
「知識(shí)復(fù)盤」初中級(jí)前端值得收藏的正則表達(dá)式知識(shí)點(diǎn)掃盲


本文是思維導(dǎo)圖學(xué)前端系列第二篇,主題是正則表達(dá)式。首先還是想說下我的出發(fā)點(diǎn),之所以自己畫一遍思維導(dǎo)圖,是因?yàn)槲艺淼乃季S導(dǎo)圖里加入了自己的理解,更容易記憶。之前也看過很多別人整理的思維導(dǎo)圖,雖然有點(diǎn)撥之用,但是要想吸收個(gè)二三分營養(yǎng)卻也是很難。
所以,建議本系列的讀者在閱讀文章之后,在時(shí)間允許的情況下,可以考慮自行整理知識(shí)點(diǎn),便于更好地理解和吸收。
推薦下同系列文章:
「思維導(dǎo)圖學(xué)前端」6k字一文搞懂Javascript對(duì)象,原型,繼承[1]
很多前端新手在遇到正則表達(dá)式時(shí)都望而卻步,我自己初學(xué)時(shí),也基本上是直接跳過了正則表達(dá)式這一章,除了copy網(wǎng)上的一些常用的正則表達(dá)式做表單校驗(yàn),其余時(shí)候幾乎沒有去了解過如何寫一個(gè)正則表達(dá)式。
但是,當(dāng)自己真正要去寫一個(gè)適合特定業(yè)務(wù)的正則表達(dá)式時(shí),我發(fā)現(xiàn)自己掌握的正則表達(dá)式知識(shí)真的是捉襟見肘。所以我這里也用思維導(dǎo)圖整理了一些正則表達(dá)式必知必會(huì)的知識(shí)點(diǎn)。
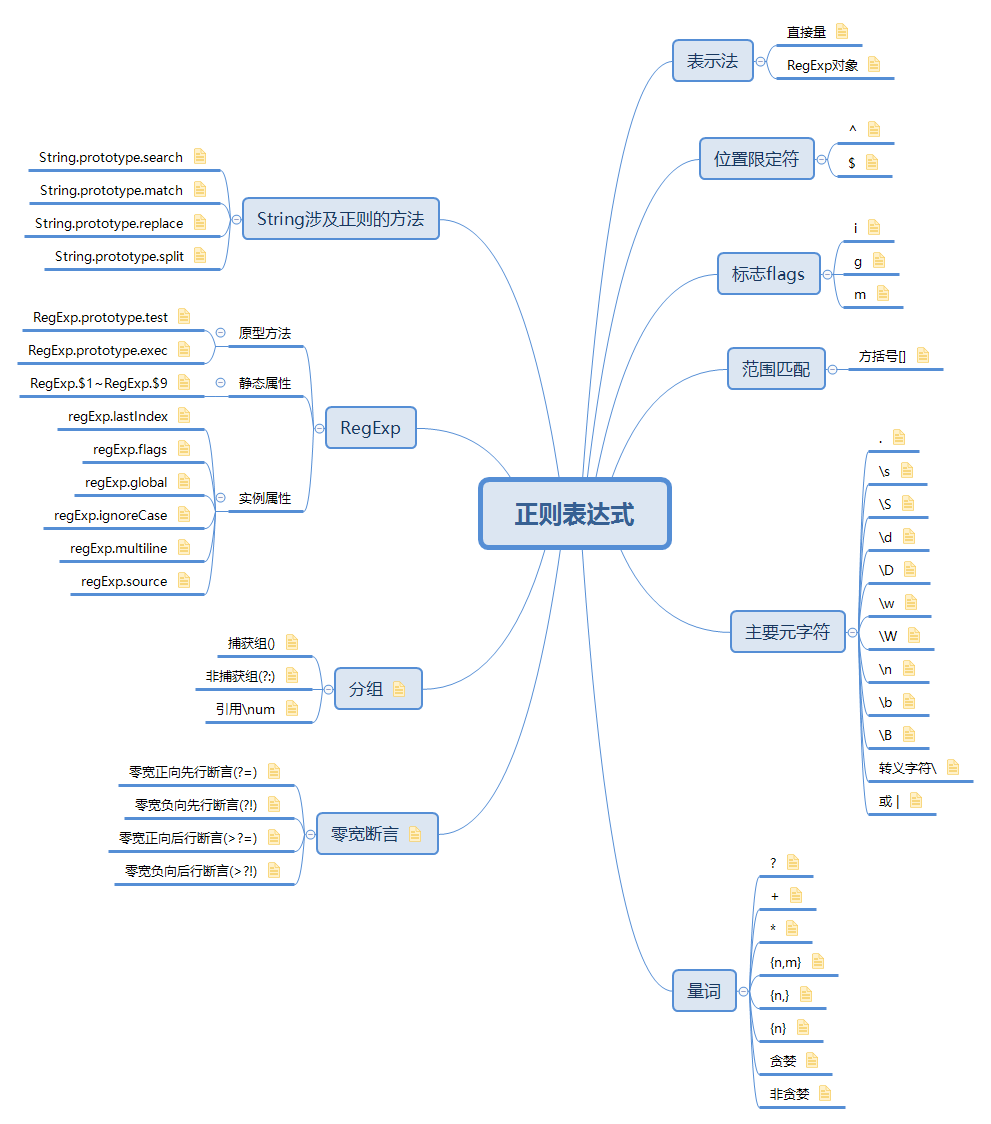
什么是正則表達(dá)式
正則表達(dá)式[2],又稱規(guī)則表達(dá)式。(英語:Regular Expression,在代碼中常簡寫為regex、regexp或RE),計(jì)算機(jī)科學(xué)的一個(gè)概念。正則表達(dá)式通常被用來檢索、替換那些符合某個(gè)模式(規(guī)則)的文本。
在軟件開發(fā)過程中,我們或多或少會(huì)接觸到正則表達(dá)式,對(duì)于前端而言,正則表達(dá)式不僅可以校驗(yàn)表單,文本查找和替換,還可以做語法解析器,用于AST,編輯器等領(lǐng)域。
正則表示法
直接量表示法
直接量也稱為字面量,寫法如下:
/^\d+$/g
直接量寫法的正則表達(dá)式在執(zhí)行時(shí)會(huì)轉(zhuǎn)換為一個(gè)新的RegExp對(duì)象。我想應(yīng)該是因?yàn)橹苯恿渴菦]有調(diào)用方法的能力的,只有轉(zhuǎn)為了對(duì)象,才使得調(diào)用方法成為可能。所以才有了/^\d+$/.test()。
當(dāng)在循環(huán)中用到正則對(duì)象lastIndex判斷終止條件時(shí),一定不要使用直接量正則表達(dá)式寫法,否則每次循環(huán)lastIndex都會(huì)被重置為0,這是因?yàn)槊看螆?zhí)行字面量正則表達(dá)式時(shí),都會(huì)轉(zhuǎn)換為一個(gè)新的RegExp對(duì)象,相應(yīng)的lastIndex當(dāng)然也會(huì)變成0。
RegExp對(duì)象表示法
var pattern = new RegExp(/^\d+$/, 'g')
第一個(gè)參數(shù)可以接受正則表達(dá)式直接量,也可以接受字符串,傳遞字符串作為第一個(gè)參數(shù)時(shí),首尾不需要帶斜杠,字符串中如果用到特殊字符\,需要在\前再加一個(gè)\,防止\在字符串中被轉(zhuǎn)義。
"\s" === "s" // true
字符串"\\s"才能正確地表示\s
第二個(gè)參數(shù)代表標(biāo)志flags,可接受的標(biāo)志有i, g, m等。
標(biāo)志flags
i
如果啟用了標(biāo)志i,正則表達(dá)式在執(zhí)行時(shí)不區(qū)分大小寫。
/abc/i.test('abc')等價(jià)于/abc/i.test('ABC')
g
如果啟用了標(biāo)志g,正則表達(dá)式會(huì)執(zhí)行全局匹配,匹配到一個(gè)結(jié)果后不會(huì)立刻停止匹配,直到后續(xù)沒有任何符合匹配規(guī)則的字符為止。
m
如果啟用了標(biāo)志m,正則表達(dá)式會(huì)執(zhí)行多行匹配,^可以匹配每一行的開始或整個(gè)字符串的開始,而$可以匹配每一行的結(jié)束或整個(gè)字符串的結(jié)束。
示例如下:
/^\d+$/.test('123\n456') // false
/^\d+$/m.test('123\n456') // true
仍然可以匹配整個(gè)字符串
/^\d+\n\d+$/m.test('123\n45') // true
位置限定符
^
匹配字符的開始。比如必須以數(shù)字開始,可以這么寫:
/^\d/
$
匹配字符的結(jié)束。比如必須以數(shù)字結(jié)束,可以這么寫:
/\d$/
范圍匹配
范圍匹配是利用方括號(hào)[]實(shí)現(xiàn)的。
方括號(hào)[]用于范圍匹配,也就是查找某個(gè)范圍內(nèi)的字符。比如[0-9]代表匹配數(shù)字,而[a-z]可以匹配小寫字母a到z這26個(gè)字符中的任意一個(gè)。
如果要匹配不在方括號(hào)中的字符,可以在方括號(hào)中以^開頭,比如[^0-9],用于匹配非數(shù)字,等價(jià)于\D。
主要元字符
.
匹配除換行符\n外的任意字符,如果要匹配任意字符,應(yīng)該用/[.\n]*/。
\s
匹配任意空字符,包括空格,制表符\t,垂直制表符\v,換行符\n,回車符\r,換頁符\f。\s等價(jià)于[ \t\v\n\r\f],注意方括號(hào)內(nèi)第一個(gè)位置有空格。
這里也說下?lián)Q行符和回車符的區(qū)別:
換行符 \n:光標(biāo)下移一行,不回行首。回車符 \r:光標(biāo)回到行首,不換行。
\S
\S是\s的反集
,利用\s和\S的這種互為反集的關(guān)系,我們就可以匹配任意字符,寫法如下:
/[\s\S]/
\d
\d用于匹配數(shù)字,等價(jià)于[0-9]。
\D
\D是\d的反集,也就是匹配非數(shù)字,等價(jià)于[^0-9]。
\w
\w用于匹配單詞字符,包含0-9,a-z,A-z以及下劃線_,等價(jià)于[A-Za-z0-9_]。
\W
\W是\w的反集,用于匹配非單詞字符,等價(jià)于[^A-Za-z0-9_]。
\n
\n是開發(fā)中經(jīng)常遇到的換行符,而上面提到的\s是包含\n在內(nèi)的。所以,能被\n匹配的字符,也一定能被\s匹配。
\b
\b用于匹配單詞的邊界,即單詞的開始或結(jié)束。
一開始其實(shí)我不太能理解\b在正則表達(dá)式中的作用。
直到我自己試了一下這個(gè)案例
'I love you'.match(/love/)
'Iloveyou'.match(/love/)
這兩個(gè)表達(dá)式都能匹配到結(jié)果"love"。
但是有時(shí)候我們并不希望這樣的字符串'Iloveyou'被匹配,因?yàn)樗鼪]有單詞間的空格。
所以\b有了它存在的意義。看下面的例子:
'I love you'.match(/\blove\b/)
'Iloveyou'.match(/\blove\b/) // null
第一個(gè)表達(dá)式仍然可以正常匹配到結(jié)果,而第二個(gè)就無法匹配到結(jié)果了,這符合我們的預(yù)期。
有的人可能會(huì)說,那我可以用空格匹配啊。
'I love you'.match(/ love /)
空格和\b在這種場景下還是有一點(diǎn)不一樣的,這體現(xiàn)在match的結(jié)果上。
如果是用空格匹配,那么match的結(jié)果數(shù)組中的第一項(xiàng)就是" love ",是帶了空格的,然而很多時(shí)候我們不希望在結(jié)果中得到空格,所以\b存在的意義也就比較明顯了。
\B
與\b相反,代表非單詞邊界。也就是說,使用\B匹配時(shí),目標(biāo)字符前或后不能是空格。
假設(shè)\B在前,比如
/\Babc/.test('111 abc') // false
假設(shè)\B在后,比如
/abc\B/.test('abc 111') // false
轉(zhuǎn)義字符\
由于正則表達(dá)式中很多字符有特殊含義,比如(, ), \, [, ], +,如果你真的要匹配它們,必須加上轉(zhuǎn)義符\。
/\//.test('/'); // true
或 |
實(shí)現(xiàn)或的邏輯是比較簡單的,正則表達(dá)式提供了|。
要注意的是,|隔斷的是其左右的整個(gè)子表達(dá)式,而不是單個(gè)普通字符。
所以,
/^ab|cd|ef$/.test('ab') // true
/^ab|cd|ef$/.test('cd') // true
/^ab|cd|ef$/.test('ace') // false
還要注意的是,|具有從左到右的優(yōu)先級(jí),如果左側(cè)的匹配上了,右側(cè)的就被忽略了,即便右側(cè)的匹配看起來更“完美”。
/a|ab/.exec('ab')得到的結(jié)果是
["a", index: 0, input: "ab", groups: undefined]
量詞
?
匹配前面的子表達(dá)式零次或一次
+
匹配前面的子表達(dá)式一次或多次
*
匹配前面的子表達(dá)式零次或任意次
{n,m}
匹配前一個(gè)普通字符或者子表達(dá)式最少n次,最多m次
{n,}
匹配前一個(gè)普通字符或者子表達(dá)式最少n次
{n}
匹配前一個(gè)普通字符或者子表達(dá)式n次
貪婪
貪婪匹配是盡可能多地匹配,如果能滿足匹配條件,就盡可能侵占后面的匹配規(guī)則。
貪婪匹配是默認(rèn)的,比如/\d?/會(huì)盡可能地匹配1個(gè)數(shù)字,/\d+/和/\d*/會(huì)盡可能地匹配多個(gè)數(shù)字。
舉個(gè)例子,
'123456789'.match(/^(\d+)(\d{2,})$/)
以上結(jié)果中捕獲組的第一項(xiàng)是"1234567",第二項(xiàng)是"89"。
為什么會(huì)這樣呢?因?yàn)?code style="font-size: 14px;overflow-wrap: break-word;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;color: rgb(19, 148, 216);padding: 2px 6px;word-break: normal;">\d+是貪婪匹配,盡可能地多匹配,如果沒有后面的\d{2,},捕獲組第一項(xiàng)會(huì)直接是"123456789"。但是由于\d{2,}的存在,\d+會(huì)給\d{2,}留個(gè)面子,滿足它的最小條件,即匹配2個(gè)數(shù)字,而\d+自己匹配7個(gè)數(shù)字。
非貪婪
非貪婪匹配是盡可能少地匹配,一般是在量詞?, +, *之后再加一個(gè)?,表示盡可能少地匹配,把機(jī)會(huì)留給后面的匹配規(guī)則。
還是拿貪婪模式中那個(gè)例子舉例,稍微改一下,\d+換成非貪婪模式\d+?。
'123456789'.match(/^(\d+?)(\d{2,})$/)
捕獲組的第一項(xiàng)是"1",第二項(xiàng)變成了"23456789"。
為什么會(huì)這樣呢?因?yàn)樵诜秦澙纺J较拢瑫?huì)盡可能少匹配,把機(jī)會(huì)留給后面的匹配規(guī)則。
分組
分組在正則中是一個(gè)非常有用的神器,用圓括號(hào)()來包裹的內(nèi)容就是一個(gè)分組,在正則中是這種表示形式:
/(\d*)([a-z]*)/
捕獲組()
利用捕獲組,我們能捕獲到關(guān)鍵字符。
比如
var group = '123456789hahaha'.match(/(\d*)([a-z]*)/)
分組1用于匹配任意個(gè)數(shù)字,分組2用于匹配任意個(gè)小寫字母。
那么我們?cè)?code style="font-size: 14px;overflow-wrap: break-word;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;color: rgb(19, 148, 216);padding: 2px 6px;word-break: normal;">match方法的返回結(jié)果中就可以取到這兩個(gè)分組匹配的結(jié)果,group[1]是"123456789",group[2]是"hahaha"。
我們還可以在RegExp的靜態(tài)屬性$1~$9取得前9個(gè)分組匹配的結(jié)果。RegExp.$1是"123456789",RegExp.$2是"hahaha"。但是RegExp.$1~$9是非標(biāo)準(zhǔn)的,雖然很多瀏覽器都實(shí)現(xiàn)了,盡量不要在生產(chǎn)環(huán)境中使用。
這種捕獲組的應(yīng)用在字符串的replace方法中也是類似,不過在調(diào)用replace方法時(shí),我們需要通過$1, $2, $n這種形式去引用分組。
"123456789hahaha".replace(/(\d*)([a-z]*)/, "$1") // "123456789"
利用$1,我們就可以把源字符串替換為分組1匹配到的字符串,也就是"123456789"。
非捕獲組(?:)
非捕獲組是不生成引用的分組,它也由圓括號(hào)()包裹起來,不過圓括號(hào)中起頭的是?:,也就是/(?:\d*)/這種形式。
還是改造下之前的例子來看下:
var group = '123456789hahaha'.match(/(?:\d*)([a-z]*)/)
由于非捕獲組不生成引用,所以group[1]是"hahaha";同樣地,RegExp.$1也是"hahaha"。
看到這里,我不禁也產(chǎn)生了疑問,既然我不需要引用非捕獲組,那么非捕獲組的意義何在?
思考了一陣后,我覺得非捕獲組大概有這么一些優(yōu)勢和必要性:
與捕獲組相比,非捕獲組在內(nèi)存上開銷更小,因?yàn)樗恍枰梢?/p>
分組是為了方便加量詞。我們雖然可以不生成引用,但是如果沒有分組,就不太方便加給一組字符加量詞。
'1a2b3c...'.match(/(?:\d[a-z]){2,3}(\.+)/)
引用\num
正則表達(dá)式中可以引用前面的具有引用的分組,通過\1,\2這種形式可以實(shí)現(xiàn)引用前面的子表達(dá)式。
比如,我要匹配一個(gè)字符串,要求符合這樣的規(guī)則:
字符串由單引號(hào)或雙引號(hào)開頭和結(jié)束,中間內(nèi)容可以是數(shù)字,單詞。
那我要保證的是首尾要么是單引號(hào),要么是雙引號(hào),所以我的pattern寫法可以是:
var pattern = /^(["'])[a-z\d]*\1$/
pattern.test("'perfect123'") // true
pattern.test('"1perfect2"') // true
零寬斷言
說實(shí)話,一開始看零寬斷言的概念和解釋時(shí),我真的完全不懂在說什么。
零寬正向先行斷言(?=) 零寬負(fù)向先行斷言(?!) 零寬正向后行斷言(?<=) 零寬負(fù)向后行斷言(?<!)
后面把詞匯拆開來看,加入自己的理解,就慢慢有點(diǎn)懂了。
零寬:zero width,斷言作為必要條件進(jìn)行匹配,但是不體現(xiàn)在匹配結(jié)果中。 正向:positive,斷言中的字符必須被匹配。 負(fù)向:negative,斷言中的字符不能被匹配。 先行:lookahead,必須滿足前方的條件,條件在前方,前方等同于右側(cè)。 后行:lookbehind,必須滿足后方的條件,條件在后方,后方等同于左側(cè)。
零寬正向先行斷言(?=)
約束目標(biāo)右側(cè)必須存在指定的字符。
/123(?=a)/.test('123a') // true
上面的例子約束了123右側(cè)必須有a。
零寬負(fù)向先行斷言(?!)
約束目標(biāo)右側(cè)不能存在指定的字符。
/123(?!a)/.test('123a') // false
上面的例子約束了123右側(cè)不能有a,否則結(jié)果為false。
零寬正向后行斷言(?<=)
約束目標(biāo)左側(cè)必須存在指定的字符。
/(?<=a)123/.test('a123') // true
上面的例子約束了123左側(cè)必須有a。
ES2018才支持零寬后行斷言,具體見TC39 Proposals[3]
零寬負(fù)向后行斷言(?<!)
約束目標(biāo)左側(cè)不能存在指定的字符。
/(?<!a)123/.test('a123') // false
上面的例子約束了123左側(cè)不能有a,否則結(jié)果為false
注:ES2018才支持此特性。
RegExp
說到正則表達(dá)式,就不得不提到RegExp對(duì)象。下面我們從原型方法,靜態(tài)屬性,實(shí)例屬性等幾個(gè)方面來認(rèn)識(shí)下RegExp對(duì)象。
原型方法
RegExp.prototype.test
test()是我們平時(shí)最常用的正則方法,test()方法執(zhí)行一個(gè)檢索,用來查看正則表達(dá)式與指定的字符串是否匹配,返回一個(gè)布爾值true或false。
如果正則表達(dá)式設(shè)置了全局標(biāo)志g,執(zhí)行test()會(huì)改變RegExp.lastIndex屬性,用于記錄上次匹配到的字符的起始索引。連續(xù)執(zhí)行test()方法,后續(xù)的執(zhí)行將會(huì)從lastIndex處開始匹配字符串。這種情況下,如果test()無法匹配到結(jié)果,lastIndex就會(huì)重置為0。
RegExp.prototype.exec
exec()相較于test()能得到更豐富的匹配信息,其結(jié)果是一個(gè)數(shù)組,數(shù)組的第0個(gè)元素是匹配到的字符串,第1~n個(gè)元素是圓括號(hào)()分組捕獲的結(jié)果。
結(jié)果數(shù)組是數(shù)組,數(shù)組也是對(duì)象類型數(shù)據(jù),所以結(jié)果數(shù)組還有兩個(gè)屬性分別是index和input
index代表匹配到的字符位于原始字符串的基于0的索引值input則代表原始字符串
與test()一致,如果正則表達(dá)式設(shè)置了g標(biāo)志符,那么每次執(zhí)行exec()都會(huì)更新lastIndex。
靜態(tài)屬性
靜態(tài)屬性不屬于任何一個(gè)實(shí)例,必須通過類名訪問,這一點(diǎn)在上一篇「思維導(dǎo)圖學(xué)前端」6k字一文搞懂Javascript對(duì)象,原型,繼承[1]已經(jīng)提到過。
RegExp.$1-$9
用于獲取分組的匹配結(jié)果,RegExp.$1獲取的是第一個(gè)分組的匹配結(jié)果,RegExp.$9則是第九個(gè)分組的匹配結(jié)果。
具體見上文分組-捕獲組一節(jié)。
實(shí)例屬性
lastIndex
lastIndex,從語義上理解,就是上次匹配到的字符的起始索引。要注意的是,只有設(shè)置了g標(biāo)志,lastIndex才有效。
當(dāng)還未進(jìn)行匹配時(shí),lastIndex自然是0,代表從第0個(gè)字符串開始匹配。
lastIndex會(huì)隨著exec()和test()的執(zhí)行而更新
var reg = /\d/g
reg.lastIndex // 0
reg.test('123456')
reg.lastIndex // 1
reg.exec('123456')
reg.lastIndex // 2
lastIndex可以手動(dòng)修改,也就是說,你可以自由控制匹配的細(xì)節(jié)。
flags
flags屬性返回一個(gè)字符串,代表該正則表達(dá)式實(shí)例啟用了哪些標(biāo)志。
var reg = /\d/ig
reg.flags; // "gi"
global
global是布爾量,表明正則表達(dá)式是否使用了g標(biāo)志。
ignoreCase
ignoreCase是布爾量,表明正則表達(dá)式是否使用了i標(biāo)志。
multiline
multiline是布爾量,表明正則表達(dá)式是否使用了m標(biāo)志。
source
source,意為源,是正則表達(dá)式的字符串表示,不會(huì)包含正則字面量兩邊的斜杠以及任何的標(biāo)志字符。
String涉及正則的方法
String.prototype.search
search()方法用正則表達(dá)式對(duì)字符串對(duì)象進(jìn)行一次匹配,結(jié)果返回一個(gè)index,代表正則表達(dá)式在字符串中首次匹配項(xiàng)的索引。如果無法匹配,則返回-1。
search()方法的參數(shù)必須是正則表達(dá)式,如果不是也會(huì)被new RegExp()默默轉(zhuǎn)換為正則表達(dá)式對(duì)象。
"123abc".search(/[a-z]/); // 3
String.prototype.match
字符串的match方法用于檢索字符串,和正則表達(dá)式的exec方法是相似的。match方法的參數(shù)也要求是正則表達(dá)式。match方法返回一個(gè)數(shù)組。
與exec()的不同點(diǎn)在于,如果match方法傳入的正則表達(dá)式帶了標(biāo)識(shí)g,則將返回與完整正則表達(dá)式匹配的所有結(jié)果,但不會(huì)返回捕獲組。
"123abc456".match(/([a-z])/g);
// 返回["a", "b", "c"]
var reg = /([a-z])/g;
reg.exec('123abc456');
// 返回?cái)?shù)組["a", "a", index: 3, input: "123abc456", groups: undefined]
reg.exec('123abc456');
// 返回?cái)?shù)組["b", "b", index: 4, input: "123abc456", groups: undefined]
reg.exec('123abc456');
// 返回?cái)?shù)組["c", "c", index: 5, input: "123abc456", groups: undefined]
如果match()方法傳入的正則表達(dá)式不帶標(biāo)志g,表現(xiàn)與exec()方法一致,只會(huì)返回第一個(gè)匹配結(jié)果和分組捕獲到的結(jié)果。
如果此時(shí)表達(dá)式中有圓括號(hào)分組,在match()的結(jié)果數(shù)組中也是可以獲取到這些分組匹配的結(jié)果的,這一點(diǎn)在捕獲組中也有提到。
"123abc456".match(/([a-z])/);
// 返回["a", "a", index: 3, input: "123abc456", groups: undefined]
RegExp.$1; // "a"
String.prototype.replace
replace()是字符串替換方法,它不要求第一個(gè)參數(shù)必須是正則表達(dá)式。如果第一個(gè)參數(shù)是正則表達(dá)式,并且包含分組,那么在replace()的第二個(gè)參數(shù)中,可以通過"$1","$2"這種形式引用分組匹配結(jié)果。
"123456789hahaha".replace(/(\d*)([a-z]*)/, "$1") // "123456789"
String.prototype.split
split()方法是字符串分割方法,也算平時(shí)用得很多的一個(gè)方法,但是很多人不知道它可以接受正則表達(dá)式作為參數(shù)。
假設(shè)我們得到這樣一個(gè)不太規(guī)律的字符串"1,2, 3 ,4, 5",然后需要分割這個(gè)字符串得到純數(shù)字組成的數(shù)組,直接使用split(",")是不行的,而利用正則表達(dá)式作為分割條件就可以做到。
var str = "1,2, 3 ,4, 5";
str.split(/\s*,\s*/);
// 返回 ["1", "2", "3", "4", "5"]
最后
正則表達(dá)式是一個(gè)非常重要卻容易被忽視的知識(shí)點(diǎn),在面試中也是一個(gè)頻繁的考點(diǎn),所以必須給予它足夠的重視。經(jīng)過上面的知識(shí)點(diǎn)梳理,相信能在后續(xù)的實(shí)戰(zhàn)中胸有成竹,不慌不忙。
參考
「思維導(dǎo)圖學(xué)前端」6k字一文搞懂Javascript對(duì)象,原型,繼承: https://juejin.im/post/5ee9ac91f265da02aa2e751e
[2]正則表達(dá)式: https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin
[3]TC39 Proposals: https://github.com/tc39/proposals/blob/master/finished-proposals.md
END


“分享、點(diǎn)贊、在看” 支持一波 