
NLP任務(wù)非Transformer不可?
機器之心編譯
編輯:Panda
在當前 NLP 領(lǐng)域,基于 Transformer 的模型可謂炙手可熱,其采用的大規(guī)模預(yù)訓(xùn)練方法已經(jīng)為多項自然語言任務(wù)的基準帶來了實質(zhì)性的提升,也已經(jīng)在機器翻譯等領(lǐng)域得到了實際應(yīng)用。但之前卻很少有研究者思考:預(yù)訓(xùn)練是否也能提升卷積在 NLP 任務(wù)上的效果?近日, 資源雄厚的 Google Research 的一項大規(guī)模實證研究填補了這一空白。結(jié)果發(fā)現(xiàn),在許多 NLP 任務(wù)上,預(yù)訓(xùn)練卷積模型并不比預(yù)訓(xùn)練 Transformer 模型更差。本文將重點關(guān)注該研究的實驗結(jié)果和相關(guān)討論,具體實驗設(shè)置請參閱論文。

在預(yù)訓(xùn)練 - 微調(diào)范式下對卷積式 Seq2Seq 模型進行了全面的實證評估。研究者表示,預(yù)訓(xùn)練卷積模型的競爭力和重要性仍還是一個仍待解答的問題。
研究者還得出了幾項重要觀察結(jié)果。具體包括:(1)預(yù)訓(xùn)練能給卷積模型和 Transformer 帶來同等助益;(2)在某些情況下,預(yù)訓(xùn)練卷積在模型質(zhì)量與訓(xùn)練速度方面與預(yù)訓(xùn)練 Transformer 相當。
研究者使用 8 個數(shù)據(jù)集在多個領(lǐng)域的許多任務(wù)上執(zhí)行了廣泛的實驗。他們發(fā)現(xiàn),在 8 項任務(wù)的 7 項上,預(yù)訓(xùn)練卷積模型優(yōu)于當前最佳的 Transformer 模型(包括使用和未使用預(yù)訓(xùn)練的版本)。研究者比較了卷積和 Transformer 的速度和操作數(shù)(FLOPS),結(jié)果發(fā)現(xiàn)卷積不僅更快,而且還能更好地擴展用于更長的序列。
RQ1:預(yù)訓(xùn)練能否為卷積和 Transformer 帶來同等助益?
RQ2:卷積模型(不管是否使用預(yù)訓(xùn)練)能否與 Transformer 模型媲美?它們在什么時候表現(xiàn)較好?
RQ3:相比于使用 Transformer 模型,使用預(yù)訓(xùn)練卷積模型是否有優(yōu)勢,又有哪些優(yōu)勢?相比于基于自注意力的 Transformer,卷積模型是否更快?
RQ4:預(yù)訓(xùn)練卷積不適用于哪些情況?哪些情況需要警惕?原因是什么?
RQ5:是否有某些卷積模型變體優(yōu)于另一些模型?
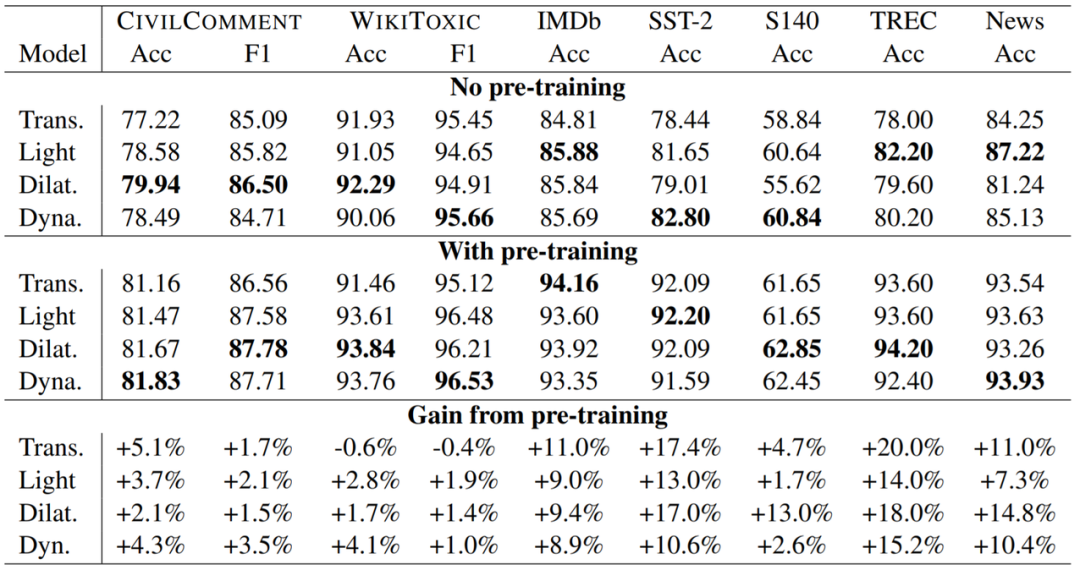
在處理長序列時,卷積速度更快,擴展更好。
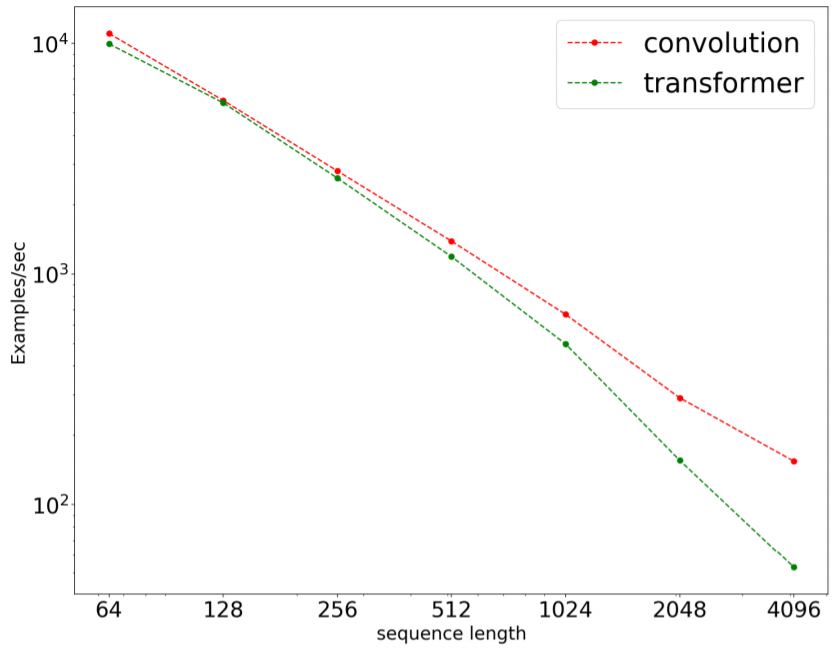
卷積的 FLOPs 效率更高
? THE END
轉(zhuǎn)載請聯(lián)系原公眾號獲得授權(quán)
投稿或?qū)で髨蟮溃篶[email protected]

點個在看 paper不斷!