
數(shù)據(jù)庫索引設(shè)計(jì)(基礎(chǔ)篇)
點(diǎn)擊藍(lán)色“有關(guān)SQL”關(guān)注我喲
加個(gè)“星標(biāo)”,天天與10000人一起快樂成長

索引在數(shù)據(jù)庫中,毋庸置疑扮演了極其重要的角色。
在這篇文章中,我們即將要討論這些和索引相關(guān)的事情:
優(yōu)化器是如何選擇索引的;
應(yīng)該如何正確的建立索引;
如何判斷優(yōu)化器選擇了正確的索引;
如何找出哪些已經(jīng)不再被使用的索引;
簡介:
索引可以幫助查詢更快的定位到所需的記錄上,從而避免整表掃描。如果索引引用的列,可以完全包含查詢所需的字段,這類索引叫做 覆蓋索引(convering index),完全不用回讀(針對非聚集索引表)便可滿足查詢需求。一些常規(guī)需求,比如排序,分組和 distinct 都可以有效利用索引。
這里有個(gè)概念特別要注意,回讀。官方給出的正式名稱,叫做 bookmark lookup. 在 SQL Server 中,有兩種形式的表存在:聚集索引表和堆表(clustered index 和 heap table).為表建立的非聚集索引,葉子節(jié)點(diǎn)存儲的除了索引值,還有指向原表的 RID(file id + page id + row id)或者聚集索引值。一旦查詢使用到了索引,而索引包含的列中,找不到查詢需要的列,那么優(yōu)化器會給出訪問原表的方法,即用索引存儲的 RID 或者鍵值,回到原表去讀一邊。此時(shí)的讀,被稱為回讀,用的是隨機(jī)讀(random read), 一次磁頭的轉(zhuǎn)動假如就為一條記錄,實(shí)際上卻掃描了一個(gè)扇區(qū),由此可見有多么浪費(fèi)資源。
索引選用機(jī)制
B-Tree(Balanced Tree),索引引入它的目的就是為了建立快速查詢的結(jié)構(gòu)。索引數(shù)據(jù)頁的葉子節(jié)點(diǎn)頁,有可能并不是按照邏輯順序排好序的,因?yàn)橛兴槠瑳_刷,長時(shí)間數(shù)據(jù)頁是被打散了的。此時(shí)按照這種頁碼去掃描,出來的結(jié)果肯定是不對的。因此引入 B-Tree, 即確保了索引最終提供正確的邏輯順序,也加快了速度。
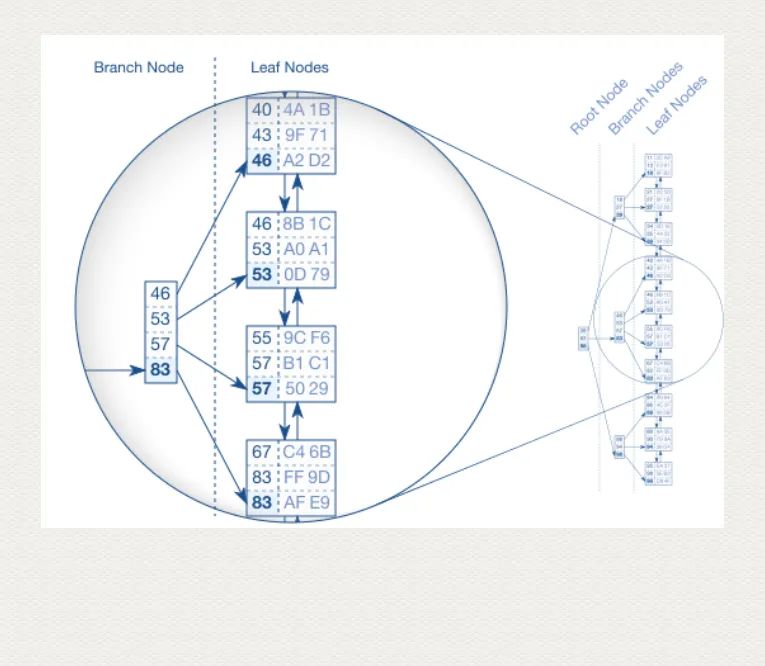
(摘自:https://use-the-index-luke.com/sql/anatomy/the-tree)
上面的 [46,53,57,83]是B-Tree 中的一個(gè)節(jié)點(diǎn),此節(jié)點(diǎn)上的數(shù)據(jù)必須保證時(shí)時(shí)刻刻都按照索引順序排列,SQL Server 靠鎖來維持對這些節(jié)點(diǎn)的獨(dú)占。正因?yàn)檫@些節(jié)點(diǎn)保證了數(shù)據(jù)的順序性,因此底層索引數(shù)據(jù)頁就不用嚴(yán)格按照索引順序排列了,由第二底層的數(shù)據(jù)頁指針,指向最終存儲的索引數(shù)據(jù)頁,就可以保證邏輯的順序正確了。
索引的使用,一般是和條件查詢綁定的。如果想要發(fā)揮索引的作用,就必須用已經(jīng)被索引的字段做條件查詢。比如以下這些判斷條件語句,是可以有效利用索引的:
ProductID = 771
UnitPrice<3.975
LastName='Allen'
LastName LIKE 'Brown%'
總結(jié)一下,等值比較或不等值比較,包括 =,<,>,<=,>=,!=,!<,!>,BETWEEN 和 In,執(zhí)行計(jì)劃都可以安排索引作為數(shù)據(jù)訪問的途徑。但以下表達(dá)式,卻會阻擾索引的使用:
ABS(ProductID)=771
UnitPrice + 1 <3.975
LastName LIKE '%Allen'
UPPER(LastName) = 'Allen'
我們只需比較兩者的執(zhí)行計(jì)劃,就可以知道,判斷條件的字段上加了函數(shù)或者表達(dá)式,索引就無法再使用了。
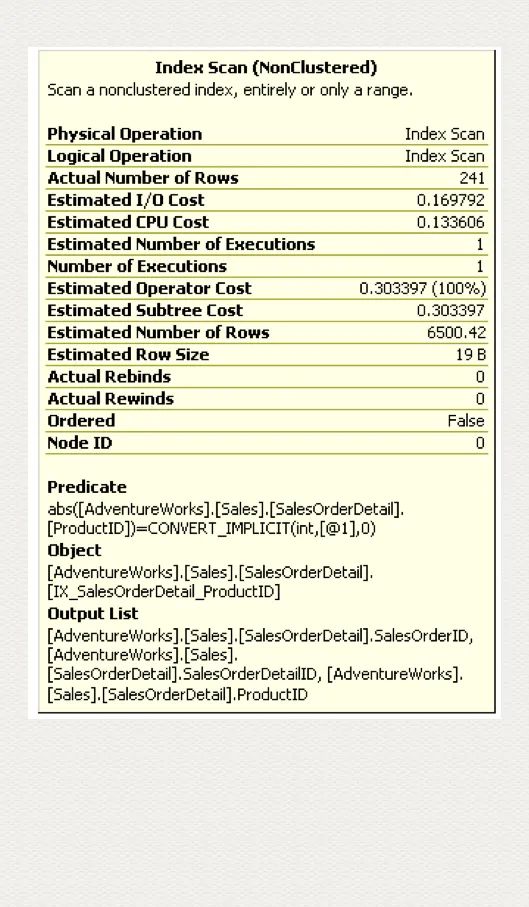
Predicate 表達(dá)式中,一旦索引字段(ProductID) 加了 abs() 函數(shù),索引就失效了。
多列組合索引,情況就會復(fù)雜一些。當(dāng)前列的條件判斷是否能有效利用索引,取決于前一列使用的條件判斷是否是等值判斷。比如下列的判斷條件,SQL Server 都是可以利用索引對兩列字段做 seek 操作的,前提是索引按照判斷條件字段的前后順序建立的:(
以下的場景,均假設(shè)了按順序建立了 ProductID + SalesOrderID, LastName + FirstName 的索引)
ProductID = 771 AND SalesOrderID > 34000LastName = 'Smith' AND FirstName = 'lan'
當(dāng)?shù)诙惺褂昧撕瘮?shù)或者復(fù)雜表達(dá)式,或者第一列使用了復(fù)雜表達(dá)式,那么就僅僅能使用索引去做第一列的 seek:
ProductID = 771 AND ABS(SalesOrderID) = 34000ProductID < 771 AND SalesOrderID = 34000LastName >'Smith' AND FirstName = 'lan'
又或者前一列用了函數(shù)或者表達(dá)式,那么整個(gè)索引就失效了:
ABS(ProductID) = 771 AND SalesOrderID = 34000LastName LIKE '%Smith' AND FirstName='lan'
看下第一列可以走索引的 seek 而第二列卻不能利用 seek 的例子:
SELECT ProductID, SalesOrderID, SalesOrderDetailIDFROM Sales.SalesOrderDetailWHERE ProductID = 771 AND ABS(SalesOrderID) = 45233
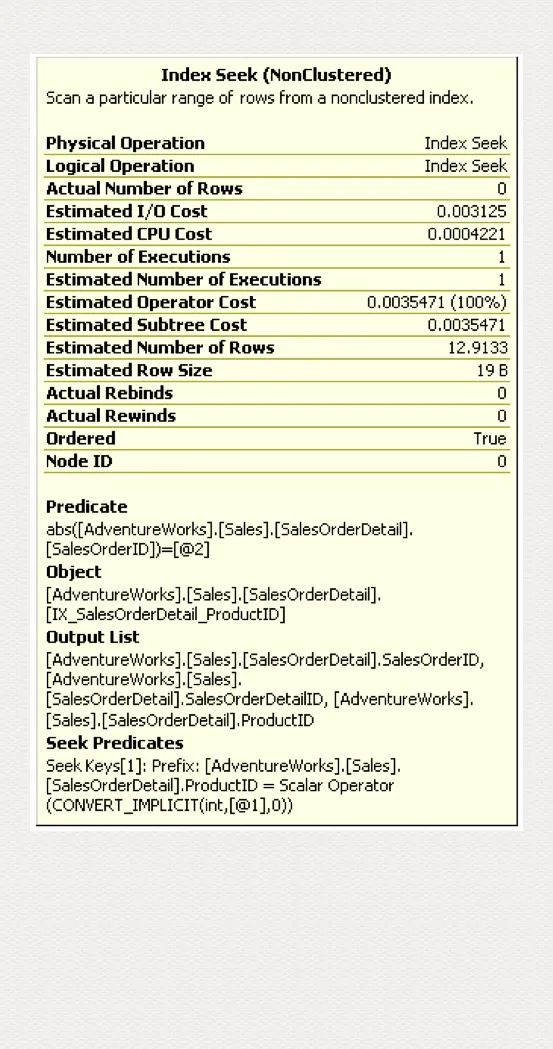
注意:Seek Predicates 顯示有效利用了索引第一列 ProductID 的條件判斷,而 Predicate 就顯示索引第二列無法使用 seek 操作
數(shù)據(jù)庫引擎優(yōu)化顧問(The Database Engine Tuning Advisor)
大多數(shù)的商業(yè)數(shù)據(jù)庫都會提供一個(gè)優(yōu)化組件,幫助建立有效的索引。SQL Server 中這個(gè)組件就是數(shù)據(jù)庫引擎優(yōu)化顧問(The Database Engine Tunning Advisor). 理論上可以有兩種架構(gòu)來設(shè)計(jì)這個(gè)優(yōu)化顧問,一種是新建一個(gè)成本模型估算成本,另一種是利用現(xiàn)有的查詢優(yōu)化器來估算成本。新建一個(gè)優(yōu)化器除去一些復(fù)雜的操作和部署不說,基于新成本模型估算出來的執(zhí)行計(jì)劃,顯然也不會給現(xiàn)有的優(yōu)化器來用,現(xiàn)有的優(yōu)化器始終還是以自己得到的執(zhí)行計(jì)劃去操作數(shù)據(jù)。因此,寶都押在利用現(xiàn)有查詢優(yōu)化器來做出優(yōu)化評估。
SQL Server 是第一家搭載物理對象設(shè)計(jì)器的商業(yè)數(shù)據(jù)庫,從 SQL Server 7.0 開始使用 Index Tuning Wizard 到 SQL Server 2005 替換成了 Database Engine Tuning Advisor( DTA). 兩個(gè)產(chǎn)品都使用了優(yōu)化器本身的成本估算模型去分析當(dāng)前優(yōu)化策略。目的就是為了達(dá)到高度自治和調(diào)優(yōu)。除了索引以外,DTA 也可以幫助引導(dǎo)建立物化視圖( indexed view) 和 分區(qū)(partition)。
當(dāng)然優(yōu)化顧問只是評估,并不會自動替人工去創(chuàng)建索引。那么不建立索引的情況下,優(yōu)化顧問是怎么去評估,得出一個(gè)合理的索引?其實(shí)本質(zhì)上優(yōu)化器選擇哪一個(gè)索引,完全建立在元數(shù)據(jù)以及字段的 statistics 之上,在優(yōu)化的過程中,索引數(shù)據(jù)存在不存在不重要。索引一旦選擇完畢,在執(zhí)行的時(shí)候,一定需要索引數(shù)據(jù)必須存在。
開啟優(yōu)化顧問,當(dāng)然會對數(shù)據(jù)庫的性能有一定額影響,所以安排好適當(dāng)時(shí)間。
所以在 DTA(Database Engine Tuning Advisor) 調(diào)優(yōu)的過程中,SQL Server 不會真的去創(chuàng)建 DTA 認(rèn)為完美的索引,而是給出一種叫做假設(shè)索引(hypothetical index),這類索引在 SQL Server 7 的 Index Tuning Wizard 當(dāng)中也有用過。就如名字一樣,hypothetical index 不是一種真實(shí)的索引,不以任何形式存在于數(shù)據(jù)庫中,因?yàn)?DTA 一旦用完,這些索引就被丟棄了。他們只包含 statistics,只能用未歸檔的 CREATE INDEX 語句的 WITH STATISTICS_ONLY 選項(xiàng)來創(chuàng)建,且這個(gè)命令只有在 SQL Server Profiler 里面看得到。
下面看個(gè)簡單的例子,用來找出索引沒有正確創(chuàng)建的場景。
1) ?創(chuàng)建一張新表,沒有任何索引存在
SELECT *INTO dbo.SalesOrderDetailFROM Sales.SalesOrderDetail
2) ?將下面的查詢保存成文件
SELECT *FROM dbo.SalesOrderDetailWHERE ProductID = 897
3) ?使用 DTA 來輔助分析缺少的索引
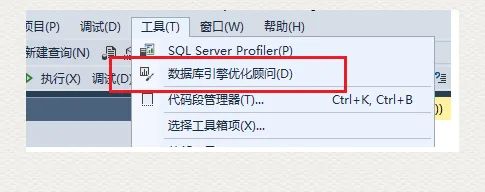
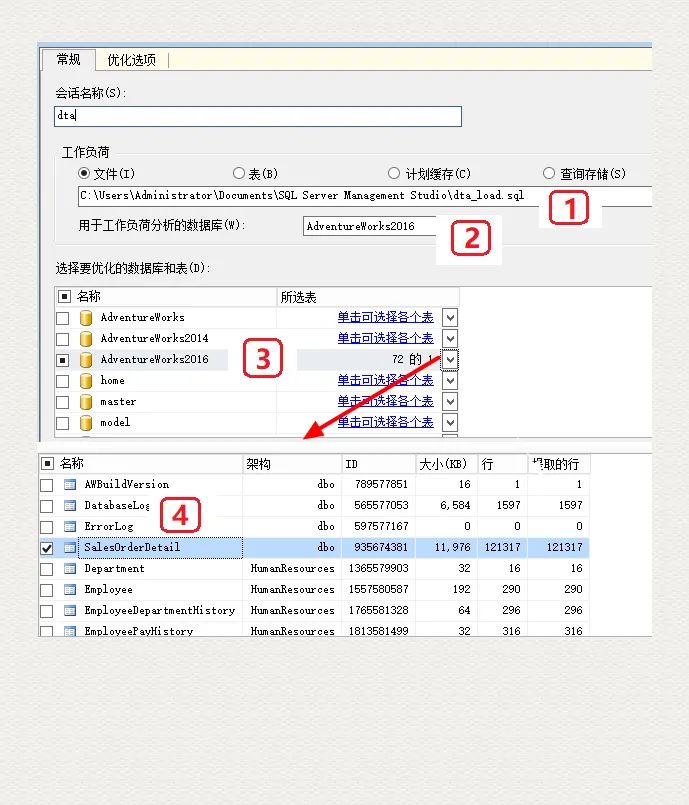
如上圖所示,打開 DTA(Database Engine Tuning Advisor),在 Workload File 選項(xiàng)下面,定位到剛才新建的文件;選擇需要測試的數(shù)據(jù)庫 AdventureWorks; 點(diǎn)擊 Start Analysis 命令執(zhí)行。
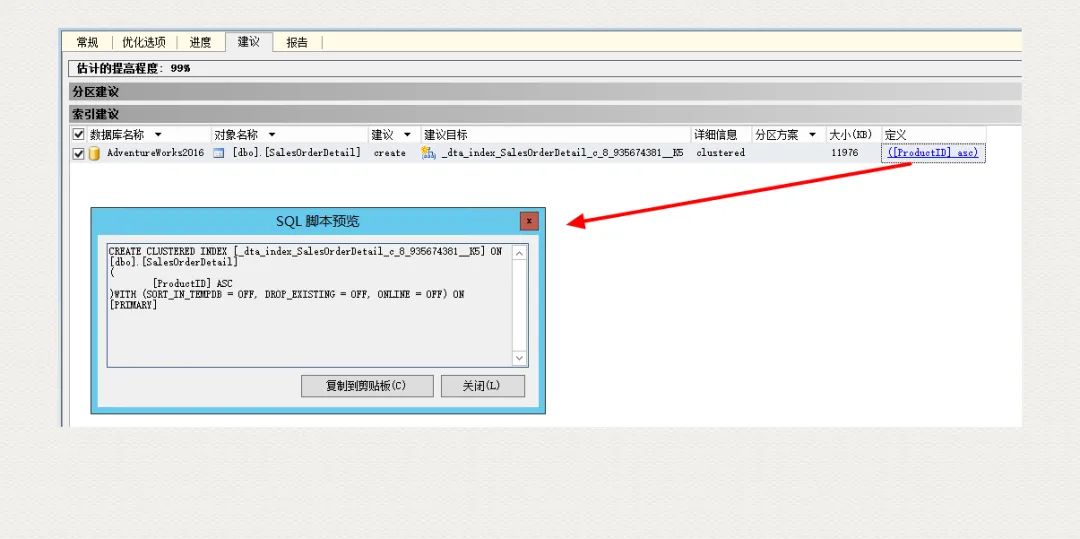
等待 DTA 完成,打開這張表分析:
SELECT *FROM msdb..DTA_reports_query

由此可見 ,DTA 幫我們推薦了個(gè)新的索引,據(jù)此索引生成的執(zhí)行計(jì)劃,成本只有 0.00332754. 而當(dāng)前環(huán)境下,成本居然高達(dá) 1.24414. 通過打開預(yù)估執(zhí)行計(jì)劃窗口,這成本可以很容易得到。

我們根據(jù) DTA 推薦的 Index Recommendations 創(chuàng)建索引,之后再執(zhí)行上面的條件查詢,很顯然效率高很多。
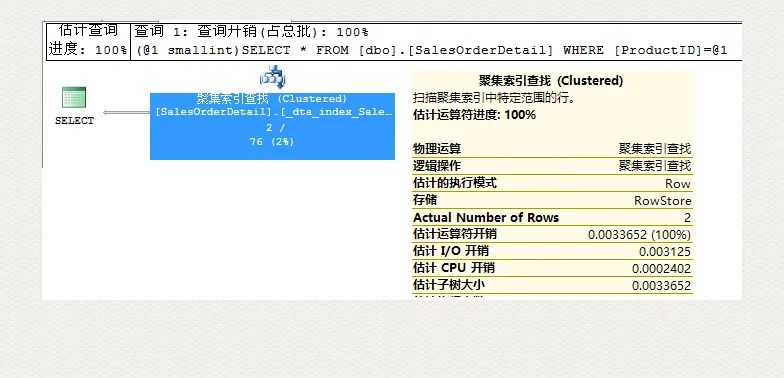
hypothetical index 還可以通過 WITH STATISTICS_ONLY 創(chuàng)建:
CREATE CLUSTERED INDEX clx_ProductIDON dbo.SalesOrderDetail(ProductID)WITH STATISTICS_ONLY
查詢索引的字典表:
SELECT name,type_desc,is_hypotheticalFROM sys.indexesWHERE object_id = object_id(N'dbo.SalesOrderDetail')AND name = 'cix_ProductID'
?
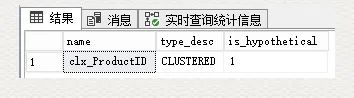
這里的 is_hypothetical 是 1, 代表的是一個(gè)假設(shè)的索引,并不真正存在。
Missing Indexes Feature(特性)
除了 DTA(Database Engine Tuning Advisor), SQL Server 還提供了一種方法來檢測哪些索引對當(dāng)前的查詢是用的。這種方法稱為 Missing Index ?特性。這個(gè)方法不需要 DBA 去判斷是否要進(jìn)行調(diào)優(yōu),不需要嚴(yán)格指定請求文件,它很輕量,早在 SQL Server 2005 就已經(jīng)推出來了。
在優(yōu)化過程中,查詢優(yōu)化器會自動填補(bǔ)一個(gè)最優(yōu)的索引,如果這個(gè)索引不存在,會在 xml 執(zhí)行計(jì)劃或者 GUI 執(zhí)行計(jì)劃里突出顯示出來,并且會在緩沖中一直保留到下次重啟,通過查詢 sys.dm_db_missing_index 動態(tài)性能視圖就可以看到統(tǒng)計(jì)情況。當(dāng)優(yōu)化器提示徐亞更好的索引滿足查詢時(shí),實(shí)際上它在告訴我們兩件事:1)當(dāng)前的執(zhí)行計(jì)劃不是最優(yōu)的;2)應(yīng)該考慮新建索引來滿足當(dāng)前查詢。當(dāng)然, missing index 有自己不足,后面會講到,更詳細(xì)的解說可以參考官方在線文檔, limitations of the Missing indexes Feature.
通過下面的這個(gè)小例子,我們一起探討下 missing index 的使用場景:
如果你是從上面的例子一路看下來的,請 drop 表 dbo.SalesOrderDetail。
1)新建表 dbo.SalesOrderDetail
SELECT *INTO dbo.SalesOrderDetailFROM Sales.SalesOrderDetail
2) 運(yùn)行下面的查詢
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112
通過查詢運(yùn)行時(shí)執(zhí)行計(jì)劃及其屬性,可知這類查詢被稱作 TRIVIAL optimization level.
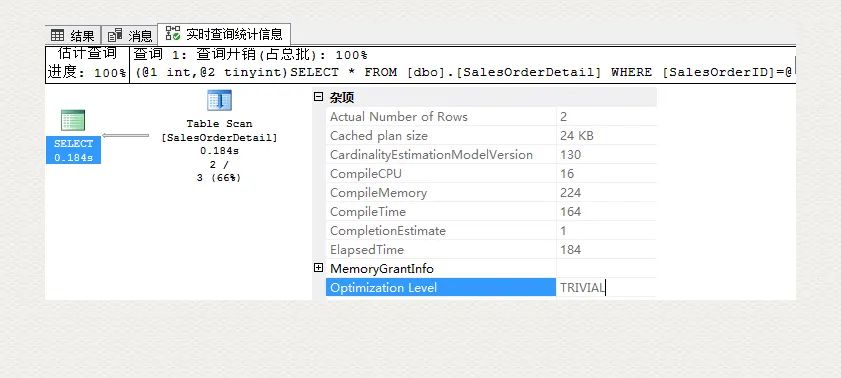
針對 TRIVIAL 級別的計(jì)劃,查詢優(yōu)化器并不會給出最優(yōu)的索引(基于哪個(gè)列,按照什么順序)。由上圖可見, GUI 并沒有提示缺少什么樣的索引。
基于此,我們可以通過增加無關(guān)的索引,來避免查詢優(yōu)化器評定查詢?yōu)?TRIVIAL 級別。如下:
CREATE INDEX IX_ProductIDON dbo.SalesOrderDetail(ProductID)
此時(shí),我們已經(jīng)可以看到 GUI 提示“缺少索引”的告警了,且 Optimization Level 為 FULL.

這里解釋下,什么是 trivial plan. 一句話概括就是簡單的不能再簡單的查詢計(jì)劃。比如:
SELECT ProductIDFROM dbo.SalesOrderDetailWHERE ProductID = 987
剛才我們已經(jīng)在表 dbo.SalesOrderDetail 上面以 ProductID 字段為索引鍵,創(chuàng)建了索引 IX_ProductID. 因此僅查詢 ProductID 且有條件表達(dá)式時(shí),不再需要其他復(fù)雜的判斷,走 index seek 即可。此時(shí),執(zhí)行計(jì)劃就被稱為 trivial plan.
處理了 trivial plan 的尷尬,剩下的事情,就是按照提示,我們判斷這索引是不是要加,還是修改之前的索引,使其符合當(dāng)下的查詢:
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112

在 [MissingIndexes] 欄位下,我們可以看到 Impact, MissingIndex, Optimization Level 三個(gè)大欄。
Impact 是指 missing index 能在多大程序上影響現(xiàn)有的查詢;
Missing Index 給出了優(yōu)化器建議的索引字段和索引順序;
Optimization Level 如果顯示了 FULL, 表達(dá)的意思就是有優(yōu)化調(diào)整空間
按照提示,我們新建索引:
CREATE INDEX IDX_ORD_DETAIL_IDON dbo.SalesOrderDetail(SalesOrderID,SalesOrderDetailID)
再執(zhí)行上面的語句 :
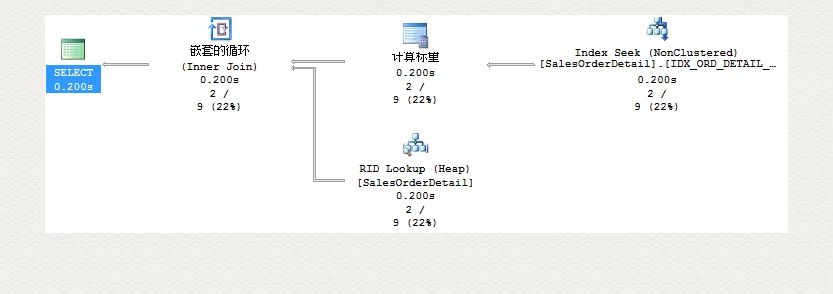
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112
對比前后執(zhí)行計(jì)劃,這一次索引真排上用場了:
無用的索引(Unused Indexes)
在應(yīng)用系統(tǒng)中,總有些表,索引,存儲過程隨著管理的松懈,慢慢遺留了下來。如何對這些無用(不再用)的數(shù)據(jù)庫對象做處理,便成為了難題。本章討論如何對無用的索引做處理。
為什么要處理掉這些無用的索引呢?首先,索引是表一樣存在的數(shù)據(jù)庫對象,占用了數(shù)據(jù)庫磁盤空間;第二,在更新數(shù)據(jù)表的時(shí)候,索引會實(shí)時(shí)更新,對并發(fā)性能產(chǎn)生很大影響;第三,大量的索引,給優(yōu)化器帶來很大的運(yùn)算壓力。
判斷索引無用的方法,核心是使用一張動態(tài)性能試圖(DMV: Dynamic Management View), 即 sys.dm_db_index_usage_stats.
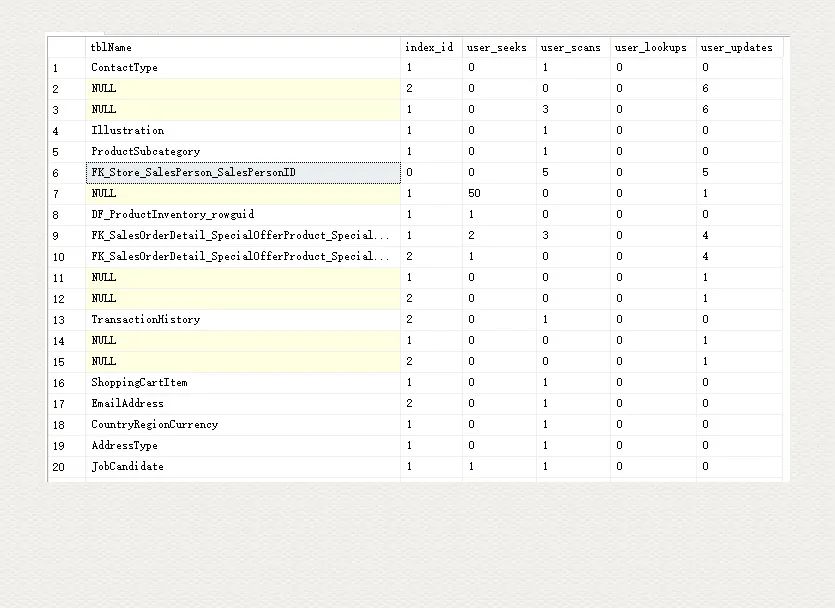
這張?jiān)噲D記錄了所有 seek, scan, lookup, update 等操作的次數(shù),還有最后一次的執(zhí)行時(shí)間。除了索引(非聚集索引)使用頻次統(tǒng)計(jì)之外,還有包括堆表和聚集表。和 sys.indexes 里面的規(guī)定一致,index_id 為 0 的即為堆表,index_id 為 1 的即為聚集索引表,大于等于 2 的為非聚集索引,這些 index_id 為 2 的索引才是我們要考慮去移除的。想想為什么?
SELECT object_name(object_id) as tblName, index_id, user_seeks, user_scans, user_lookups, user_updatesFROM sys.dm_db_index_usage_stats WITH(NOLOCK)
往期精彩: