
你可能用錯了 kafka 的重試機制

來源 | http://r6d.cn/b2u2p
Apache Kafka 已成為跨微服務(wù)異步通信的主流平臺。它有很多強大的特性,讓我們能夠構(gòu)建健壯、有彈性的異步架構(gòu)。
同時,我們在使用它的過程中也需要小心很多潛在的陷阱。如果未能提前發(fā)現(xiàn)可能發(fā)生(換句話說就是遲早會發(fā)生)的問題,我們就要面對一個容易出錯和損壞數(shù)據(jù)的系統(tǒng)了。
在本文中,我們將重點介紹其中的一個陷阱:嘗試處理消息時遭遇失敗。首先,我們需要意識到消息消費可能會,而且遲早會遭遇失敗。其次,我們需要確保在處理此類故障時不會引入更多問題。
Kafka 簡介
閱讀本文的讀者應(yīng)該都對 Kafka 有所了解。網(wǎng)上也有一些介紹 Kafka 及其使用方法的深度文章。話雖如此,我們這里還是先簡要回顧一下對我們的討論很重要的一些概念。
事件日志、發(fā)布者和消費者
Kafka 是用來處理數(shù)據(jù)流的系統(tǒng)。從概念上講,我們可以認(rèn)為 Kafka 包含三個基本組件:
一個事件日志(Event Log),消息會發(fā)布到它這里 發(fā)布者(Publisher),將消息發(fā)布到事件日志 消費者(Consumer),消費(也就是使用)事件日志中的消息

與 RabbitMQ 之類的傳統(tǒng)消息隊列不同,Kafka 由消費者來決定何時讀取消息(也就是說,Kafka 采用了拉取而非推送模式)。每條消息都有一個偏移量(offset),每個消費者都跟蹤(或提交)其最近消費消息的偏移量。這樣,消費者就可以通過這條消息的偏移量請求下一條消息。
主題
事件日志分為幾個主題(topic),每個主題都定義了要發(fā)布給它的消息類型。定義主題是我們這些工程師的責(zé)任,所以我們應(yīng)該記住一些經(jīng)驗法則:
每個主題都應(yīng)描述一個其他服務(wù)可能需要了解的事件。 每個主題都應(yīng)定義每條消息都將遵循的一個唯一模式(schema)。
分區(qū)和分區(qū)鍵
主題被進一步細(xì)分為多個分區(qū)(partition)。分區(qū)使消息可以被并行消費。Kafka 允許通過一個**分區(qū)鍵(partition key)**來確定性地將消息分配給各個分區(qū)。分區(qū)鍵是一段數(shù)據(jù)(通常是消息本身的某些屬性,例如 ID),其上會應(yīng)用一個算法以確定分區(qū)。

這里,我們將消息的 UUID 字段分配為分區(qū)鍵。生產(chǎn)者應(yīng)用一種算法(例如按照分區(qū)數(shù)修改每個 UUID 值)來將每條消息分配給一個分區(qū)。
以這種方式使用分區(qū)鍵,使我們能夠確保與給定 ID 關(guān)聯(lián)的每條消息都會發(fā)布到單個分區(qū)上。
還需要注意的是,可以將一個消費者的多個實例部署為一個消費者組。Kafka 將確保給定分區(qū)中的任何消息將始終由組中的同一消費者實例讀取。
在微服務(wù)中使用 Kafka
Kafka 非常強大。所以它可用于多種環(huán)境中,涵蓋眾多用例。在這里,我們將重點介紹微服務(wù)架構(gòu)中最常見的用法。
跨有界上下文傳遞消息
當(dāng)我們剛開始構(gòu)建微服務(wù)時,我們許多人一開始采用的是某種中心化模式。每條數(shù)據(jù)都有一個駐留的單一微服務(wù)(即單一真實來源)。如果其他任何微服務(wù)需要訪問這份數(shù)據(jù),它將發(fā)起一個同步調(diào)用以檢索它。
這種方法導(dǎo)致了許多問題,包括同步調(diào)用鏈較長、單點故障、團隊自主權(quán)下降等。
最后我們找到了更好的辦法。在今天的成熟架構(gòu)中,我們將通信分為命令處理和事件處理。
命令處理通常在單個有界上下文中執(zhí)行,并且往往還是會包含同步通信。
另一方面,事件通常由一個有界上下文中的服務(wù)發(fā)出,并異步發(fā)布到 Kafka,以供其他有界上下文中的服務(wù)消費。
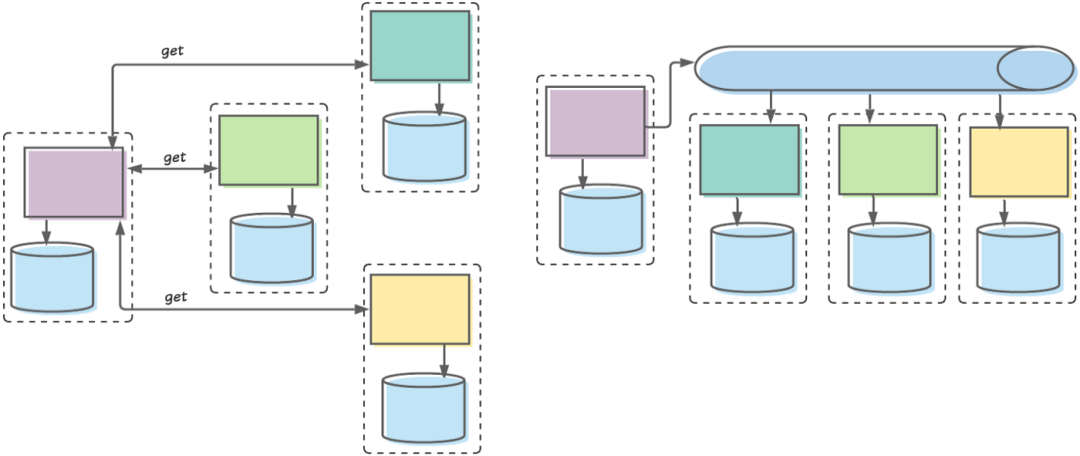
左側(cè)是我們以前設(shè)計微服務(wù)通信的方式:一個有界上下文(由虛線框表示)中的服務(wù)從其他有界上下文中的服務(wù)接收同步調(diào)用。右邊是我們?nèi)缃竦淖龇ǎ阂粋€有界上下文中的服務(wù)發(fā)布事件,其他有界上下文中的服務(wù)在自己空閑時消費它們。
例如,以一個 User 有界上下文為例。我們的 User 團隊會構(gòu)建負(fù)責(zé)啟用新用戶、更新現(xiàn)有用戶帳戶等任務(wù)的應(yīng)用程序和服務(wù)。
創(chuàng)建或修改用戶帳戶后,UserAccount 服務(wù)會將一個相應(yīng)的事件發(fā)布到 Kafka。其他感興趣的有界上下文可以消費該事件,將其存儲在本地,使用其他數(shù)據(jù)增強它,等等。例如,我們的 Login 有界上下文可能想知道用戶的當(dāng)前名稱,以便在登錄時向他們致意。
 把 14 億人都拉到一個微信群,在技術(shù)上能實現(xiàn)嗎?
把 14 億人都拉到一個微信群,在技術(shù)上能實現(xiàn)嗎?
我們將這種用例稱為跨邊界事件發(fā)布。
在執(zhí)行跨邊界事件發(fā)布時,我們應(yīng)該發(fā)布聚合(Aggregate)。聚合是自包含的實體組,每個實體都被視為一個單獨的原子實體。每個聚合都有一個“根”實體,以及一些提供附加數(shù)據(jù)的從屬實體。
當(dāng)管理聚合的服務(wù)發(fā)布一條消息時,該消息的負(fù)載將是一個聚合的某種表示形式(例如 JSON 或 Avro)。重要的是,該服務(wù)將指定聚合的唯一標(biāo)識符作為分區(qū)鍵。這將確保對任何給定聚合實體的更改都將發(fā)布到同一分區(qū)。
出問題的時候怎么辦?
盡管 Kafka 的跨邊界事件發(fā)布機制顯得相當(dāng)優(yōu)雅,但畢竟這是一個分布式系統(tǒng),因此系統(tǒng)可能會有很多錯誤。我們將關(guān)注也許是最常見的惱人問題:消費者可能無法成功處理其消費的消息。
 霸榜GitHubTrending的設(shè)計模式教程出紙質(zhì)書啦
霸榜GitHubTrending的設(shè)計模式教程出紙質(zhì)書啦
我們現(xiàn)在該怎么辦?
確定這是一個問題
團隊做錯的第一件事就是根本沒有意識到這是一個潛在的問題。消息失敗時有發(fā)生,我們需要制定一種策略來處理它……要未雨綢繆,而非亡羊補牢。
因此,了解這是一種遲早會發(fā)生的問題并設(shè)計針對性的解決方案是我們要做的第一步。如果我們做到了這一點,就應(yīng)該向自己表示一點祝賀。現(xiàn)在最大的問題仍然存在:我們該如何處理這種情況?
我們不能一直重試那條消息嗎?
默認(rèn)情況下,如果消費者沒有成功消費一條消息(也就是說消費者無法提交當(dāng)前偏移量),它將重試同一條消息。那么,難道我們不能簡單地讓這種默認(rèn)行為接管一切,然后重試消息直到成功嗎?
問題是這條消息可能永遠(yuǎn)不會成功。至少,沒有某種形式的手動干預(yù)它是不會成功的。于是乎,消費者就永遠(yuǎn)不會繼續(xù)處理后續(xù)的任何消息,并且我們的消息處理將陷入困境。
好吧,我們不能簡單地跳過那條消息嗎?
我們通常允許同步請求失敗。例如,對我們的 UserAccount 服務(wù)所做的一個“create-user”POST 可能包含錯誤或丟失的數(shù)據(jù)。在這種情況下,我們可以簡單地返回一個錯誤代碼(例如 HTTP 400),然后要求調(diào)用方重試。
雖然這種辦法并不不理想,但這不會對我們的數(shù)據(jù)完整性造成任何長期問題。那個 POST 代表一條命令,是還沒有發(fā)生的事情。即使我們讓它失敗,我們的數(shù)據(jù)也將保持一致狀態(tài)。
當(dāng)我們丟棄消息時情況并非如此。消息表示已經(jīng)發(fā)生的事件。任何忽略這些事件的消費者都將與生成事件的上游服務(wù)不再同步。
所有這些都表明,我們不想丟棄消息。
那么我們?nèi)绾谓鉀Q這個問題呢?
對我們來說這不是什么容易解決的問題。因此,一旦我們認(rèn)識到它需要解決,就可以向互聯(lián)網(wǎng)咨詢解決方案。但這引出了我們的第二個問題:網(wǎng)上有一些我們可能不應(yīng)該遵循的建議。
重試主題:流行的解決方案
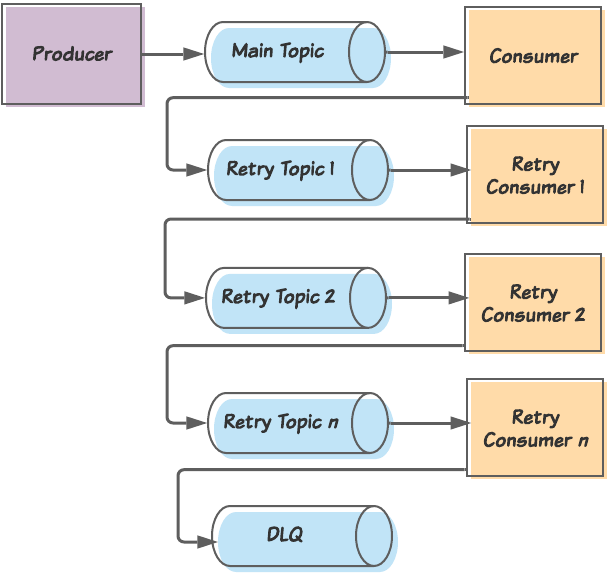
你會發(fā)現(xiàn)最受歡迎的一種解決方案就是重試主題(retry topics)的概念。具體細(xì)節(jié)因?qū)崿F(xiàn)而異,但總體概念是這樣的:
消費者嘗試消費主要主題中的一條消息。 如果未能正確消費該消息,則消費者將消息發(fā)布到第一個重試主題,然后提交消息的偏移量,以便繼續(xù)處理下一條消息。 訂閱重試主題的是重試消費者,它包含與主消費者相同的邏輯。該消費者在消息消費嘗試之間引入了短暫的延遲。如果這個消費者也無法消費該消息,則會將該消息發(fā)布到另一個重試主題,并提交該消息的偏移量。 這一過程繼續(xù),并增加了一些重試主題和重試消費者,每個重試的延遲越來越多(用作退避策略)。最后,在最終重試消費者無法處理某條消息后,該消息將發(fā)布到一個死信隊列(Dead Letter Queue,DLQ)中,工程團隊將在該隊列中對其進行手動分類。
 TiDB 在知乎萬億量級業(yè)務(wù)數(shù)據(jù)下的實踐和挑戰(zhàn)
TiDB 在知乎萬億量級業(yè)務(wù)數(shù)據(jù)下的實踐和挑戰(zhàn)
概念上講,重試主題模式定義了失敗的消息將被分流到的多個主題。如果主要主題的消費者消費了它無法處理的消息,它會將該消息發(fā)布到重試主題 1 并提交當(dāng)前偏移量,從而將自身釋放給下一條消息。重試主題的消費者將是主消費者的副本,但如果它無法處理該消息,它將發(fā)布到一個新的重試主題。最終,如果最后一個重試消費者也無法處理該消息,它將把該消息發(fā)布到一個死信隊列(DLQ)。
問題出在哪里?
看起來這種方法似乎很合理。實際上,它在許多用例中都能正常工作。問題在于它不能充當(dāng)一種通用解決方案。現(xiàn)實中存在一些特殊用例(例如我們的跨邊界事件發(fā)布),對于這些用例來說,這種方法實際上是危險的。
它忽略了不同類型的錯誤
第一個問題是,它沒有考慮到導(dǎo)致事件消費失敗的兩大原因:可恢復(fù)錯誤和不可恢復(fù)錯誤。
可恢復(fù)錯誤指的是,如果我們多次重試,這些錯誤最終將得以解決。一個簡單的示例是將數(shù)據(jù)保存到數(shù)據(jù)庫的消費者。如果數(shù)據(jù)庫暫時不可用,那么當(dāng)下一條消息通過時,消費者將失敗。一旦數(shù)據(jù)庫再次變得可用,消費者就能夠再次處理該消息。
從另一個角度來看:可恢復(fù)錯誤指的是那些根源在消息和消費者外部的錯誤。解決這種錯誤后,我們的消費者將繼續(xù)前進,好像無事發(fā)生一樣。(很多人在這里被弄糊涂了。“可恢復(fù)”一詞并不意味著應(yīng)用程序本身——在我們的示例中為消費者——可以恢復(fù)。相反,它指的是某些外部資源——在此示例中為數(shù)據(jù)庫——會失敗并最終恢復(fù)。)
關(guān)于可恢復(fù)錯誤需要注意的是,它們將困擾主題中的幾乎每一條消息。回想一下,主題中的所有消息都應(yīng)遵循相同的架構(gòu),并代表相同類型的數(shù)據(jù)。同樣,我們的消費者將針對該主題的每個事件執(zhí)行相同的操作。因此,如果消息 A 由于數(shù)據(jù)庫中斷而失敗,那么消息 B、消息 C 等也將失敗。
不可恢復(fù)錯誤指的是無論我們重試多少次都將失敗的錯誤。例如,消息中缺少字段可能會導(dǎo)致一個 NullPointerException,或者包含特殊字符的字段可能會使消息無法解析。
與可恢復(fù)錯誤不同,不可恢復(fù)錯誤通常會影響單個孤立消息。例如,如果只有消息 A 包含不可解析的特殊字符,則消息 B 將成功,消息 C 等也將成功。
與可恢復(fù)錯誤不同,解決不可恢復(fù)錯誤意味著我們必須修復(fù)消費者本身(永遠(yuǎn)不要“修復(fù)”消息本身——它們是不可變的記錄!)例如,我們可能會修復(fù)消費者以便正確處理空值,然后重新部署它。
那么,這與重試主題解決方案有什么關(guān)系?
對于初學(xué)者來說,它對可恢復(fù)錯誤不是特別有用。請記住,在解決外部問題之前,可恢復(fù)錯誤將影響每一條消息,而不僅僅是當(dāng)前的一條消息。因此可以肯定的是,將失敗的消息分流到重試主題將為下一條消息清理出通道。但接下來的消息也將失敗,下一條以及再下一條也將失敗。我們最好還是讓消費者自己重試,直到問題解決為止。
不可恢復(fù)的錯誤呢?重試隊列可以在這些情況下提供幫助。如果一條麻煩的消息阻止了所有后續(xù)消息的消費,那么毫無疑問,分流該消息肯定會為我們的用戶消費清除障礙(當(dāng)然,多個重試主題是沒必要的)。
但是,雖然重試隊列可以幫助受不可恢復(fù)錯誤困擾的消息消費者繼續(xù)前進,但它也可能帶來更多隱患。下面我們就進一步分析背后的原因。
它會忽略排序
我們簡要回顧一下跨邊界事件發(fā)布的一些重要環(huán)節(jié)。在有界上下文中處理一條命令后,我們會將一個對應(yīng)的事件發(fā)布到一個 Kafka 主題。重要的是,我們會將聚合的 ID 指定為分區(qū)鍵。
為什么這很重要?它確保的是對任何給定聚合的更改都會發(fā)布到同一分區(qū)。
好吧,那這一點為什么會那么重要呢?當(dāng)事件發(fā)布到同一分區(qū)時,可以保證各個事件按照它們發(fā)生的順序進行處理。如果對同一聚合進行連續(xù)更改,并且所產(chǎn)生的事件發(fā)布到不同的分區(qū),就可能發(fā)生爭用狀況,也就是消費者在消費第一個更改之前就消費了第二個更改。這會導(dǎo)致數(shù)據(jù)不一致。
我們舉個簡單的例子。我們的 User 有界上下文提供了一個允許用戶更改其名稱的應(yīng)用程序。一位用戶將他的名字從 Zoey 更改為 Zo?,然后立即又更改為 Zoiee。如果我們不管排序,則某個下游消費者(例如 Login 有界上下文)可能會先處理對 Zoiee 的更改,然后不久用 Zo?覆蓋它。
現(xiàn)在,登錄數(shù)據(jù)與我們的用戶數(shù)據(jù)已經(jīng)不同步了。更麻煩的是,每當(dāng) Zoiee 登錄我們的網(wǎng)站時都會看到“歡迎光臨,Zo?!”的登錄提示。
這才是重試主題真正出問題的地方。它們讓我們的消費者容易打亂處理事件的順序。如果一個消費者在處理 Zo?更改時受到某個臨時的數(shù)據(jù)庫中斷的影響,它會把這個消息分流到一個重試主題,稍后再嘗試。如果在 Zoiee 更改到達(dá)時數(shù)據(jù)庫中斷已得到糾正,則這條消息將先被成功處理,然后再由 Zo?更改覆蓋。
為了說明問題,這里用了 Zoiee/Zo?這樣一個簡單的示例。實際上,亂序處理事件可能導(dǎo)致會各種各樣的數(shù)據(jù)損壞問題。更糟糕的是,這些問題很少會在一開始就被注意到。相反,它們所導(dǎo)致的數(shù)據(jù)損壞往往在一段時間內(nèi)都不會引起注意,但損壞程度會隨著時間的推移而增長。一般來說,當(dāng)我們意識到發(fā)生了什么事情時,已經(jīng)有大量數(shù)據(jù)受到影響了。
重試主題什么時候可行?
需要明確的是,重試主題并非一直都是錯誤的模式。當(dāng)然,它也存在一些合適的用例。具體來說,當(dāng)消費者的工作是收集不可修改的記錄時,這種模式就很不錯。這樣的例子可能包括:
處理網(wǎng)站活動流以生成報告的消費者 將交易添加到分類賬的消費者(只要這些交易用不著按特定順序跟蹤) 正在從另一個數(shù)據(jù)源 ETL 數(shù)據(jù)的消費者
這類消費者可能會從重試主題模式中受益,同時沒有數(shù)據(jù)損壞的風(fēng)險。
不過,請注意
即使存在這種用例,我們?nèi)詰?yīng)謹(jǐn)慎行事。構(gòu)建這樣的解決方案既復(fù)雜又耗時。因此,作為一個組織,我們不想為每個新的消費者編寫一個新的解決方案。相反,我們要創(chuàng)建一個統(tǒng)一的解決方案,比如一個庫或一個容器等,可以在各種服務(wù)之間重復(fù)使用。
還存在另一個問題。我們可能會為相關(guān)消費者構(gòu)建一個重試主題的解決方案。不幸的是,不久之后,這個解決方案就會進入跨邊界事件發(fā)布消費者的領(lǐng)域了。擁有這些消費者的團隊可能沒有意識到風(fēng)險的存在。正如我們前面所討論的那樣,在發(fā)生重大數(shù)據(jù)損壞之前,他們可能不會意識到任何問題。
因此,在實現(xiàn)重試主題解決方案之前,我們應(yīng) 100%確定:
我們的業(yè)務(wù)中永遠(yuǎn)不會有消費者來更新現(xiàn)有數(shù)據(jù),或者 我們擁有嚴(yán)格的控制措施,以確保我們的重試主題解決方案不會在此類消費者中實現(xiàn)
我們?nèi)绾胃纳七@種模式?
鑒于重試主題模式可能不是跨邊界事件發(fā)布消費者的可接受解決方案,我們是否可以對其做一些調(diào)整來改善它呢?
一開始,本文想要提供一種完整的解決方案。但之后我意識到,并不存在什么萬能的路徑。因此,我們將只討論一些在制定合適解決方案時需要考慮的事項。
消除錯誤類型
如果我們能夠在可恢復(fù)錯誤和不可恢復(fù)錯誤之間消除歧義,生活就會變得輕松許多。例如,如果我們的消費者開始遇到可恢復(fù)錯誤,那么重試主題就變得多余了。
因此,我們可以嘗試確定所遇到的錯誤類型:
void processMessage(KafkaMessage km) {
try {
Message m = km.getMessage();
transformAndSave(m);
} catch (Throwable t) {
if (isRecoverable(t)) {
// ...
} else {
// ...
}
}
}
在上面的 Java 偽代碼示例中,isRecoverable()將采用一種白名單方法來確定 t 是否表示可恢復(fù)錯誤。換句話說,它檢查 t 以確定它是否與任何已知的可恢復(fù)錯誤(例如 SQL 連接錯誤或 ReST 客戶端超時)相匹配,如果匹配則返回 true,否則返回 false。這樣就能防止我們的消費者被不可恢復(fù)錯誤一直阻塞下去。
誠然,要在可恢復(fù)錯誤和不可恢復(fù)錯誤之間消除歧義可能很困難。例如,一個 SQLException 可能指的是一次數(shù)據(jù)庫故障(可恢復(fù))或一次約束違反狀況(不可恢復(fù))。如有疑問,我們可能應(yīng)該假設(shè)錯誤是不可恢復(fù)的——為此要冒的風(fēng)險是將其他好的消息發(fā)送給隱藏主題,從而延遲它們的處理……但這也能避免我們無意間陷入泥潭,無休止地嘗試處理不可恢復(fù)錯誤。
在消費者內(nèi)重試可恢復(fù)錯誤
正如我們所討論的那樣,存在可恢復(fù)錯誤時,將消息發(fā)布到重試主題毫無意義。我們只會為下一條消息的失敗掃清道路。相反,消費者可以簡單地重試,直到條件恢復(fù)。
當(dāng)然,出現(xiàn)可恢復(fù)錯誤意味著外部資源存在問題。我們不斷對這塊資源發(fā)送請求是無濟于事的。因此,我們希望對重試應(yīng)用一個退避策略。我們的偽 Java 代碼現(xiàn)在可能看起來像這樣:
void processMessage(KafkaMessage km) {
try {
Message m = km.getMessage();
transformAndSave(m);
} catch (Throwable t) {
if (isRecoverable(t)) {
doWithRetry(m, Backoff.EXPONENTIAL, this::transformAndSave);
} else {
// ...
}
}
}
(注意:我們使用的任何退避機制都應(yīng)配置為在達(dá)到某個閾值時向我們發(fā)出警報,并通知我們潛在的嚴(yán)重錯誤)
遇到不可恢復(fù)錯誤時,將消息直接發(fā)送到最后一個主題
另一方面,當(dāng)我們的消費者遇到不可恢復(fù)錯誤時,我們可能希望立即隱藏(stash)該消息,以釋放后續(xù)消息。但在這里使用多個重試主題會有用嗎?答案是否定的。在轉(zhuǎn)到 DLQ 之前,我們的消息只會經(jīng)歷 n 次消費失敗而已。那么,為什么不從一開始就將消息粘貼在那里呢?
與重試主題一樣,這個主題(在這里,我們將其稱為隱藏主題)將擁有自己的消費者,其與主消費者保持一致。但就像 DLQ 一樣,這個消費者并不總是在消費消息;它只有在我們明確需要時才會這么做。
考慮排序
來看看排序的情況。我們在這里重用之前的“用戶/登錄”示例。嘗試處理 Zo?名稱中的?字符時,Login 消費者可能會遇到錯誤。消費者將其識別為一個不可恢復(fù)錯誤,將消息放在一邊,然后繼續(xù)處理后續(xù)消息。不久之后,消費者將獲得 Zoiee 消息并成功處理它。
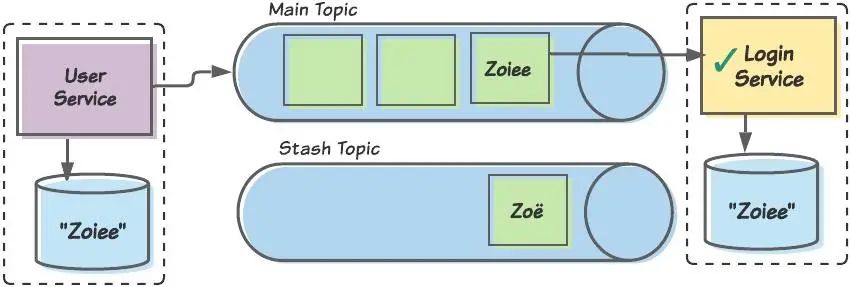
Zo?消息已隱藏,并且 Zoiee 消息現(xiàn)在已成功處理完畢。目前,兩個有界上下文之間的數(shù)據(jù)是一致的。
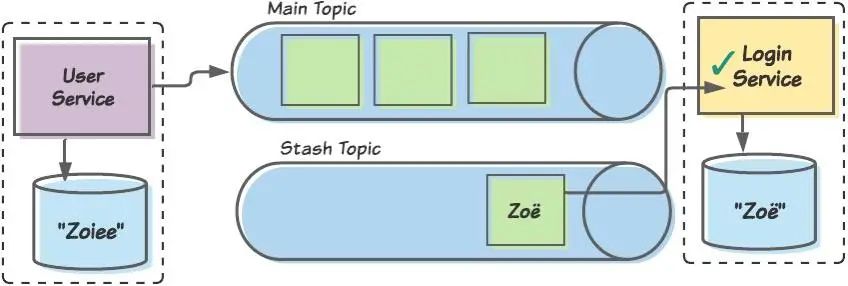
晚些時候,我們的團隊會修復(fù)消費者,以便其可以正確處理特殊字符并重新部署它。然后,我們將 Zo?消息重新發(fā)布給消費者,消費者現(xiàn)在可以正確處理該消息了。
 注意!Apache下這些與Hadoop相關(guān)的開源項目要退休了!
注意!Apache下這些與Hadoop相關(guān)的開源項目要退休了!
當(dāng)更新的消費者隨后處理隱藏的 Zo?消息后,兩個有界上下文之間的數(shù)據(jù)將變得不一致。因此,當(dāng) User 有界上下文將用戶視為 Zoiee 時,Login 有界上下文會將她稱為 Zo?。
顯然,我們沒有保持排序;Zo?是在 Zoiee 之前由 Login 消費者處理的,但正確的順序是倒過來的。隱藏一條消息后,我們可以開始隱藏所有消息,但在那種情況下我們實際上會陷入困境。幸運的是,我們不需要保持所有消息的順序,只需考慮與單個聚合相關(guān)聯(lián)的消息即可。因此,如果我們的消費者可以跟蹤已隱藏的特定聚合,它就可以確保屬于同一聚合的后續(xù)消息也被隱藏。
收到隱藏主題中消息的警報后,我們可以取消部署消費者并修復(fù)其代碼(請注意:切勿修改消息本身;消息代表不可變的事件!)在修復(fù)并測試了我們的消費者之后,我們可以重新部署它。當(dāng)然,在繼續(xù)使用主要主題之前,我們將需要特別注意先處理隱藏主題中的所有記錄。這樣,我們將繼續(xù)保持正確的排序狀態(tài)。出于這個原因,我們將首先部署隱藏消費者,并且只有在其完成時(這意味著消費者組中的所有實例都完成,如果我們使用了多個消費者),我們才會取消部署它并部署主消費者。
我們還應(yīng)該考慮以下事實:固定的消費者處理了隱藏消息后,它仍可能會遇到其他錯誤。在這種情況下,其錯誤處理行為應(yīng)像我們之前描述的那樣:
如果錯誤是可恢復(fù)的,則使用退避策略重試; 如果錯誤是不可恢復(fù)的,它將隱藏消息并繼續(xù)下一條消息。
為此,我們可以考慮使用第二個隱藏主題。
可以接受一些數(shù)據(jù)不一致?
這樣的系統(tǒng)構(gòu)建起來可能會變得相當(dāng)復(fù)雜。它們可能很難構(gòu)建、測試和維護。因此,某些組織可能會想要確定出數(shù)據(jù)不一致的可能性,并判斷他們是否可以承受這種風(fēng)險。
在許多情況下,這些組織可能會采用數(shù)據(jù)協(xié)調(diào)機制,以使他們的數(shù)據(jù)最終(是相對較長的“最終”)變得一致。為此也存在許多策略(超出了本文的范圍)。
總結(jié)
處理重試似乎很復(fù)雜,那是因為它就是這么麻煩——和一切正常時 Kafka 相對優(yōu)雅的風(fēng)格相比之下尤其明顯。我們構(gòu)建的任何合適的解決方案(無論是重試主題、隱藏主題還是其他解決方案)都將比我們想要的更復(fù)雜。
不幸的是,如果我們希望在微服務(wù)之間建立彈性的異步通信流,那么我們就不能忽略它。
本文介紹了一種流行的解決方案、它的缺點以及在設(shè)計替代解決方案時應(yīng)考慮的一些事項。到最后,想要構(gòu)建正確的解決方案,我們就應(yīng)該牢記一些事情,例如:
了解 Kafka 通過主題、分區(qū)和分區(qū)鍵提供的功能。 考慮到可恢復(fù)錯誤與不可恢復(fù)錯誤之間的差異。 設(shè)計模式的用法,例如有界上下文和聚合。 無論現(xiàn)在還是將來,都要搞清楚我們組織的用例特性。我們只是在移動獨立的記錄嗎?……在這種情況下,我們可能不關(guān)心排序;還是說我們正在傳播表示數(shù)據(jù)更改的事件?……在這種情況下,排序至關(guān)重要。 仔細(xì)考慮我們是否愿意承受任何水平的數(shù)據(jù)不一致。
參考資料
https://dzone.com/articles/creating-apache-kafka-topics-dynamically-as-part-o https://quarkus.io/blog/kafka-failure-strategy/ https://eng.uber.com/reliable-reprocessing/ https://jaceklaskowski.gitbooks.io/apache-kafka/content/kafka-topics.html https://www.red-gate.com/simple-talk/sql/bi/reconciling-data-across-systems-using-reconciliation-hub/
往期推薦
Spring For All社區(qū)3.0開始測試?yán)玻?/span>
學(xué)習(xí)的路上不孤單,快來注冊分享與交流吧!
點擊閱讀原文直達(dá)新版社區(qū)