
Elasticseatch筆記(基礎(chǔ)篇)
本文公眾號(hào)來(lái)源:Echo1024
作者:賜我白日夢(mèng)
本文已收錄至我的GitHub
【對(duì)線面試官】系列?一周兩篇持續(xù)更新中!
1.1、認(rèn)識(shí)ES
關(guān)系型數(shù)據(jù)庫(kù):
像MySQL這種數(shù)據(jù)庫(kù)就是傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)。它有個(gè)很直觀的特點(diǎn):每一張數(shù)據(jù)表的列在創(chuàng)建表的時(shí)候就需要確定下來(lái)。比如你創(chuàng)建一個(gè)user表,定義了3列id、username、password。這時(shí)如果你的實(shí)體類中多了一個(gè)age的字段,那這個(gè)實(shí)體是不能保存進(jìn)user表的。(當(dāng)然后續(xù)你可以通過(guò)DDL修改添加列或者減少列。讓實(shí)體類的屬性和表中的列一一對(duì)應(yīng))。
非關(guān)系型數(shù)據(jù)庫(kù):
非關(guān)系型數(shù)據(jù)庫(kù)也就是我們常聽說(shuō)的NoSQL。常見的有:MongoDB、Redis、Elasticsearch。
且不說(shuō)性能方面,單說(shuō)使用方面NoSQL這種非關(guān)系類型的數(shù)據(jù)庫(kù)都支持你往它里面存儲(chǔ)一個(gè)json對(duì)象,這個(gè)json有多少個(gè)字段并不是它關(guān)系的,拿上面的例子來(lái)說(shuō),只要你給他一個(gè)對(duì)象,不管有沒有age、它都能幫你存儲(chǔ)進(jìn)去。
關(guān)于ES更多的知識(shí)點(diǎn)我們?cè)谙挛闹姓归_,再說(shuō)一下ES常見的使用場(chǎng)景和特性:
站內(nèi)搜索:
如果你的公司想做自己的站內(nèi)搜索,那ES再合適不過(guò)了。作為非關(guān)系型數(shù)據(jù)庫(kù)的ES允許你往它里面存儲(chǔ)各種格式不確定的Json對(duì)象,還為你提供了全文本搜索和分析引擎。它使您可以快速,近乎實(shí)時(shí)地(1 s)存儲(chǔ),搜索和分析大量數(shù)據(jù)。一個(gè)字:快!
日志采集系統(tǒng):
Elasticsearch是Elastic公司的核技術(shù),并且Elastic公司還有其他諸如:Logstash、Filebeat、Kibana等技術(shù)棧。常見的公司里面使用的日志管理系統(tǒng)就可以使用ELK+Filebeat搭建起來(lái),F(xiàn)ilebeat收集日志推送到Logstash做處理,然后Logstash將數(shù)據(jù)存儲(chǔ)入ES,最終通過(guò)Kibana展示日志。
可擴(kuò)展性:
Elasticsearch天生就是分布式的,既能以單機(jī)的形式運(yùn)行一臺(tái)性能很差的服務(wù)器上。它也可以形成一個(gè)成百上千節(jié)點(diǎn)的集群。并且它自己會(huì)管理集群中的節(jié)點(diǎn),在ES中我們可以隨意的添加、摘除節(jié)點(diǎn),集群自己會(huì)將數(shù)據(jù)均攤在各個(gè)節(jié)點(diǎn)上。
1.2、安裝、啟動(dòng)ES、Kibana、IK分詞器
安裝很簡(jiǎn)單,所以詳細(xì)過(guò)程不會(huì)寫到文章中。 安裝啟動(dòng)教程、ES、Kibana、IK分詞器安裝包都以百度網(wǎng)盤的方式分享給大家,后臺(tái)回復(fù):es 可領(lǐng)取
二、核心概念
因?yàn)檫@是第一篇基礎(chǔ)篇,對(duì)小白友好一些,所以需要先了解一些基本概念,你可以耐折性子讀一下,都不難理解的哈。
2.1、Near Realtime (NRT)
ES號(hào)稱對(duì)外提供的是近實(shí)時(shí)的搜索服務(wù),意思是數(shù)據(jù)從寫入ES到可以被Searchable僅僅需要1秒鐘,所以說(shuō)基于ES執(zhí)行的搜索和分析可以達(dá)到秒級(jí)。
2.2、Cluster
集群:集群是一個(gè)或多個(gè)node的集合,它們一起保存你存放進(jìn)去的數(shù)據(jù),用戶可以在所有的node之間進(jìn)行檢索,一般的每個(gè)集群都會(huì)有一個(gè)唯一的名稱標(biāo)識(shí),默認(rèn)的名稱標(biāo)識(shí)為 elasticsearch ,這個(gè)名字很重要,因?yàn)閚ode想加入cluster時(shí),需要這個(gè)名稱信息。
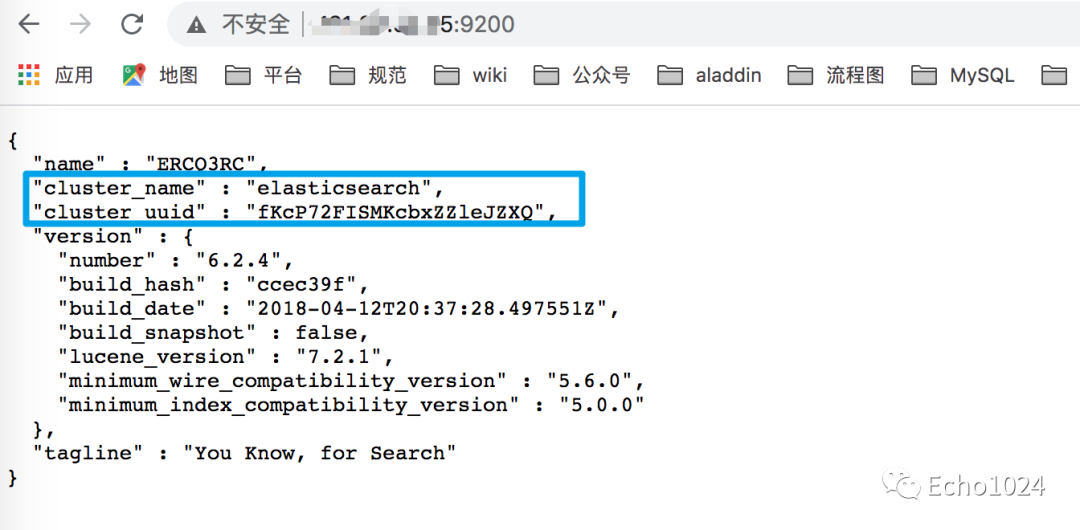
確保別在不同的環(huán)境中使用相同的集群名稱,進(jìn)而避免node加錯(cuò)集群的情況,一顆考慮下面的集群命名風(fēng)格logging-stage和logging-dev和logging-pro。
2.3、Node
單臺(tái)server就是一個(gè)node,它和cluster一樣,也存在一個(gè)默認(rèn)的名稱。但是它的名稱是通過(guò)UUID生成的隨機(jī)串,當(dāng)然用戶也可以定制不同的名稱,但是這個(gè)名字最好別重復(fù)。這個(gè)名稱對(duì)于管理來(lái)說(shuō)很在乎要,因?yàn)樾枰_定,當(dāng)前網(wǎng)絡(luò)中的哪臺(tái)服務(wù)器,對(duì)應(yīng)這個(gè)集群中的哪個(gè)節(jié)點(diǎn)。
node存在一個(gè)默認(rèn)的設(shè)置,默認(rèn)的,當(dāng)每一個(gè)node在啟動(dòng)時(shí)都會(huì)自動(dòng)的去加入一個(gè)叫elasticsearch的節(jié)點(diǎn),這就意味著,如果用戶在網(wǎng)絡(luò)中啟動(dòng)了多個(gè)node,它們會(huì)彼此發(fā)現(xiàn),然后組成集群。
在單個(gè)的cluster中,你可以擁有任意多的node。假如說(shuō)你的網(wǎng)絡(luò)上沒有其它正在運(yùn)行的節(jié)點(diǎn),然后你啟動(dòng)一個(gè)新的節(jié)點(diǎn),這個(gè)新的節(jié)點(diǎn)自己會(huì)組建一個(gè)集群。
2.4、Index
index是一類擁有相似屬性的document的集合。比如你可以為消費(fèi)者的數(shù)據(jù)創(chuàng)建一個(gè)index,為產(chǎn)品創(chuàng)建一個(gè)index,為訂單創(chuàng)建一個(gè)index。
index名稱(必須是小寫的字符)。?當(dāng)需要對(duì)index中的文檔執(zhí)行索引、搜索、更新、刪除、等操作時(shí),都需要用到這個(gè)index。
理論上:你可以在一個(gè)集群中創(chuàng)建任意數(shù)量的index。
2.5、Type
Type可以作為index中的邏輯類別。為了更細(xì)的劃分,比如用戶數(shù)據(jù)type、評(píng)論數(shù)據(jù)type、博客數(shù)據(jù)type
在設(shè)計(jì)時(shí)盡最大努力讓擁有更多相同field的document劃分到同一個(gè)type下。
2.6、Document
document就是ES中存儲(chǔ)的一條數(shù)據(jù),就像mysql中的一行記錄一樣。它可以是一條用戶的記錄、一個(gè)商品的記錄等等
2.7、一個(gè)不嚴(yán)謹(jǐn)?shù)男〗Y(jié):
為什么說(shuō)這是不嚴(yán)謹(jǐn)?shù)男〗Y(jié)呢? 就是說(shuō)下面三個(gè)對(duì)應(yīng)關(guān)系只能說(shuō)的從表面上看起來(lái)比較相似。但是ES中的type其實(shí)是一個(gè)邏輯上的劃分。數(shù)據(jù)在存儲(chǔ)是時(shí)候依然是混在一起存儲(chǔ)的(往下看下文中有寫),而mysql中的不同表的兩個(gè)列是絕對(duì)沒有關(guān)系的。
| Elasticsearch | 關(guān)系型數(shù)據(jù)庫(kù) |
|---|---|
| Document | 行 |
| type | 表 |
| index | 數(shù)據(jù)庫(kù) |
2.8、Shards & Replicas
2.8.1、問(wèn)題引入:
如果讓一個(gè)Index自己存儲(chǔ)1TB的數(shù)據(jù),響應(yīng)的速度就會(huì)下降。為了解決這個(gè)問(wèn)題,ES提供了一種將用戶的Index進(jìn)行subdivide的騷操作,就是將index分片,每一片都叫一個(gè)Shards,進(jìn)而實(shí)現(xiàn)了將整體龐大的數(shù)據(jù)分布在不同的服務(wù)器上存儲(chǔ)。
2.8.2、什么是shard?
shard分成replica shard和primary shard。顧名思義一個(gè)是主shard、一個(gè)是備份shard, 負(fù)責(zé)容錯(cuò)以及承擔(dān)部分讀請(qǐng)求。
shard可以理解成是ES中最小的工作單元。所有shard中的數(shù)據(jù)之和,才是整個(gè)ES中存儲(chǔ)的數(shù)據(jù)。可以把shard理解成是一個(gè)luncene的實(shí)現(xiàn),擁有完整的創(chuàng)建索引,處理請(qǐng)求的能力。
下圖是兩個(gè)node,6個(gè)shard的組成的集群的劃分情況:
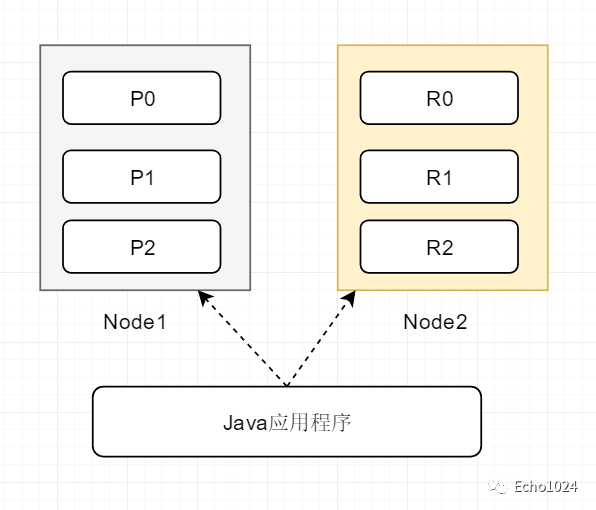
你可以看一下上面的圖,圖中無(wú)論java應(yīng)用程序訪問(wèn)的是node1還是node2,其實(shí)都能獲取到數(shù)據(jù)。
2.8.3、shard的默認(rèn)數(shù)量
新創(chuàng)建的節(jié)點(diǎn)會(huì)存在5個(gè)primary shard,注意!后續(xù)不然能再改動(dòng)primary shard的值,如果每一個(gè)primary shard都對(duì)應(yīng)一個(gè)replica shard,按理說(shuō)單臺(tái)es啟動(dòng)就會(huì)存在10個(gè)分片,但是現(xiàn)實(shí)是,同一個(gè)節(jié)點(diǎn)的replica shard和primary shard不能存在于一個(gè)server中,因此單臺(tái)es默認(rèn)啟動(dòng)后的分片數(shù)量還是5個(gè)。
2.8.4、如何拓容Cluster
首先明確一點(diǎn):一旦index創(chuàng)建完成了,primary shard的數(shù)量就不可能再發(fā)生變化。
因此橫向拓展就得添加replica的數(shù)量, 因?yàn)?span style="color: rgb(255, 104, 39);">replica shard的數(shù)量后續(xù)是可以改動(dòng)的。也就是說(shuō),如果后續(xù)我們將它的數(shù)量改成了2, 就意味著讓每個(gè)primary shard都擁有了兩個(gè)replica shard, 計(jì)算一下: 5+5*2=15 集群就會(huì)拓展成15個(gè)節(jié)點(diǎn)。
如果想讓每一個(gè)shard都有最多的系統(tǒng)的資源就增加服務(wù)器的數(shù)量,讓每一個(gè)shard獨(dú)占一個(gè)服務(wù)器。
2.8.5、舉個(gè)例子:
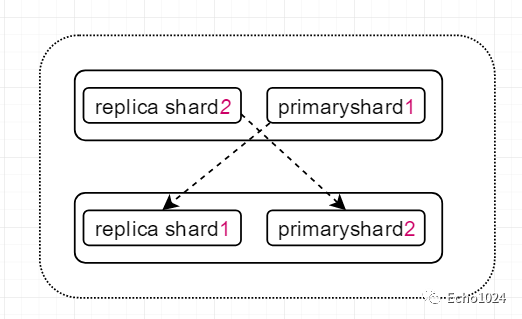
上圖中存在上下兩個(gè)node,每個(gè)node中都有一個(gè) 自己的primary shard和其它節(jié)點(diǎn)的replica shard,為什么是強(qiáng)調(diào)自己和其它呢? 因?yàn)镋S中規(guī)定,同一個(gè)節(jié)點(diǎn)的replica shard和primary shard不能存在于一個(gè)server中,而不同節(jié)點(diǎn)的primary shard可以存在于同一個(gè)server上。
當(dāng)primary shard宕機(jī)時(shí),因?yàn)樗鼘?duì)應(yīng)的replicas shard在其它的server沒有受到影響,所以ES可以繼續(xù)響應(yīng)用戶的讀請(qǐng)求。通過(guò)這種分片的機(jī)制,并且分片的地位相當(dāng),假設(shè)單個(gè)shard可以處理2000/s的請(qǐng)求,通過(guò)橫向拓展可以在此基礎(chǔ)上成倍提升系統(tǒng)的吞吐量,天生分布式,高可用。
此外: 每一個(gè)document肯定存在于一個(gè)primary shard和這個(gè)primary shard 對(duì)應(yīng)的replica shard中, 絕對(duì)不會(huì)出現(xiàn)同一個(gè)document同時(shí)存在于多個(gè)primary shard中的情況。
三、入門探索:
下面的小節(jié)中你會(huì)看到我使用大量的GET / POST 等等包括什么query。其實(shí)你不用詫異為啥整一堆這些東西而不寫點(diǎn)代碼。
其實(shí)這些命令對(duì)于ES來(lái)說(shuō),就像是SQL和MySQL的關(guān)系。換句話說(shuō),其實(shí)你寫的代碼的底層幫你執(zhí)行的也是我下面說(shuō)得的這些命令。所以,別怕麻煩,下面的這些知識(shí)點(diǎn)無(wú)論如何你都不能直接跨越過(guò)去。
3.1、集群的健康狀況
GET /_cat/health?v
執(zhí)行結(jié)果如下:
epoch??????timestamp?cluster???????status?node.total?node.data?shards?pri?relo?init?unassign?pending_tasks?max_task_wait_time?active_shards_percent
1572595632?16:07:12??elasticsearch?yellow??????????1?????????1??????5???5????0????0????????5?????????????0??????????????????-?????????????????50.0%
解讀上面的信息,默認(rèn)的集群名是elasticsearch,當(dāng)前集群的status是yellow,后續(xù)列出來(lái)的是集群的分片信息,最后一個(gè)active_shards_percent表示當(dāng)前集群中僅有一半shard是可用的。
狀態(tài):
存在三種狀態(tài)分別是:red、green、yellow
green : 表示當(dāng)前集群所有的節(jié)點(diǎn)全部可用。 yellow: 表示ES中所有的數(shù)據(jù)都是可以訪問(wèn)的,但是并不是所有的replica shard都是可以使用的(我現(xiàn)在是默認(rèn)啟動(dòng)一個(gè)node,而ES又不允許同一個(gè)node的primary shard和replica shard共存,因此我當(dāng)前的node中僅僅存在5個(gè)primary shard,為status為黃色)。 red: 集群宕機(jī),數(shù)據(jù)不可訪問(wèn)。
3.2、集群的索引信息
GET /_cat/indices?v
結(jié)果:
health?status?index??????????????uuid???????????????????pri?rep?docs.count?docs.deleted?store.size?pri.store.size
yellow?open???ai_answer_question?cl_oJNRPRV-bdBBBLLL05g???5???1?????203459????????????0????172.3mb????????172.3mb
顯示狀態(tài)為yellow,表示存在replica shard不可用, 存在5個(gè)primary shard,并且每一個(gè)primary shard都有一個(gè)replica shard , 一共20多萬(wàn)條文檔,未刪除過(guò)文檔,文檔占用的空間情況為172.3兆。
3.3、創(chuàng)建index
PUT /customer?pretty
ES 使用的RestfulAPI,新增使用put,這是個(gè)很親民的舉動(dòng)。
3.4、添加 or 修改
如果是ES中沒有過(guò)下面的數(shù)據(jù)則添加進(jìn)去,如果存在了id=1的元素就修改(全量替換)。
格式: PUT /index/type/id
全量替換時(shí),原來(lái)的document是沒有被刪除的!而是被標(biāo)記為deleted,被標(biāo)記成的deleted是不會(huì)被檢索出來(lái)的,當(dāng)ES中數(shù)據(jù)越來(lái)越多時(shí),才會(huì)刪除它。
PUT /customer/_doc/1?pretty
{
"name": "John Doe"
}
響應(yīng):
{
??"_index":?"customer",
??"_type":?"_doc",
??"_id":?"1",
??"_version":?1,
??"result":?"created",
??"_shards":?{
????"total":?2,
????"successful":?1,
????"failed":?0
??},
??"_seq_no":?0,
??"_primary_term":?1
}
強(qiáng)制創(chuàng)建,加添_create或者?op_type=create。
PUT?/customer/_doc/1?op_type=create
PUT?/customer/_doc/1/_create
局部更新(Partial Update)
不指定id則新增document。
POST?/customer/_doc?pretty
{
??"name":?"Jane?Doe"
}
指定id則進(jìn)行doc的局部更新操作。
POST /customer/_doc/1?pretty
{
"name": "Jane Doe"
}
并且POST相對(duì)于上面的PUT而言,不論是否存在相同內(nèi)容的doc,只要不指定id,都會(huì)使用一個(gè)隨機(jī)的串當(dāng)成id,完成doc的插入。
Partial Update先獲取document,再將傳遞過(guò)來(lái)的field更新進(jìn)document的json中,將老的doc標(biāo)記為deleted,再將創(chuàng)建document,相對(duì)于全量替換中間會(huì)省去兩次網(wǎng)絡(luò)請(qǐng)求
3.5、檢索
格式: GET /index/type/
GET /customer/_doc/1?pretty
響應(yīng):
{
??"_index":?"customer",
??"_type":?"_doc",
??"_id":?"1",
??"_version":?1,
??"found":?true,
??"_source":?{
????"name":?"John?Doe"
??}
}
3.6、刪除
刪除一條document。
大部分情況下,原來(lái)的document不會(huì)被立即刪除,而是被標(biāo)記為deleted,被標(biāo)記成的deleted是不會(huì)被檢索出來(lái)的,當(dāng)ES中數(shù)據(jù)越來(lái)越多時(shí),才會(huì)刪除它。
DELETE /customer/_doc/1
響應(yīng):
{
??"_index":?"customer",
??"_type":?"_doc",
??"_id":?"1",
??"_version":?2,
??"result":?"deleted",
??"_shards":?{
????"total":?2,
????"successful":?1,
????"failed":?0
??},
??"_seq_no":?1,
??"_primary_term":?1
}
刪除index
DELETE /index1
DELETE /index1,index2
DELETE /index*
DELETE /_all
可以在elasticsearch.yml中將下面這個(gè)設(shè)置置為ture,表示禁止使用 DELETE /_all
action.destructive_required_name:true
響應(yīng)
{
??"acknowledged":?true
}
3.6、更新文檔
上面說(shuō)了POST關(guān)鍵字,可以實(shí)現(xiàn)不指定id就完成document的插入, POST + _update關(guān)鍵字可以實(shí)現(xiàn)更新的操作。
POST?/customer/_doc/1/_update?pretty
{
??"doc":?{?"name":?"changwu"?}
}
POST+_update進(jìn)行更新的動(dòng)作依然需要指定id, 但是相對(duì)于PUT來(lái)說(shuō),當(dāng)使用POST進(jìn)行更新時(shí),id不存在的話會(huì)報(bào)錯(cuò),而PUT則會(huì)認(rèn)為這是在新增。
此外: 針對(duì)這種更新操作,ES會(huì)先刪除原來(lái)的doc,然后插入這個(gè)新的doc。
四、document api
4.1、search
檢索所有索引下面的所有數(shù)據(jù)
/_search
搜索指定索引下的所有數(shù)據(jù)
/index/_search
更多模式
/index1/index2/_search
/*1/*2/_search
/index1/index2/type1/type2/_search
/_all/type1/type2/_search
4.2、_mget api 批量查詢
mget是ES為我們提供的批量查詢的API,我們只需要制定好 index、type、id。ES會(huì)將命中的記錄批量返回給我們。
在docs中指定 _index,_type,_id
GET?/_mget
{
????"docs"?:?[
????????{
????????????"_index"?:?"test",
????????????"_type"?:?"_doc",
????????????"_id"?:?"1"
????????},
????????{
????????????"_index"?:?"test",
????????????"_type"?:?"_doc",
????????????"_id"?:?"2"
????????}
????]
}
在URL中指定index
GET?/test/_mget
{
????"docs"?:?[
????????{
????????????"_type"?:?"_doc",
????????????"_id"?:?"1"
????????},
????????{
????????????"_type"?:?"_doc",
????????????"_id"?:?"2"
????????}
????]
}
在URL中指定 index和type
GET?/test/type/_mget
{
????"docs"?:?[
????????{
????????????"_id"?:?"1"
????????},
????????{
????????????"_id"?:?"2"
????????}
在URL中指定index和type,并使用ids指定id范圍
GET?/test/type/_mget
{
????"ids"?:?["1",?"2"]
}
為不同的doc指定不同的過(guò)濾規(guī)則
GET?/_mget
{
????"docs"?:?[
????????{
????????????"_index"?:?"test",
????????????"_type"?:?"_doc",
????????????"_id"?:?"1",
????????????"_source"?:?false
????????},
????????{
????????????"_index"?:?"test",
????????????"_type"?:?"_doc",
????????????"_id"?:?"2",
????????????"_source"?:?["field3",?"field4"]
????????},
????????{
????????????"_index"?:?"test",
????????????"_type"?:?"_doc",
????????????"_id"?:?"3",
????????????"_source"?:?{
????????????????"include":?["user"],
????????????????"exclude":?["user.location"]
????????????}
????????}
????]
}
4.3、_bulk api 批量增刪改
4.3.1、基本語(yǔ)法
{"action":{"metadata"}}\n
{"data"}\n
存在哪些類型的操作可以執(zhí)行呢?
delete: 刪除文檔。
create: _create 強(qiáng)制創(chuàng)建。
index: 表示普通的put操作,可以是創(chuàng)建文檔也可以是全量替換文檔。
update: 局部替換。
上面的語(yǔ)法中并不是人們習(xí)慣閱讀的json格式,但是這種單行形式的json更具備高效的優(yōu)勢(shì)。
ES如何處理普通的json如下:
將json數(shù)組轉(zhuǎn)換為JSONArray對(duì)象,這就意味著內(nèi)存中會(huì)出現(xiàn)一份一模一樣的拷貝,一份是json文本,一份是JSONArray對(duì)象。
但是如果上面的單行JSON,ES直接進(jìn)行切割使用,不會(huì)在內(nèi)存中整一個(gè)數(shù)據(jù)拷貝出來(lái)。
4.3.2、delete
delete比較好看僅僅需要一行json就ok
{?"delete"?:?{?"_index"?:?"test",?"_type"?:?"_doc",?"_id"?:?"2"?}?}
4.3.3、create
兩行json,第一行指明我們要?jiǎng)?chuàng)建的json的index,type以及id
第二行指明我們要?jiǎng)?chuàng)建的doc的數(shù)據(jù)
{?"create"?:?{?"_index"?:?"test",?"_type"?:?"_doc",?"_id"?:?"3"?}?}
{?"field1"?:?"value3"?}
4.3.4、index
相當(dāng)于是PUT,可以實(shí)現(xiàn)新建或者是全量替換,同樣是兩行json。
第一行表示將要新建或者是全量替換的json的index type 以及 id。
第二行是具體的數(shù)據(jù)。
{?"index"?:?{?"_index"?:?"test",?"_type"?:?"_doc",?"_id"?:?"1"?}?}
{?"field1"?:?"value1"?}
4.3.5、update
表示 parcial update,局部替換。
它可以指定一個(gè)retry_on_conflict的特性,表示可以重試3次。
POST?_bulk
{?"update"?:?{"_id"?:?"1",?"_type"?:?"_doc",?"_index"?:?"index1",?"retry_on_conflict"?:?3}?}
{?"doc"?:?{"field"?:?"value"}?}
{?"update"?:?{?"_id"?:?"0",?"_type"?:?"_doc",?"_index"?:?"index1",?"retry_on_conflict"?:?3}?}
{?"script"?:?{?"source":?"ctx._source.counter?+=?params.param1",?"lang"?:?"painless",?"params"?:?{"param1"?:?1}},?"upsert"?:?{"counter"?:?1}}
{?"update"?:?{"_id"?:?"2",?"_type"?:?"_doc",?"_index"?:?"index1",?"retry_on_conflict"?:?3}?}
{?"doc"?:?{"field"?:?"value"},?"doc_as_upsert"?:?true?}
{?"update"?:?{"_id"?:?"3",?"_type"?:?"_doc",?"_index"?:?"index1",?"_source"?:?true}?}
{?"doc"?:?{"field"?:?"value"}?}
{?"update"?:?{"_id"?:?"4",?"_type"?:?"_doc",?"_index"?:?"index1"}?}
{?"doc"?:?{"field"?:?"value"},?"_source":?true}
4.4、滾動(dòng)查詢技術(shù)
如果你想一次性查詢好幾萬(wàn)條數(shù)據(jù),這么龐大的數(shù)據(jù)量,ES性能肯定會(huì)受到影響。這時(shí)可以選擇使用滾動(dòng)查詢(scroll)。一批一批的查詢,直到所有的數(shù)據(jù)被查詢完成。也就是說(shuō)它會(huì)先搜索一批數(shù)據(jù)再搜索一批數(shù)據(jù)。
示例如下:每次發(fā)送一次scroll請(qǐng)求,我們還需要指定一個(gè)scroll需要的參數(shù):一個(gè)時(shí)間窗口,每次搜索只要在這個(gè)時(shí)間窗口內(nèi)完成就ok。
GET?/index/type/_search?scroll=1m
{
????"query":{
????????"match_all":{}
????},
????"sort":["_doc"],
????"size":3
}
響應(yīng)
{
??"_scroll_id":?"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3",
??"took":?9,
??"timed_out":?false,
??"_shards":?{
????"total":?5,
????"successful":?5,
????"skipped":?0,
????"failed":?0
??},
??"hits":?{
????"total":?2,
????"max_score":?null,
????"hits":?[
??????{
????????"_index":?"my_index",
????????"_type":?"_doc",
????????"_id":?"2",
????????"_score":?null,
????????"_source":?{
??????????"title":?"This?is?another?document",
??????????"body":?"This?document?has?a?body"
????????},
????????"sort":?[
??????????0
????????]
??????},
??????{
????????"_index":?"my_index",
????????"_type":?"_doc",
????????"_id":?"1",
????????"_score":?null,
????????"_source":?{
??????????"title":?"This?is?a?document"
????????},
????????"sort":?[
??????????0
????????]
??????}
·????]
??}
}
查詢下一批數(shù)據(jù)時(shí),需要攜帶上一次scroll返回給我們的_scroll_id再次滾動(dòng)查詢
GET?/_search/scroll
{
????"scroll":"1m",
????"_scroll_id":?"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3"
}
滾動(dòng)查詢時(shí),如果采用基于_doc的排序方式會(huì)獲得較高的性能。

添加我的私人微信【sanwaiyihao】進(jìn)一步交流和學(xué)習(xí)
【對(duì)線面試官】系列?一周兩篇持續(xù)更新中!