
Apache Kylin 在貝殼找房指標(biāo)體系的應(yīng)用
引言
Apache Kylin 在貝殼找房的發(fā)展歷程

2017 年 3 月,Kylin 1.6 版本上線
隨著指標(biāo)平臺的上線,Kylin 開始對外提供服務(wù)。
2017 年底,貝殼已經(jīng)累計創(chuàng)建了 300 + Cube,每天有 20 多萬的查詢量
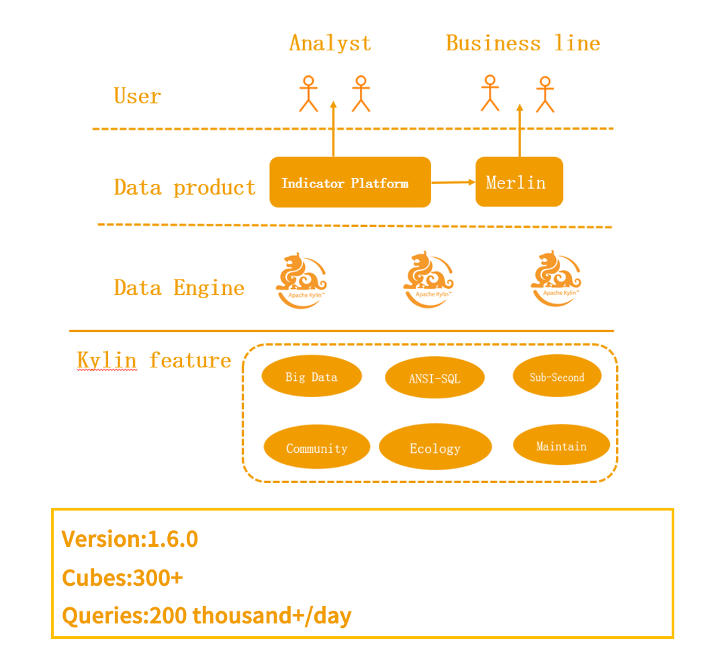
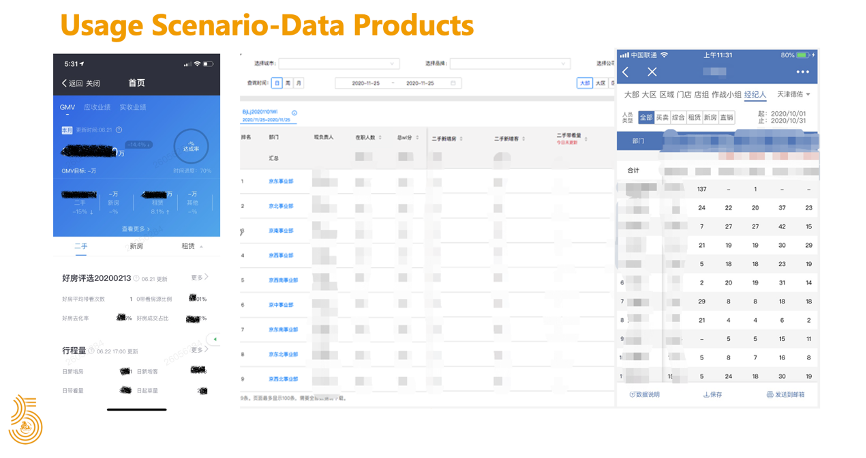
2018 年初,隨著指標(biāo)在各業(yè)務(wù)線的推廣,有越來越多的數(shù)據(jù)產(chǎn)品開始接入 Kylin
例如像 Merlin、Turing 等數(shù)據(jù)產(chǎn)品,這些產(chǎn)品從PC端到手機(jī)端覆蓋的范圍非常廣泛,涉及到公司組織架構(gòu)的各個層級,都有相應(yīng)的數(shù)據(jù)需求。同時為了保障重點數(shù)據(jù)的產(chǎn)出和查詢,我們又部署了一套集群來給重點業(yè)務(wù)使用。
2018 年底,貝殼一共有 2 套集群,累計創(chuàng)建了 600+ Cube,每天的查詢量達(dá)到了 200 萬。

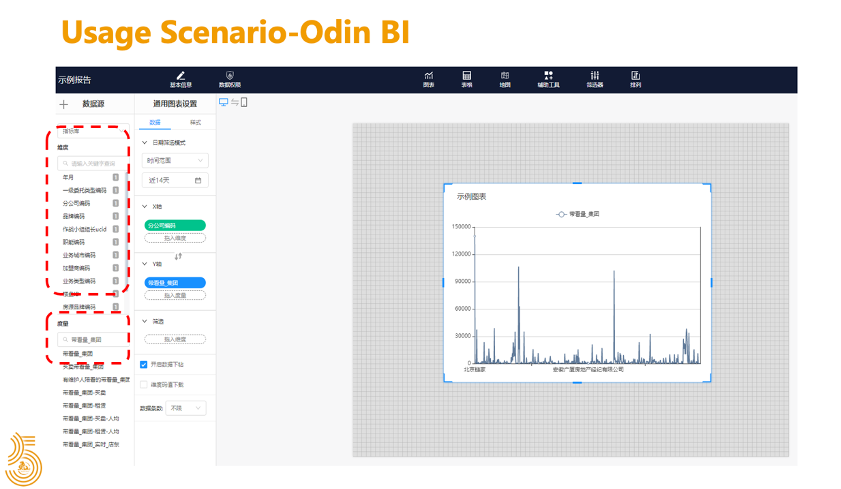
2019 年初,我們 Kylin Team 定下了兩個 KPI,在機(jī)制方面要保障重點數(shù)據(jù)在每天上午 9 點之前產(chǎn)出,在查詢上要達(dá)成 3 秒鐘內(nèi)響應(yīng)占比 99.7%,將 Kylin 升級到 3.1 版本,主要來做實時多維分析的應(yīng)用。

為了達(dá)成這兩個目標(biāo),在計算方面我們把集群從 1.6.0升級到 2.5.2,引入了 Spark 組件,將重點 Cube 構(gòu)建的方式從 MR 改為了 Spark。
上圖是調(diào)優(yōu)前后的對比,重點 Cube 的平均構(gòu)建時間從 70 分鐘降到了 43 分鐘,近 40% 左右的提升;在查詢方面也通過一系列的優(yōu)化,在 12 月就達(dá)成了 3 秒內(nèi)占比 99.7% 的目標(biāo)。
下圖是當(dāng)時每天的統(tǒng)計數(shù)據(jù),到 19 年底貝殼還是兩套集群,版本是 2.5.2,累計 700+ Cubes,每天的查詢量超過了 1000 萬。

2020年初,Kylin 升級到 3.1.0,引入了 Flink 組件。
下圖是公司的一級指標(biāo)使用 Flink 組件前后花費時間的對比,可以看到提升比較明顯,截止到 2020 年底,貝殼有兩個3.1的集群,累計 800+ Cubes,每天的查詢量最高超過了 2300 萬。
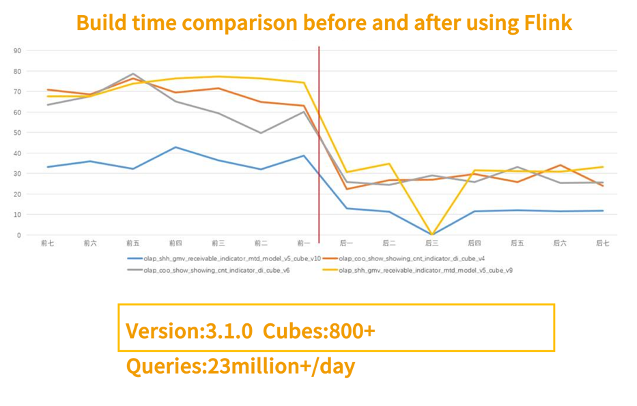
使用 Flink 前后的構(gòu)建時長對比
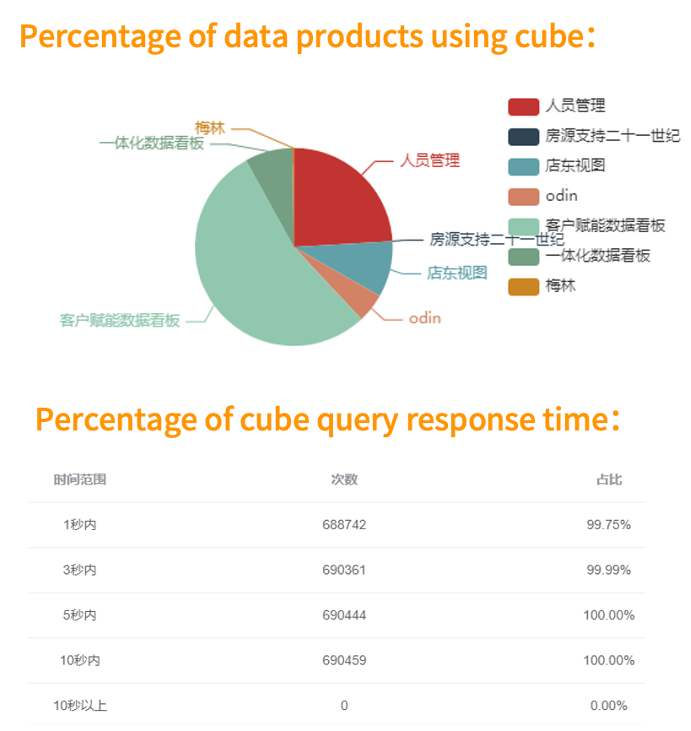
Cube 被使用最多的維度組合排行
Cube 查詢慢的組合排行
最近 30 天都沒有用到過的維度


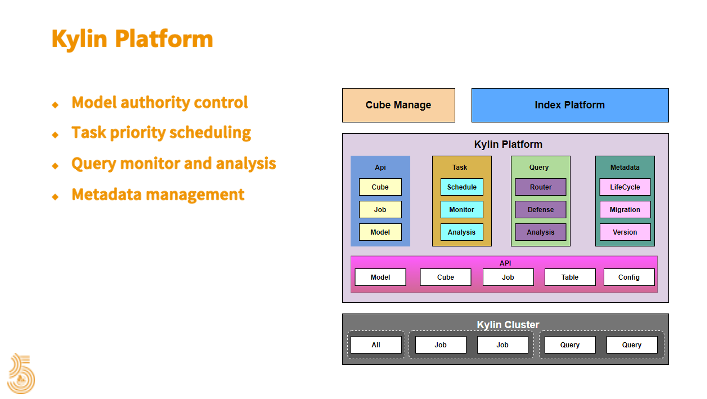
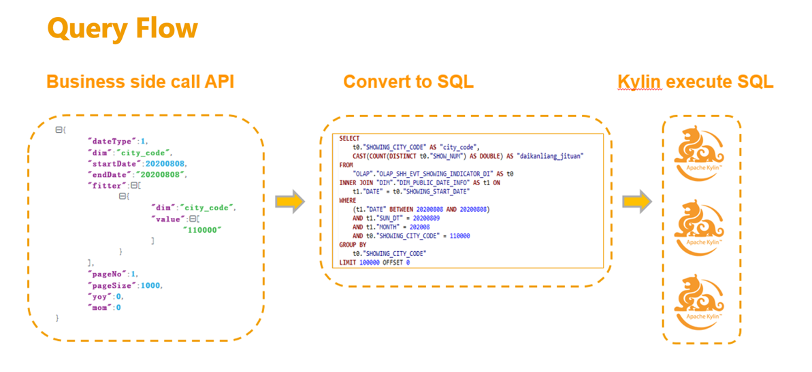
Kylin 在貝殼找房指標(biāo)體系建設(shè)過程中的作用



對 Kylin 未來發(fā)展的展望
作者介紹