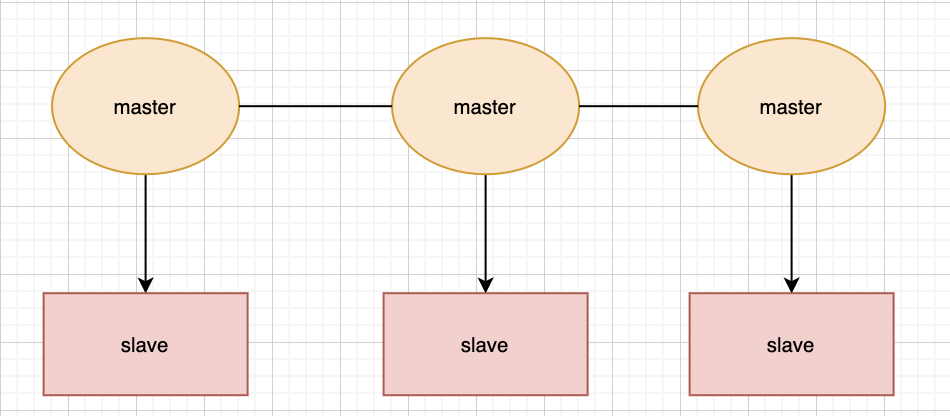
使用cluster集群模式,只需要將每個數(shù)據(jù)庫節(jié)點的cluster-enabled配置選項打開即可,但是每個cluster集群至少要保證有3個主數(shù)據(jù)庫才能正常運行。
cluster集群模式是怎么存放數(shù)據(jù)的?
一個cluster集群中總共有16384個節(jié)點,集群會將這16384個節(jié)點平均分配給每個節(jié)點,當然,我這里的節(jié)點指的是每個主節(jié)點,就如同下圖:
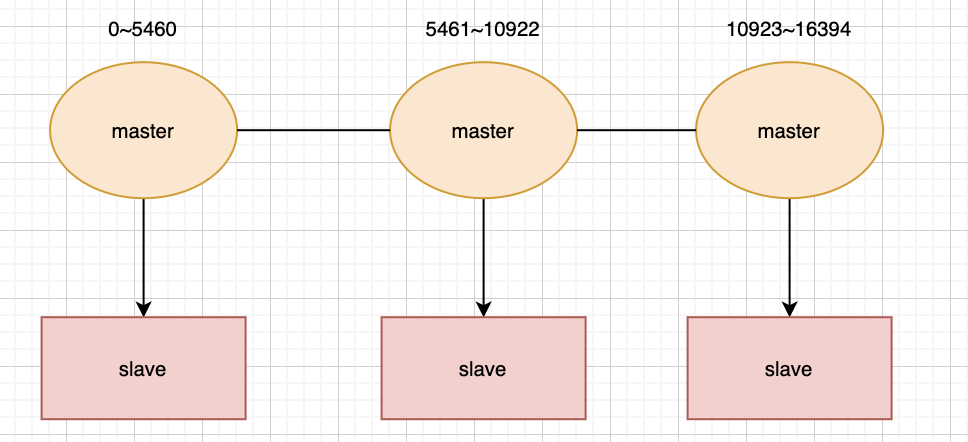
鍵是如何和16384個插槽做關(guān)聯(lián)的?
redis將每個redis的鍵的鍵名有效部分使用CRC16算法計算出散列值,然后與16384取余數(shù),這樣的就可以使每個鍵能夠盡量的均勻分布在16384個插槽中。
插槽是如何和節(jié)點做關(guān)聯(lián)的?
1.插槽之前沒有被分配過,現(xiàn)在想分配給指定節(jié)點 2.插槽之前被分配過,現(xiàn)在想移動指定節(jié)點
第一種情況可以通過cluster add slot s 命令來實現(xiàn)
第二種情況的原理相對麻煩一點,但是redis也提供的便捷的方式去操作,我們可以使用redis-trib.rb去實現(xiàn)
如何獲取與插槽對應(yīng)的節(jié)點?
當客戶端向redis集群中的任意一個節(jié)點發(fā)送命令后,該節(jié)點都會判斷當前鍵的信息是否存在于當前節(jié)點:
如果存在,那么就會像單機的reids一樣執(zhí)行命令。
如果不存在,就會返回一個move重定向請求,告訴客戶端負責(zé)該數(shù)據(jù)的節(jié)點是哪一個,然后客戶端會向該節(jié)點發(fā)送命令再次請求獲取數(shù)據(jù)
新節(jié)點的加入
需要通過cluster meet命令來實現(xiàn):
cluster?meet?ip?port
ip port 是我們已運行的redis集群中任意一個節(jié)點的地址和端口號,新節(jié)點在客戶端輸入命令后,會與命令中的節(jié)點進行握手,握手后,命令中的集群節(jié)點會將這個新節(jié)點的信息分享給集群中的每一個節(jié)點。
故障恢復(fù)
判斷故障的邏輯其實與哨兵模式有點類似,在集群中,每個節(jié)點都會定期的向其他節(jié)點發(fā)送ping命令,通過有沒有收到回復(fù)來判斷其他節(jié)點是否已經(jīng)下線。
如果長時間沒有回復(fù),那么發(fā)起ping命令的節(jié)點就會認為目標節(jié)點疑似下線,也可以和哨兵一樣稱作主觀下線,當然也需要集群中一定數(shù)量的節(jié)點都認為該節(jié)點下線才可以,我們來說說具體過程:
1。當A節(jié)點發(fā)現(xiàn)目標節(jié)點疑似下線,就會向集群中的其他節(jié)點散播消息,其他節(jié)點就會向目標節(jié)點發(fā)送命令,判斷目標節(jié)點是否下線 2.如果集群中半數(shù)以上的節(jié)點都認為目標節(jié)點下線,就會對目標節(jié)點標記為下線,從而告訴其他節(jié)點,讓目標節(jié)點在整個集群中都下線
如何提高redis的讀寫能力
這個問題也是我們之前拋出來的問題,我們放一張圖大家就會很容易明白了:
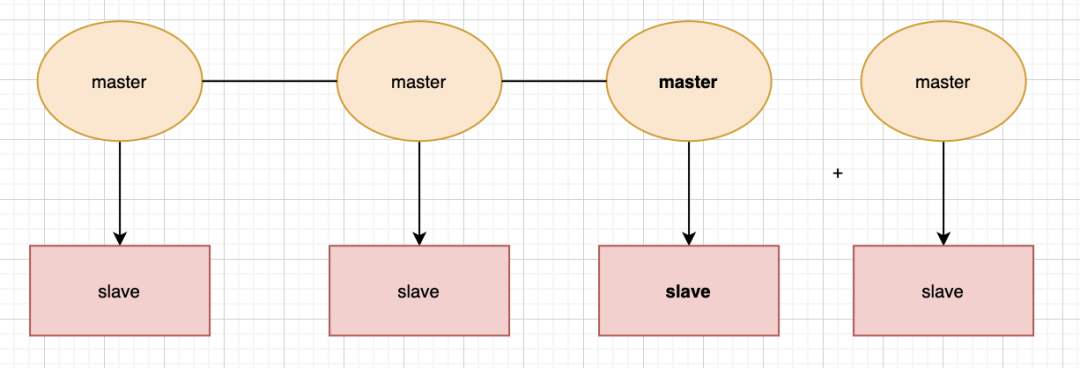
提高寫能力只需要橫向擴容master
提高讀能力只需要橫向擴容slave
結(jié)語
關(guān)于這三種部署的方式,基本上在我知道的公司都毫無疑問直接選擇cluster模式,當然具體的選擇還是要看公司的規(guī)模了,畢竟技術(shù)服務(wù)于業(yè)務(wù),選擇合適于當前業(yè)務(wù)的,就是最好的。
END
有熱門推薦??
最近面試BAT,整理一份面試資料《Java面試BATJ通關(guān)手冊》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
獲取方式:點“在看”,關(guān)注公眾號并回復(fù)?Java?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。
文章有幫助的話,在看,轉(zhuǎn)發(fā)吧。
謝謝支持喲 (*^__^*)
