
HashMap面試題,看這一篇就夠了!
在后端的日常開發(fā)工作中,集合是使用頻率相當(dāng)高的一個(gè)工具,而其中的HashMap,則更是我們用以處理業(yè)務(wù)邏輯的好幫手,同時(shí)HashMap的底層實(shí)現(xiàn)和原理,也成了面試題中的常客。
以前曾有詳細(xì)了解過HashMap的實(shí)現(xiàn)原理,看過源碼(JDK7版本)。但隨著jdk版本的飛速迭代(現(xiàn)在都到JDK13了,但新特性還從沒用過。。),主流的jdk使用版本也終于從JDK7挪到了JDK8。
由于JDK的向前兼容,在JDK8的使用過程中也沒發(fā)現(xiàn)HashMap有什么特別之處,特性并無變化(依然線程不安全)。但最近的一次好奇心驅(qū)使,從IDE中點(diǎn)進(jìn)去看了下HashMap的put()方法,有點(diǎn)兒懵逼,怎么跟我記憶中的不太一樣?從JDK7到JDK8,HashMap也做了升級(jí)么?升級(jí)了什么哪些內(nèi)容?
借著這股好奇心,把JDK7和JDK8的源碼都翻了翻,對(duì)兩者的實(shí)現(xiàn)原理做一下對(duì)比,JDK版本都在半年左右一次的速度推陳出新,我們的認(rèn)知當(dāng)然也要跟上,不斷學(xué)習(xí),站在浪潮之巔,不然就要被這滾滾的信息泥石流給裹挾淹沒了。
先展示下Map家族的關(guān)系層級(jí),有助于我們更好的理解后面的內(nèi)容。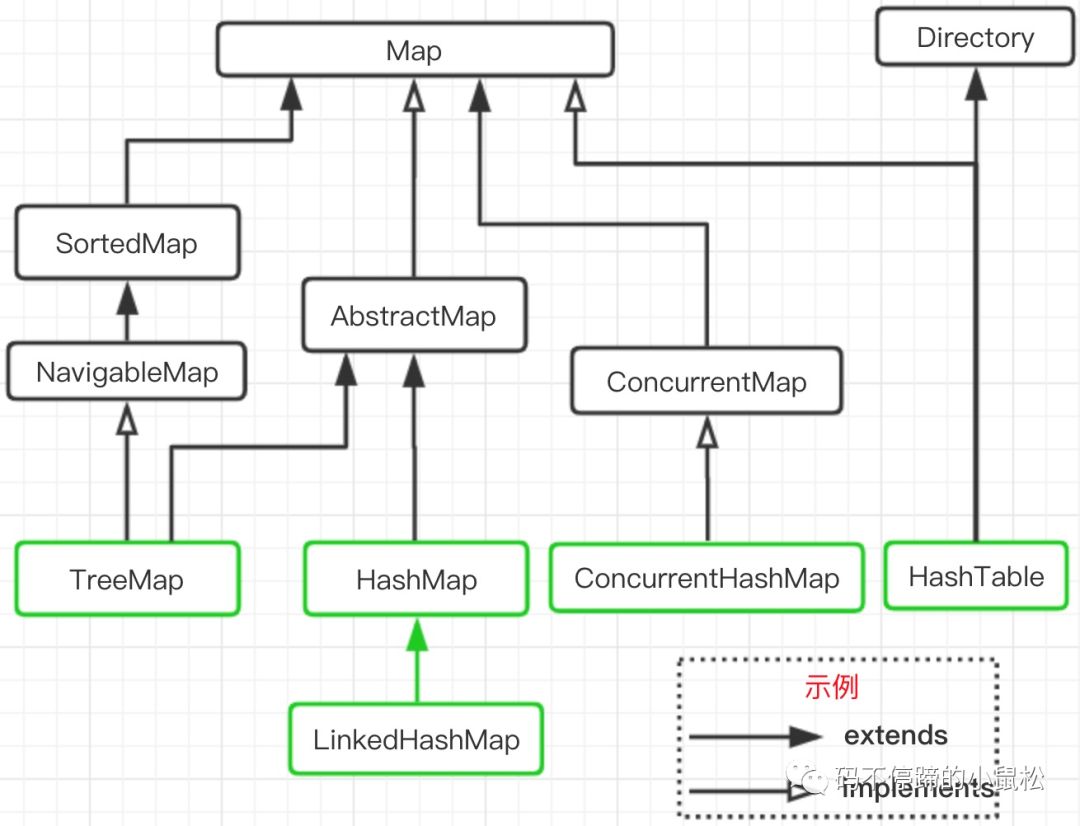
HashMap的基本知識(shí)點(diǎn)介紹就不多啰嗦了,直奔主題,看JDK7和JDK8的功能實(shí)現(xiàn)吧。
一、JDK7中的HashMap底層實(shí)現(xiàn)1.1 基礎(chǔ)知識(shí)
不管是1.7,還是1.8,HashMap的實(shí)現(xiàn)框架都是哈希表 + 鏈表的組合方式。結(jié)構(gòu)圖如下: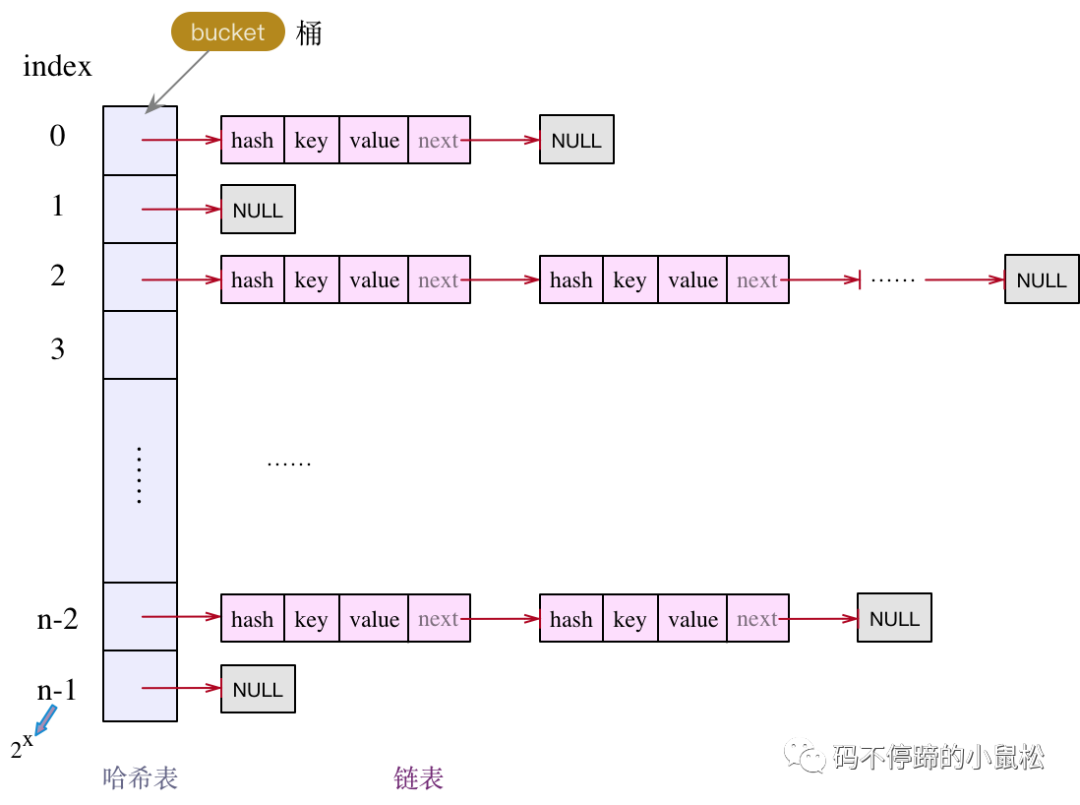
平常使用最多的就是put()、get()操作,想要了解底層實(shí)現(xiàn),最直接的就是從put()/get()方法看起。不過在具體看源碼前,我們先關(guān)注幾個(gè)域變量,打打基礎(chǔ),如下: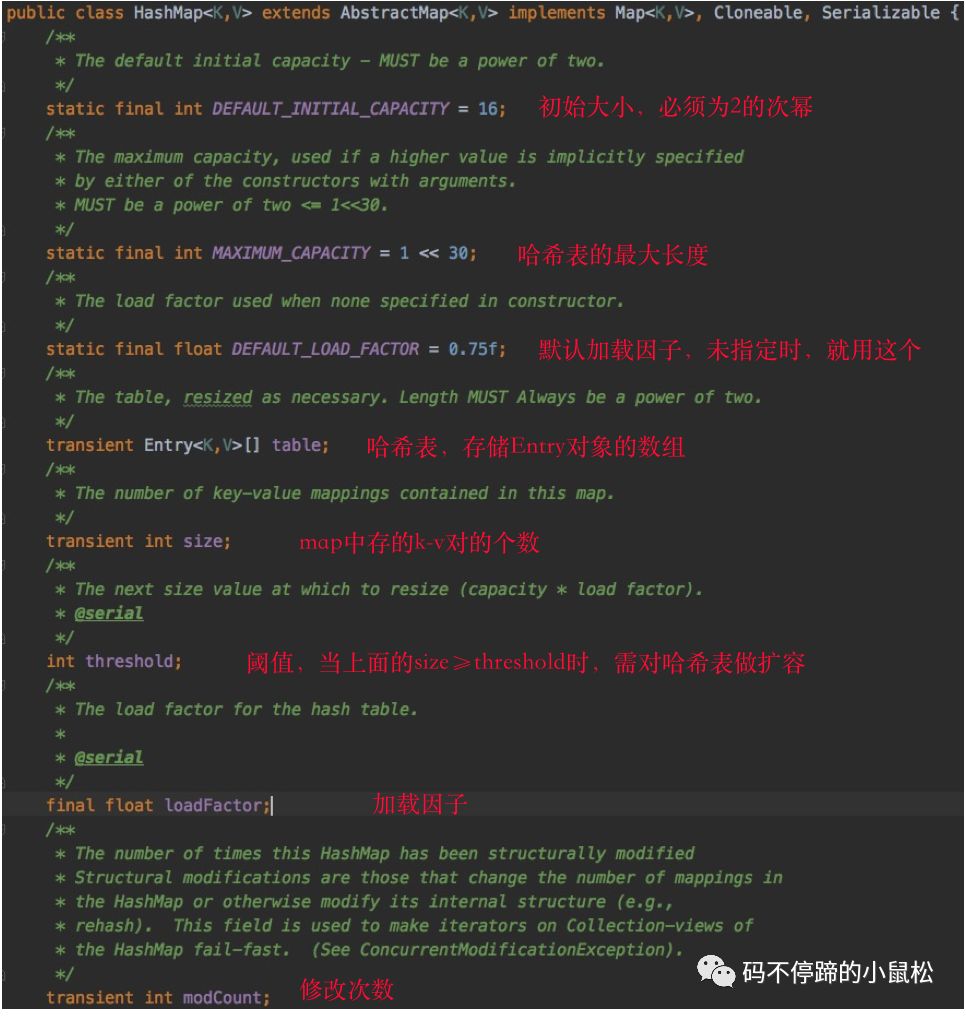
上圖中,已對(duì)各個(gè)變量做了簡(jiǎn)單的解釋。再多說一下,最后一個(gè)變量modCount,記錄了map新增/刪除k-v對(duì),或者內(nèi)部結(jié)構(gòu)做了調(diào)整的次數(shù),其主要作用,是對(duì)Map的iterator()操作做一致性校驗(yàn),如果在iterator操作的過程中,map的數(shù)值有修改,直接拋出ConcurrentModificationException異常。
還需要說明的是,上面的域變量中存在一個(gè)等式:
threshold = table.length * loadFactor;
當(dāng)執(zhí)行put()操作放入一個(gè)新的值時(shí),如果map中已經(jīng)存在對(duì)應(yīng)的key,則作替換即可,若不存在,則會(huì)首先判斷size>=threshold是否成立,這是決定哈希table是否擴(kuò)容的重要因素。
就使用層面來說,用的最多的莫過于put()方法、get()方法。想要詳細(xì)了解運(yùn)作原理,那就先從這兩個(gè)方法看起吧,這兩個(gè)方法弄明白了,也就基本能理清HashMap的實(shí)現(xiàn)原理了。
1.2 put()方法
當(dāng)了解了以上的變量和用途后,接下來看下put()方法的具體實(shí)現(xiàn):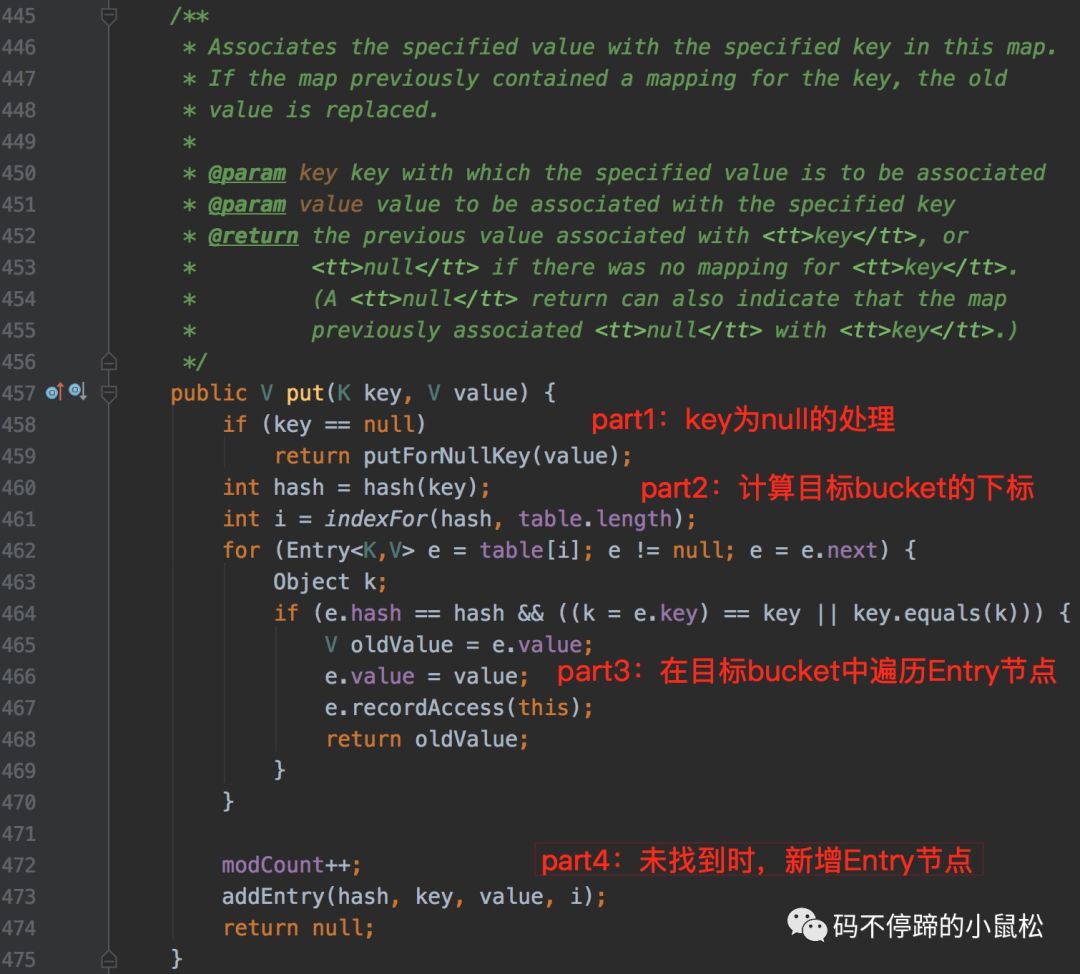 如上面的截圖代碼所示,整個(gè)put方法的處理過程,可拆分為四部分:
如上面的截圖代碼所示,整個(gè)put方法的處理過程,可拆分為四部分:
- part1:特殊key值處理,key為null;
- part2:計(jì)算table中目標(biāo)bucket的下標(biāo);
- part3:指定目標(biāo)bucket,遍歷Entry結(jié)點(diǎn)鏈表,若找到key相同的Entry結(jié)點(diǎn),則做替換;
- part4:若未找到目標(biāo)Entry結(jié)點(diǎn),則新增一個(gè)Entry結(jié)點(diǎn)。
不知大家有沒有發(fā)現(xiàn),上面截圖中的put()方法是有返回值的,場(chǎng)景區(qū)分如下:
- 場(chǎng)景1:若執(zhí)行put操作前,key已經(jīng)存在,那么在執(zhí)行put操作時(shí),會(huì)使用本次的新value值來覆蓋前一次的舊value值,返回的就是舊value值;
- 場(chǎng)景2:若key不存在,則返回null值。
下面對(duì)put方法的各部分做詳細(xì)的拆解分析。
1.2.1 特殊key值處理
特殊key值,指的就是key為null。先說結(jié)論:
a) HashMap中,是允許key、value都為null的,且key為null只存一份,多次存儲(chǔ)會(huì)將舊value值覆蓋;
b) key為null的存儲(chǔ)位置,都統(tǒng)一放在下標(biāo)為0的bucket,即:table[0]位置的鏈表;
c)?如果是第一次對(duì)key=null做put操作,將會(huì)在table[0]的位置新增一個(gè)Entry結(jié)點(diǎn),使用頭插法做鏈表插入。
上代碼:
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
putForNullKey()方法中的代碼較為簡(jiǎn)單:首先選擇table[0]位置的鏈表,然后對(duì)鏈表做遍歷操作,如果有結(jié)點(diǎn)的key為null,則將新value值替換掉舊value值,返回舊value值,如果未找到,則新增一個(gè)key為null的Entry結(jié)點(diǎn)。
重點(diǎn)我們看下第二個(gè)方法addEntry()。?
這是一個(gè)通用方法:
給定hash、key、value、bucket下標(biāo),新增一個(gè)Entry結(jié)點(diǎn),另外還擔(dān)負(fù)了擴(kuò)容職責(zé)。如果哈希表中存放的k-v對(duì)數(shù)量超過了當(dāng)前閾值(threshold = table.length * loadFactor),且當(dāng)前的bucket下標(biāo)有鏈表存在,那么就做擴(kuò)容處理(resize)。擴(kuò)容后,重新計(jì)算hash,最終得到新的bucket下標(biāo),然后使用頭插法新增結(jié)點(diǎn)。
1.2.2 擴(kuò)容
上一節(jié)有提及,當(dāng)k-v對(duì)的容量超出一定限度后,需要對(duì)哈希table做擴(kuò)容操作。那么問題來了,怎么擴(kuò)容的?下面看下源代碼: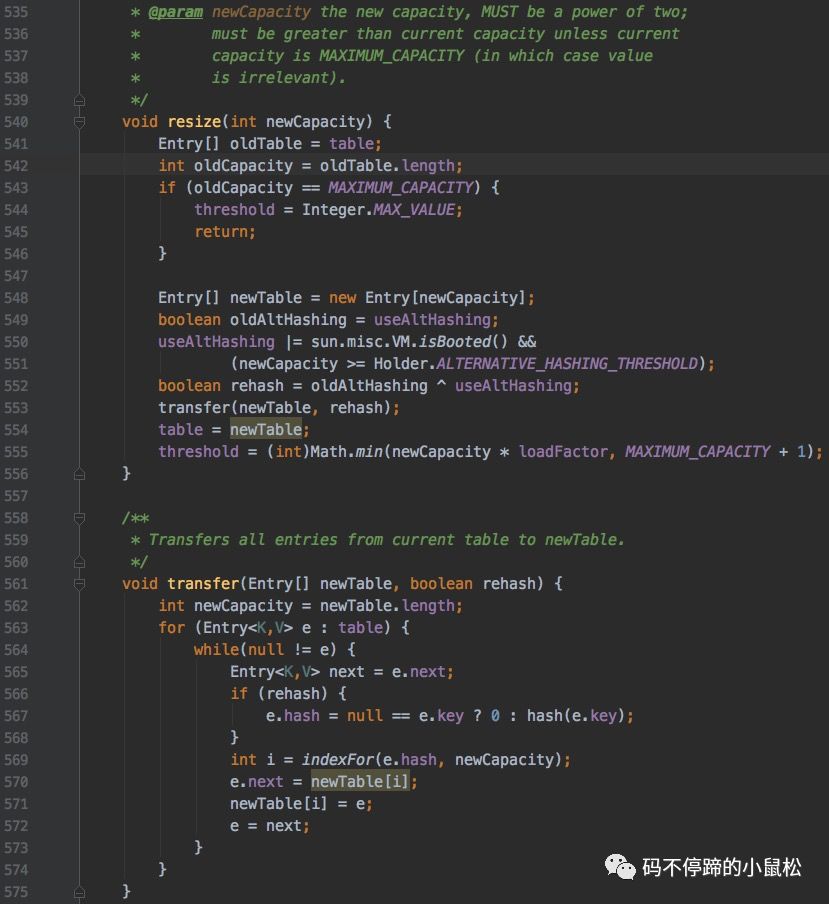
有兩個(gè)核心點(diǎn):
a) 擴(kuò)容后大小是擴(kuò)容前的2倍;
oldCapacity=table.length;
newCapacity = 2 * oldCapacity;
b) 數(shù)據(jù)搬遷,從舊table遷到擴(kuò)容后的新table。為避免碰撞過多,先決策是否需要對(duì)每個(gè)Entry鏈表結(jié)點(diǎn)重新hash,然后根據(jù)hash值計(jì)算得到bucket下標(biāo),然后使用頭插法做結(jié)點(diǎn)遷移。
1.2.3 如何計(jì)算bucket下標(biāo)?
① hash值的計(jì)算
首先得有key的hash值,就是一個(gè)整數(shù),int類型,其計(jì)算方式使用了一種可盡量減少碰撞的算式(高位運(yùn)算),具體原理不再展開,只要知道一點(diǎn)就行:使用key的hashCode作為算式的輸入,得到了hash值。
從以上知識(shí)點(diǎn),我們可以得到一個(gè)推論:
對(duì)于兩個(gè)對(duì)象,若其hashCode相同,那么兩個(gè)對(duì)象的hash值就一定相同。
這里還牽涉到另外一個(gè)知識(shí)點(diǎn)。對(duì)于HashMap中key的類型,必須滿足以下的條件:
若兩個(gè)對(duì)象邏輯相等,那么他們的hashCode一定相等,反之卻不一定成立。
邏輯相等的含義就比較寬泛了,我們可以將邏輯的相等定義為兩個(gè)對(duì)象的內(nèi)存地址相同,也可以定義為對(duì)象的某個(gè)域值相等,自定義兩個(gè)對(duì)象的邏輯相等,可通過重寫Object類的equals()方法來實(shí)現(xiàn)。比如String類,請(qǐng)看以下代碼:
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2); // false,兩個(gè)對(duì)象的內(nèi)存地址并不同
System.out.println(str1.equals(str2)); // true 兩個(gè)對(duì)象的域值相同,都存儲(chǔ)了 abc 這三個(gè)字符
對(duì)于上面代碼中的str1、str2兩個(gè)對(duì)象,雖然它們的內(nèi)存地址不同,但根據(jù)String類中對(duì)Object類的equals()方法的重寫(@override),兩個(gè)對(duì)象的域變量(即char數(shù)組)都存儲(chǔ)了'a'、'b'、'c'三個(gè)字符,因此邏輯上是相等的。既然str1、str2兩個(gè)對(duì)象邏輯上相等,那么一定有如下結(jié)果:
System.out.println(str1.hashCode() == str2.hashCode());
---輸出---
true
從而我們就可以知道,在同一個(gè)HashMap對(duì)象中,會(huì)有如下結(jié)果:
String str1 = "abc";
String str2 = new String("abc");
Map testMap = new HashMap<>();
testMap.put(str1, 12);
testMap.put(str2, 13);
String str3 = new StringBuilder("ab").append("c").toString();
System.out.println(testMap.get(str3));
---輸出---
13
另外,我們也可以反過來想一下。
假設(shè)HashMap的key不滿足上面提到的條件,即:兩個(gè)對(duì)象相等的情況下,他們的hashCode可能不一致。那么,這會(huì)帶來什么后果呢?以上面示例代碼中的str1、str2為例,若它們的hashCode不相等,那么對(duì)應(yīng)的hash也就可能不相等(注意:這里是可能不相等,也有可能相等),testMap做put操作時(shí),str1、str2為就會(huì)被分配到不同的bucket上,導(dǎo)致的最直接后果就是會(huì)存儲(chǔ)兩份。間接的后果那就更多了,比如:使用str3對(duì)象執(zhí)行testMap.get(str3)操作時(shí),可能獲取不到值,更進(jìn)一步的后果就是這部分無法觸達(dá)的對(duì)象無法回收,導(dǎo)致內(nèi)存泄漏。
因此,再重新一遍,HashMap的key所對(duì)應(yīng)的類型,一定要滿足如下條件:
若兩個(gè)對(duì)象邏輯相等,那么他們的hashCode一定相等,反之卻不一定成立。
② 取模的邏輯
前面我們分析了hash值的計(jì)算,接下來就可以引出bucket下標(biāo)的計(jì)算:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
計(jì)算相當(dāng)簡(jiǎn)潔:將table的容量與hash值做“與”運(yùn)算,得到哈希table的bucket下標(biāo)。
③ 拓展
這種通俗的不能再通俗的計(jì)算大家都能看懂,但為何要這樣做呢?背后的思考是什么?在看到下面的解釋前,大家可以先思考下~
在文檔開頭,給出了HashMap類中的各個(gè)域變量。其中,哈希table的初始大小默認(rèn)設(shè)置為16,為2的次冪數(shù)。后面在擴(kuò)容時(shí),都是以2的倍數(shù)來擴(kuò)容。為什么非要將哈希table的大小控制為2的次冪數(shù)?
原因1:降低發(fā)生碰撞的概率,使散列更均勻。根據(jù)key的hash值計(jì)算bucket的下標(biāo)位置時(shí),使用“與”運(yùn)算公式:h & (length-1),當(dāng)哈希表長(zhǎng)度為2的次冪時(shí),等同于使用表長(zhǎng)度對(duì)hash值取模(不信大家可以自己演算一下),散列更均勻;
原因2:表的長(zhǎng)度為2的次冪,那么(length-1)的二進(jìn)制最后一位一定是1,在對(duì)hash值做“與”運(yùn)算時(shí),最后一位就可能為1,也可能為0,換句話說,取模的結(jié)果既有偶數(shù),又有奇數(shù)。設(shè)想若(length-1)為偶數(shù),那么“與”運(yùn)算后的值只能是0,奇數(shù)下標(biāo)的bucket就永遠(yuǎn)散列不到,會(huì)浪費(fèi)一半的空間。
1.2.4 在目標(biāo)bucket中遍歷Entry結(jié)點(diǎn)
先把這部分代碼拎出來:
...
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
...
通過hash值計(jì)算出下標(biāo),找到對(duì)應(yīng)的目標(biāo)bucket,然后對(duì)鏈表做遍歷操作,逐個(gè)比較,如下: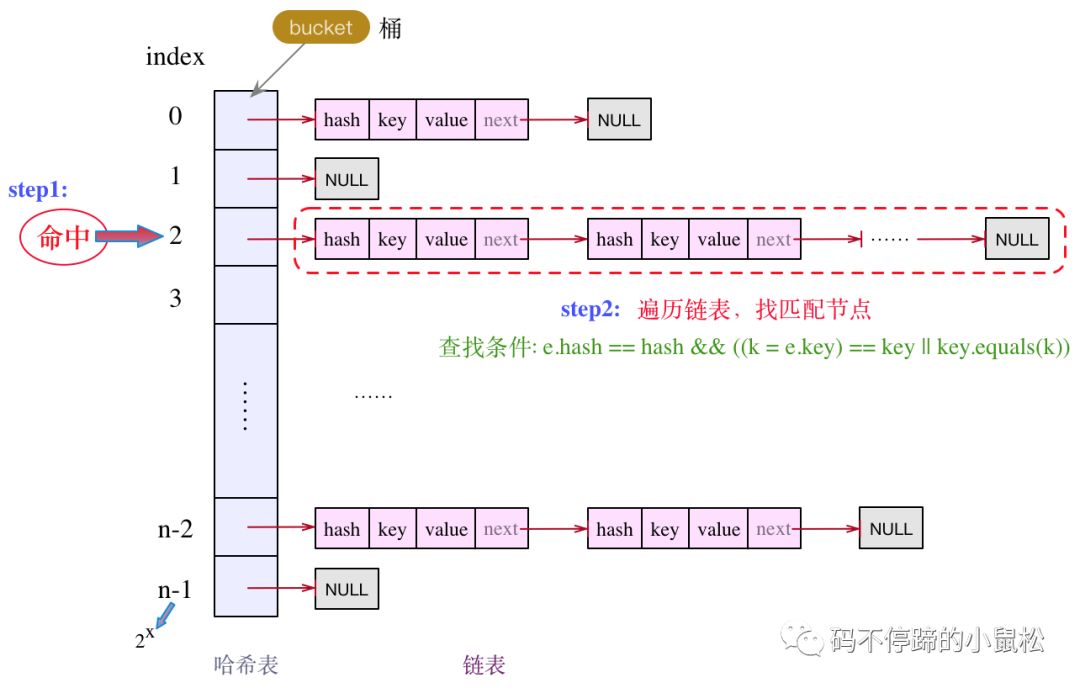
注意這里的查找條件:e.hash == hash && ((k = e.key) == key || key.equals(k))結(jié)點(diǎn)的key與目標(biāo)key的相等,要么內(nèi)存地址相等,要么邏輯上相等,兩者有一個(gè)滿足即可。
1.3 get()方法
相比于put()方法,get()方法的實(shí)現(xiàn)就相對(duì)簡(jiǎn)單多了。主要分為兩步,先是通過key的hash值計(jì)算目標(biāo)bucket的下標(biāo),然后遍歷對(duì)應(yīng)bucket上的鏈表,逐個(gè)對(duì)比,得到結(jié)果。
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
/**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*/
final Entry getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
1.4 Map中的迭代器Iterator
1.4.1 Map遍歷的幾種方式
先問個(gè)問題,你能想到幾種遍歷Map的方式?
方式1:Iterator迭代器
Iterator> iterator = testMap.entrySet().iterator();
while (iterator.hasNext()) {
Entry next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
逐個(gè)獲取哈希table中的每個(gè)bucket中的每個(gè)Entry結(jié)點(diǎn),后面會(huì)詳細(xì)介紹。
方式2:最常見的使用方式,可同時(shí)得到key、value值
// 方式一
for (Map.Entry entry : testMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
這種方式是一個(gè)語法糖,我們可通過反編譯命令javap,或通過IDE來查下編譯之后的語句:
Iterator var2 = testMap.entrySet().iterator();
while(var2.hasNext()) {
Entry entry = (Entry)var2.next();
System.out.println((String)entry.getKey() + ":" + entry.getValue());
}
其底層還是使用的是Iterator功能。
方式3:使用foreach方式(JDK1.8才有)
testMap.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
這是一種Lambda表達(dá)式。foreach也是一個(gè)語法糖,其內(nèi)部是使用了方式二的處理方式,Map的foreach方法實(shí)現(xiàn)如下: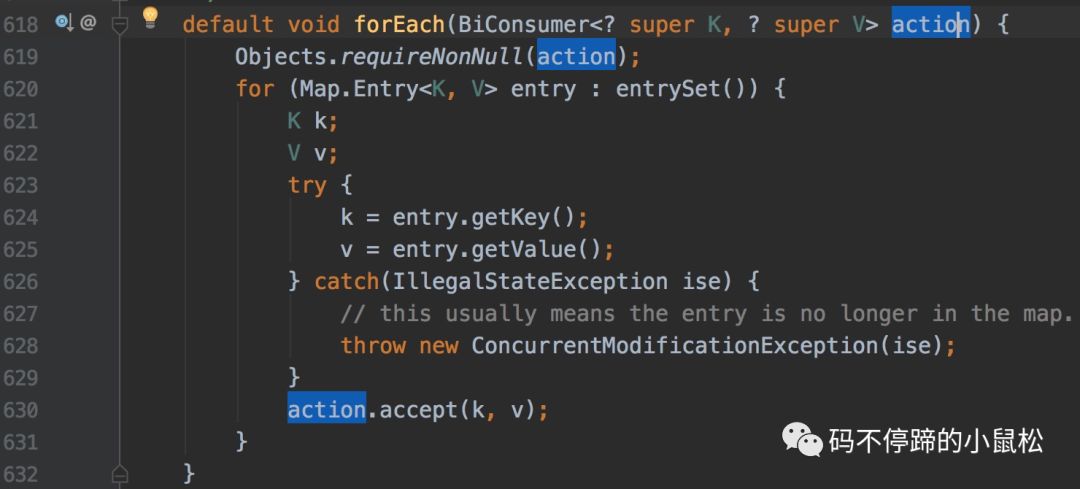
方式4:通過key的set集合遍歷
Iterator keyIterator = testMap.keySet().iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
System.out.println(key + ":" + testMap.get(key));
}
這種也是Iterator的方式,不過是通過Set類的iterator方式。
相比方式1,這種方式在獲取value時(shí),還需要再次通過testMap.get()的方式,性能相比方式1要降低很多。但兩者有各自的使用場(chǎng)景,若在Map的遍歷中僅使用key,則方式4較為適合,若需用到value,推薦使用方式1。
從前面的方式1和方式2可知,方式4還有如下的變體(語法糖的方式):
for (String key : testMap.keySet()) {
System.out.println(key + ":" + testMap.get(key));
}
綜合以上,在遍歷Map時(shí),從性能方面考慮,若需同時(shí)使用key和value,推薦使用方式1或方式2,若單純只是使用key,推薦使用方式4。任何情況下都不推薦使用方式3,因?yàn)闀?huì)新增二次查詢(通過key再一次在Map中查找value)。
另外,使用方式1時(shí),還可以做remove操作,這個(gè)下面會(huì)講到。
1.4.2 Iterator的實(shí)現(xiàn)原理
先看一張類/接口的繼承關(guān)系圖: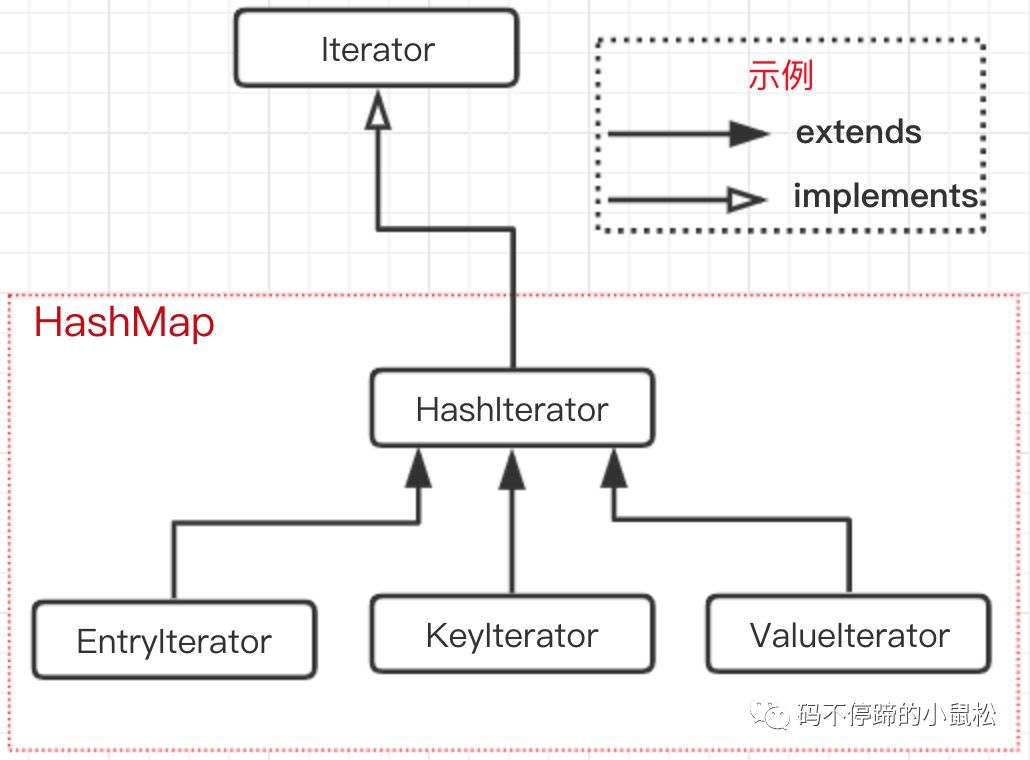
Iterator為一個(gè)頂層接口,只提供了三個(gè)基礎(chǔ)方法聲明:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
}
這也是我們使用Iterator時(shí)繞不開的三個(gè)方法。在HashMap中,首先是新增了一個(gè)內(nèi)部抽象類HashIterator,如下: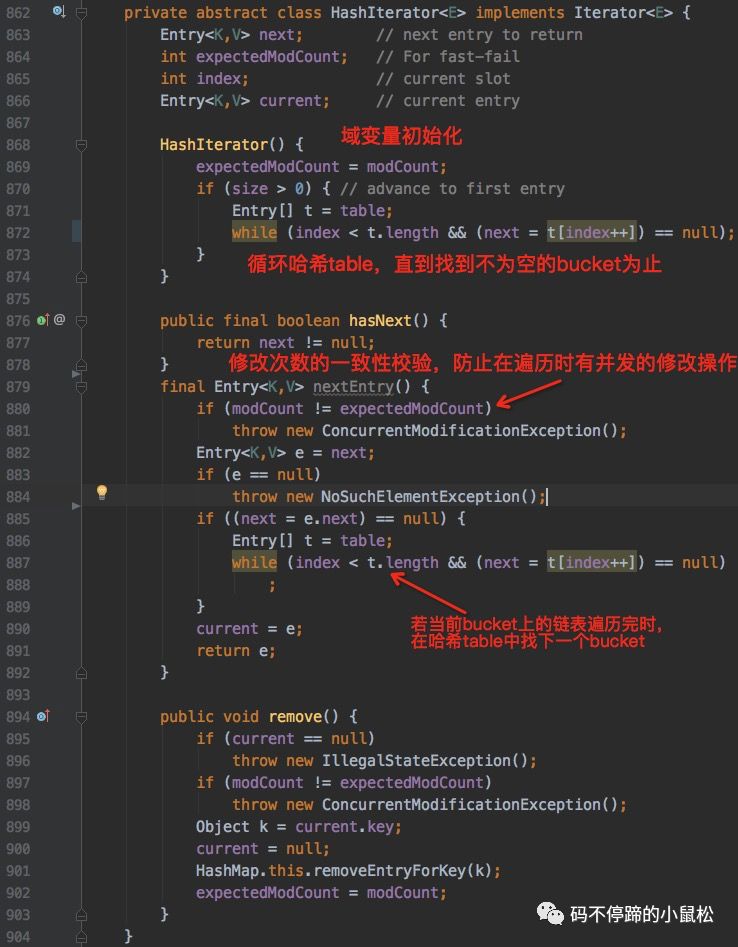
我們以Entry結(jié)點(diǎn)的遍歷為例(map的key、value的Iterator遍歷方式都類似):
Iterator> iterator = testMap.entrySet().iterator();
while (iterator.hasNext()) {
Entry next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
首先,第一行代碼,找到Iterator接口的具體實(shí)現(xiàn)類EntryIterator:
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry next() {
return nextEntry();
}
}
非常簡(jiǎn)潔有木有???就只有一個(gè)next()方法,其正是對(duì)Iterator接口的next()方法的實(shí)現(xiàn)。方法內(nèi)部也只有一行,指向了父類的nextEntry()方法,即上面截圖中的HashIterator類中的nextEntry()方法。
HashMap中的Iterator實(shí)現(xiàn)原理也不過如此,就是這么樸實(shí)無華,是不是都想動(dòng)手自己擼一個(gè)HashMap的實(shí)現(xiàn)了?嗯,你可以的!!!
1.5 fail-fast策略
和fail-fast經(jīng)常一起出現(xiàn)的還有一個(gè)異常類ConcurrentModificationException,接下來我們聊下這兩者是什么關(guān)系,以及為什么搞這么個(gè)策略出來。
什么是fail-fast?我們可以稱它為"快速失效策略",下面是Wikipedia中的解釋:
In systems design, a?fail-fast?system is one which immediately reports at its interface any condition that is likely to indicate a failure.?Fail-fast?systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process.?
Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
大白話翻譯過來,就是在系統(tǒng)設(shè)計(jì)中,當(dāng)遇到可能會(huì)誘導(dǎo)失敗的條件時(shí)立即上報(bào)錯(cuò)誤,快速失效系統(tǒng)往往被設(shè)計(jì)在立即終止正常操作過程,而不是嘗試去繼續(xù)一個(gè)可能會(huì)存在錯(cuò)誤的過程。
再簡(jiǎn)潔點(diǎn)說,就是盡可能早的發(fā)現(xiàn)問題,立即終止當(dāng)前執(zhí)行過程,由更高層級(jí)的系統(tǒng)來做處理。
在HashMap中,我們前面提到的modCount域變量,就是用于實(shí)現(xiàn)hashMap中的fail-fast。出現(xiàn)這種情況,往往是在非同步的多線程并發(fā)操作。
在對(duì)Map的做迭代(Iterator)操作時(shí),會(huì)將modCount域變量賦值給expectedModCount局部變量。在迭代過程中,用于做內(nèi)容修改次數(shù)的一致性校驗(yàn)。若此時(shí)有其他線程或本線程的其他操作對(duì)此Map做了內(nèi)容修改時(shí),那么就會(huì)導(dǎo)致modCount和expectedModCount不一致,立即拋出異常ConcurrentModificationException。
舉個(gè)栗子:
public static void main(String[] args) {
Map testMap = new HashMap<>();
testMap.put("s1", 11);
testMap.put("s2", 22);
testMap.put("s3", 33);
for (Map.Entry entry : testMap.entrySet()) {
String key = entry.getKey();
if ("s1".equals(key)) {
testMap.remove(key);
}
}
}
---- output ---
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1437)
at java.util.HashMap$EntryIterator.next(HashMap.java:1471)
at java.util.HashMap$EntryIterator.next(HashMap.java:1469)
...
正確的刪除Map元素的姿勢(shì):只有一個(gè),Iteator的remove()方法。
// 方式三
Iterator> iterator = testMap.entrySet().iterator();
while (iterator.hasNext()) {
Entry next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
if (next.getKey().equals("s2")) {
iterator.remove();
}
}
但也要注意一點(diǎn),能安全刪除,并不代表就是多線程安全的,在多線程并發(fā)執(zhí)行時(shí),若都執(zhí)行上面的操作,因未設(shè)置為同步方法,也可能導(dǎo)致modCount與expectedModCount不一致,從而拋異常ConcurrentModificationException。線程不安全的體現(xiàn)和規(guī)避方式,后續(xù)章節(jié)會(huì)詳細(xì)提及。
前面我們已經(jīng)詳細(xì)剖析了HashMap在JDK7中的實(shí)現(xiàn),不知大家有沒有發(fā)現(xiàn)其中可以優(yōu)化的地方?比如哈希表中因?yàn)閔ash碰撞而產(chǎn)生的鏈表結(jié)構(gòu),如果數(shù)據(jù)量很大,那么產(chǎn)生碰撞的幾率很增加,這帶來的后果就是鏈表長(zhǎng)度也一直在增加,對(duì)于查詢來說,性能會(huì)越來越低。如何提升查詢性能,成了JDK8中的HashMap要解決的問題。
因此,相比于JDK7,HashMap在JDK8中做鏈表結(jié)構(gòu)做了優(yōu)化(但仍然線程不安全),在一定條件下將鏈表轉(zhuǎn)為紅黑樹,提升查詢效率。
JDK8中的HashMap其底層存儲(chǔ)結(jié)構(gòu)如下:
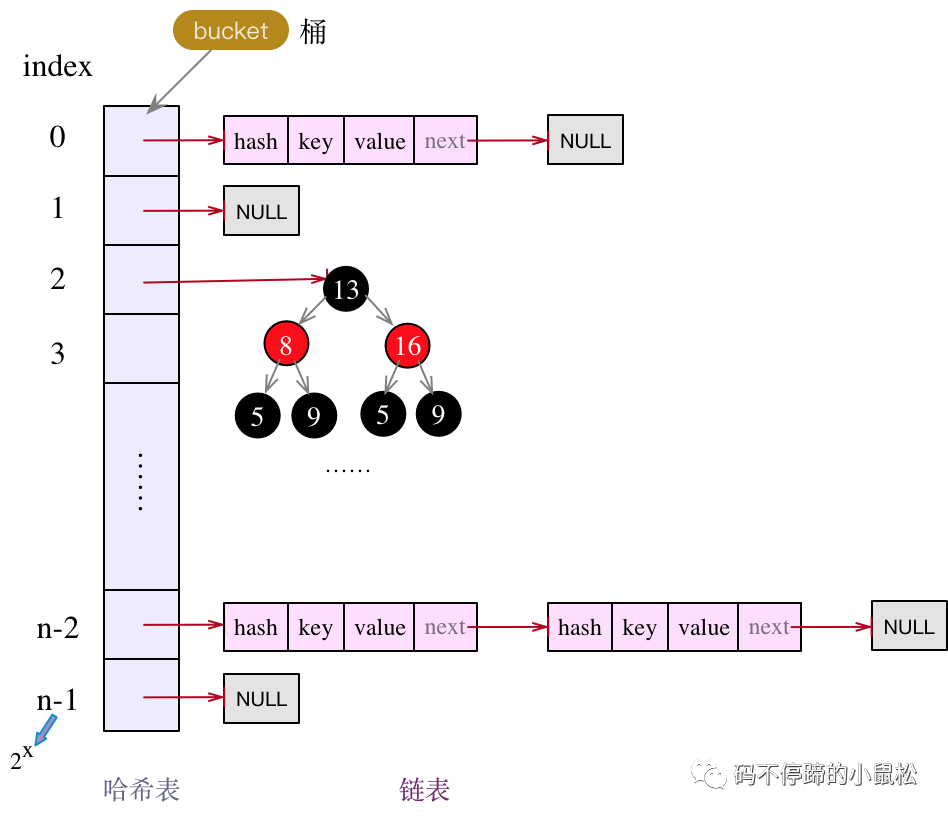 相比于JDK7,JDK8中的HashMap會(huì)將較長(zhǎng)的鏈表轉(zhuǎn)為紅黑樹,這也是與JDK7的核心差異。下面先看下
相比于JDK7,JDK8中的HashMap會(huì)將較長(zhǎng)的鏈表轉(zhuǎn)為紅黑樹,這也是與JDK7的核心差異。下面先看下put()方法的實(shí)現(xiàn)。
2.1 put()操作
在進(jìn)一步分析put()操作前,先說明一下:除了底層存儲(chǔ)結(jié)構(gòu)有調(diào)整,鏈表結(jié)點(diǎn)的定義也由Entry類轉(zhuǎn)為了Node類,但內(nèi)核沒有變化,不影響理解。
先上源代碼:?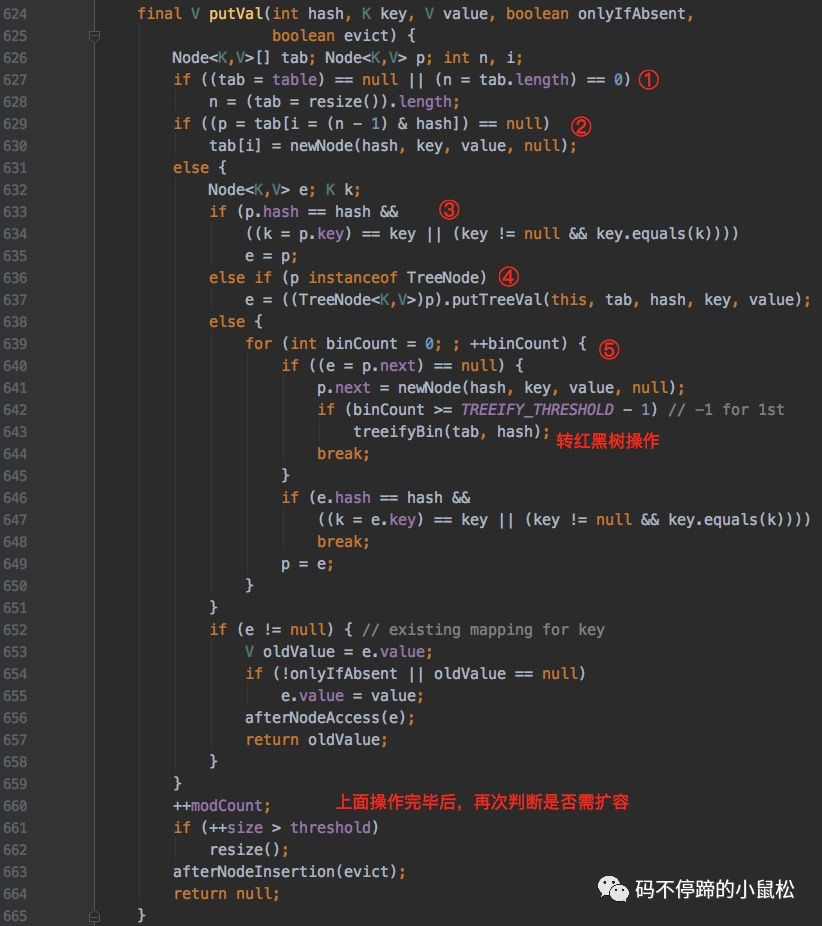
是不是很長(zhǎng)很復(fù)雜?其實(shí)不難,只要記住上面的底層存儲(chǔ)結(jié)構(gòu)圖,代碼就很容易看懂。還是一樣的存儲(chǔ)套路,先根據(jù)key確定在哈希table中的下標(biāo),找到對(duì)應(yīng)的bucket,遍歷鏈表(或紅黑樹),做插入操作。在JDK7中,新增結(jié)點(diǎn)是使用頭插法,但在JDK8中,在鏈表使用尾插法,將待新增結(jié)點(diǎn)追加到鏈表末尾。
為方便理解,將上面的代碼轉(zhuǎn)為了下面的流程圖:
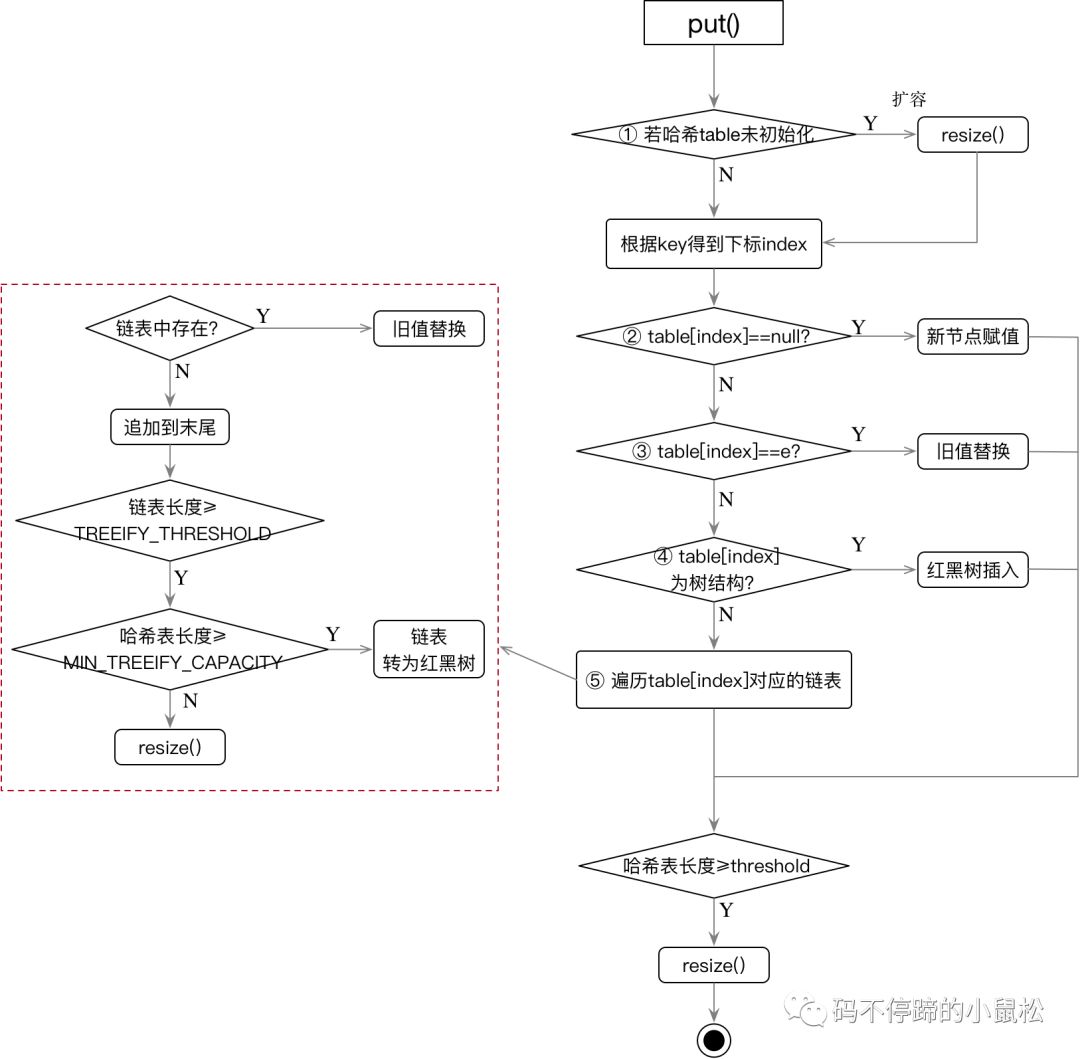
步驟①:若哈希table為null,或長(zhǎng)度為0,則做一次擴(kuò)容操作;?
步驟②:根據(jù)index找到目標(biāo)bucket后,若當(dāng)前bucket上沒有結(jié)點(diǎn),那么直接新增一個(gè)結(jié)點(diǎn),賦值給該bucket;
步驟③:若當(dāng)前bucket上有鏈表,且頭結(jié)點(diǎn)就匹配,那么直接做替換即可;
步驟④:若當(dāng)前bucket上的是樹結(jié)構(gòu),則轉(zhuǎn)為紅黑樹的插入操作;
步驟⑤:若步驟①、②、③、④都不成立,則對(duì)鏈表做遍歷操作。
??? a) 若鏈表中有結(jié)點(diǎn)匹配,則做value替換;
??? b)若沒有結(jié)點(diǎn)匹配,則在鏈表末尾追加。同時(shí),執(zhí)行以下操作:
?????? i) 若鏈表長(zhǎng)度大于TREEIFY_THRESHOLD,則執(zhí)行紅黑樹轉(zhuǎn)換操作;
?????? ii) 若條件i) 不成立,則執(zhí)行擴(kuò)容resize()操作。
以上5步都執(zhí)行完后,再看當(dāng)前Map中存儲(chǔ)的k-v對(duì)的數(shù)量是否超出了threshold,若超出,還需再次擴(kuò)容。
紅黑樹的轉(zhuǎn)換操作如下:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
// 若表為空,或表長(zhǎng)度小于MIN_TREEIFY_CAPACITY,也不做轉(zhuǎn)換,直接做擴(kuò)容處理。
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode hd = null, tl = null;
do {
TreeNode p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
2.2 擴(kuò)容操作
什么場(chǎng)景下回觸發(fā)擴(kuò)容?
場(chǎng)景1:哈希table為null或長(zhǎng)度為0;
場(chǎng)景2:Map中存儲(chǔ)的k-v對(duì)數(shù)量超過了閾值threshold;
場(chǎng)景3:鏈表中的長(zhǎng)度超過了TREEIFY_THRESHOLD,但表長(zhǎng)度缺小于MIN_TREEIFY_CAPACITY。
一般的擴(kuò)容分為2步,第1步是對(duì)哈希表長(zhǎng)度的擴(kuò)展(2倍),第2步是將舊table中的數(shù)據(jù)搬到新table上。
那么,在JDK8中,HashMap是如何擴(kuò)容的呢?
上源代碼片段:
...
// 前面已經(jīng)做了第1步的長(zhǎng)度拓展,我們主要分析第2步的操作:如何遷移數(shù)據(jù)
table = newTab;
if (oldTab != null) {
// 循環(huán)遍歷哈希table的每個(gè)不為null的bucket
// 注意,這里是"++j",略過了oldTab[0]的處理
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 若只有一個(gè)結(jié)點(diǎn),則原地存儲(chǔ)
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
// "lo"前綴的代表要在原bucket上存儲(chǔ),"hi"前綴的代表要在新的bucket上存儲(chǔ)
// loHead代表是鏈表的頭結(jié)點(diǎn),loTail代表鏈表的尾結(jié)點(diǎn)
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
// 以oldCap=8為例,
// 0001 1000 e.hash=24
// & 0000 1000 oldCap=8
// = 0000 1000 --> 不為0,需要遷移
// 這種規(guī)律可發(fā)現(xiàn),[oldCap, (2*oldCap-1)]之間的數(shù)據(jù),
// 以及在此基礎(chǔ)上加n*2*oldCap的數(shù)據(jù),都需要做遷移,剩余的則不用遷移
if ((e.hash & oldCap) == 0) {
// 這種是有序插入,即依次將原鏈表的結(jié)點(diǎn)追加到當(dāng)前鏈表的末尾
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 需要搬遷的結(jié)點(diǎn),新下標(biāo)為從當(dāng)前下標(biāo)往前挪oldCap個(gè)距離。
newTab[j + oldCap] = hiHead;
}
}
}
}
}
2.3 get()操作
了解了上面的put()操作,get()操作就比較簡(jiǎn)單了。
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
先根據(jù)key計(jì)算hash值,進(jìn)一步計(jì)算得到哈希table的目標(biāo)index,若此bucket上為紅黑樹,則再紅黑樹上查找,若不是紅黑樹,遍歷聯(lián)表。
三、HashMap、HashTable是什么關(guān)系?再把文章開頭的這張圖放出來,溫習(xí)一下:
3.1 共同點(diǎn)與異同點(diǎn)
共同點(diǎn):
- 底層都是使用哈希表 + 鏈表的實(shí)現(xiàn)方式。
區(qū)別:
- 從層級(jí)結(jié)構(gòu)上看,HashMap、HashTable有一個(gè)共用的
Map接口。另外,HashTable還單獨(dú)繼承了一個(gè)抽象類Dictionary; - HashTable誕生自JDK1.0,HashMap從JDK1.2之后才有;
- HashTable線程安全,HashMap線程不安全;
- 初始值和擴(kuò)容方式不同。HashTable的初始值為11,擴(kuò)容為原大小的
2*d+1。容量大小都采用奇數(shù)且為素?cái)?shù),且采用取模法,這種方式散列更均勻。但有個(gè)缺點(diǎn)就是對(duì)素?cái)?shù)取模的性能較低(涉及到除法運(yùn)算),而HashTable的長(zhǎng)度都是2的次冪,設(shè)計(jì)就較為巧妙,前面章節(jié)也提到過,這種方式的取模都是直接做位運(yùn)算,性能較好。 - HashMap的key、value都可為null,且value可多次為null,key多次為null時(shí)會(huì)覆蓋。當(dāng)HashTable的key、value都不可為null,否則直接NPE(NullPointException)。
示例:
public static void main(String[] args) {
Map testTable = new Hashtable<>();
testTable.put(null, 23); // 拋NPE
testTable.put("s1", null); // 拋NPE
}
看下put()方法的源碼:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
源碼中不允許value為null,若為null則直接拋NPE。
對(duì)于key為null時(shí),源碼第9行:int hash = key.hashCode(); 未做判空操作,也會(huì)外拋NPE。
另外,我們現(xiàn)在看到的抽象類Dictionary,是一個(gè)已經(jīng)廢棄的類,源碼注釋中有如下說明:
NOTE: This class is obsolete. New implementations should
implement the Map interface, rather than extending this class.strong>
3.2 HashMap的線程安全
能保證線程線程安全的方式有多個(gè),比如添加synchronized關(guān)鍵字,或者使用lock機(jī)制。兩者的差異不在此展開,后續(xù)會(huì)寫有關(guān)線程安全的文章,到時(shí)再詳細(xì)說明。而HashTable使用了前者,即synchronized關(guān)鍵字。
put操作、get操作、remove操作、equals操作,都使用了synchronized關(guān)鍵字修飾。
這么做是保證了HashTable對(duì)象的線程安全特性,但同樣也帶來了問題,突出問題就是效率低下。為何會(huì)說它效率低下呢?
因?yàn)榘磗ynchronized的特性,對(duì)于多線程共享的臨界資源,同一時(shí)刻只能有一個(gè)線程在占用,其他線程必須原地等待,為方便理解,大家不妨想下計(jì)時(shí)用的沙漏,中間最細(xì)的瓶頸處阻擋了上方細(xì)沙的下落,同樣的道理,當(dāng)有大量線程要執(zhí)行get()操作時(shí),也存在此類問題,大量線程必須排隊(duì)一個(gè)個(gè)處理。
這時(shí)可能會(huì)有人說,既然get()方法只是獲取數(shù)據(jù),并沒有修改Map的結(jié)構(gòu)和數(shù)據(jù),不加不就行了嗎?不好意思,不加也不行,別的方法都加,就你不加,會(huì)有一種場(chǎng)景,那就是A線程在做put或remove操作時(shí),B線程、C線程此時(shí)都可以同時(shí)執(zhí)行g(shù)et操作,可能哈希table已經(jīng)被A線程改變了,也會(huì)帶來問題,因此不加也不行。
現(xiàn)在好了,HashMap線程不安全,HashTable雖然線程安全,但性能差,那怎么破?使用ConcurrentHashMap類吧,既線程安全,還操作高效,誰用誰說好。莫急,下面章節(jié)會(huì)詳細(xì)解釋ConcurrentHashMap類。
本章節(jié)主要探討下HashMap的線程不安全會(huì)帶來哪些方面的問題。
4.1 數(shù)據(jù)覆蓋問題
兩個(gè)線程執(zhí)行put()操作時(shí),可能導(dǎo)致數(shù)據(jù)覆蓋。JDK7版本和JDK8版本的都存在此問題,這里以JDK7為例。
假設(shè)A、B兩個(gè)線程同時(shí)執(zhí)行put()操作,且兩個(gè)key都指向同一個(gè)buekct,那么此時(shí)兩個(gè)結(jié)點(diǎn),都會(huì)做頭插法。先看這里的代碼實(shí)現(xiàn):
public V put(K key, V value) {
...
addEntry(hash, key, value, i);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
...
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
看下最后的createEntry()方法,首先獲取到了bucket上的頭結(jié)點(diǎn),然后再將新結(jié)點(diǎn)作為bucket的頭部,并指向舊的頭結(jié)點(diǎn),完成一次頭插法的操作。
當(dāng)線程A和線程B都獲取到了bucket的頭結(jié)點(diǎn)后,若此時(shí)線程A的時(shí)間片用完,線程B將其新數(shù)據(jù)完成了頭插法操作,此時(shí)輪到線程A操作,但這時(shí)線程A所據(jù)有的舊頭結(jié)點(diǎn)已經(jīng)過時(shí)了(并未包含線程B剛插入的新結(jié)點(diǎn)),線程A再做頭插法操作,就會(huì)抹掉B剛剛新增的結(jié)點(diǎn),導(dǎo)致數(shù)據(jù)丟失。
其實(shí)不光是put()操作,刪除操作、修改操作,同樣都會(huì)有覆蓋問題。
4.2 擴(kuò)容時(shí)導(dǎo)致死循環(huán)
這是最常遇到的情況,也是面試經(jīng)常被問及的考題。但說實(shí)話,這個(gè)多線程環(huán)境下導(dǎo)致的死循環(huán)問題,并不是那么容易解釋清楚,因?yàn)檫@里已經(jīng)深入到了擴(kuò)容的細(xì)節(jié)。這里盡可能簡(jiǎn)單的描述死循環(huán)的產(chǎn)生過程。
另外,只有JDK7及以前的版本會(huì)存在死循環(huán)現(xiàn)象,在JDK8中,resize()方式已經(jīng)做了調(diào)整,使用兩隊(duì)鏈表,且都是使用的尾插法,及時(shí)多線程下,也頂多是從頭結(jié)點(diǎn)再做一次尾插法,不會(huì)造成死循環(huán)。而JDK7能造成死循環(huán),就是因?yàn)閞esize()時(shí)使用了頭插法,將原本的順序做了反轉(zhuǎn),才留下了死循環(huán)的機(jī)會(huì)。
在進(jìn)一步說明死循環(huán)的過程前,我們先看下JDK7中的擴(kuò)容代碼片段:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
其實(shí)就是簡(jiǎn)單的鏈表反轉(zhuǎn),再進(jìn)一步簡(jiǎn)化的話,分為當(dāng)前結(jié)點(diǎn)e,以及下一個(gè)結(jié)點(diǎn)e.next。我們以鏈表a->b->c->null為例,兩個(gè)線程A和B,分別做擴(kuò)容操作。
原表: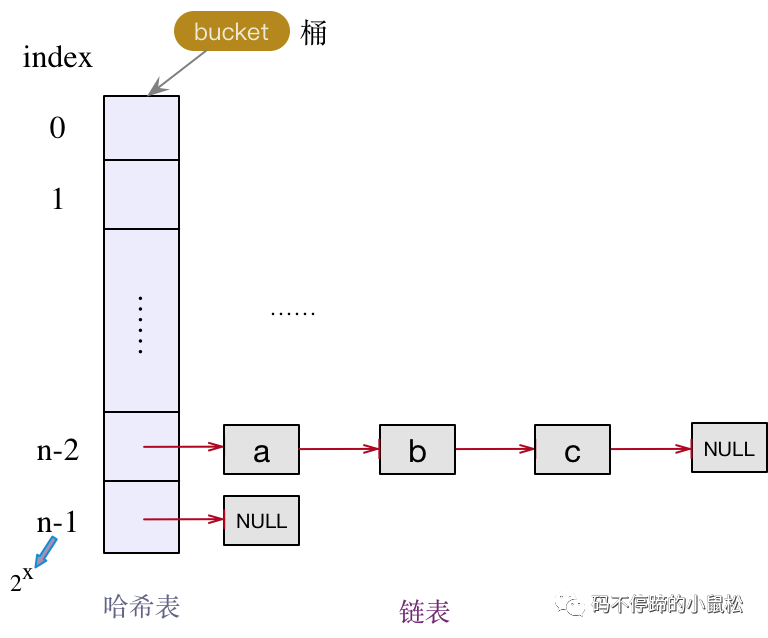
線程A和B各自新增了一個(gè)新的哈希table,在線程A已做完擴(kuò)容操作后,線程B才開始擴(kuò)容。此時(shí)對(duì)于線程B來說,當(dāng)前結(jié)點(diǎn)e指向a結(jié)點(diǎn),下一個(gè)結(jié)點(diǎn)e.next仍然指向b結(jié)點(diǎn)(此時(shí)在線程A的鏈表中,已經(jīng)是c->b->a的順序)。按照頭插法,哈希表的bucket指向a結(jié)點(diǎn),此時(shí)a結(jié)點(diǎn)成為線程B中鏈表的頭結(jié)點(diǎn),如下圖所示:
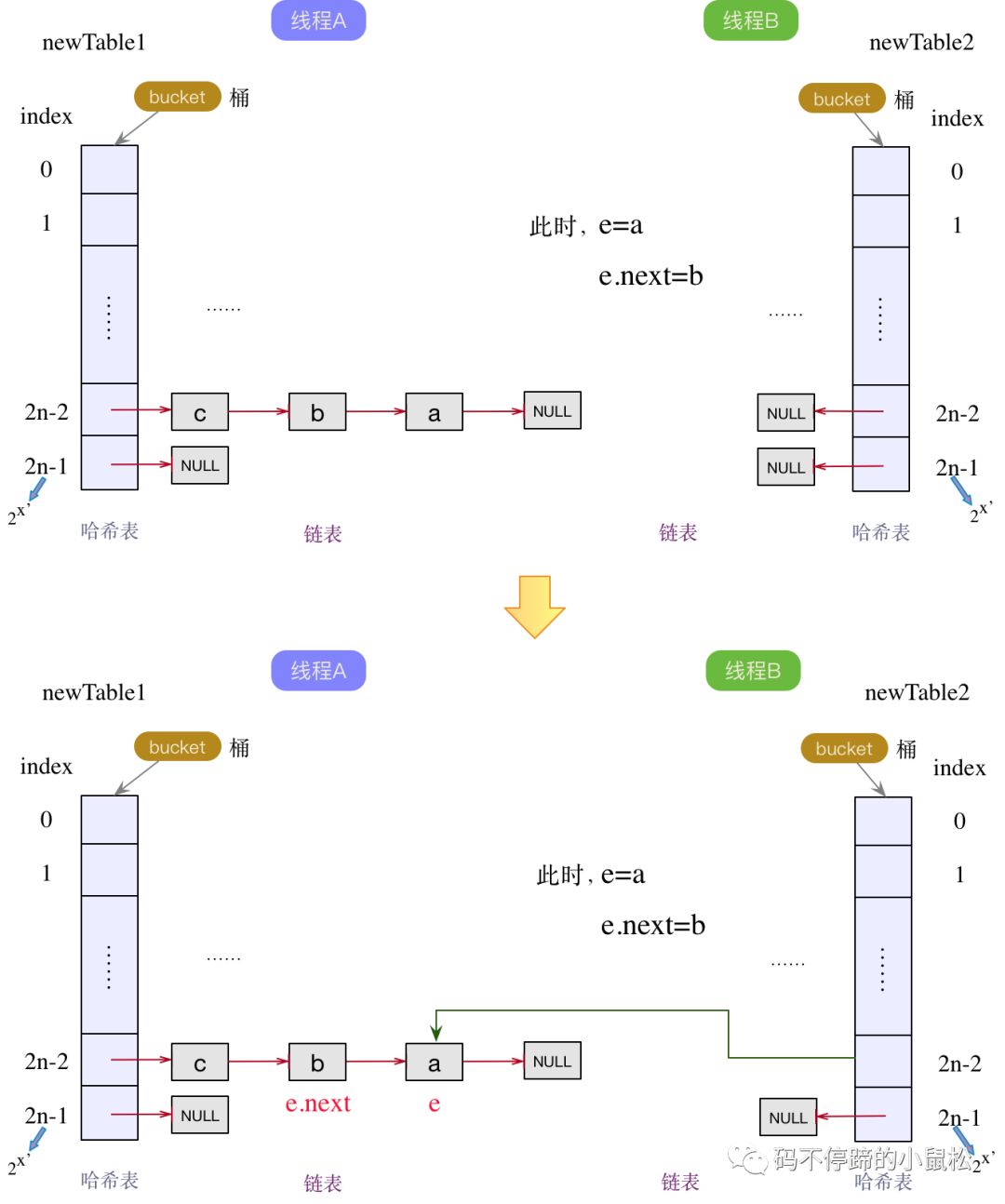
a結(jié)點(diǎn)成為線程B中鏈表的頭結(jié)點(diǎn)后,下一個(gè)結(jié)點(diǎn)e.next為b結(jié)點(diǎn)。既然下一個(gè)結(jié)點(diǎn)e.next不為null,那么當(dāng)前結(jié)點(diǎn)e就變成了b結(jié)點(diǎn),下一個(gè)結(jié)點(diǎn)e.next變?yōu)閍結(jié)點(diǎn)。繼續(xù)執(zhí)行頭插法,將b變?yōu)殒湵淼念^結(jié)點(diǎn),同時(shí)next指針指向舊的頭節(jié)點(diǎn)a,如下圖:
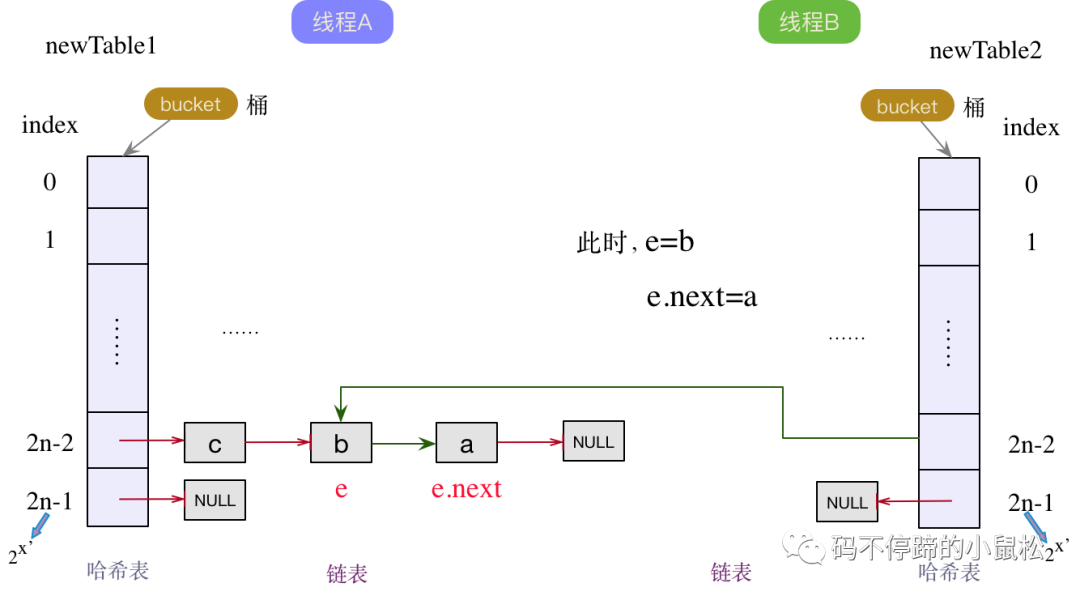
此時(shí),下一個(gè)結(jié)點(diǎn)e.next為a節(jié)點(diǎn),不為null,繼續(xù)頭插法。指針后移,那么當(dāng)前結(jié)點(diǎn)e就成為了a結(jié)點(diǎn),下一個(gè)結(jié)點(diǎn)為null。將a結(jié)點(diǎn)作為線程B鏈表中的頭結(jié)點(diǎn),并將next指針指向原來的舊頭結(jié)點(diǎn)b,如下圖所示:
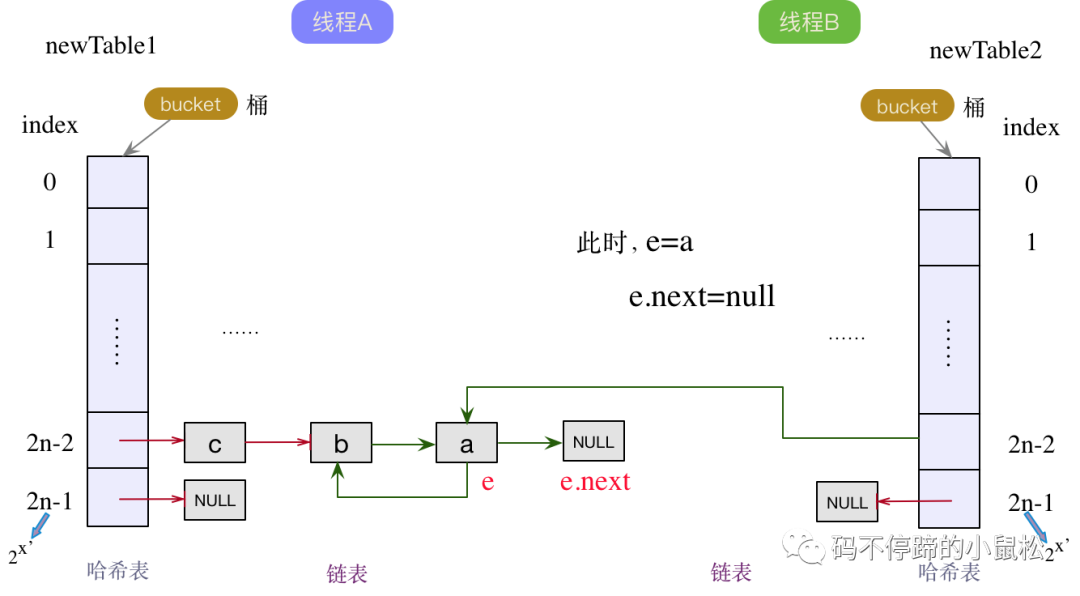
此時(shí),已形成環(huán)鏈表。同時(shí)下一個(gè)結(jié)點(diǎn)e.next為null,流程結(jié)束。
4.3 小結(jié)
多線程環(huán)境下使用HashMap,會(huì)引起各類問題,上面僅為不安全問題的兩個(gè)典型示例,具體問題無法一一列舉,但大體會(huì)分為以下三類:
- 死循環(huán)
- 數(shù)據(jù)重復(fù)
- 數(shù)據(jù)丟失(覆蓋)
在JDK1.5之前,多線程環(huán)境往往使用HashTable,但在JDK1.5及以后的版本中,在并發(fā)包中引入了專門用于多線程環(huán)境的ConcurrentHashMap類,采用分段鎖實(shí)現(xiàn)了線程安全,相比HashTable有更高的性能,推薦使用。
前面提到了HashMap在多線程環(huán)境下的各類不安全問題,那么有哪些方式可以轉(zhuǎn)成線程安全的呢?
5.1 將Map轉(zhuǎn)為包裝類
如何轉(zhuǎn)?使用Collections.SynchronizedMap()方法,示例代碼:
Map testMap = new HashMap<>();
...
// 轉(zhuǎn)為線程安全的map
Map map = Collections.synchronizedMap(testMap);
其內(nèi)部實(shí)現(xiàn)也很簡(jiǎn)單,等同于HashTable,只是對(duì)當(dāng)前傳入的map對(duì)象,新增對(duì)象鎖(synchronized):
// 源碼來自Collections類
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
}
5.2 使用ConcurrentHashMap
既然HashMap類是線程不安全的,那就不妨找個(gè)線程安全的替代品——ConcurrentHashMap類。
使用示例:
Map susuMap = new ConcurrentHashMap<>();
susuMap.put("susu1", 111);
susuMap.put("susu2", 222);
System.out.println(susuMap.get("susu1"));
在使用習(xí)慣上完全兼容了HashMap的使用。
JDK1.5版本引入,位于并發(fā)包java.util.concurrent下。
在JDK7版本及以前,ConcurrentHashMap類使用了分段鎖的技術(shù)(segment + Lock),但在jdk8中,也做了較大改動(dòng),使用回了synchronized修飾符。具體差別,在以后的文章中再詳細(xì)介紹。
文章較長(zhǎng),希望能對(duì)在看的你有所幫助。

我?guī)桶⒗镌仆茝V服務(wù)器89/年,229/3年,買來送自己,送女朋友馬上過年再合適不過了,買了搭建個(gè)項(xiàng)目給面試官看也香,還可以熟悉技術(shù)棧,(老用戶用家人賬號(hào)買就好了,我用我女朋友的?)。掃碼購(gòu)買