
ELK 性能優(yōu)化實(shí)踐
一、背景介紹
近一年內(nèi)對(duì)公司的 ELK 日志系統(tǒng)做過(guò)性能優(yōu)化,也對(duì) SkyWalking 使用的 ES 存儲(chǔ)進(jìn)行過(guò)性能優(yōu)化,在此做一些總結(jié)。本篇主要是講 ES 在 ELK 架構(gòu)中作為日志存儲(chǔ)時(shí)的性能優(yōu)化方案。
ELK 架構(gòu)作為日志存儲(chǔ)方案

二、現(xiàn)狀分析
1. 版本及硬件配置
JDK:JDK1.8_171-b11 (64 位) ES集群:由3臺(tái)16核32G的虛擬機(jī)部署 ES 集群,每個(gè)節(jié)點(diǎn)分配 20 G 堆內(nèi)存 ELK版本:6.3.0 垃圾回收器:ES 默認(rèn)指定的老年代(CMS)+ 新生代(ParNew) 操作系統(tǒng):CentOS Linux release 7.4.1708(Core)
2. 性能問(wèn)題
隨著接入 ELK 的應(yīng)用越來(lái)越多,每日新增索引約 230 個(gè),新增 document 約 3000 萬(wàn)到 5000 萬(wàn)。
每日上午和下午是日志上傳高峰期,在 Kibana 上查看日志,發(fā)現(xiàn)問(wèn)題:
(1) 日志會(huì)有 5-40 分鐘的延遲
(2) 有很多日志丟失,無(wú)法查到
3. 問(wèn)題分析
3.1 日志延遲
首先了解清楚:數(shù)據(jù)什么時(shí)候可以被查到?
數(shù)據(jù)先是存放在 ES 的內(nèi)存 buffer,然后執(zhí)行 refresh 操作寫(xiě)入到操作系統(tǒng)的內(nèi)存緩存 os cache,此后數(shù)據(jù)就可以被搜索到。
所以,日志延遲可能是我們的數(shù)據(jù)積壓在 buffer 中沒(méi)有進(jìn)入 os cache 。
3.2 日志丟失
查看日志發(fā)現(xiàn)很多 write 拒絕執(zhí)行的情況
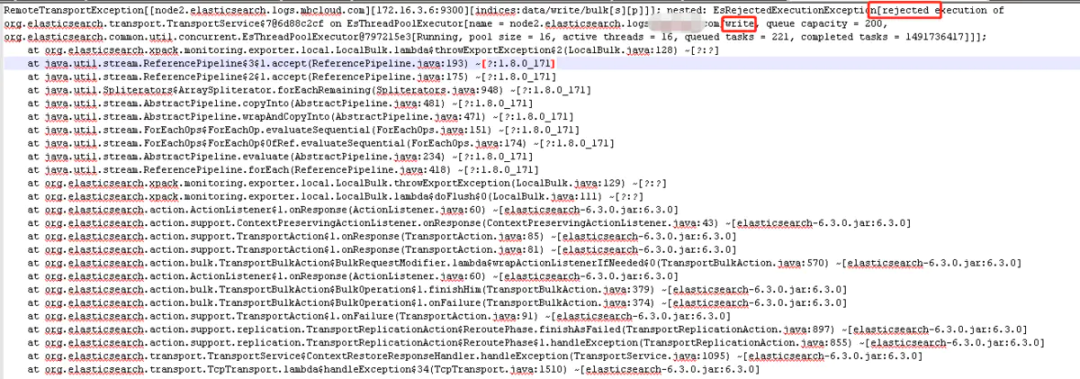
從日志中可以看出 ES 的 write 線程池已經(jīng)滿負(fù)荷,執(zhí)行任務(wù)的線程已經(jīng)達(dá)到最大 16 個(gè)線程,而 200 容量的隊(duì)列也已經(jīng)放不下新的 task。
查看線程池的情況也可以看出 write 線程池有很多寫(xiě)入的任務(wù)
GET?/_cat/thread_pool?v&h=host,name,type,size,active,largest,rejected,completed,queue,queue_size
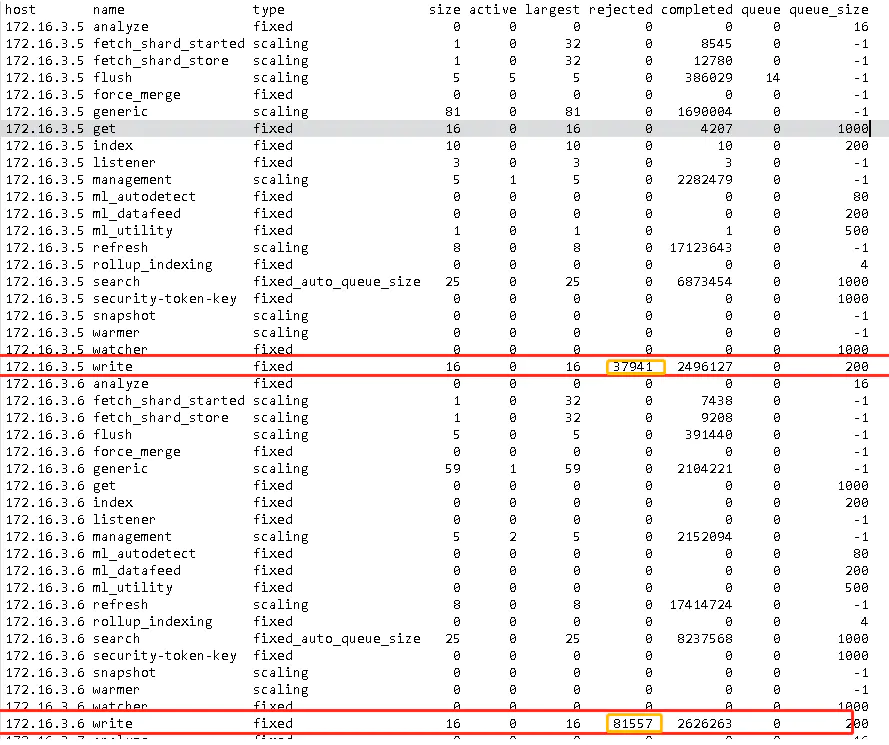
所以我們需要優(yōu)化 ES 的 write 的性能。
4.解決思路
4.1 分析場(chǎng)景
ES 的優(yōu)化分為很多方面,我們要根據(jù)使用場(chǎng)景考慮對(duì) ES 的要求。
根據(jù)個(gè)人實(shí)踐經(jīng)驗(yàn),列舉三種不同場(chǎng)景下的特點(diǎn):
SkyWalking:一般配套使用 ES 作為數(shù)據(jù)存儲(chǔ),存儲(chǔ)鏈路追蹤數(shù)據(jù)、指標(biāo)數(shù)據(jù)等信息。 ELK:一般用來(lái)存儲(chǔ)系統(tǒng)日志,并進(jìn)行分析,搜索,定位應(yīng)用的問(wèn)題。 全文搜索的業(yè)務(wù):業(yè)務(wù)中常用 ES 作為全文搜索引擎,例如在外賣(mài)應(yīng)用中,ES 用來(lái)存儲(chǔ)商家、美食的業(yè)務(wù)數(shù)據(jù),用戶在客戶端可以根據(jù)關(guān)鍵字、地理位置等查詢(xún)條件搜索商家、美食信息。
這三類(lèi)場(chǎng)景的特點(diǎn)如下:
| SkyWalking | ELK | 全文搜索的業(yè)務(wù) | |
|---|---|---|---|
| 并發(fā)寫(xiě) | 高并發(fā)寫(xiě) | 高并發(fā)寫(xiě) | 并發(fā)一般不高 |
| 并發(fā)讀 | 并發(fā)低 | 并發(fā)低 | 并發(fā)高 |
| 實(shí)時(shí)性要求 | 5分鐘以?xún)?nèi) | 30秒以?xún)?nèi) | 1分鐘內(nèi) |
| 數(shù)據(jù)完整性 | 可容忍丟失少量數(shù)據(jù) | 可容忍丟失少量數(shù)據(jù) | 數(shù)據(jù)盡量100%不丟失 |
關(guān)于實(shí)時(shí)性
SkyWalking 在實(shí)際使用中,一般使用頻率不太高,往往是發(fā)現(xiàn)應(yīng)用的問(wèn)題后,再去 SkyWalking 查歷史鏈路追蹤數(shù)據(jù)或指標(biāo)數(shù)據(jù),所以可以接受幾分鐘的延遲。 ELK 不管是開(kāi)發(fā)、測(cè)試等階段,時(shí)常用來(lái)定位應(yīng)用的問(wèn)題,如果不能快速查詢(xún)出數(shù)據(jù),延遲太久,會(huì)耽誤很多時(shí)間,大大降低工作效率;如果是查日志定位生產(chǎn)問(wèn)題,那更是刻不容緩。 全文搜索的業(yè)務(wù)中一般可以接受在1分鐘內(nèi)查看到最新數(shù)據(jù),比如新商品上架一分鐘后才看到,但盡量實(shí)時(shí),在幾秒內(nèi)可以可看到。
4.2 優(yōu)化的方向
可以從三方面進(jìn)行優(yōu)化:JVM 性能調(diào)優(yōu)、ES 性能調(diào)優(yōu)、控制數(shù)據(jù)來(lái)源
三、ES性能優(yōu)化
可以從三方面進(jìn)行優(yōu)化:JVM 性能調(diào)優(yōu)、ES 性能調(diào)優(yōu)、控制數(shù)據(jù)來(lái)源
1. JVM調(diào)優(yōu)
第一步是 JVM 調(diào)優(yōu)。
因?yàn)?ES 是依賴(lài)于 JVM 運(yùn)行,沒(méi)有合理的設(shè)置 JVM 參數(shù),將浪費(fèi)資源,甚至導(dǎo)致 ES 很容易 OOM 而崩潰。
1.1 監(jiān)控 JVM 運(yùn)行情況
(1)查看 GC 日志
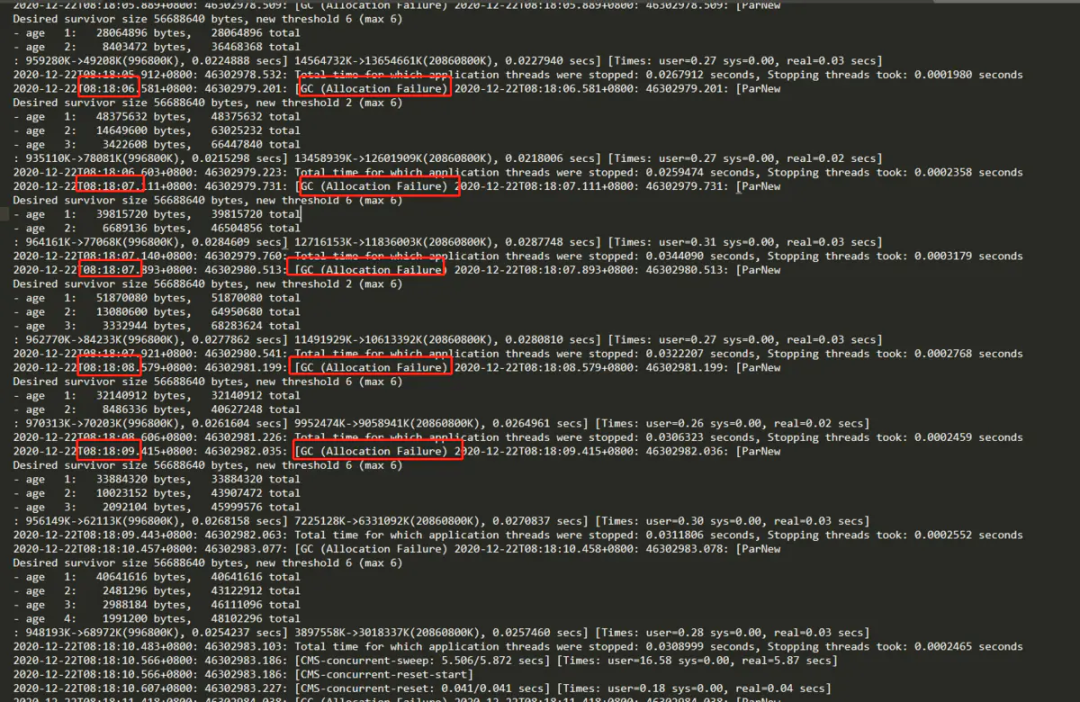
問(wèn)題:Young GC 和 Full GC 都很頻繁,特別是 Young GC 頻率高,累積耗時(shí)非常多。
(2) 使用 jstat 看下每秒的 GC 情況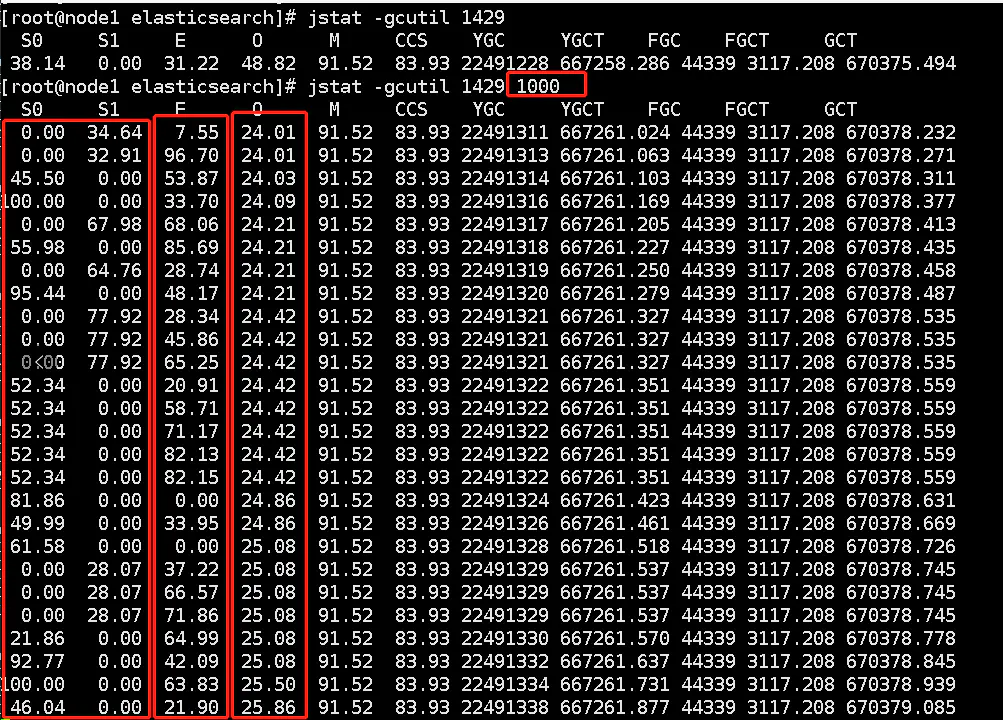 參數(shù)說(shuō)明
參數(shù)說(shuō)明
S0:幸存1區(qū)當(dāng)前使用比例 S1:幸存2區(qū)當(dāng)前使用比例 E:伊甸園區(qū)使用比例 O:老年代使用比例 M:元數(shù)據(jù)區(qū)使用比例 CCS:壓縮使用比例 YGC:年輕代垃圾回收次數(shù) FGC:老年代垃圾回收次數(shù) FGCT:老年代垃圾回收消耗時(shí)間 GCT:垃圾回收消耗總時(shí)間問(wèn)題:從 jstat gc 中也可以看出,每秒的 eden 增長(zhǎng)速度非常快,很快就滿了。
1.2 定位 Young GC 頻繁的原因
1.2.1 檢查是否新生代的空間是否太小
用下面幾種方式都可查看新、老年代內(nèi)存大小
(1) 使用 jstat -gc pid ?查看 Eden 區(qū)、老年代空間大小
(2) 使用 jmap -heap pid ?查看 Eden 區(qū)、老年代空間大小
(3) 查看 GC 日志中的 GC 明細(xì) 其中 996800K 為新生代可用空間大小,即 Eden 區(qū) +1 個(gè) Survivor 區(qū)的空間大小,所以新生代總內(nèi)存是996800K/0.9, 約1081M
其中 996800K 為新生代可用空間大小,即 Eden 區(qū) +1 個(gè) Survivor 區(qū)的空間大小,所以新生代總內(nèi)存是996800K/0.9, 約1081M
上面的幾種方式都查詢(xún)出,新生代總內(nèi)存約1081M,即1G左右;老年代總內(nèi)存為19864000K,約19G。新、老比例約1:19,出乎意料。
1.2.1 新老年代空間比例為什么不是 JDK 默認(rèn)的1:2【重點(diǎn)!】
這真是一個(gè)容易踩坑的地方。如果沒(méi)有顯示設(shè)置新生代大小,JVM 在使用 CMS 收集器時(shí)會(huì)自動(dòng)調(diào)參,新生代的大小在沒(méi)有設(shè)置的情況下是通過(guò)計(jì)算得出的,其大小可能與 NewRatio 的默認(rèn)配置沒(méi)什么關(guān)系而與 ParallelGCThreads 的配置有一定的關(guān)系。
參考文末鏈接:CMS GC 默認(rèn)新生代是多大?
所以:新生代大小有不確定性,最好配置 JVM 參數(shù) -XX:NewSize、-XX:MaxNewSize 或者 -xmn ,免得遇到一些奇怪的 GC,讓人措手不及。
1.3 上面現(xiàn)象造成的影響
新生代過(guò)小,老年代過(guò)大的影響
新生代過(guò)小: (1) 會(huì)導(dǎo)致新生代 Eden 區(qū)很快用完,而觸發(fā) Young GC,Young GC 的過(guò)程中會(huì) STW(Stop The World),也就是所有工作線程停止,只有 GC 的線程在進(jìn)行垃圾回收,這會(huì)導(dǎo)致 ES 短時(shí)間停頓。頻繁的 Young GC,積少成多,對(duì)系統(tǒng)性能影響較大。(2) 大部分對(duì)象很快進(jìn)入老年代,老年代很容易用完而觸發(fā) Full GC。 老年代過(guò)大:會(huì)導(dǎo)致 Full GC 的執(zhí)行時(shí)間過(guò)長(zhǎng),F(xiàn)ull GC 雖然有并行處理的步驟,但是還是比 Young GC 的 STW 時(shí)間更久,而 GC 導(dǎo)致的停頓時(shí)間在幾十毫秒到幾秒內(nèi),很影響 ES 的性能,同時(shí)也會(huì)導(dǎo)致請(qǐng)求 ES 服務(wù)端的客戶端在一定時(shí)間內(nèi)沒(méi)有響應(yīng)而發(fā)生 timeout 異常,導(dǎo)致請(qǐng)求失敗。
1.4 JVM優(yōu)化
1.4.1 配置堆內(nèi)存空間大小
32G 的內(nèi)存,分配 20G 給堆內(nèi)存是不妥當(dāng)?shù)模哉{(diào)整為總內(nèi)存的50%,即16G。修改 elasticsearch 的 jvm.options 文件
-Xms16g
-Xmx16g
設(shè)置要求:
Xms 與 Xmx 大小相同。
在 jvm 的參數(shù)中 -Xms 和 -Xmx 設(shè)置的不一致,在初始化時(shí)只會(huì)初始 -Xms 大小的空間存儲(chǔ)信息,每當(dāng)空間不夠用時(shí)再向操作系統(tǒng)申請(qǐng),這樣的話必然要進(jìn)行一次 GC,GC會(huì)帶來(lái) STW。而剩余空間很多時(shí),會(huì)觸發(fā)縮容。再次不夠用時(shí)再擴(kuò)容,如此反復(fù),這些過(guò)程會(huì)影響系統(tǒng)性能。同理在 MetaSpace 區(qū)也有類(lèi)似的問(wèn)題。
jvm 建議不要超過(guò) 32G,否則 jvm 會(huì)禁用內(nèi)存對(duì)象指針壓縮技術(shù),造成內(nèi)存浪費(fèi)
Xmx 和 Xms 不要超過(guò)物理 RAM 的50%。參考文末:官方堆內(nèi)存設(shè)置的建議
Xmx 和 Xms 不要超過(guò)物理內(nèi)存的50%。Elasticsearch 需要內(nèi)存用于JVM堆以外的其他用途,為此留出空間非常重要。例如,Elasticsearch 使用堆外緩沖區(qū)進(jìn)行有效的網(wǎng)絡(luò)通信,依靠操作系統(tǒng)的文件系統(tǒng)緩存來(lái)高效地訪問(wèn)文件,而 JVM 本身也需要一些內(nèi)存。
1.4.2 配置堆內(nèi)存新生代空間大小
因?yàn)橹付ㄐ律臻g大小,導(dǎo)致 JVM 自動(dòng)調(diào)參只分配了 1G 內(nèi)存給新生代。
修改 elasticsearch 的 jvm.options 文件,加上
-XX:NewSize=8G
-XX:MaxNewSize=8G
老年代則自動(dòng)分配 16G-8G=8G 內(nèi)存,新生代老年代的比例為 1:1。修改后每次 Young GC 頻率更低,且每次 GC 后只有少數(shù)數(shù)據(jù)會(huì)進(jìn)入老年代。
2.3 使用G1垃圾回收器(未實(shí)踐)
G1垃圾回收器讓系統(tǒng)使用者來(lái)設(shè)定垃圾回收堆系統(tǒng)的影響,然后把內(nèi)存拆分為大量的小 Region,追蹤每個(gè) Region 中可以回收的對(duì)象大小和回收完成的預(yù)計(jì)花費(fèi)的時(shí)間, 最后在垃圾回收的時(shí)候,盡量把垃圾回收對(duì)系統(tǒng)造成的影響控制在我們指定的時(shí)間范圍內(nèi),同時(shí)在有限的時(shí)間內(nèi)盡量回收更多的垃圾對(duì)象。G1垃圾回收器一般在大數(shù)量、大內(nèi)存的情況下有更好的性能。
ES默認(rèn)使用的垃圾回收器是:老年代(CMS)+ 新生代(ParNew)。如果是JDK1.9,ES 默認(rèn)使用 G1 垃圾回收器。
因?yàn)槭褂玫氖?JDK1.8,所以并未切換垃圾回收器。后續(xù)如果再有性能問(wèn)題再切換G1垃圾回收器,測(cè)試是否有更好的性能。
1.5 優(yōu)化的效果
1.5.1 新生代使用內(nèi)存的增長(zhǎng)率更低
優(yōu)化前

每秒打印一次 GC 數(shù)據(jù)。可以看出,年輕代增長(zhǎng)速度很快,幾秒鐘年輕代就滿了,導(dǎo)致 Young GC 觸發(fā)很頻繁,幾秒鐘就會(huì)觸發(fā)一次。而每次 Young GC 很大可能有存活對(duì)象進(jìn)入老年代,而且,存活對(duì)象多的時(shí)候(看上圖中第一個(gè)紅框中的old gc數(shù)據(jù)),有(51.44-51.08)/100 * 19000M = 約68M。每次進(jìn)入老年代的對(duì)象較多,加上頻繁的 Young GC,會(huì)導(dǎo)致新老年代的分代模式失去了作用,相當(dāng)于老年代取代了新生代來(lái)存放近期內(nèi)生成的對(duì)象。當(dāng)老年代滿了,觸發(fā) Full GC,存活的對(duì)象也會(huì)很多,因?yàn)檫@些對(duì)象很可能還是近期加入的,還存活著,所以一次 Full GC 回收對(duì)象不多。而這會(huì)惡性循環(huán),老年代很快又滿了,又 Full GC,又殘留一大部分存活的,又很容易滿了,所以導(dǎo)致一直頻繁 Full GC。
優(yōu)化后
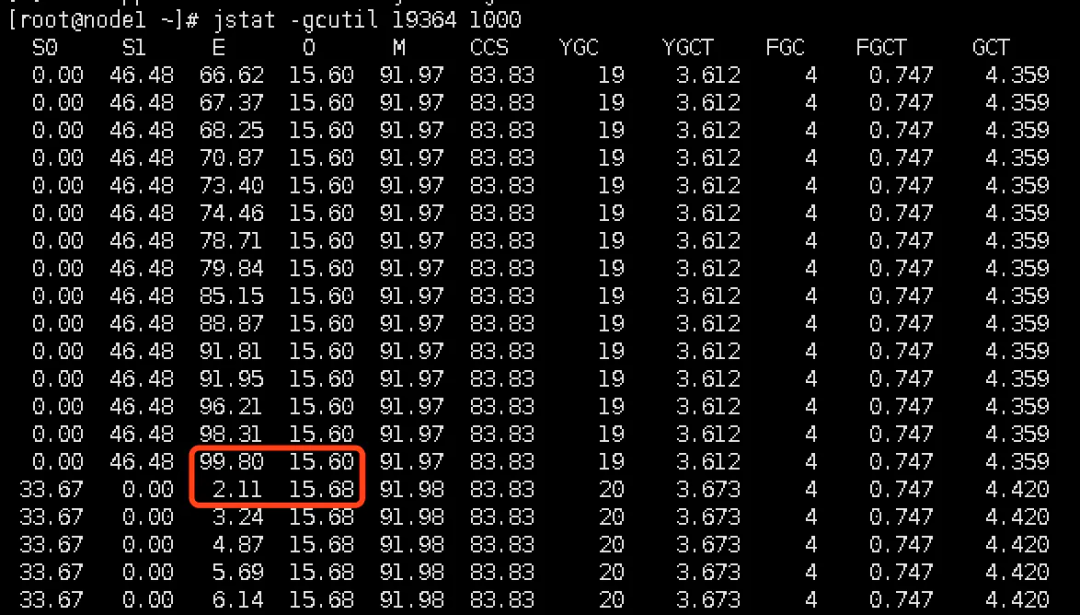
每秒打印一次 GC 數(shù)據(jù)。可以看出,新生代增長(zhǎng)速度慢了許多,至少要 60 秒才會(huì)滿,如上圖紅框中數(shù)據(jù),進(jìn)入老年代的對(duì)象約(15.68-15.60)/100 * 10000 = 8M,非常的少。所以要很久才會(huì)觸發(fā)一次 Full GC 。而且等到 Full GC 時(shí),老年代里很多對(duì)象都是存活了很久的,一般都是不會(huì)被引用,所以很大一部分會(huì)被回收掉,留一個(gè)比較干凈的老年代空間,可以繼續(xù)放很多對(duì)象。
1.5.2 新生代和老年代 GC 頻率更低
ES 啟動(dòng)后,運(yùn)行14個(gè)小時(shí)
優(yōu)化前

Young GC 每次的時(shí)間是不長(zhǎng)的,從上面監(jiān)控?cái)?shù)據(jù)中可以看出每次GC時(shí)長(zhǎng) 1467.995/27276 約等于 0.05 秒。那一秒鐘有多少時(shí)間是在處理 Young GC ?
計(jì)算公式:1467 秒/( 60 秒× 60 分 14 小時(shí))= 約 0.028 秒,也就是 100 秒中就有 2.8 秒在Young GC,也就是有 2.8S 的停頓,這對(duì)性能還是有很大消耗的。同時(shí)也可以算出多久一次 Young GC, 方程是:60秒×60分*14小時(shí)/ 27276次 = 1次/X秒,計(jì)算得出X = 0.54,也就是 0.54 秒就會(huì)有一次 Young GC,可見(jiàn) Young GC 頻率非常頻繁。
優(yōu)化后

Young GC 次數(shù)只有修改前的十分之一,Young GC 時(shí)間也是約八分之一。Full GC 的次數(shù)也是只有原來(lái)的八分之一,GC 時(shí)間大約是四分之一。
GC 對(duì)系統(tǒng)的影響大大降低,性能已經(jīng)得到很大的提升。
2.ES 調(diào)優(yōu)
上面已經(jīng)分析過(guò) ES 作為日志存儲(chǔ)時(shí)的特性是:高并發(fā)寫(xiě)、讀少、接受 30 秒內(nèi)的延時(shí)、可容忍部分日志數(shù)據(jù)丟失。下面我們針對(duì)這些特性對(duì)ES進(jìn)行調(diào)優(yōu)。
2.1 優(yōu)化 ES 索引設(shè)置
2.2.1 ES 寫(xiě)數(shù)據(jù)底層原理
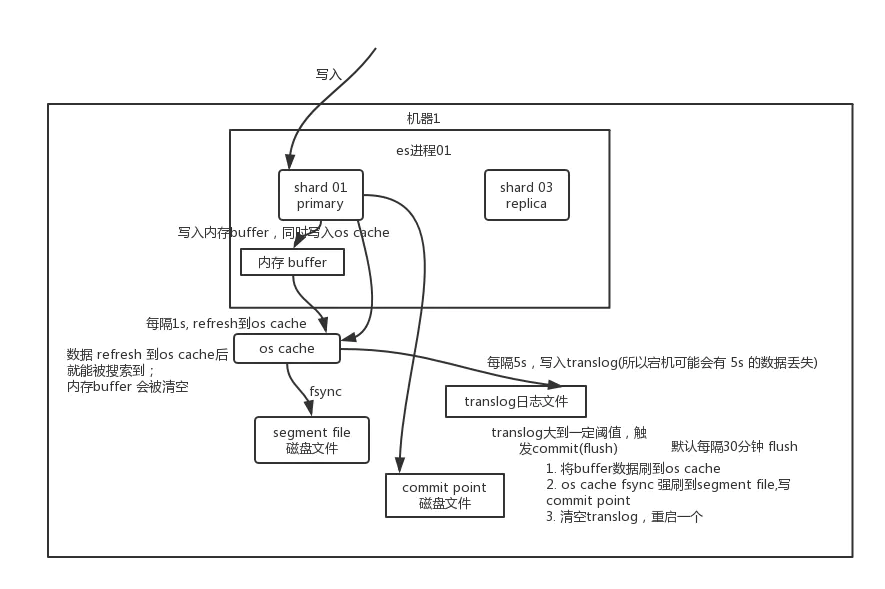
refresh ES 接收數(shù)據(jù)請(qǐng)求時(shí)先存入 ES 的內(nèi)存中,默認(rèn)每隔一秒會(huì)從內(nèi)存 buffer 中將數(shù)據(jù)寫(xiě)入操作系統(tǒng)緩存 os cache,這個(gè)過(guò)程叫做 refresh;
到了 os cache 數(shù)據(jù)就能被搜索到(所以我們才說(shuō) ES 是近實(shí)時(shí)的,因?yàn)?1 s 的延遲后執(zhí)行 refresh 便可讓數(shù)據(jù)被搜索到)
fsync translog 會(huì)每隔 5 秒或者在一個(gè)變更請(qǐng)求完成之后執(zhí)行一次 fsync 操作,將 translog 從緩存刷入磁盤(pán),這個(gè)操作比較耗時(shí),如果對(duì)數(shù)據(jù)一致性要求不是很高時(shí)建議將索引改為異步,如果節(jié)點(diǎn)宕機(jī)時(shí)會(huì)有5秒數(shù)據(jù)丟失;
flush ES 默認(rèn)每隔30分鐘會(huì)將 os cache 中的數(shù)據(jù)刷入磁盤(pán)同時(shí)清空 translog 日志文件,這個(gè)過(guò)程叫做 flush。
merge
ES 的一個(gè) index 由多個(gè) shard 組成,而一個(gè) shard 其實(shí)就是一個(gè) Lucene 的 index ,它又由多個(gè) segment 組成,且 Lucene 會(huì)不斷地把一些小的 segment 合并成一個(gè)大的 segment ,這個(gè)過(guò)程被稱(chēng)為段merge(參考文末鏈接)。執(zhí)行索引操作時(shí),ES 會(huì)先生成小的segment,ES 有離線的邏輯對(duì)小的 segment 進(jìn)行合并,優(yōu)化查詢(xún)性能。但是合并過(guò)程中會(huì)消耗較多磁盤(pán) IO,會(huì)影響查詢(xún)性能。
2.2.2 優(yōu)化方向
2.2.2.1 優(yōu)化 fsync
為了保證不丟失數(shù)據(jù),就要保護(hù) translog 文件的安全:
Elasticsearch 2.0 之后, 每次寫(xiě)請(qǐng)求(如 index 、delete、update、bulk 等)完成時(shí), 都會(huì)觸發(fā)
fsync將 translog 中的 segment 刷到磁盤(pán), 然后才會(huì)返回200 OK的響應(yīng);或者: 默認(rèn)每隔5s就將 translog 中的數(shù)據(jù)通過(guò)
fsync強(qiáng)制刷新到磁盤(pán).
該方式提高數(shù)據(jù)安全性的同時(shí), 降低了一點(diǎn)性能.
==> 頻繁地執(zhí)行 fsync 操作, 可能會(huì)產(chǎn)生阻塞導(dǎo)致部分操作耗時(shí)較久. 如果允許部分?jǐn)?shù)據(jù)丟失, 可設(shè)置異步刷新 translog 來(lái)提高效率,還有降低 flush 的閥值,優(yōu)化如下:
"index.translog.durability":?"async",
"index.translog.flush_threshold_size":"1024mb",
"index.translog.sync_interval":?"120s"
2.2.2.2 優(yōu)化 refresh
寫(xiě)入 Lucene 的數(shù)據(jù),并不是實(shí)時(shí)可搜索的,ES 必須通過(guò) refresh 的過(guò)程把內(nèi)存中的數(shù)據(jù)轉(zhuǎn)換成 Lucene 的完整 segment 后,才可以被搜索。
默認(rèn) 1秒后,寫(xiě)入的數(shù)據(jù)可以很快被查詢(xún)到,但勢(shì)必會(huì)產(chǎn)生大量的 segment,檢索性能會(huì)受到影響。所以,加大時(shí)長(zhǎng)可以降低系統(tǒng)開(kāi)銷(xiāo)。對(duì)于日志搜索來(lái)說(shuō),實(shí)時(shí)性要求不是那么高,設(shè)置為 5 秒或者 10s;對(duì)于 SkyWalking,實(shí)時(shí)性要求更低一些,我們可以設(shè)置為 30s。
設(shè)置如下:
"index.refresh_interval":"5s"
2.2.2.3 優(yōu)化 merge
index.merge.scheduler.max_thread_count 控制并發(fā)的 merge 線程數(shù),如果存儲(chǔ)是并發(fā)性能較好的 SSD,可以用系統(tǒng)默認(rèn)的 max(1, min(4, availableProcessors / 2)),當(dāng)節(jié)點(diǎn)配置的 cpu 核數(shù)較高時(shí),merge 占用的資源可能會(huì)偏高,影響集群的性能,普通磁盤(pán)的話設(shè)為1,發(fā)生磁盤(pán) IO 堵塞。設(shè)置max_thread_count 后,會(huì)有 max_thread_count + 2 個(gè)線程同時(shí)進(jìn)行磁盤(pán)操作,也就是設(shè)置為 1 允許3個(gè)線程。
設(shè)置如下:
"index.merge.scheduler.max_thread_count":"1"
2.2.2 優(yōu)化設(shè)置
2.2.2.1 對(duì)現(xiàn)有索引做索引設(shè)置
#?需要先?close?索引,然后再執(zhí)行,最后成功之后再打開(kāi)
#?關(guān)閉索引
curl?-XPOST?'http://localhost:9200/_all/_close'
#?修改索引設(shè)置
curl?-XPUT?-H?"Content-Type:application/json"?'http://localhost:9200/_all/_settings?preserve_existing=true'?-d?'{"index.merge.scheduler.max_thread_count"?:?"1","index.refresh_interval"?:?"10s","index.translog.durability"?:?"async","index.translog.flush_threshold_size":"1024mb","index.translog.sync_interval"?:?"120s"}'
#?打開(kāi)索引
curl?-XPOST?'http://localhost:9200/_all/_open'
該方式可對(duì)已經(jīng)生成的索引做修改,但是對(duì)于后續(xù)新建的索引不生效,所以我們可以制作 ES 模板,新建的索引按模板創(chuàng)建索引。
2.2.2.2 制作索引模板
#?制作模板?大部分索引都是業(yè)務(wù)應(yīng)用的日志相關(guān)的索引,且索引名稱(chēng)是?202*?這種帶著日期的格式
PUT?_template/business_log
{
??"index_patterns":?["*202*.*.*"],
??"settings":?{
??"index.merge.scheduler.max_thread_count"?:?"1","index.refresh_interval"?:?"5s","index.translog.durability"?:?"async","index.translog.flush_threshold_size":"1024mb","index.translog.sync_interval"?:?"120s"}
}
#?查詢(xún)模板是否創(chuàng)建成功
GET?_template/business_log
因?yàn)槲覀兊臉I(yè)務(wù)日志是按天維度創(chuàng)建索引,索引名稱(chēng)示例:user-service-prod-2020.12.12,所以用通配符*202..**匹配對(duì)應(yīng)要?jiǎng)?chuàng)建的業(yè)務(wù)日志索引。
2.2 優(yōu)化線程池配置
前文已經(jīng)提到過(guò),write 線程池滿負(fù)荷,導(dǎo)致拒絕任務(wù),而有的數(shù)據(jù)無(wú)法寫(xiě)入。
而經(jīng)過(guò)上面的優(yōu)化后,拒絕的情況少了很多,但是還是有拒絕任務(wù)的情況。
所以我們還需要優(yōu)化 write 線程池。
從 prometheus 監(jiān)控中可以看到線程池的情況:
為了更直觀看到 ES 線程池的運(yùn)行情況,我們安裝了 elasticsearch_exporter 收集 ES 的指標(biāo)數(shù)據(jù)到 prometheus,再通過(guò) grafana 進(jìn)行查看。
經(jīng)過(guò)上面的各種優(yōu)化,拒絕的數(shù)據(jù)量少了很多,但是還是存在拒絕的情況,如下圖:
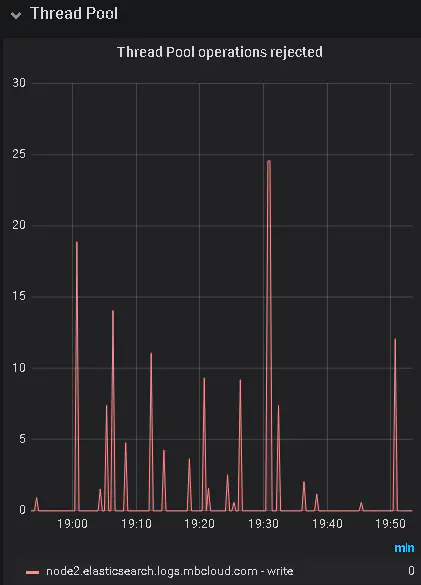
write 線程池如何設(shè)置:
參考文末鏈接:ElasticSearch線程池
writeFor single-document index/delete/update and bulk requests. Thread pool type is
fixedwith a size of# of available processors, queue_size of200. The maximum size for this pool is1 + # of available processors.
write 線程池采用 fixed 類(lèi)型的線程池,也就是核心線程數(shù)與最大線程數(shù)值相同。線程數(shù)默認(rèn)等于 cpu 核數(shù),可設(shè)置的最大值只能是 cpu 核數(shù)加 1,也就是 16 核 CPU,能設(shè)置的線程數(shù)最大值為 17。
優(yōu)化的方案:
線程數(shù)改為 17,也就是 cpu 總核數(shù)加 1 隊(duì)列容量加大。隊(duì)列在此時(shí)的作用是消峰。不過(guò)隊(duì)列容量加大本身不會(huì)提升處理速度,只是起到緩沖作用。此外,隊(duì)列容量也不能太大,否則積壓很多任務(wù)時(shí)會(huì)占用過(guò)多堆內(nèi)存。
config/elasticsearch.yml文件增加配置
#?線程數(shù)設(shè)置
thread_pool:
??write:
????#?線程數(shù)默認(rèn)等于cpu核數(shù),即16??
????size:?17
????#?因?yàn)槿蝿?wù)多時(shí)存在任務(wù)拒絕的情況,所以加大隊(duì)列大小,可以在間歇性任務(wù)量陡增的情況下,緩存任務(wù)在隊(duì)列,等高峰過(guò)去逐步消費(fèi)完。
????queue_size:?10000
優(yōu)化后效果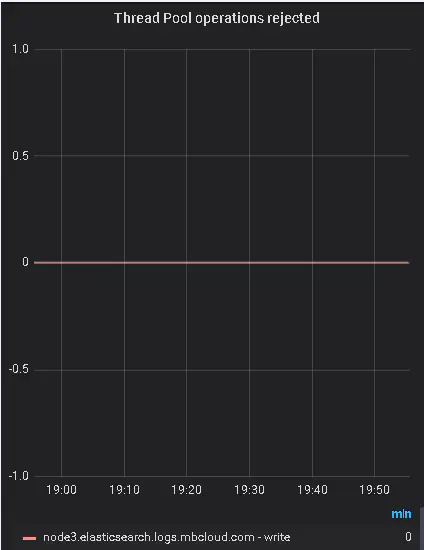 可以看到,已經(jīng)沒(méi)有拒絕的情況,這樣也就是解決了日志丟失的問(wèn)題。
可以看到,已經(jīng)沒(méi)有拒絕的情況,這樣也就是解決了日志丟失的問(wèn)題。
2.3 鎖定內(nèi)存,不讓 JVM 使用 Swap
Swap 交換分區(qū):
當(dāng)系統(tǒng)的物理內(nèi)存不夠用的時(shí)候,就需要將物理內(nèi)存中的一部分空間釋放出來(lái),以供當(dāng)前運(yùn)行的程序使用。那些被釋放的空間可能來(lái)自一些很長(zhǎng)時(shí)間沒(méi)有什么操作的程序,**這些被釋放的空間被臨時(shí)保存到 Swap 中,等到那些程序要運(yùn)行時(shí),再?gòu)?Swap 中恢復(fù)保存的數(shù)據(jù)到內(nèi)存中。**這樣,系統(tǒng)總是在物理內(nèi)存不夠時(shí),才進(jìn)行 Swap 交換。
參考文末鏈接:ElasticSearch官方解釋為什么要禁用交換內(nèi)存
Swap 交換分區(qū)對(duì)性能和節(jié)點(diǎn)穩(wěn)定性非常不利,一定要禁用。它會(huì)導(dǎo)致垃圾回收持續(xù)幾分鐘而不是幾毫秒,并會(huì)導(dǎo)致節(jié)點(diǎn)響應(yīng)緩慢,甚至與集群斷開(kāi)連接。
有三種方式可以實(shí)現(xiàn) ES 不使用 Swap 分區(qū)
2.3.1 Linux 系統(tǒng)中的關(guān)閉 Swap (臨時(shí)有效)
執(zhí)行命令
sudo?swapoff?-a
可以臨時(shí)禁用 Swap 內(nèi)存,但是操作系統(tǒng)重啟后失效
2.3.2 Linux 系統(tǒng)中的盡可能減少 Swap 的使用(永久有效)
執(zhí)行下列命令
echo?"vm.swappiness?=?1">>?/etc/sysctl.conf
正常情況下不會(huì)使用 Swap,除非緊急情況下才會(huì) Swap。
2.3.3 啟用 bootstrap.memory_lock
config/elasticsearch.yml 文件增加配置
#鎖定內(nèi)存,不讓?JVM?寫(xiě)入?Swap,避免降低?ES?的性能
bootstrap.memory_lock:?true
2.4 減少分片數(shù)、副本數(shù)
分片
索引的大小取決于分片與段的大小,分片過(guò)小,可能導(dǎo)致段過(guò)小,進(jìn)而導(dǎo)致開(kāi)銷(xiāo)增加;分片過(guò)大可能導(dǎo)致分片頻繁 Merge,產(chǎn)生大量 IO 操作,影響寫(xiě)入性能。
因?yàn)槲覀兠總€(gè)索引的大小在 15G 以下,而默認(rèn)是 5 個(gè)分片,沒(méi)有必要這么多,所以調(diào)整為 3 個(gè)。
"index.number_of_shards":?"3"
分片的設(shè)置我們也可以配置在索引模板。
副本數(shù)
減少集群副本分片數(shù),過(guò)多副本會(huì)導(dǎo)致 ES 內(nèi)部寫(xiě)擴(kuò)大。副本數(shù)默認(rèn)為 1,如果某索引所在的 1 個(gè)節(jié)點(diǎn)宕機(jī),擁有副本的另一臺(tái)機(jī)器擁有索引備份數(shù)據(jù),可以讓索引數(shù)據(jù)正常使用。但是數(shù)據(jù)寫(xiě)入副本會(huì)影響寫(xiě)入性能。對(duì)于日志數(shù)據(jù),有 1 個(gè)副本即可。對(duì)于大數(shù)據(jù)量的索引,可以設(shè)置副本數(shù)為0,減少對(duì)性能的影響。
"index.number_of_replicas":?"1"
分片的設(shè)置我們也可以配置在索引模板。
3.控制數(shù)據(jù)來(lái)源
3.1 應(yīng)用按規(guī)范打印日志
有的應(yīng)用 1 天生成 10G 日志,而一般的應(yīng)用只有幾百到 1G。一天生成 10G 日志一般是因?yàn)椴糠謶?yīng)用日志使用不當(dāng),很多大數(shù)量的日志可以不打,比如大數(shù)據(jù)量的列表查詢(xún)接口、報(bào)表數(shù)據(jù)、debug 級(jí)別日志等數(shù)據(jù)是不用上傳到日志服務(wù)器,這些即影響日志存儲(chǔ)的性能,更影響應(yīng)用自身性能。
四、ES性能優(yōu)化后的效果
優(yōu)化后的兩周內(nèi) ELK 性能良好,沒(méi)有使用上的問(wèn)題:
ES 數(shù)據(jù)不再丟失
數(shù)據(jù)延時(shí)在 10 秒之內(nèi),一般在 5 秒可以查出
每個(gè) ES 節(jié)點(diǎn)負(fù)載比較穩(wěn)定,CPU 和內(nèi)存使用率都不會(huì)過(guò)高,如下圖

ES 節(jié)點(diǎn)運(yùn)行情況.png
五、參考文檔
參考
記一次 ElasticSearch 優(yōu)化總結(jié): https://juejin.cn/post/6844903689480568840 ElasticSearch 的數(shù)據(jù)寫(xiě)入流程及優(yōu)化: https://www.cnblogs.com/zhangan/p/11231990.html 百億級(jí)實(shí)時(shí)計(jì)算系統(tǒng)性能優(yōu)化–—ElasticSearch篇 : https://www.cnblogs.com/qcloud1001/p/14068642.html CMS GC 默認(rèn)新生代是多大?: https://www.jianshu.com/p/832fc4d4cb53 官方堆內(nèi)存設(shè)置的建議: https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html#heap-size-settings ElasticSearch線程池: https://www.elastic.co/guide/en/elasticsearch/reference/6.3/modules-threadpool.html#modules-threadpool ElasticSearch官方解釋為什么要禁用交換內(nèi)存: https://www.elastic.co/guide/en/elasticsearch/reference/6.3/setup-configuration-memory.html 段 merge: https://www.elastic.co/guide/en/elasticsearch/reference/6.3/index-modules-merge.html https://stackoverflow.com/questions/15426441/understanding-segments-in-elasticsearch