
MySQL模糊查詢再也用不著 like+% 了!
我們都知道 InnoDB 在模糊查詢數(shù)據(jù)時使用 "%xx" 會導(dǎo)致索引失效,但有時需求就是如此,類似這樣的需求還有很多,例如,搜索引擎需要根基用戶數(shù)據(jù)的關(guān)鍵字進(jìn)行全文查找,電子商務(wù)網(wǎng)站需要根據(jù)用戶的查詢條件,在可能需要在商品的詳細(xì)介紹中進(jìn)行查找,這些都不是B+樹索引能很好完成的工作。
通過數(shù)值比較,范圍過濾等就可以完成絕大多數(shù)我們需要的查詢了。但是,如果希望通過關(guān)鍵字的匹配來進(jìn)行查詢過濾,那么就需要基于相似度的查詢,而不是原來的精確數(shù)值比較,全文索引就是為這種場景設(shè)計(jì)的。
全文索引(Full-Text Search)是將存儲于數(shù)據(jù)庫中的整本書或整篇文章中的任意信息查找出來的技術(shù)。它可以根據(jù)需要獲得全文中有關(guān)章、節(jié)、段、句、詞等信息,也可以進(jìn)行各種統(tǒng)計(jì)和分析。
在早期的 MySQL 中,InnoDB 并不支持全文檢索技術(shù),從 MySQL 5.6 開始,InnoDB 開始支持全文檢索。
全文檢索通常使用倒排索引(inverted index)來實(shí)現(xiàn),倒排索引同 B+Tree 一樣,也是一種索引結(jié)構(gòu)。它在輔助表中存儲了單詞與單詞自身在一個或多個文檔中所在位置之間的映射,這通常利用關(guān)聯(lián)數(shù)組實(shí)現(xiàn),擁有兩種表現(xiàn)形式:
inverted file index:{單詞,單詞所在文檔的id} full inverted index:{單詞,(單詞所在文檔的id,再具體文檔中的位置)}
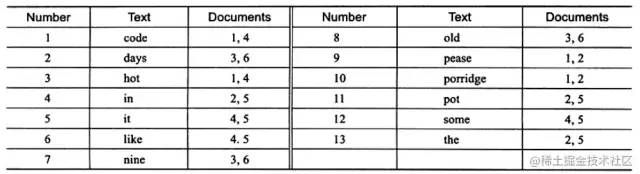
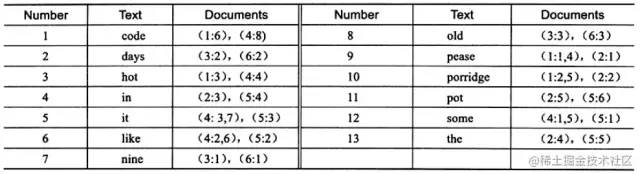
上圖為 inverted file index 關(guān)聯(lián)數(shù)組,可以看到其中單詞"code"存在于文檔1,4中,這樣存儲再進(jìn)行全文查詢就簡單了,可以直接根據(jù) Documents 得到包含查詢關(guān)鍵字的文檔;而 full inverted index 存儲的是對,即(DocumentId,Position),因此其存儲的倒排索引如下圖,如關(guān)鍵字"code"存在于文檔1的第6個單詞和文檔4的第8個單詞。相比之下,full inverted index 占用了更多的空間,但是能更好的定位數(shù)據(jù),并擴(kuò)充一些其他搜索特性。
全文檢索
創(chuàng)建全文索引
1、創(chuàng)建表時創(chuàng)建全文索引語法如下:
CREATE TABLE table_name ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, author VARCHAR(200),
title VARCHAR(200), content TEXT(500), FULLTEXT full_index_name (col_name) ) ENGINE=InnoDB;
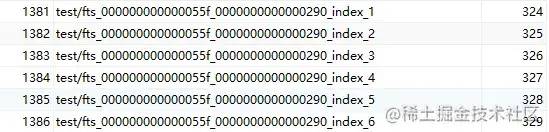
輸入查詢語句:
SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES
WHERE name LIKE 'test/%';
2、在已創(chuàng)建的表上創(chuàng)建全文索引語法如下:
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name);
使用全文索引
MySQL 數(shù)據(jù)庫支持全文檢索的查詢,全文索引只能在 InnoDB 或 MyISAM 的表上使用,并且只能用于創(chuàng)建 char,varchar,text 類型的列。
其語法如下:
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
全文搜索使用?`MATCH() AGAINST()`[1]語法進(jìn)行,其中,MATCH() 采用逗號分隔的列表,命名要搜索的列。AGAINST()接收一個要搜索的字符串,以及一個要執(zhí)行的搜索類型的可選修飾符。全文檢索分為三種類型:自然語言搜索、布爾搜索、查詢擴(kuò)展搜索,下面將對各種查詢模式進(jìn)行介紹。
Natural Language
自然語言搜索將搜索字符串解釋為自然人類語言中的短語,MATCH()默認(rèn)采用 Natural Language 模式,其表示查詢帶有指定關(guān)鍵字的文檔。
接下來結(jié)合demo來更好的理解Natural Language
SELECT
count(*) AS count
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL' );
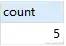
上述語句,查詢 title,body 列中包含 'MySQL' 關(guān)鍵字的行數(shù)量。上述語句還可以這樣寫:
SELECT
count(IF(MATCH ( title, body )
against ( 'MySQL' ), 1, NULL )) AS count
FROM
`fts_articles`;
上述兩種語句雖然得到的結(jié)果是一樣的,但從內(nèi)部運(yùn)行來看,第二句SQL的執(zhí)行速度更快些,因?yàn)榈谝痪銼QL(基于where索引查詢的方式)還需要進(jìn)行相關(guān)性的排序統(tǒng)計(jì),而第二種方式是不需要的。
還可以通過SQL語句查詢相關(guān)性:
SELECT
*,
MATCH ( title, body ) against ( 'MySQL' ) AS Relevance
FROM
fts_articles;
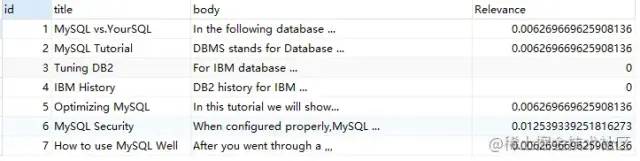
相關(guān)性的計(jì)算依據(jù)以下四個條件:
word 是否在文檔中出現(xiàn) word 在文檔中出現(xiàn)的次數(shù) word 在索引列中的數(shù)量 多少個文檔包含該 word
對于 InnoDB 存儲引擎的全文檢索,還需要考慮以下的因素:
查詢的 word 在 stopword 列中,忽略該字符串的查詢 查詢的 word 的字符長度是否在區(qū)間 [innodb_ft_min_token_size,innodb_ft_max_token_size] 內(nèi)
如果詞在 stopword 中,則不對該詞進(jìn)行查詢,如對 'for' 這個詞進(jìn)行查詢,結(jié)果如下所示:
SELECT
*,
MATCH ( title, body ) against ( 'for' ) AS Relevance
FROM
fts_articles;
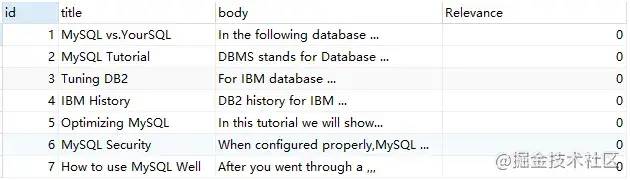
可以看到,'for'雖然在文檔 2,4中出現(xiàn),但由于其是 stopword ,故其相關(guān)性為0
Boolean
布爾搜索使用特殊查詢語言的規(guī)則來解釋搜索字符串,該字符串包含要搜索的詞,它還可以包含指定要求的運(yùn)算符,例如匹配行中必須存在或不存在某個詞,或者它的權(quán)重應(yīng)高于或低于通常情況。例如,下面的語句要求查詢有字符串"Pease"但沒有"hot"的文檔,其中+和-分別表示單詞必須存在,或者一定不存在。
select * from fts_test where MATCH(content) AGAINST('+Pease -hot' IN BOOLEAN MODE);
Boolean 全文檢索支持的類型包括:
+:表示該 word 必須存在 -:表示該 word 必須不存在 (no operator)表示該 word 是可選的,但是如果出現(xiàn),其相關(guān)性會更高 @distance表示查詢的多個單詞之間的距離是否在 distance 之內(nèi),distance 的單位是字節(jié),這種全文檢索的查詢也稱為 Proximity Search,如MATCH(context) AGAINST('"Pease hot"@30' IN BOOLEAN MODE)語句表示字符串 Pease 和 hot 之間的距離需在30字節(jié)內(nèi):表示出現(xiàn)該單詞時增加相關(guān)性
<:表示出現(xiàn)該單詞時降低相關(guān)性 ~:表示允許出現(xiàn)該單詞,但出現(xiàn)時相關(guān)性為負(fù) :表示以該單詞開頭的單詞,如 lik*,表示可以是lik,like,likes" :表示短語
下面是一些demo,看看 Boolean Mode 是如何使用的。
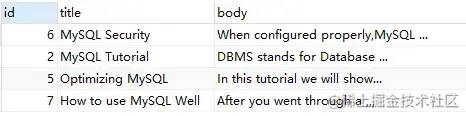
demo1:+ -
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '+MySQL -YourSQL' IN BOOLEAN MODE );
上述語句,查詢的是包含 'MySQL' 但不包含 'YourSQL' 的信息
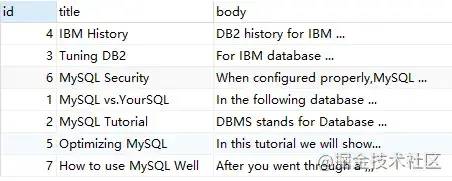
demo2:no operator
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL IBM' IN BOOLEAN MODE );
上述語句,查詢的 'MySQL IBM' 沒有 '+','-'的標(biāo)識,代表 word 是可選的,如果出現(xiàn),其相關(guān)性會更高
demo3:@
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '"DB2 IBM"@3' IN BOOLEAN MODE );
上述語句,代表 "DB2" ,"IBM"兩個詞之間的距離在3字節(jié)之內(nèi)
demo4:> <
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '+MySQL +(>database <DBMS)' IN BOOLEAN MODE );
上述語句,查詢同時包含 'MySQL','database','DBMS' 的行信息,但不包含'DBMS'的行的相關(guān)性高于包含'DBMS'的行。

demo5: ~
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL ~database' IN BOOLEAN MODE );
上述語句,查詢包含 'MySQL' 的行,但如果該行同時包含 'database',則降低相關(guān)性。

demo6:*
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'My*' IN BOOLEAN MODE );
上述語句,查詢關(guān)鍵字中包含'My'的行信息。
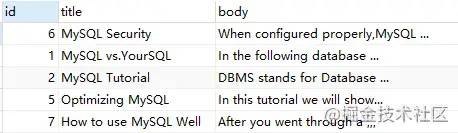
demo7:"
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '"MySQL Security"' IN BOOLEAN MODE );
上述語句,查詢包含確切短語 'MySQL Security' 的行信息。

Query Expansion
第一階段:根據(jù)搜索的單詞進(jìn)行全文索引查詢 第二階段:根據(jù)第一階段產(chǎn)生的分詞再進(jìn)行一次全文檢索的查詢
接著來看一個例子,看看 Query Expansion 是如何使用的。
-- 創(chuàng)建索引
create FULLTEXT INDEX title_body_index on fts_articles(title,body);
-- 使用 Natural Language 模式查詢
SELECT
*
FROM
`fts_articles`
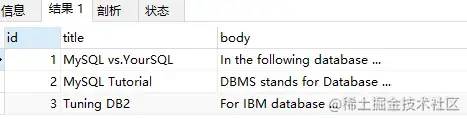
WHERE
MATCH(title,body) AGAINST('database');
使用 Query Expansion 前查詢結(jié)果如下:
-- 當(dāng)使用 Query Expansion 模式查詢
SELECT
*
FROM
`fts_articles`
WHERE
MATCH(title,body) AGAINST('database' WITH QUERY expansion);
使用 Query Expansion 后查詢結(jié)果如下:
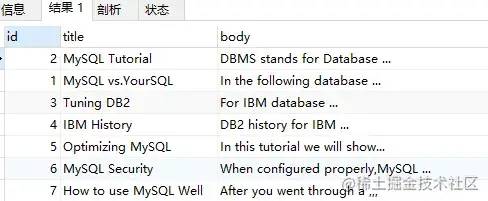
由于 Query Expansion 的全文檢索可能帶來許多非相關(guān)性的查詢,因此在使用時,用戶可能需要非常謹(jǐn)慎。
刪除全文索引
1、直接刪除全文索引語法如下:
DROP INDEX full_idx_name ON db_name.table_name;
2、使用 alter table 刪除全文索引語法如下:
ALTER TABLE db_name.table_name DROP INDEX full_idx_name;
小結(jié)
本文從理論與實(shí)踐結(jié)合的角度對 fulltext index 做了介紹
作者:沸羊羊
鏈接:juejin.cn/post/6989871497040887845
推薦閱讀:
世界的真實(shí)格局分析,地球人類社會底層運(yùn)行原理
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實(shí)踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf
華為如何實(shí)施數(shù)字化轉(zhuǎn)型(附PPT)