
每日一道 LeetCode (5):最長公共前綴

代碼倉庫
GitHub:https://github.com/meteor1993/LeetCode
Gitee:https://gitee.com/inwsy/LeetCode
題目:最長公共前綴
題目來源:https://leetcode-cn.com/problems/longest-common-prefix/
編寫一個函數(shù)來查找字符串數(shù)組中的最長公共前綴。
如果不存在公共前綴,返回空字符串?""。
示例?1:
輸入: ["flower","flow","flight"]
輸出: "fl"
示例?2:
輸入: ["dog","racecar","car"]
輸出: ""
解釋: 輸入不存在公共前綴。
說明:
所有輸入只包含小寫字母 a-z 。
解題思路 A :「暴力橫向查找」
看到這道題,我又感覺我行了,先聊聊我沒看答案之前的思路,這個思路我覺得是一個正常人,看到這道題應(yīng)該有的,如果這個思路都沒有,可能你比較適合學(xué)文科。
我的思路一般都很暴力,直接循環(huán)這個字符串數(shù)組,從第一個開始,挨個向后比較,比較兩個字符串的每一個字符,遇到不一樣的直接返回。
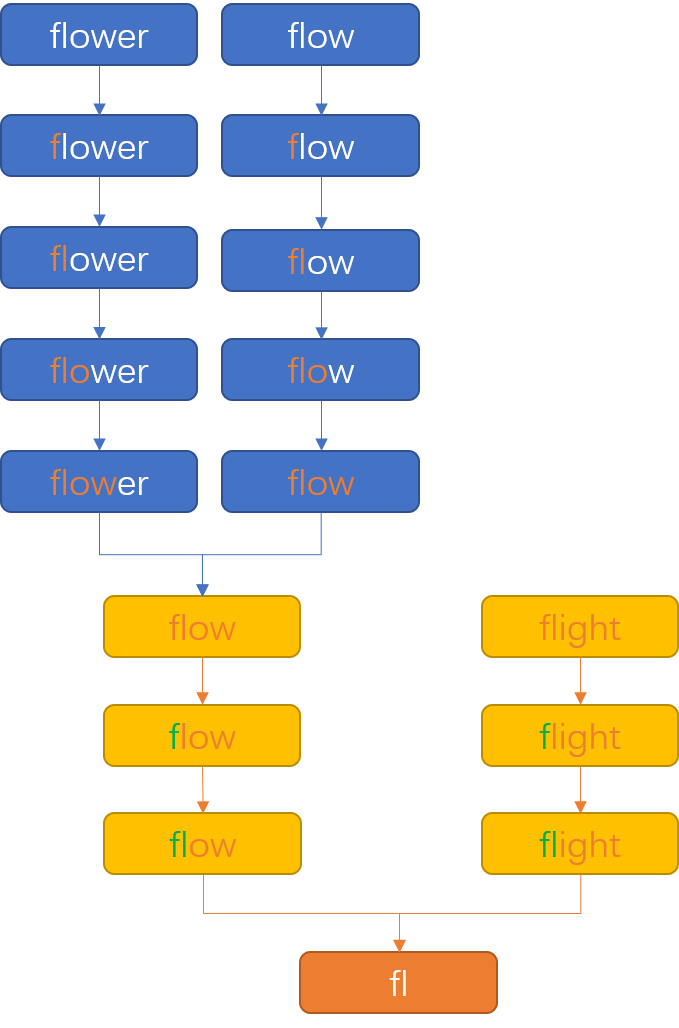
這思路夠簡單、暴力、直接吧,我想大家第一反應(yīng)應(yīng)該都能想得到這個方案。
接下來是代碼時間:
public String longestCommonPrefix(String[] strs) {
if (strs.length == 0) return "";
String prefix = strs[0];
for (int i = 1; i < strs.length; i++) {
prefix = compareTwoStrs(prefix, strs[i]);
if (prefix.length() == 0) break;
}
return prefix;
}
// 獲取兩個字符串的公共前綴
private String compareTwoStrs(String str1, String str2) {
int length = Math.min(str1.length(), str2.length());
int index = 0;
while (index < length && str1.charAt(index) == str2.charAt(index)) {
index++;
}
return str1.substring(0, index);
}
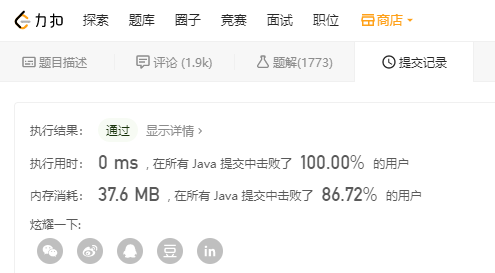
我在 LeetCode 上運行了一下,直接得到這個結(jié)果,這個結(jié)果應(yīng)該是我做 LeetCode 最好的結(jié)果了,竟然耗時小于 1ms ,難道我已經(jīng)這么牛皮了么,我感覺自己飄了。

我滿懷信心的打開了答案頁,正準備寫個回答裝個 B 的時候,我傻眼了, NM ,這道題竟然有這么多種解法的啊,心態(tài)崩了啊。

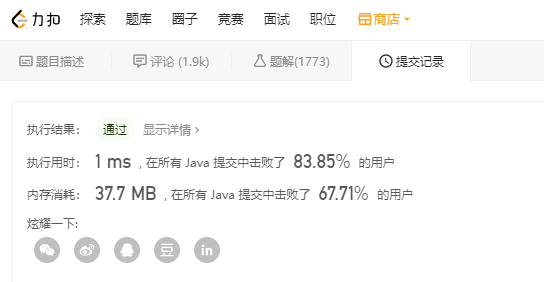
忽然想到,剛才我的方案只是一個最簡單的正向暴力破解的方案,但是我的解法耗時低于 1ms 啊,這么看來,我的解法還是可以的嘛。
解題思路 B :「暴力縱向查找」
我看到答案上把我上面的那種思路叫做「暴力橫向查找」,然后大神們按照這個思路,又搞出來了「暴力縱向查找」。
圖我就不畫了,反正和上面的思路一致,就是把橫向比較換成了縱向比較,然后一個接一個比一圈,直到最短的字符串長度結(jié)束,或者開始出現(xiàn)不一樣的字符為止。
代碼漲這個樣子:
public String longestCommonPrefix_1(String[] strs) {
if (strs.length == 0) return "";
for (int i = 0; i < strs[0].length(); i++) {
for (int j = 1; j < strs.length; j++) {
if (i == strs[j].length() || strs[j].charAt(i) != strs[0].charAt(i)) {
return strs[0].substring(0, i);
}
}
}
return strs[0];
}
解題思路 C :「分治」
當我以為到這里就結(jié)束了的時候,我接著往下翻了翻答案,結(jié)果發(fā)現(xiàn)我自己還是圖樣圖森破啊,我太小看了「學(xué)霸」和「大神」這兩個詞。

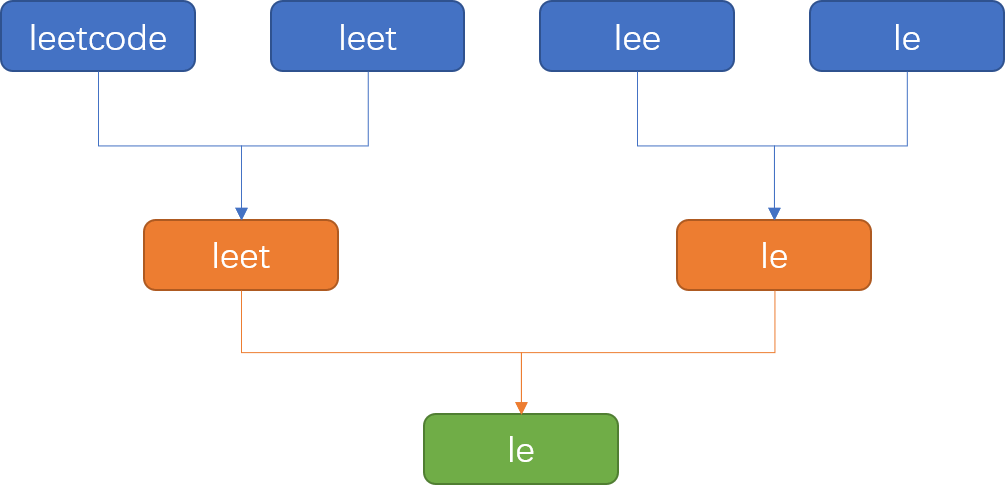
「分治」這個方案是先把字符串數(shù)組從中間切開,然后再按照「暴力橫向查找」的方案分別取到切開后的兩個數(shù)組的最長前綴,最后再從這兩個前綴中取交集。
這種方案可以看做是「暴力橫向查找」方案的一個變種方案,示意圖如下:
public String longestCommonPrefix_2(String[] strs) {
if (strs.length == 0) {
return "";
} else {
return longestCommonPrefix(strs, 0, strs.length - 1);
}
}
public String longestCommonPrefix(String[] strs, int start, int end) {
if (start == end) {
return strs[start];
} else {
int mid = (end - start) / 2 + start;
String lcpLeft = longestCommonPrefix(strs, start, mid);
String lcpRight = longestCommonPrefix(strs, mid + 1, end);
return commonPrefix(lcpLeft, lcpRight);
}
}
public String commonPrefix(String lcpLeft, String lcpRight) {
int minLength = Math.min(lcpLeft.length(), lcpRight.length());
for (int i = 0; i < minLength; i++) {
if (lcpLeft.charAt(i) != lcpRight.charAt(i)) {
return lcpLeft.substring(0, i);
}
}
return lcpLeft.substring(0, minLength);
}

當然,這種方案還可以接著變種,把「暴力橫向查找」替換成「暴力縱向查找」。
解題思路 D :「二分查找」
最后還有一種二分查找比較新奇,我覺得刷題少的人肯定想不到這種方案。
這種方案的思路是在字符串數(shù)組中,最長公共前綴的長度肯定不會超過字符串數(shù)組中的最短字符串的長度(如果超過了,也不會是最長公共前綴)。
首先找到最短的字符串長度 minLength ,然后隨機找一個字符串判斷這個 minLength 是否是最長公共前綴,如果不是則把這個 minLength 從中間劈開,接著判斷前一半是不是公共前綴,如果是,則最長公共前綴一定大于等于這一半,如果不是,則最長公共前綴一定小于這一半,就這樣逐漸縮小范圍,直到找到為止。
這個我就不畫圖了,就是一個單純的二分法不停的往下切,直到切中了為止。
public String longestCommonPrefix_3(String[] strs) {
if (strs.length == 0) return "";
// 先獲取最小長度
int minLength = Integer.MAX_VALUE;
for (String str : strs) {
minLength = Math.min(minLength, str.length());
}
// 定義變量,開始二分法
int low = 0, high = minLength;
while (low < high) {
// 獲取中間點
int mid = (high - low + 1) / 2 + low;
if (isCommonPrefix(strs, mid)) {
low = mid;
} else {
high = mid - 1;
}
}
return strs[0].substring(0, low);
}
public Boolean isCommonPrefix(String[] strs, int length) {
// 先獲取前一半要比較的字符串
String str0 = strs[0].substring(0, length);
for (int i = 1; i < strs.length; i++) {
for (int j = 0; j < length; j++) {
// 按字符進行判斷,如果有不一樣的字符直接返回 false
if (str0.charAt(j) != strs[i].charAt(j)) {
return false;
}
}
}
return true;
}
從上面的結(jié)果看下來,好像是二分法的速度是最慢的,實際上這是由于測試的數(shù)據(jù)集的關(guān)系,測試所使用的的數(shù)據(jù)集可能都比較適合「暴力橫向查找」這個方案。
