
搞懂索引,真的很重要
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”
回復(fù)”學(xué)習(xí)資料“獲取學(xué)習(xí)寶典

什么是索引?
索引是輔助存儲(chǔ)引擎高效獲取數(shù)據(jù)的一種數(shù)據(jù)結(jié)構(gòu)。
很多人形象的說(shuō)索引就是數(shù)據(jù)的目錄,便于存儲(chǔ)引擎快速的定位數(shù)據(jù)。
索引的分類
我們經(jīng)常從以下幾個(gè)方面對(duì)索引進(jìn)行分類
從數(shù)據(jù)結(jié)構(gòu)的角度對(duì)索引進(jìn)行分類
B+tree Hash Full-texts索引
從物理存儲(chǔ)的角度對(duì)索引進(jìn)行分類
聚簇索引 二級(jí)索引(輔助索引)
從索引字段特性角度分類
主鍵索引 唯一索引 普通索引 前綴索引
從組成索引的字段個(gè)數(shù)角度分類
單列索引 聯(lián)合索引(復(fù)合索引)
數(shù)據(jù)結(jié)構(gòu)角度看索引
下表是MySQL常見(jiàn)的存儲(chǔ)引擎InnoDB,MyISAM和Memory分別支持的索引類型
| InnoDB | MyISAM | Memory | |
|---|---|---|---|
| B+tree索引 | Yes | Yes | Yes |
| Hash索引 | No | No | Yes |
| Full-text索引 | Yes | Yes | No |
在實(shí)際使用中,InnoDB作為MySQL建表時(shí)默認(rèn)的存儲(chǔ)引擎
對(duì)上表進(jìn)行橫向查看可以了解到,B+tree是MySQL中被存儲(chǔ)引擎采用最多的索引類型。
這里淺嘗輒止的談一下B+tree 與 Hash和紅黑樹(shù)的區(qū)別。
B+tree和B-tree
1970年,
R.Bayer和E.Mccreight提出了一種適用于外查找的平衡多叉樹(shù)——B-樹(shù),磁盤管理系統(tǒng)中的目錄管理,以及數(shù)據(jù)庫(kù)系統(tǒng)中的索引組織多數(shù)采用B-Tree這種數(shù)據(jù)結(jié)構(gòu)。--數(shù)據(jù)結(jié)構(gòu)C語(yǔ)言版第二版 嚴(yán)蔚敏
B+tree是B-Tree的一個(gè)變種。(哦,對(duì)了,B-tree念B樹(shù),它不叫B減樹(shù)。。。)
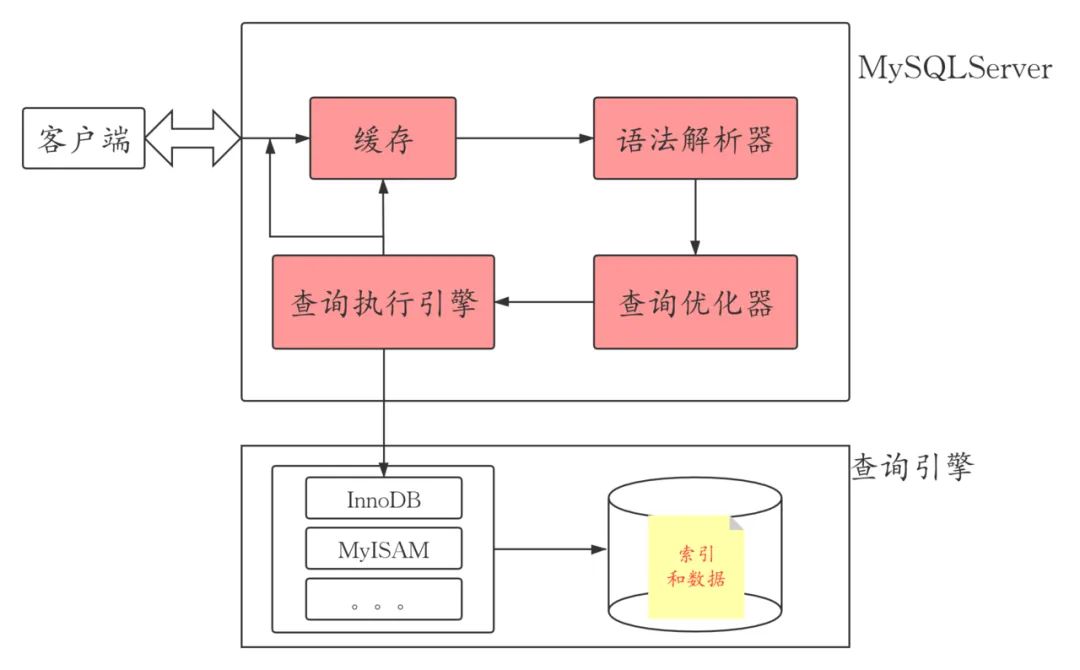
B+tree只在葉子節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù),而B(niǎo)-tree非葉子節(jié)點(diǎn)也存儲(chǔ)數(shù)據(jù)。
因此,B+tree單個(gè)節(jié)點(diǎn)的數(shù)量更小,在相同的磁盤IO下能查詢更多的節(jié)點(diǎn)。
另外B+tree葉子節(jié)點(diǎn)采用單鏈表鏈接適合MySQL中常見(jiàn)的基于范圍的順序檢索場(chǎng)景,而B(niǎo)-tree無(wú)法做到這一點(diǎn)。
B+tree和紅黑樹(shù)
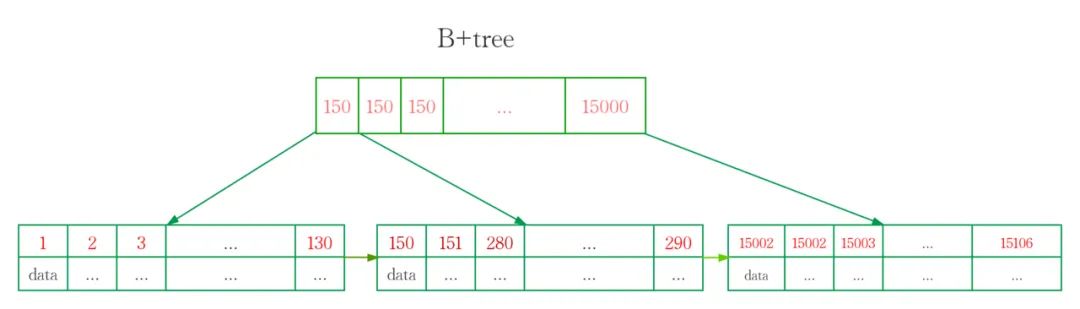
對(duì)于有N個(gè)葉子節(jié)點(diǎn)的B+tree,搜索復(fù)雜度為O(logdN) ,d是指degree是指B+tree的度,表示節(jié)點(diǎn)允許的最大子節(jié)點(diǎn)個(gè)數(shù)為d個(gè),在實(shí)際的運(yùn)用中d值是大于100的,即使數(shù)據(jù)達(dá)到千萬(wàn)級(jí)別時(shí)候B+tree的高度依然維持在3-4左右,保證了3-4次磁盤I/O就能查到目標(biāo)數(shù)據(jù).
從上圖中可以看出紅黑樹(shù)是二叉樹(shù),節(jié)點(diǎn)的子節(jié)點(diǎn)個(gè)數(shù)最多為2個(gè),意味著其搜索復(fù)雜度為O(logN),比B+樹(shù)高出不少,因此紅黑樹(shù)檢索到目標(biāo)數(shù)據(jù)所需經(jīng)理的磁盤I/O次數(shù)更多。
B+tree索引與Hash表
范圍查詢是MySQL數(shù)據(jù)庫(kù)中常見(jiàn)的場(chǎng)景,而Hash表不適合做范圍查詢,Hash表更適合做等值查詢,另外Hash表還存在Hash函數(shù)選擇和Hash值沖突等問(wèn)題。
因?yàn)檫@些原因,B+tree索引要比Hash表索引有更廣的適用場(chǎng)景。
物理存儲(chǔ)角度看索引
MySQL中的兩種常用存儲(chǔ)引擎對(duì)索引的處理方式差別較大。
InnoDB的索引
首先看一下InnoDB存儲(chǔ)引擎中的索引,InnoDB表的索引按照葉子節(jié)點(diǎn)存儲(chǔ)的是否為完整表數(shù)據(jù)分為聚簇索引和二級(jí)索引。
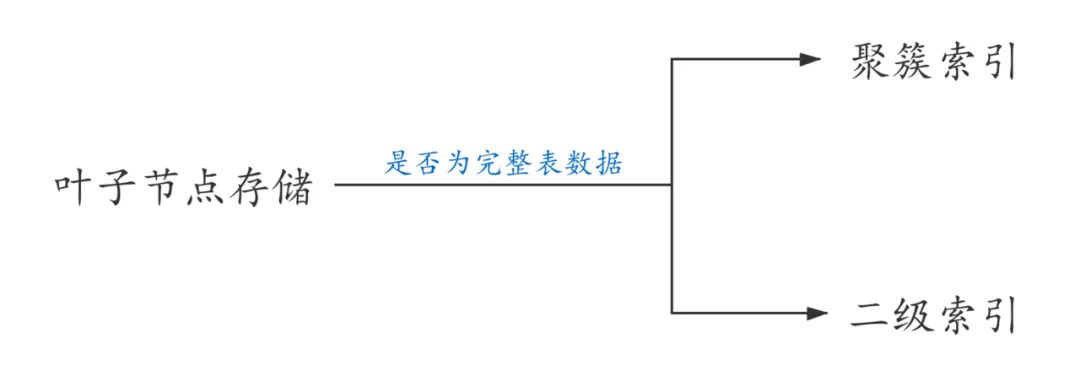
全表數(shù)據(jù)就是存儲(chǔ)在聚簇索引中的。
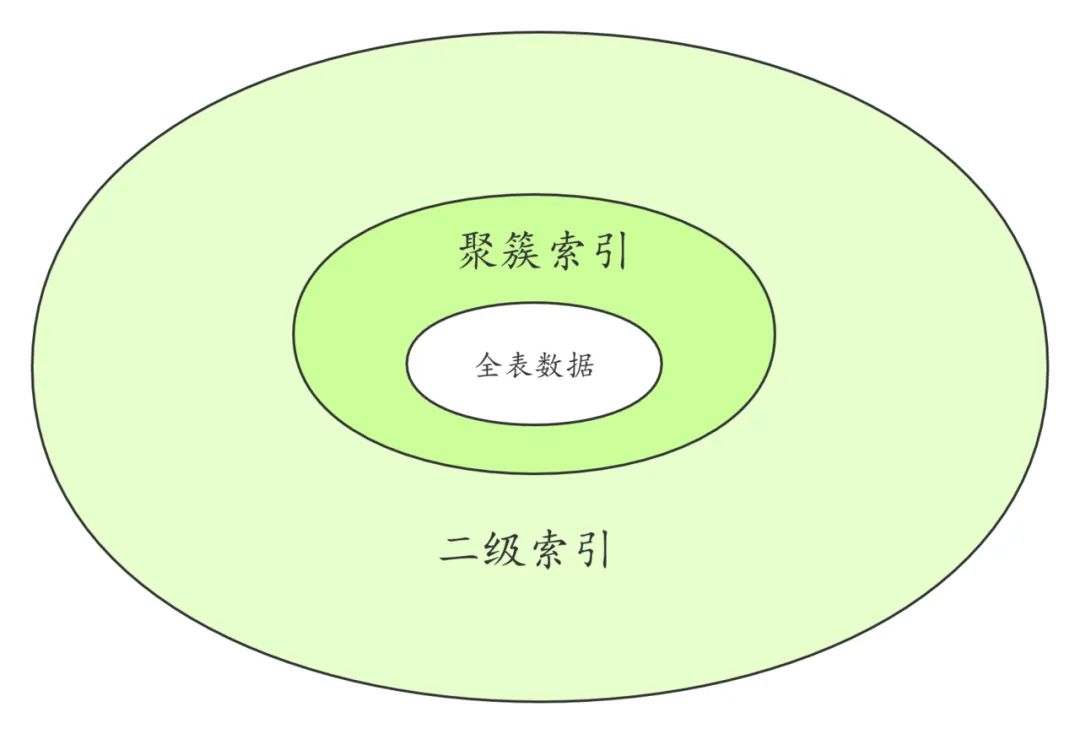
聚簇索引以外的其它索引叫做二級(jí)索引。
下面結(jié)合實(shí)際的例子介紹下這兩類索引。
create?table?workers
?(
?????id????int(11)?????not?null?auto_increment?comment?'員工工號(hào)',
?????name??varchar(16)?not?null?comment?'員工名字',
?????sales?int(11)?default?null?comment?'員工銷售業(yè)績(jī)',
?????primary?key?(id)
?)?engine?InnoDB
???AUTO_INCREMENT?=?10
???default?charset?=?utf8;
?
?insert?into?workers(id,?name,?sales)?values?(1,?'江南',?12744);
?insert?into?workers(id,?name,?sales)?values?(3,?'今何在',?14082);
?insert?into?workers(id,?name,?sales)?values?(7,?'路明非',?14738);
?insert?into?workers(id,?name,?sales)?values?(8,?'呂歸塵',?7087);
?insert?into?workers(id,?name,?sales)?values?(11,?'姬野',?8565);
?insert?into?workers(id,?name,?sales)?values?(15,?'凱撒',?8501);
?insert?into?workers(id,?name,?sales)?values?(20,?'繪梨衣',?7890);
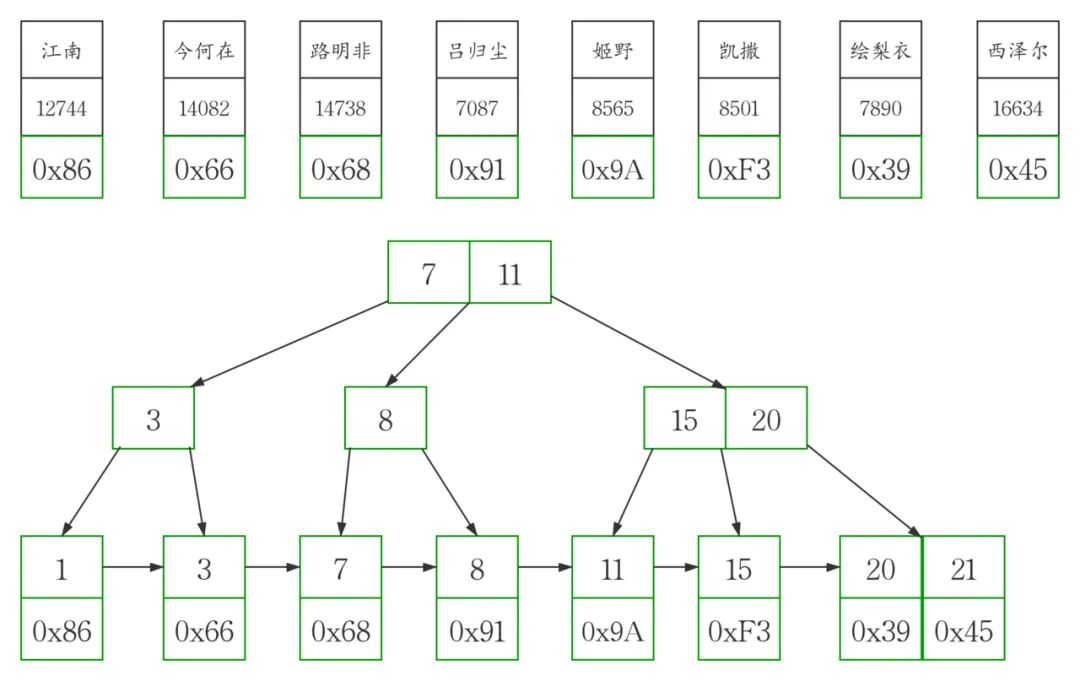
我們現(xiàn)在自己的測(cè)試數(shù)據(jù)庫(kù)中創(chuàng)建一個(gè)包含銷售員信息的測(cè)試表workers
包含id(主鍵),name,sales三個(gè)字段,指定表的存儲(chǔ)引擎為InnoDB。
然后插入8條數(shù)據(jù)
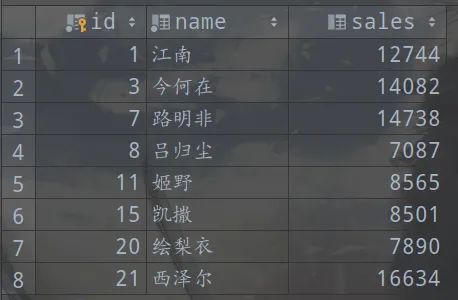
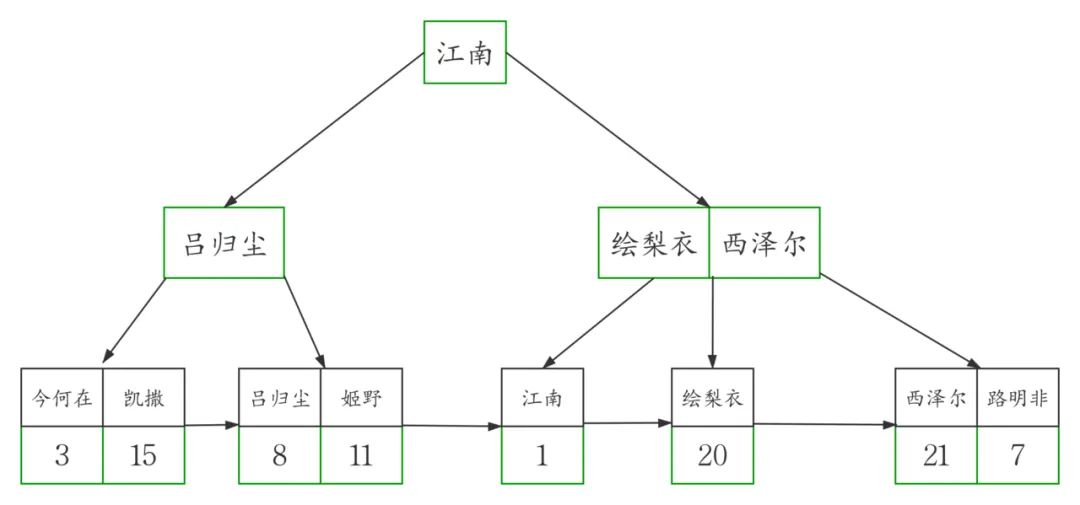
這個(gè)例子當(dāng)中,workers表的聚簇索引建立在字段id上
為了準(zhǔn)確模擬,我們先把主鍵id插入b+tree得到下圖
然后在此圖基礎(chǔ)上,我畫(huà)出了高清版。
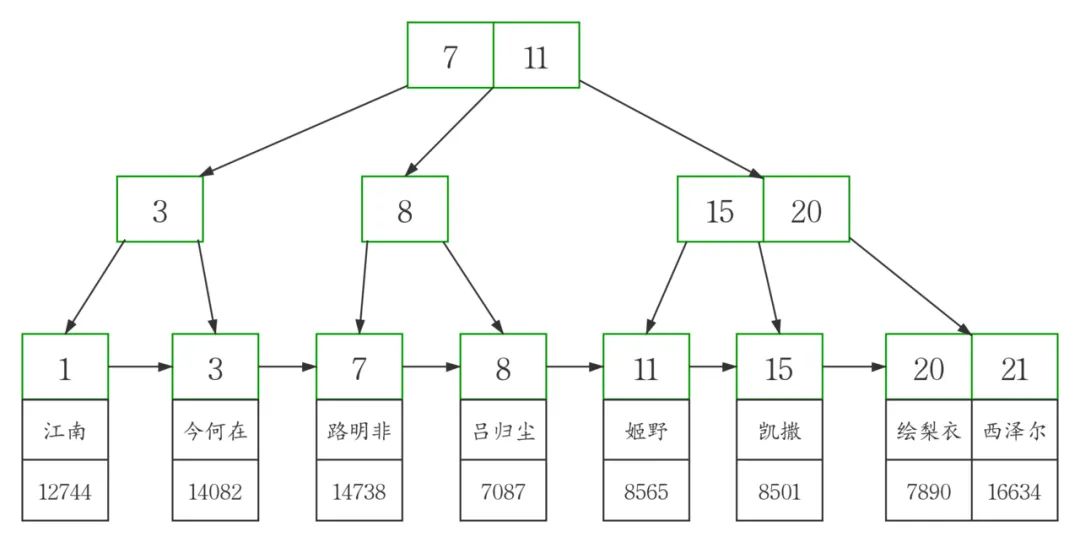
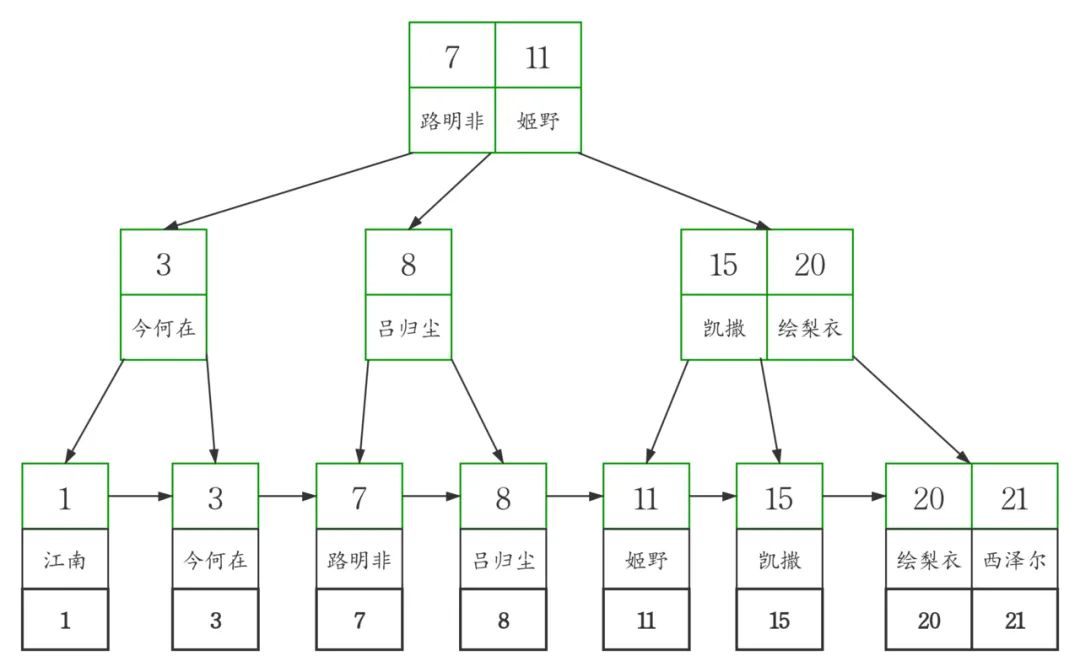
接著來(lái)看二級(jí)索引。
還以剛才的workers表為例
我們?cè)趎ame字段上添加二級(jí)索引index_name
alter?table??workers?add?index??index_name(name);
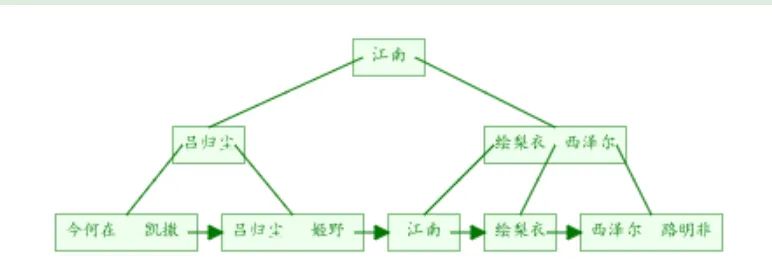
同樣我們畫(huà)出了二級(jí)索引index_name的B+tree示意圖
圖中可以看出二級(jí)索引的葉子節(jié)點(diǎn)并不存儲(chǔ)一行完整的表數(shù)據(jù),而是存儲(chǔ)了聚簇索引所在列的值,也就是
workers表中的id列的值。
這兩張示意圖中B+tree的度設(shè)置為了3 ,這也主要是為了方便演示。
實(shí)際的B+tree索引中,樹(shù)的度通常會(huì)大于100。
說(shuō)了聚簇索引和二級(jí)索引 肯定要提到回表查詢。
由于二級(jí)索引的葉子節(jié)點(diǎn)不存儲(chǔ)完整的表數(shù)據(jù),所以當(dāng)通過(guò)二級(jí)索引查詢到聚簇索引的列值后,還需要回到局促索引也就是表數(shù)據(jù)本身進(jìn)一步獲取數(shù)據(jù)。
比如說(shuō)我們要在workers表中查詢 名叫呂歸塵的人
select?*?from?workers?where?name='呂歸塵';
這條sql通過(guò)name='呂歸塵'的條件
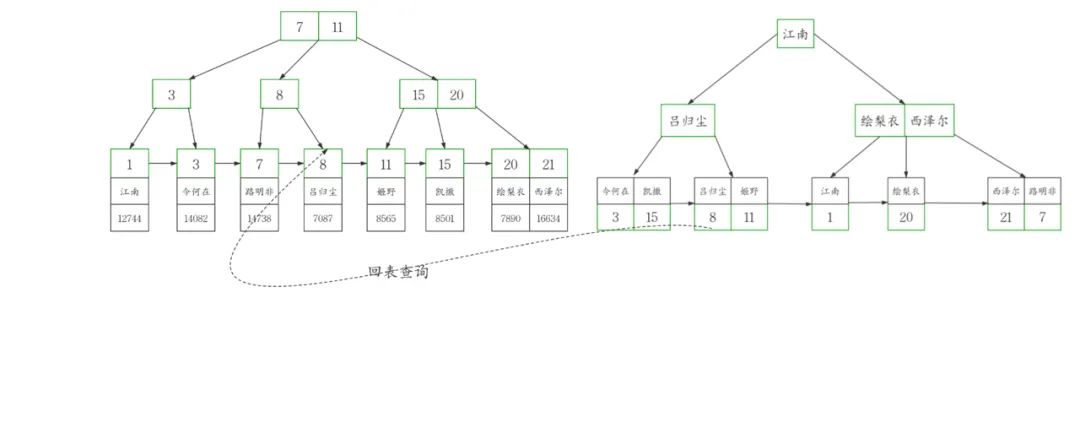
在二級(jí)索引index_name中查詢到主鍵id=8 ,接著帶著id=8這個(gè)條件
進(jìn)一步回到聚簇索引查詢以后才能獲取到完整的數(shù)據(jù),很顯然回表需要額外的B+tree搜索過(guò)程,必然增大查詢耗時(shí)。
需要注意的是通過(guò)二級(jí)索引查詢時(shí),回表不是必須的過(guò)程,當(dāng)Query的所有字段在二級(jí)索引中就能找到時(shí),就不需要回表,MySQL稱此時(shí)的二級(jí)索引為覆蓋索引或稱觸發(fā)了索引覆蓋。
select?id,name?from?workers?where?name='呂歸塵';
這句sql只查詢了id,和name,二級(jí)索引就已經(jīng)包含了Query所以需要的所有字段,就無(wú)需回表查詢。
explain?select?id,name?from?workers?where?name='呂歸塵';
使用explain查看此條sql的執(zhí)行計(jì)劃

執(zhí)行計(jì)劃的Extra字段中出現(xiàn)了Using where;Using index表明查詢觸發(fā)了索引index_name的索引覆蓋,且對(duì)索引做了where篩選,這里不需要回表。
下面做對(duì)比,查詢一下沒(méi)有索引的
explain?select?id,name,sales?from?workers?where?name='呂歸塵';

Extra為Using Index Condition 表示會(huì)先條件過(guò)濾索引,過(guò)濾完索引后找到所有符合索引條件的數(shù)據(jù)行,隨后用 WHERE 子句中的其他條件去過(guò)濾這些數(shù)據(jù)行。Index Condition Pushdown (ICP)是MySQL 5.6 以上版本中的新特性,是一種在存儲(chǔ)引擎層使用索引過(guò)濾數(shù)據(jù)的一種優(yōu)化方式。ICP開(kāi)啟時(shí)的執(zhí)行計(jì)劃含有 Using index condition 標(biāo)示 ,表示優(yōu)化器使用了ICP對(duì)數(shù)據(jù)訪問(wèn)進(jìn)行優(yōu)化。
如果你對(duì)此感興趣去查閱對(duì)應(yīng)的官方文檔和技術(shù)博客。
這次我們簡(jiǎn)化來(lái)理解,不考慮ICP對(duì)數(shù)據(jù)訪問(wèn)的優(yōu)化,
當(dāng)關(guān)閉ICP時(shí),Index僅僅是data access的一種訪問(wèn)方式,存儲(chǔ)引擎通過(guò)索引回表獲取的數(shù)據(jù)會(huì)傳遞到MySQL Server 層進(jìn)行WHERE條件過(guò)濾。
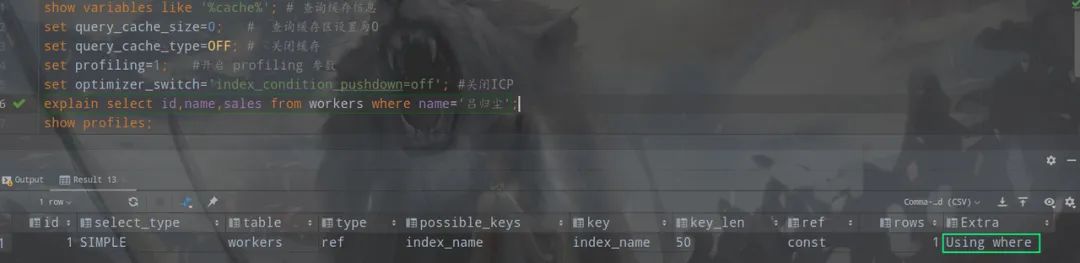
Extra為Using where 只是提醒我們MySQL將用where子句來(lái)過(guò)濾結(jié)果集。這個(gè)一般發(fā)生在MySQL服務(wù)器,而不是存儲(chǔ)引擎層。一般發(fā)生在不能走索引掃描的情況下或者走索引掃描,但是有些查詢條件不在索引當(dāng)中的情況下。
這里表明沒(méi)有觸發(fā)索引覆蓋,進(jìn)行回表查詢。
MyISAM的索引
說(shuō)完了InnoDB的索引,接下來(lái)我們來(lái)看MyISAM的索引
以MyISAM存儲(chǔ)引擎存儲(chǔ)的表不存在聚簇索引。
MyISAM索引B+tree示意圖
MyISAM表中的主鍵索引和非主鍵索引的結(jié)構(gòu)是一樣的,從上圖中我們可以看到
他們的葉子節(jié)點(diǎn)是不存儲(chǔ)表數(shù)據(jù)的,節(jié)點(diǎn)中存放的是表數(shù)據(jù)的地址,所以MyISAM表可以沒(méi)有主鍵。
MyISAM表的數(shù)據(jù)和索引是分開(kāi)的,是單獨(dú)存放的。
MyISAM表中的主鍵索引和非主鍵索引的區(qū)別僅在于主鍵索引B+tree上的key必須符合主鍵的限制,
非主鍵索引B+tree上的key只要符合相應(yīng)字段的特性就可以了。
索引字段特性角度看索引
主鍵索引
建立在主鍵字段上的索引 一張表最多只有一個(gè)主鍵索引 索引列值不允許為null 通常在創(chuàng)建表的時(shí)候一起創(chuàng)建
唯一索引
建立在UNIQUE字段上的索引就是唯一索引 一張表可以有多個(gè)唯一索引,索引列值允許為null
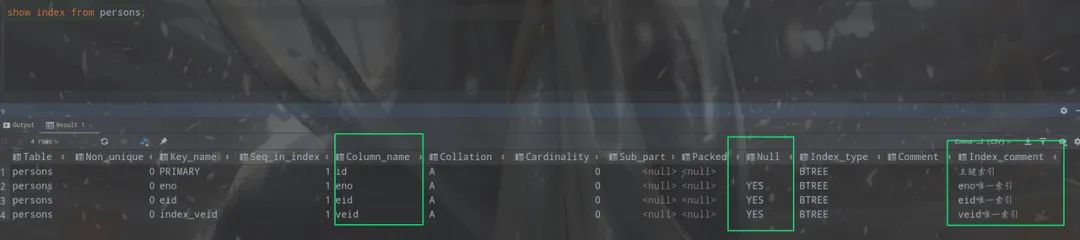
我們演示創(chuàng)建索引
create?table?persons
?(
?????id???int(11)?not?null?auto_increment?comment?'主鍵id',
?????eno??int(11)?comment?'工號(hào)',
?????eid??int(11)?comment?'身份證號(hào)',
?????veid?int(11)?comment?'虛擬身份證號(hào)',
?????name?varchar(16)?comment?'名字',
?????primary?key?(id)?comment?'主鍵索引',
?????UNIQUE?key?(eno)?comment?'eno唯一索引',
?????UNIQUE?key?(eid)?comment?'eid唯一索引'
?)?engine?=?InnoDB
???auto_increment?=?1000
???default?charset?=?utf8;
?
?alter?table?persons
?????add?unique?index?index_veid?(veid)?comment?'veid唯一索引';
通過(guò)show index from persons;命令我們看到已經(jīng)成功創(chuàng)建了三個(gè)唯一索引。
普通索引
主鍵索引和唯一索引對(duì)字段的要求是要求字段為主鍵或unique字段,
而那些建立在普通字段上的索引叫做普通索引,既不要求字段為主鍵也不要求字段為unique。
前綴索引
前綴索引是指對(duì)字符類型字段的前幾個(gè)字符或?qū)ΧM(jìn)制類型字段的前幾個(gè)bytes建立的索引,而不是在整個(gè)字段上建索引。
例如,可以對(duì)persons表中的name(varchar(16))字段 中name的前5個(gè)字符建立索引。
create?index?index_name?on?persons?(name(5))?comment?'前綴索引';
?show?index?from?persons;
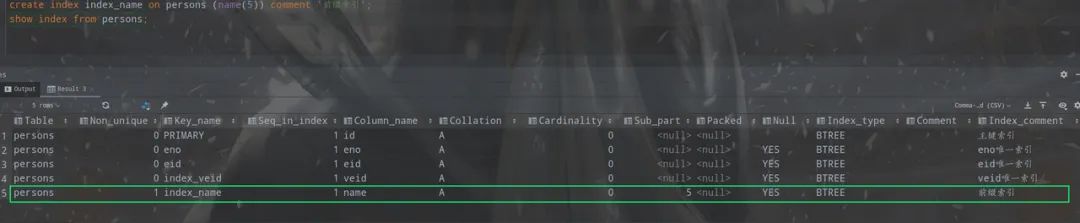
前綴索引可以建立在類型為
char varchar binary varbinary
的列上,可以大大減少索引占用的存儲(chǔ)空間,也能提升索引的查詢效率。
索引列的個(gè)數(shù)角度看索引
建立在單個(gè)列上的索引為單列索引 建立在多列上的稱為聯(lián)合索引(復(fù)合索引)
演示一下聯(lián)合索引
create?index?index_id_name?on?workers(id,name)?comment?'組合索引';
這條語(yǔ)句在我們演示表workers中建立id,name這兩個(gè)字段的聯(lián)合索引。
借助show index命令查看索引的詳細(xì)信息 操作后結(jié)果如下:

雖然詳細(xì)信息當(dāng)中列出了兩條關(guān)于聯(lián)合索引的條目,但并不表示聯(lián)合索引是建立了多個(gè)索引,聯(lián)合索引是一個(gè)索引結(jié)構(gòu),這兩個(gè)條目表示的是組合索引中字段的具體信息,按建立索引時(shí)的書(shū)寫(xiě)順序排序。
同樣我們來(lái)看下聯(lián)合索引的B+tree示意圖
從圖中看到組合索引的非葉子節(jié)點(diǎn)保存了兩個(gè)字段的值作為B+tree的key值,當(dāng)B+tree上插入數(shù)據(jù)時(shí),先按字段id比較,在id相同的情況下按name字段比較。
后臺(tái)回復(fù)?學(xué)習(xí)資料?領(lǐng)取學(xué)習(xí)視頻