
如何看待 Google Docs 將從 HTML 遷移到基于 Canvas 渲染?
共 5089字,需瀏覽 11分鐘
·
2022-02-09 17:29
Google Docs 這么做是必然選擇,而且是所有號稱要做「云端Office」在線文檔的終極形態(tài)。
相關問題回答如下
- Google Docs 會采用 canvas 是否標志著網(wǎng)頁三劍客(HTML、CSS、JS)的沒落?
- Google Docs 之前的技術選型有什么問題?
- Google Docs 會如何技術升級(瞎猜)?
1. Google Docs 會采用 canvas 是否標志著網(wǎng)頁三劍客(HTML、CSS、JS)的沒落?
肯定不是,采用 canvas 渲染取決于 Google Docs 的項目復雜度和特殊性,99.9999%的項目用網(wǎng)頁三劍客無疑是更好的選擇,文本處理器(Google Docs)有超高的一致性和性能要求,這些要求絕大多數(shù)應用根本不需要考慮,可惜,Google Docs 就是那 0.0001% 它是極其特殊的存在,而且我個人認為 Google Docs 并不會重新造一個類似于 flutter 的 UI 系統(tǒng),而是重寫「字體解析」「字體整形」「文本布局」「文字處理渲染引擎」等一系列相關的引擎,總之,Google Docs 用 canvas 干的事情,跟大家理解用 canvas 干的不是一回事。
2. Google Docs 之前的技術選型有什么問題?
Google Docs 2010 之前基于 contenteditable ,之后不基于 contenteditable 但仍基于DOM。
基于 contenteditable 的富文本編輯器會產(chǎn)生非常多的問題,已經(jīng)是老生常談了,下面這篇文章已經(jīng)寫得比較清楚了:
為什么 ContentEditable 很恐怖 - OSCHINA - 中文開源技術交流社區(qū)Google Docs 在 2010 年也解釋了為什么拋棄 contenteditable:
https://drive.googleblog.com/2010/05/whats-different-about-new-google-docs.html簡單而言就是為了一致性、高級功能(標尺、腳注、分頁)、協(xié)同編輯。
其實關于 contenteditable 的技術選型問題無需我多言,以上兩篇文章足以解答。
我們重點談拋棄了 contenteditable 之后為什么依然有問題?
Google Docs 已經(jīng)說明了是為了「一致性」和「性能」考慮。
首先,我們解釋一下在線文檔的一致性是什么?
如果你的在線文檔基于瀏覽器,那么必然會用到瀏覽器實現(xiàn)的特性,而各大瀏覽器實現(xiàn)的方式不同,呈現(xiàn)的效果也不同,這就導致了不同瀏覽器編輯同一份文檔會出現(xiàn)不一致,現(xiàn)在在線協(xié)同是這些軟件的標榜功能之一,如果編輯的呈現(xiàn)效果不一致,那么何談「協(xié)同編輯」?
實際上現(xiàn)代瀏覽器的一致性差異已經(jīng)比較小了(相比于2010年 IE 還在大行其道的年代),所以大多數(shù)情況下一致性是可以接受的,但是依然有一些一致性問題困擾著開發(fā)者。
比如「語雀」基于瀏覽器實現(xiàn)了選取拖藍,這就導致了不一致性,如果你在 Firefox 下雙擊選區(qū)會選擇「一句文字」進行拖藍:
如果你在 Chrome 下進行雙擊選取拖藍,它會拖藍「一個詞組」:
歸根到底是 Chrome 相比于 Firefox ,多進行了一步基于 CC-CEDICT 的分詞操作,Chrome 會優(yōu)先選擇詞組而不是句子:
當然你可以用各種方法把這些不一致性抹平,比如拖藍選區(qū)的一致性問題也可以解決,那就是自己寫一個相關的庫替代瀏覽器自帶的拖藍選區(qū)功能,但是這就像一個無底洞,你不知道像瀏覽器這種龐然大物到底有多少不一致性,每一次更新都可能帶來變化。
大家要記住,越多的依賴瀏覽器的能力,就越多的受到瀏覽器一致性問題的困擾
2010 年后 Google Docs 計算出文本的大小進行絕對定位排版,實現(xiàn)了自己全新的文本布局引擎,包括選區(qū)、光標、排版都進行了自研,似乎已經(jīng)徹底擺脫了瀏覽器的控制,但是事實卻不是這樣。
現(xiàn)在的 Google Docs 的文本布局引擎是基于 「div+span+絕對定位」 的方式實現(xiàn)的,實際上并沒有脫離 DOM,這就到了大量的操作依然依賴于瀏覽器的底層提供的能力。
雙向文本(BIDI)
我們的現(xiàn)代漢字和實際上絕大多數(shù)文字的書寫方式是自左向右的,但是也有不少例外,阿拉伯文、希伯來文的書寫順序是自右向左,而古代漢語、傳統(tǒng)蒙語等是縱向排版的,這需要文本處理器可以識別不同的文字進行不同的處理。
https://zh.wikipedia.org/wiki/%E9%9B%99%E5%90%91%E6%96%87%E7%A8%BFUnicode 有相關的 BIDI 算法,而 Google Docs 選擇了基于瀏覽器的能力,大家看看這段阿拉伯文, Google Docs 的處理方式,利用了 CSS 的屬性,而并非自己實現(xiàn)。
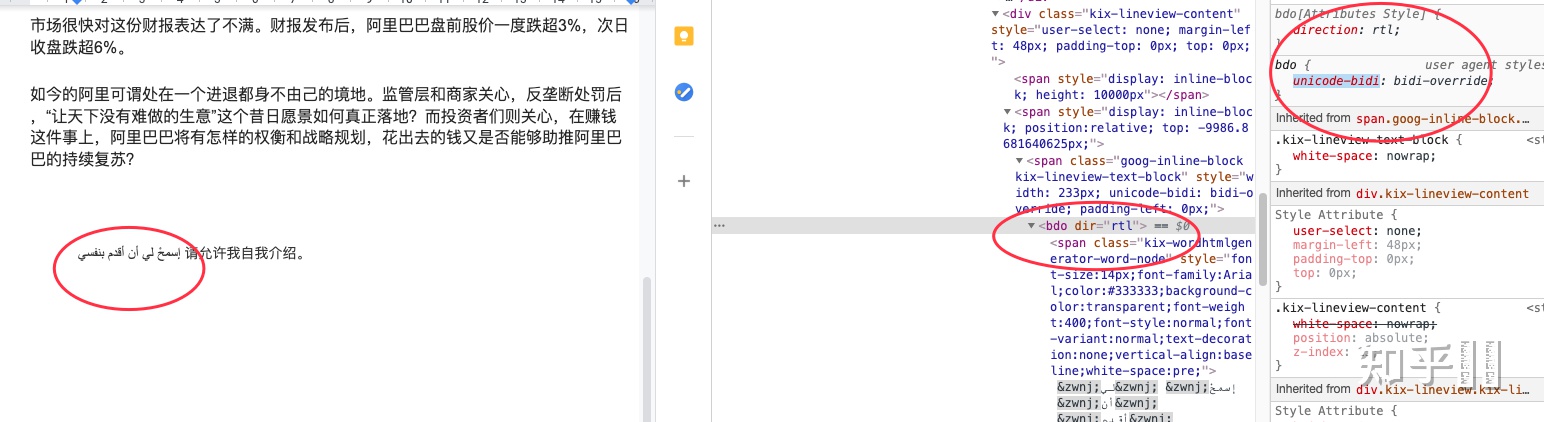
同樣的, CSS 基于瀏覽器提供的底層算法,蘋果系統(tǒng)需要 CoreText 提供支持,而 Linux 下則是 :
fribidi/fribidi幸好這個算法是有通用標準的,實現(xiàn)起來應該大差不差,如果沒有通用解決方法,各個瀏覽器自己實現(xiàn),那么不一致問題就會出現(xiàn)。
字體解析與渲染
我們提到了,Google Docs 的字體解析與渲染依然是基于瀏覽器的,看下圖,直接 span + css 對文字進行了排版:
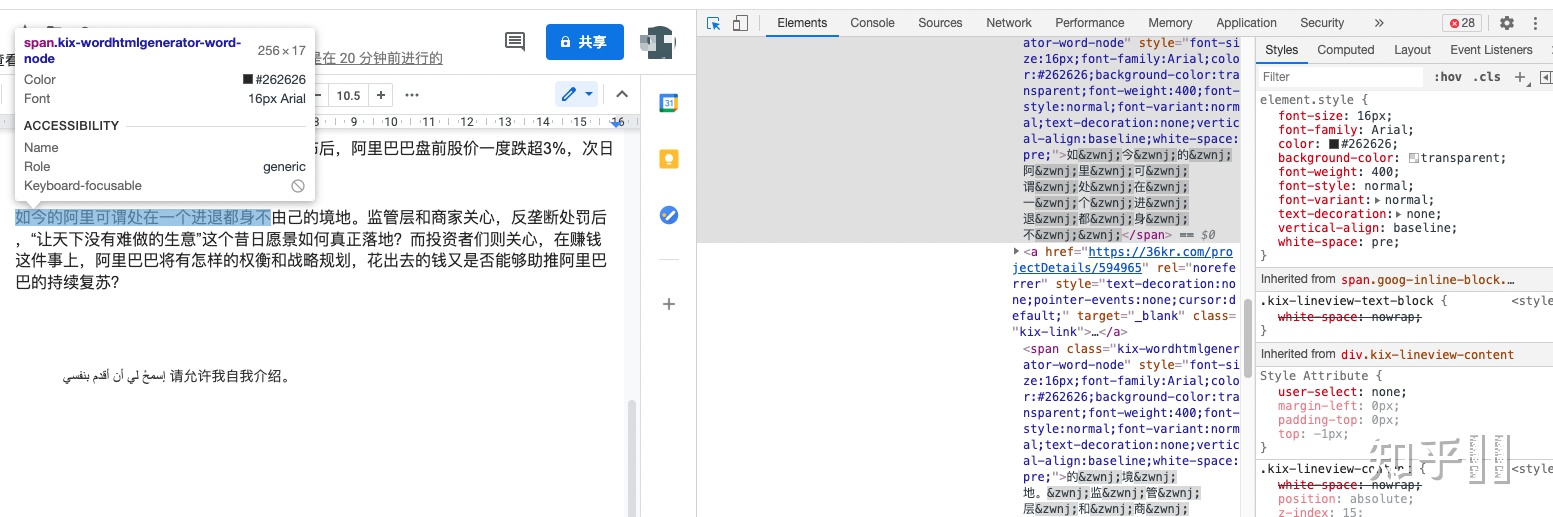
瀏覽器在不同平臺依賴的底層庫也不一致,比如 windows 下的 DirectWrite,Mac 下的 Core Text 等等。
我就存在一個可能由于解析+渲染導致的不一致問題。
比如在 Google Docs 下我一臺 Mac Mini 的 Chrome 呈現(xiàn)是這樣的(存在bug),注意那個笑臉表情,光標所在的位置直接顯示在笑臉上面:

當我打開同一臺電腦、同一個文檔,唯一的不同就是用 Firefox 打開后,顯示是正確的,不僅如此所有其他電腦任何瀏覽器都是正確的,唯獨這一臺 Mac mini 用 Chrome 打開是錯誤的:

這就是我這臺 Mac Mini 特有的系統(tǒng)級 Bug 導致的問題,因為這臺 Mac mini 是通過時間機器從舊 MBP 上遷移的,而這個問題同樣出現(xiàn)在舊 MBP,而舊 MBP 重置系統(tǒng)后問題消失了,舊 MBP 重置系統(tǒng)后跟 Mac mini 系統(tǒng)版本號一致,Chrome版本號也一致,但是沒問題。
這說明,由于 Google Docs 依賴的瀏覽器提供的底層能力(瀏覽器的能力部分來自于操作系統(tǒng)),導致了這種不可控的 Bug。
說完一致性問題,我們再看看「性能」問題,這個依然是由于依賴瀏覽器的 DOM 導致的,雖然 Google Docs 在我看來已經(jīng)很快了,用一些低端筆記本打開也挺流暢的,可能 Google Docs 有更高的性能要求吧。
目前 Google Docs 依然是我們上面所說的依賴 DOM,那么 Google Docs 的文字處理區(qū)域的回流、重繪依然是依靠瀏覽器自帶的能力,Google Docs 目前除了文本布局是由自己接管之外,還得依靠瀏覽器,雖然對于絕大多數(shù)人瀏覽器提供的能力已經(jīng)很夠用了(我就覺得挺夠用的 ),但是如果自己徹底接管整個文字處理區(qū)域的布局、排版,那么優(yōu)化的上限會很高(下限也會很低,取決于開發(fā)者水平)。
至于 Google Docs 會如何優(yōu)化,我在下面有自己的猜測。
Google Docs 背后技術升級的猜想
說了 Google Docs 為什么要升級技術,我們可以大膽猜測下 Google Docs 會如何升級技術。
接管字體相關的一切工作
從字體解析一直到光柵化必須由 Google Docs 自己控制,而非瀏覽器控制。
字體解析:這需要一個字體解析器,兼容 TrueType 和 OpenType 標準 ,并實現(xiàn)標準中的一系列特性,類似于這種:

文本整形(text shaping engine):文本整形是將一串字符代碼(例如Unicode代碼點)轉換為正確排列的字形序列的過程,這些字形序列可以呈現(xiàn)在屏幕上或最終輸出形式以包含在文檔中。
這篇文章說的很清楚,為什么這一步必不可少:
Why do I need a shaping engine?舉個簡單的例子,阿拉伯文的字母出現(xiàn)在上下文不同的位置有四種不同的變體。
如阿拉伯文的mīm,單獨書寫為:
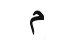
?三個連寫(mmm,顯示為詞頭,詞中,詞尾形)就變?yōu)?:
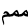
如果沒有文本整形引擎,這一步無法實現(xiàn)。
比如如果沒有文本整形引擎效果如下:

上圖中我們文本框顯示的是由瀏覽器渲染的是正確的的,下面的是字體解析器渲染的,如果沒有文本整形,就是錯誤的。
如果字體解析器配合上文本整形引擎那么效果如下:

高級文本布局:目前 Google Docs 倒是實現(xiàn)了這一步,依靠絕對定位 + span 實現(xiàn)了對文本布局的控制,但是我猜想 Google Docs 用的方法是從 TextMetrics 倒推出文本前進寬度進行排版的(應該也沒別的辦法了),但是 TextMetrics 是個殘廢 API,很多屬性都沒有提供,而且短期內瀏覽器也不會提供,所以也只是能湊合用的程度。
TextMetrics 拿不到完整的 glyph list ,對于高級文本布局的排版只能湊合用大概,歸根到底是瀏覽器不開放給開發(fā)者能力,那么如果字體相關的工作靠瀏覽器解析,他不給你你永遠拿不到,這就是被瀏覽器廠商「卡脖子」,如果字體相關工作 Google Docs 自己「獨立自主」,那么很多屬性就可以拿到(比如unitsPerEm -字體內部坐標網(wǎng)格的大小,lineGap -行之間應包含的空間量,bbox-字體的邊界框,等等等對高級文本布局排版非常有用的屬性),可以進行精細化開發(fā)。

為了適應 Google Docs 的要求,必須實現(xiàn)包括但不限于:
- dibi 雙向文本布局
- 文本斷行
- 制表符
- 字間距、行間距、段間距等排版
- 頁碼、頁眉、腳注等等
- 分頁、分欄等
高性能渲染引擎:由于脫離了 DOM,雖然成功 「獨立自主」,但是獨立自主并非沒有代價,那就是什么事情都得自己干。
瀏覽器提供了非常便捷的 DOM 直接供我們操作,但是用 canvas 你必須自己實現(xiàn)精靈、事件、動畫,并自定義一系列控件,比如「列表」「表格」「按鈕」「選區(qū)拖藍」等等等,也就是 DOM 的一切現(xiàn)有的東西都無法復用,必須用 canvas 從頭造一遍(至少Google Docs需要用到的東西)。
可以性能優(yōu)化的點可能如下:
- 圖形拾取優(yōu)化:在 canvas 中文字、線條、表格、圖片都是一視同仁的,都是 canvas 精靈,沒了 DOM 都需要自己判斷鼠標是否在某個精靈上,是否選中了某個精靈,才有可能觸發(fā)鼠標或者鍵盤的各種事件,可以選擇「離屏緩存 Canvas」或者「幾何計算bbox」來進行判斷,在大量文本、圖片、表格等元素充斥的情況下保證性能很不容易。
- 局部渲染:很多時候我們修改的文本只涉及了某一段、某一行甚至某些文字,如果每次都全量渲染必然造成性能瓶頸,所以可以判斷用戶操作影響的范圍,計算出局部刷新的影響的包圍盒,只對影響范圍內的元素進行刷新。
- 分片渲染:React Fiber 將一次大的渲染任務拆分為一系列小的渲染任務,每一個任務可以在瀏覽器的一幀(16ms)中執(zhí)行完畢,并將任務分為高優(yōu)先級(用戶事件等)和 低優(yōu)先級任務(普通渲染任務)分別處理。
我們也可以用同樣的思路:
- 分拆渲染任務保證每個任務能在16毫秒內執(zhí)行完
- 可以動態(tài)對任務進行調整,暫停、刪除、終止任務
- 對不同類型的任務區(qū)分高低優(yōu)先級,比如用戶輸入、拖藍這種即時反饋的必須高優(yōu)先級
還有什么預渲染、避免使用 shadow、避免使用浮點小數(shù)這種更常規(guī)的就不談了。
除此之外還有光標處理、對象模型、復制粘貼、撤銷等一系列問題應該都不是重點,總之,Google Docs 向傳統(tǒng)桌面文字處理軟件比如 WPS、Word 繼續(xù)貼近了一大步,進入了 Web 文字處理軟件的終極形態(tài),從此之后應該不會有大的變化,只有小修小補了。
這種追求卓越的開發(fā)精神值得佩服,也不得不說,做這種事情需要大量人力、物力、時間的支撐,最后還是看出來,Google 真有錢!