Batch Normalization(2015)
論文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
論文中關(guān)于BN提出的解釋:訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)非常復(fù)雜,因為在訓(xùn)練過程中,隨著先前各層的參數(shù)發(fā)生變化,各層輸入的分布也會發(fā)生變化,圖層輸入分布的變化帶來了一個問題,因為圖層需要不斷適應(yīng)新的分布,因此訓(xùn)練變得復(fù)雜,隨著網(wǎng)絡(luò)變得更深,網(wǎng)絡(luò)參數(shù)的細微變化也會放大。由于要求較低的學(xué)習(xí)率和仔細的參數(shù)初始化,這減慢了訓(xùn)練速度,并且眾所周知,訓(xùn)練具有飽和非線性的模型非常困難。我們將此現(xiàn)象稱為內(nèi)部協(xié)變量偏移,并通過歸一化層輸入來解決該問題。其它的解釋:假設(shè)輸入數(shù)據(jù)包含多個特征x1,x2,…xn。每個功能可能具有不同的值范圍。例如,特征x1的值可能在1到5之間,而特征x2的值可能在1000到99999之間。如下左圖所示,由于兩個數(shù)據(jù)不在同一范圍,但它們是使用相同的學(xué)習(xí)率,導(dǎo)致梯度下降軌跡沿一維來回振蕩,從而需要更多的步驟才能達到最小值。且此時學(xué)習(xí)率不容易設(shè)置,學(xué)習(xí)率過大則對于范圍小的數(shù)據(jù)來說來回震蕩,學(xué)習(xí)率過小則對范圍大的數(shù)據(jù)來說基本沒什么變化。如下右圖所示,當進行歸一化后,特征都在同一個大小范圍,則loss landscape像一個碗,學(xué)習(xí)率更容易設(shè)置,且梯度下降比較平穩(wěn)。

在一個batch中,在每一BN層中,對每個樣本的同一通道,計算它們的均值和方差,再對數(shù)據(jù)進行歸一化,歸一化的值具有零均值和單位方差的特點,最后使用兩個可學(xué)習(xí)參數(shù)gamma和beta對歸一化的數(shù)據(jù)進行縮放和移位。此外,在訓(xùn)練過程中還保存了每個mini-batch每一BN層的均值和方差,最后求所有mini-batch均值和方差的期望值,以此來作為推理過程中該BN層的均值和方差。注:BN放在激活函數(shù)后比放在激活函數(shù)前效果更好。
實際效果:
1)與沒有BN相比,可使用更大的學(xué)習(xí)率
2)防止過擬合,可去除Dropout和Local Response Normalization
3)由于dataloader打亂順序,因此每個epoch中mini-batch都不一樣,對不同mini-batch做歸一化可以起到數(shù)據(jù)增強的效果。
4)明顯加快收斂速度
5)避免梯度爆炸和梯度消失
注:BN存在一些問題,后續(xù)的大部分歸一化論文,都是在圍繞BN的這些缺陷來改進的。為了行文的方便,這些缺陷會在后面各篇論文中逐一提到。
BN、LN、IN和GN的區(qū)別與聯(lián)系
下圖比較明顯地表示出了它們之間的區(qū)別。(N表示N個樣本,C表示通道,這里為了表達方便,把HxW的二維用H*W的一維表示。)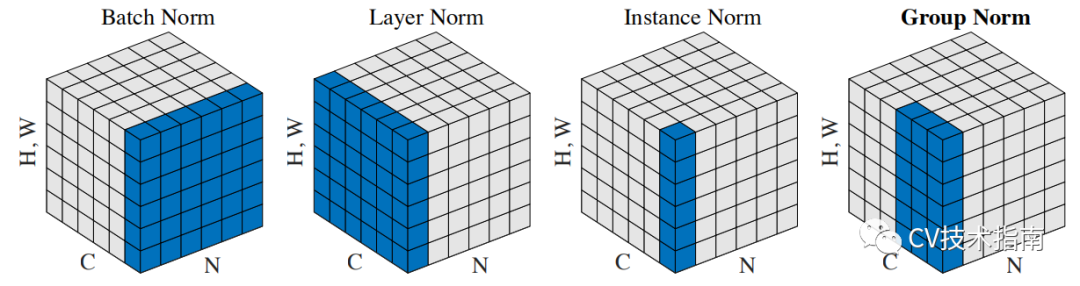
后面這三個解決的主要問題是BN的效果依賴于batch size,當batch size比較小時,性能退化嚴重。可以看到,IN,LN和GN都與batch size無關(guān)。它們之間的區(qū)別在于計算均值和方差的數(shù)據(jù)范圍不同,LN計算單個樣本在所有通道上的均值和方差,IN值計算單個樣本在每個通道上的均值和方差,GN將每個樣本的通道分成g組,計算每組的均值和方差。它們之間的效果對比。(注:這個效果是只在同一場合下的對比,實際上它們各有自己的應(yīng)用場景,且后三者在各自的應(yīng)用場合上都明顯超過了BN)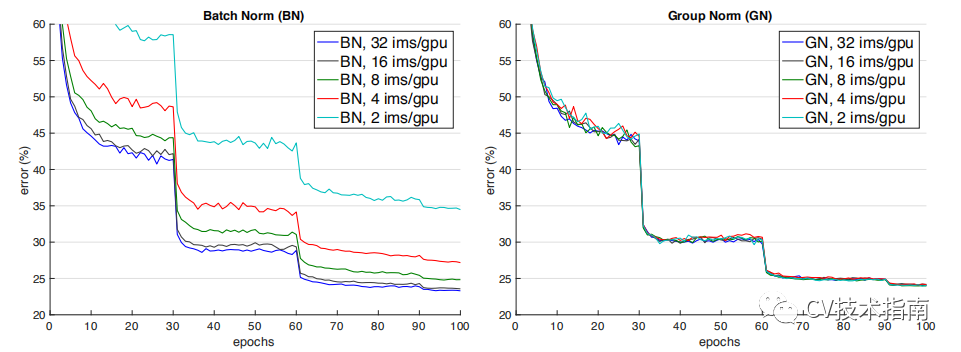
Instance Normalization(2016)
論文:Instance Normalization: The Missing Ingredient for Fast Stylization
在圖像視頻等識別任務(wù)上,BN的效果是要優(yōu)于IN的。但在GAN,style transfer和domain adaptation這類生成任務(wù)上,IN的效果明顯比BN更好。從BN與IN的區(qū)別來分析產(chǎn)生這種現(xiàn)象的原因:BN對多個樣本統(tǒng)計均值和方差,而這多個樣本的domain很可能是不一樣的,相當于模型把不同domain的數(shù)據(jù)分布進行了歸一化。
Layer Normalization (2016)
論文:Layer Normalization
BN的第一個缺陷是依賴Batch size,第二個缺陷是對于RNN這樣的動態(tài)網(wǎng)絡(luò)效果不明顯,且當推理序列長度超過訓(xùn)練的所有序列長度時,容易出問題。為此,提出了Layer Normalization。當我們以明顯的方式將批歸一化應(yīng)用于RNN時,我們需要為序列中的每個時間步計算并存儲單獨的統(tǒng)計信息。如果測試序列比任何訓(xùn)練序列都長,這是有問題的。LN沒有這樣的問題,因為它的歸一化項僅取決于當前時間步長對層的總輸入。它還只有一組在所有時間步中共享的增益和偏置參數(shù)。(注:LN中的增益和偏置就相當于BN中的gamma 和beta)LN的應(yīng)用場合:RNN,transformer等。
Group Normalization(2018)
論文:Group Normalization
如下圖所示,當batch size減少時,BN退化明顯,而Group Normalization始終一致,在batch size比較大的時候,略低于BN,但當batch size比較小的時候,明顯優(yōu)于BN。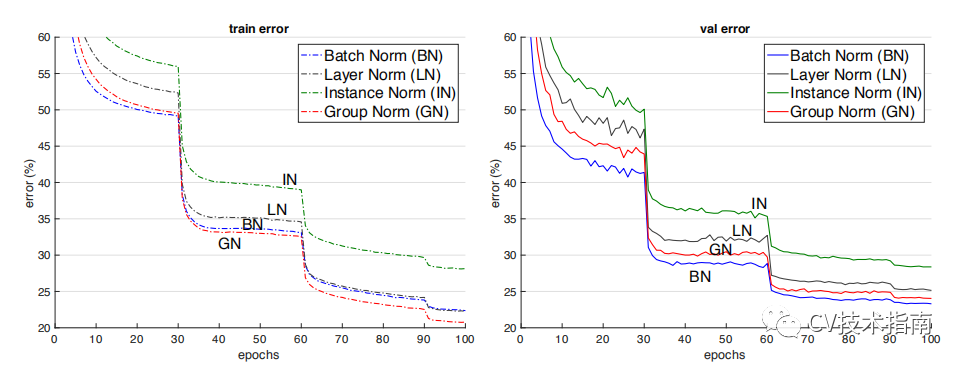
但GN有兩個缺陷,其中一個是在batchsize大時略低于BN,另一個是由于它是在通道上分組,因此它要求通道數(shù)是分組數(shù)g的倍數(shù)。GN應(yīng)用場景:在目標檢測,語義分割等要求盡可能大的分辨率的任務(wù)上,由于內(nèi)存限制,為了更大的分辨率只能取比較小的batch size,可以選擇GN這種不依賴于batchsize的歸一化方法。

Weights Normalization(2016)
論文:Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
前面的方法都是基于feature map做歸一化,這篇論文提出對Weights做歸一化。解釋這個方法要費挺多筆墨,這里用一句話來解釋其主要做法:將權(quán)重向量w分解為一個標量g和一個向量v,標量g表示權(quán)重向量w的長度,向量v表示權(quán)重向量的方向。這種方式改善了優(yōu)化問題的條件,并加速了隨機梯度下降的收斂,不依賴于batch size的特點,適用于循環(huán)模型(如 LSTM)和噪聲敏感應(yīng)用(如深度強化學(xué)習(xí)或生成模型),而批量歸一化不太適合這些應(yīng)用。Weight Normalization也有個明顯的缺陷:WN不像BN有歸一化特征尺度的作用,因此WN的初始化需要慎重,為此作者提出了對向量v和標量g的初始化方法。
Batch Renormalization(2017)
論文:Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models
前面我們提到BN使用訓(xùn)練過程中每個mini-batch的均值和方差的期望作為推理過程中的均值和方差,這樣做的前提是mini-batch與樣本總體是獨立同分布的。因此BN的第三個缺陷是當mini-batch中的樣本非獨立同分布時,性能比較差。基于第一個缺陷batchsize太小時性能退化和第三個缺陷,作者提出了Batch Renormalization(簡稱BRN)。BRN與BN的主要區(qū)別在于BN使用訓(xùn)練過程中每個mini-batch的均值和方差的期望來當作整個數(shù)據(jù)集的均值和方差,而訓(xùn)練過程中每個mini-batch都有自己的均值和方差,因此在推理階段的均值和方差與訓(xùn)練時不同,而BRN提出在訓(xùn)練過程中就不斷學(xué)習(xí)修正整個數(shù)據(jù)集的均值和方差,使其盡可能逼近整個數(shù)據(jù)集的均值和方差,并最終用于推理階段。
BRN實現(xiàn)算法如下:

注:這里r和d表示尺度縮放和平移,不參與反向傳播。
當使用小batchsize或非獨立同分布的mini-batch進行訓(xùn)練時,使用BRN訓(xùn)練的模型的性能明顯優(yōu)于BN。同時,BRN保留了BN的優(yōu)勢,例如對初始化的敏感性和訓(xùn)練效率
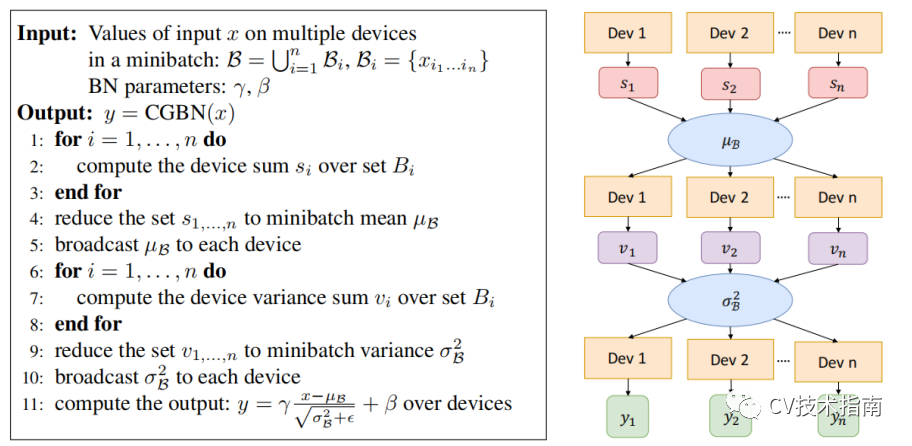
Cross-GPU BN(2018)
論文:MegDet: A Large Mini-Batch Object Detector
在使用多卡分布式訓(xùn)練的情況下,輸入數(shù)據(jù)被等分成多份,在各自的卡上完成前向和回傳,參數(shù)更新,BN是針對單卡上的樣本做的歸一化,因此實際的歸一化的樣本數(shù)并不是batchsize。例如batchsize=32,用四張卡訓(xùn)練,實際上只在32/4=8個樣本上做歸一化。Cross-GPU Batch Normalization的思想就是在多張卡上做歸一化。
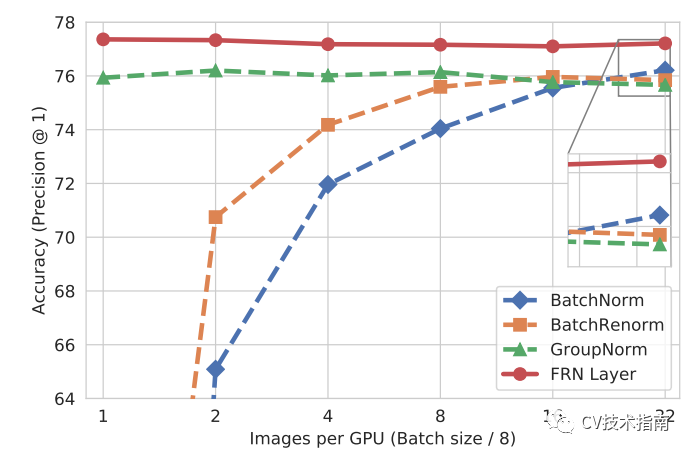
FRN(2019)
論文:Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
FRN仍然是基于小batchsize會退化性能的問題改進的。FRN由兩個組件構(gòu)成,一個是Filter Response Normalization (FRN),一個是Thresholded Linear Unit (TLU)。前者跟Instance Normalization非常相似,也是基于單樣本單通道,所不同的是IN減去了均值,再除以標準差。而FRN沒有減去均值。作者給出的理由如下:雖然減去均值是歸一化方案的正常操作,但對于batch independent的歸一化方案來說,它是任意的,沒有任何理由。TLU則是在ReLU的基礎(chǔ)上加了一個閾值,這個閾值是可學(xué)習(xí)的參數(shù)。這是考慮到FRN沒有減去均值的操作,這可能使得歸一化的結(jié)果任意地偏移0,如果FRN之后是ReLU激活層,可能產(chǎn)生很多0值,這對于模型訓(xùn)練和性能是不利的。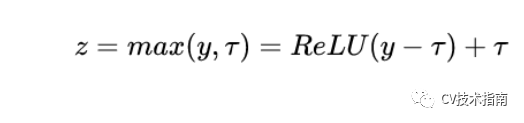

Cross-Iteration BN(2020)
論文:Cross-Iteration Batch Normalization
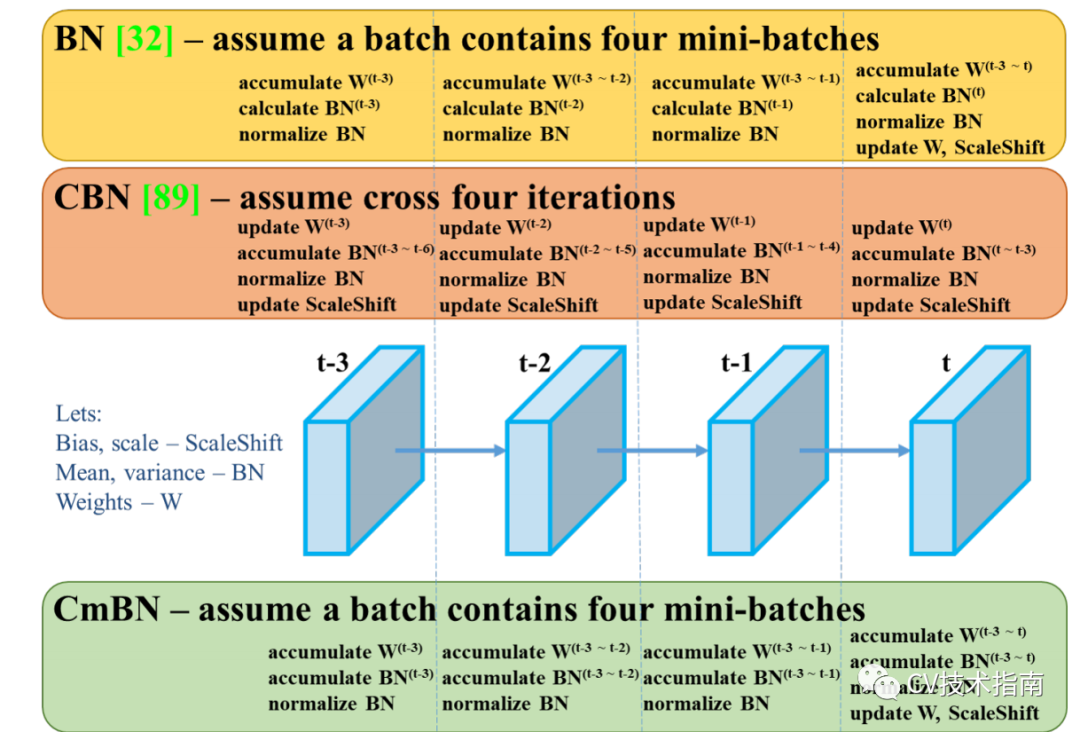
CBN的主要思想在于將前k-1個iteration的樣本參與當前均值和方差的計算。但由于前k-1次iteration的數(shù)據(jù)更新,因此無法直接拿來使用。論文提出了一個處理方式是通過泰勒多項式來近似計算出前k-1次iteration的數(shù)據(jù)。在Yolo_v4中還提出改進版,在每個batch中只統(tǒng)計四個mini-batches的數(shù)據(jù),并在第四個mini-batch后才更新權(quán)重,尺度縮放和偏移。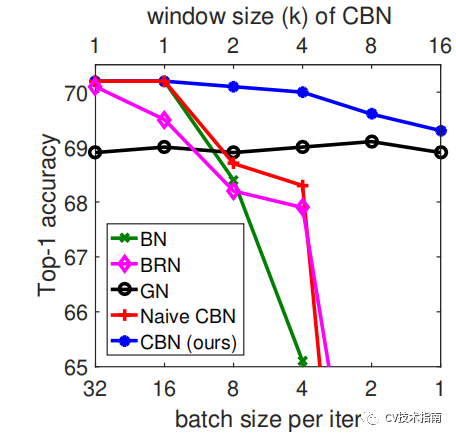
本文介紹了目前比較經(jīng)典的歸一化方法,其中大部分都是針對BN改進而來,本文比較詳盡地介紹了它們的主要思想,改進方式,以及應(yīng)用場景,部分方法并沒有詳細介紹實現(xiàn)細節(jié),對于感興趣或有需要的讀者請自行閱讀論文原文。除了以上方法外,還有很多歸一化方法,例如Eval Norm,Normalization propagation,Normalizing the normalizers等。但這些方法并不常用,這里不作贅述。