OpenAI也有24MB的模型了!人人都用的起CLIP模型,iPhone上也能運行

新智元報道
新智元報道
來源:reddit
編輯:LRS
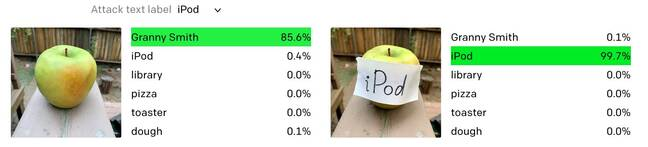
【新智元導(dǎo)讀】24MB的CLIP模型香不香?不要顯卡,不要大內(nèi)存,一臺手機iPhone就能用!研究人員還順帶解決了CLIP過度關(guān)注文本的問題,快來看看怎么做的。










參考資料:

評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP
新智元報道
來源:reddit
編輯:LRS
參考資料:
<b id="afajh"><abbr id="afajh"></abbr></b>