
java中那些讓你傻傻分不清楚的小細(xì)節(jié)
擴(kuò)展右上角“設(shè)為星標(biāo)”能第一時(shí)間看到好文章
大家好,我是蘇三,又和大家見面了。
祝大家新年快樂,身體健康,財(cái)源滾滾,萬事如意。
最近有篇文章在開源中國上火了,讓我挺驚喜的。
我以前在上面發(fā)表文章,一般只有幾個(gè)閱讀量,稍微好點(diǎn)的有幾十,如果被推薦也只有幾百。像這種有3.2W閱讀的情況,還是頭一次遇到,真的活久見。非常感謝源碼中國平臺(tái),讓我的文章可以被更多的人看見。
前言
最近我們通過sonar靜態(tài)代碼檢測,同時(shí)配合人工代碼review,發(fā)現(xiàn)了項(xiàng)目中很多代碼問題。除了常規(guī)的bug和安全漏洞之外,還有幾處方法用法錯(cuò)誤,引起了我極大的興趣。我為什么會(huì)對這幾個(gè)方法這么感興趣呢?因?yàn)樗鼈儤O具迷惑性,可能會(huì)讓我們傻傻分不清楚。
1. replace會(huì)替換所有字符?
很多時(shí)候我們在使用字符串時(shí),想把字符串比如:ATYSDFA*Y中的字符A替換成字符B,第一個(gè)想到的可能是使用replace方法。
如果想把所有的A都替換成B,很顯然可以用replaceAll方法,因?yàn)榉浅V庇^,光從方法名就能猜出它的用途。
那么問題來了:replace方法會(huì)替換所有匹配字符嗎?
jdk的官方給出了答案。
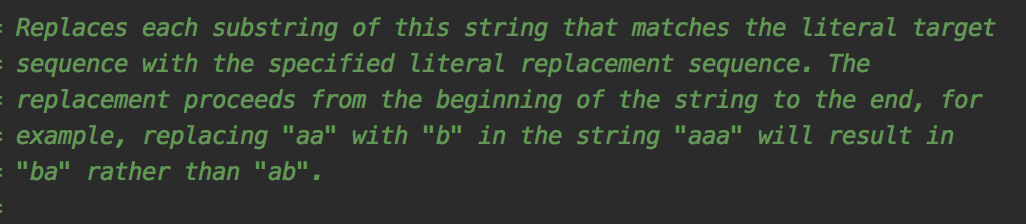
該方法會(huì)替換每一個(gè)匹配的字符串。
既然replace和replaceAll都能替換所有匹配字符,那么他們有啥區(qū)別呢?
replace有兩個(gè)重載的方法。
其中一個(gè)方法的參數(shù):char oldChar 和 char newChar,支持字符的替換。
source.replace('A', 'B')
另一個(gè)方法的參數(shù)是:CharSequence target 和 CharSequence replacement,支持字符串的替換。
source.replace("A", "B")
replaceAll方法的參數(shù)是:String regex 和 String replacement,基于正則表達(dá)式的替換。普通字符串替換:
source.replaceAll("A", "B")
正則表達(dá)替換(將*替換成C):
source.replaceAll("\\*", "C")
順便說一下,將*替換成C使用replace方法也可以實(shí)現(xiàn):
source.replace("*", "C")
無需對特殊字符進(jìn)行轉(zhuǎn)義。
不過,千萬注意,切勿使用如下寫法:
source.replace("\\*", "C")
這種寫法會(huì)導(dǎo)致字符串無法替換。
還有個(gè)小問題,如果我只想替換第一個(gè)匹配的字符串該怎么辦?
這時(shí)可以使用replaceFirst方法:
source.replaceFirst("A", "B")
2. Integer不能用==判斷相等?
不知道你在項(xiàng)目中有沒有見過,有些同事對Integer類型的兩個(gè)參數(shù)使用==比較是否相等?
反正我見過的,那么這種用法對嗎?
我的回答是看具體場景,不能說一定對,或不對。
有些狀態(tài)字段,比如:orderStatus有:-1(未下單),0(已下單),1(已支付),2(已完成),3(取消),5種狀態(tài)。
這時(shí)如果用==判斷是否相等:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1 == orderStatus2);
返回結(jié)果會(huì)是true嗎?
答案:是false。
有些同學(xué)可能會(huì)反駁,Integer中不是有范圍是:-128-127的緩存嗎?
為什么是false?
先看看Integer的構(gòu)造方法: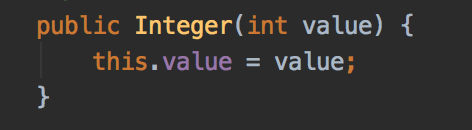 它其實(shí)并沒有用到緩存。
它其實(shí)并沒有用到緩存。
那么緩存是在哪里用的?
答案在valueOf方法中: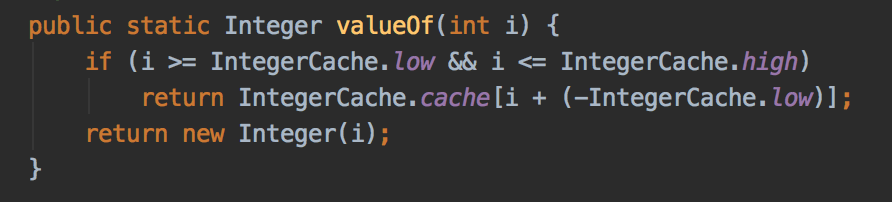
如果上面的判斷改成這樣:
String orderStatus1 = new String("1");
String orderStatus2 = new String("1");
System.out.println(Integer.valueOf(orderStatus1) == Integer.valueOf(orderStatus2));
返回結(jié)果會(huì)是true嗎?
答案:還真是true。
我們要養(yǎng)成良好編碼習(xí)慣,盡量少用==判斷兩個(gè)Integer類型數(shù)據(jù)是否相等,只有在上述非常特殊的場景下才相等。
而應(yīng)該改成使用equals方法判斷:
Integer orderStatus1 = new Integer(1);
Integer orderStatus2 = new Integer(1);
System.out.println(orderStatus1.equals(orderStatus2));
3. 使用BigDecimal就不丟失精度?
通常我們會(huì)把一些小數(shù)類型的字段(比如:金額),定義成BigDecimal,而不是Double,避免丟失精度問題。
使用Double時(shí)可能會(huì)有這種場景:
double amount1 = 0.02;
double amount2 = 0.03;
System.out.println(amount2 - amount1);
正常情況下預(yù)計(jì)amount2 - amount1應(yīng)該等于0.01
但是執(zhí)行結(jié)果,卻為:
0.009999999999999998
實(shí)際結(jié)果小于預(yù)計(jì)結(jié)果。
Double類型的兩個(gè)參數(shù)相減會(huì)轉(zhuǎn)換成二進(jìn)制,因?yàn)镈ouble有效位數(shù)為16位這就會(huì)出現(xiàn)存儲(chǔ)小數(shù)位數(shù)不夠的情況,這種情況下就會(huì)出現(xiàn)誤差。
常識(shí)告訴我們使用BigDecimal能避免丟失精度。
但是使用BigDecimal能避免丟失精度嗎?
答案是否定的。
為什么?
BigDecimal amount1 = new BigDecimal(0.02);
BigDecimal amount2 = new BigDecimal(0.03);
System.out.println(amount2.subtract(amount1));
這個(gè)例子中定義了兩個(gè)BigDecimal類型參數(shù),使用構(gòu)造函數(shù)初始化數(shù)據(jù),然后打印兩個(gè)參數(shù)相減后的值。
結(jié)果:
0.0099999999999999984734433411404097569175064563751220703125
不科學(xué)呀,為啥還是丟失精度了?
jdk中BigDecimal的構(gòu)造方法上有這樣一段描述:
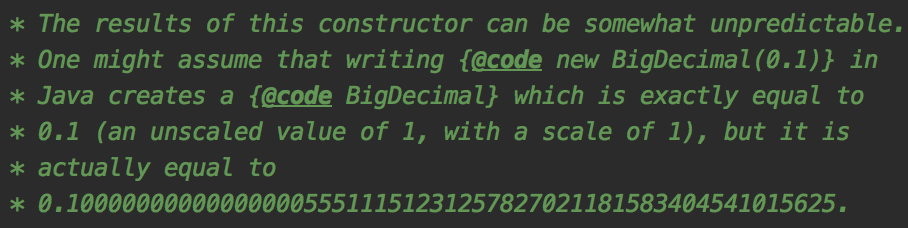
大致的意思是此構(gòu)造函數(shù)的結(jié)果可能不可預(yù)測,可能會(huì)出現(xiàn)創(chuàng)建時(shí)為0.1,但實(shí)際是0.1000000000000000055511151231257827021181583404541015625的情況。
由此可見,使用BigDecimal構(gòu)造函數(shù)初始化對象,也會(huì)丟失精度。
那么,如何才能不丟失精度呢?
BigDecimal amount1 = new BigDecimal(Double.toString(0.02));
BigDecimal amount2 = new BigDecimal(Double.toString(0.03));
System.out.println(amount2.subtract(amount1));
使用Double.toString方法對double類型的小數(shù)進(jìn)行轉(zhuǎn)換,這樣能保證精度不丟失。
其實(shí),還有更好的辦法:
BigDecimal amount1 = BigDecimal.valueOf(0.02);
BigDecimal amount2 = BigDecimal.valueOf(0.03);
System.out.println(amount2.subtract(amount1));
使用BigDecimal.valueOf方法初始化BigDecimal類型參數(shù),也能保證精度不丟失。在新版的阿里巴巴開發(fā)手冊中,也推薦使用這種方式創(chuàng)建BigDecimal參數(shù)。
4. 字符串拼接不能用String?
String類型的字符串被稱為不可變序列,也就是說該對象的數(shù)據(jù)被定義好后就不能修改了,如果要修改則需要?jiǎng)?chuàng)建新對象。
String a = "123";
String b = "456";
String c = a + b;
System.out.println(c);
在大量字符串拼接的場景中,如果對象被定義成String類型,會(huì)產(chǎn)生很多無用的中間對象,浪費(fèi)內(nèi)存空間,效率低。
這時(shí),我們可以用更高效的可變字符序列:StringBuilder和StringBuffer,來定義對象。
那么,StringBuilder和StringBuffer有啥區(qū)別?
StringBuffer對各主要方法加了synchronized關(guān)鍵字,而StringBuilder沒有。所以,StringBuffer是線程安全的,而StringBuilder不是。
其實(shí),我們很少會(huì)出現(xiàn)需要在多線程下拼接字符串的場景,所以StringBuffer實(shí)際上用得非常少。一般情況下,拼接字符串時(shí)我們推薦使用StringBuilder,通過它的append方法追加字符串,它只會(huì)產(chǎn)生一個(gè)對象,而且沒有加鎖,效率較高。
String a = "123";
String b = "456";
StringBuilder c = new StringBuilder();
c.append(a).append(b);
System.out.println(c);
接下來,關(guān)鍵問題來了:字符串拼接時(shí)使用String類型的對象,效率一定比StringBuilder類型的對象低?
答案是否定的。
為什么?
使用javap -c StringTest命令反編譯:
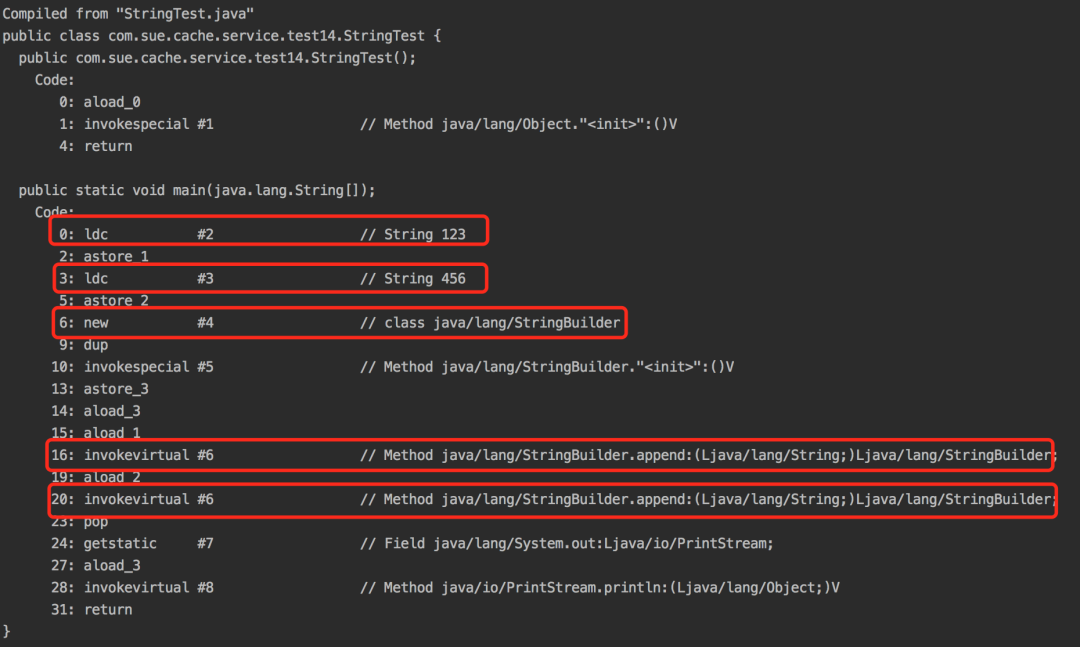
從圖中能看出定義了兩個(gè)String類型的參數(shù),又定義了一個(gè)StringBuilder類的參數(shù),然后兩次使用append方法追加字符串。
如果代碼是這樣的:
String a = "123";
String b = "789";
String c = a + b;
System.out.println(c);
使用javap -c StringTest命令反編譯的結(jié)果會(huì)怎樣呢?
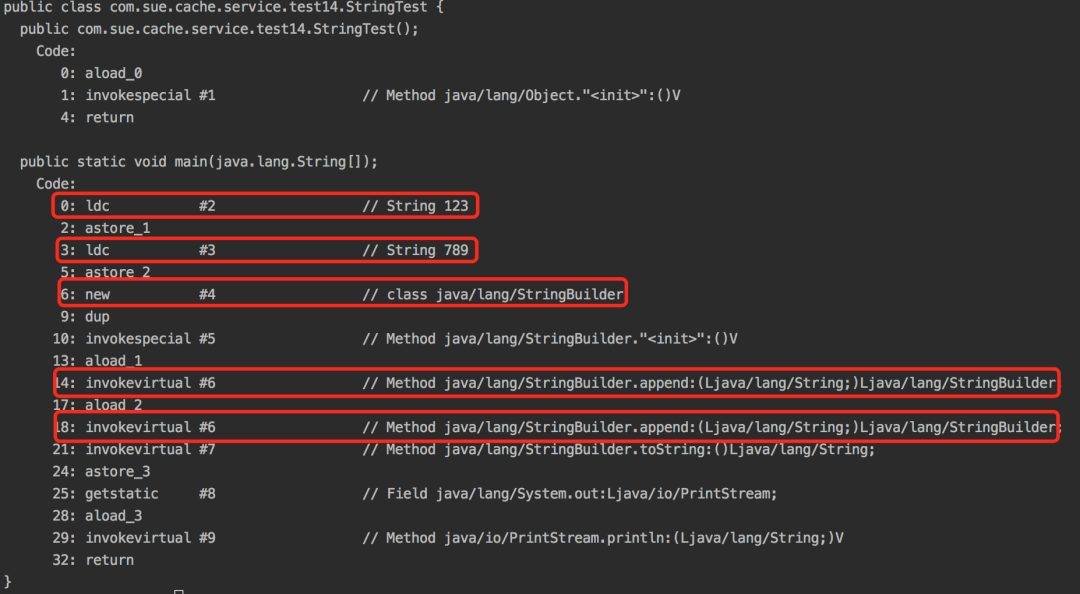
我們會(huì)驚訝的發(fā)現(xiàn),同樣定義了兩個(gè)String類型的參數(shù),又定義了一個(gè)StringBuilder類的參數(shù),然后兩次使用append方法追加字符串。跟上面的結(jié)果是一樣的。
其實(shí)從jdk5開始,java就對String類型的字符串的+操作做了優(yōu)化,該操作編譯成字節(jié)碼文件后會(huì)被優(yōu)化為StringBuilder的append操作。
5. isEmpty和isBlank的區(qū)別
我們在對字符串進(jìn)行操作的時(shí)候,需要經(jīng)常判斷該字符串是否為空。如果沒有借助任何工具,我們一般是這樣判斷的:
if (null != source && !"".equals(source)) {
System.out.println("not empty");
}
但是如果每次都這樣判斷,會(huì)有些麻煩,所以很多jar包都對字符串判空做了封裝。目前市面上主流的工具有:
spring中的StringUtils jdbc中的StringUtils apache common3中的StringUtils
不過spring中的StringUtils類只有isEmpty方法,沒有isNotEmpty方法。
jdbc中的StringUtils類只有isNullOrEmpty方法,也沒有isNotNullOrEmpty方法。
所以在這里強(qiáng)烈推薦一下apache common3中的StringUtils類,它里面包含了很多實(shí)用的判空方法:isEmpty、isBlank、isNotEmpty、isNotBlank等,還有其他字符串處理方法。
問題來了,isEmpty和isBlank有啥區(qū)別?
使用isEmpty方法判斷:
StringUtils.isNotEmpty(null) = true
StringUtils.isNotEmpty("") = true
StringUtils.isNotEmpty(" ") = false
StringUtils.isNotEmpty("bob") = false
StringUtils.isNotEmpty(" bob ") = false
使用isBlank方法判斷:
StringUtils.isBlank(null) = true
StringUtils.isBlank("") = true
StringUtils.isBlank(" ") = true
StringUtils.isBlank("bob") = false
StringUtils.isBlank(" bob ") = false
兩個(gè)方法關(guān)鍵的區(qū)別在于這種" "空字符串的情況,isNotEmpty返回false,而isBlank返回true。
6. mapper查詢結(jié)果要判空?
有次代碼review的時(shí)候,當(dāng)時(shí)有個(gè)同事說這里的判空可以去掉,讓我記憶猶新:
List list = userMapper.query(search);
if(CollectionUtils.isNotEmpty(list)) {
List idList = list.stream().map(User::getId).collect(Collectors.toList());
}
因?yàn)榘闯@恚话阏{(diào)用方法查詢出來的集合,可能為null,需要判空的。但是,這里比較特殊,我查了一下mybatis的源碼,這個(gè)判空的代碼還真的可以去掉。
怎么回事呢?
mybatis的查詢方法最終都會(huì)調(diào)到DefaultResultSetHandler類的handleResultSets方法: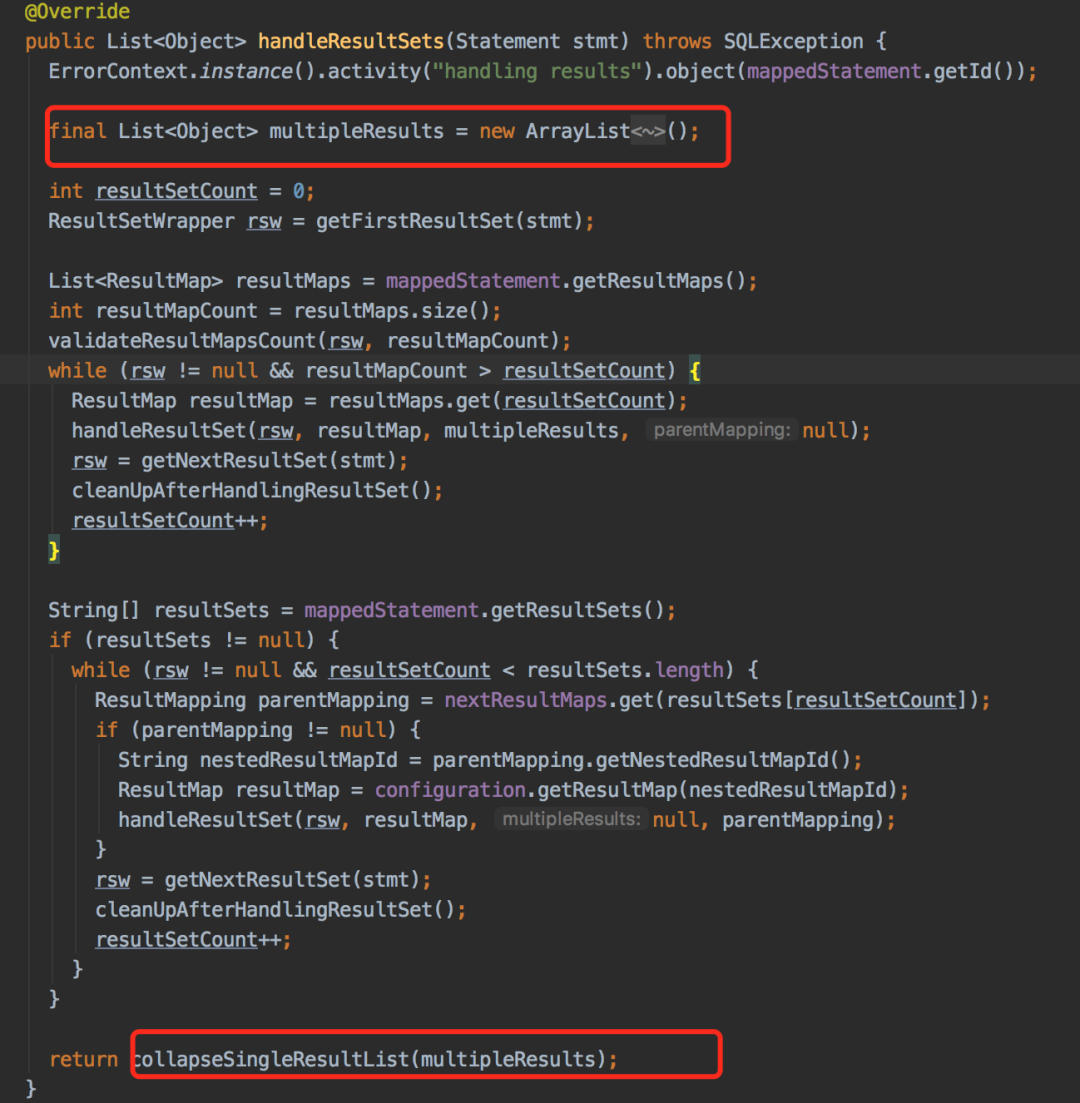
 該方法會(huì)返回一個(gè)
該方法會(huì)返回一個(gè)multipleResultsList集合對象,在方法剛開始就new出來了,肯定是不會(huì)為空。
所以,如果你在項(xiàng)目的代碼中看到有人直接使用查詢出的結(jié)果,不判空也不要驚訝:
List list = userMapper.query(search);
List idList = list.stream().map(User::getId).collect(Collectors.toList());
因?yàn)?code style="font-size: 14px;word-wrap: break-word;padding: 2px 4px;border-radius: 4px;margin: 0 2px;background-color: rgba(27,31,35,.05);font-family: Operator Mono, Consolas, Monaco, Menlo, monospace;word-break: break-all;color: #28ca71;">mapper底層已經(jīng)處理過的,它不會(huì)出現(xiàn)空指針異常。
7. indexOf方法的正確用法
有次在review別人代碼的時(shí)候,看到有個(gè)地方indexOf使用了這種寫法,讓我印象比較深刻:
String source = "#ATYSDFA*Y";
if(source.indexOf("#") > 0) {
System.out.println("do something");
}
你們說這段代碼會(huì)打印出do something嗎?
答案是否定的。
為什么呢?
jdk官方說了不存在的情況會(huì)返回-1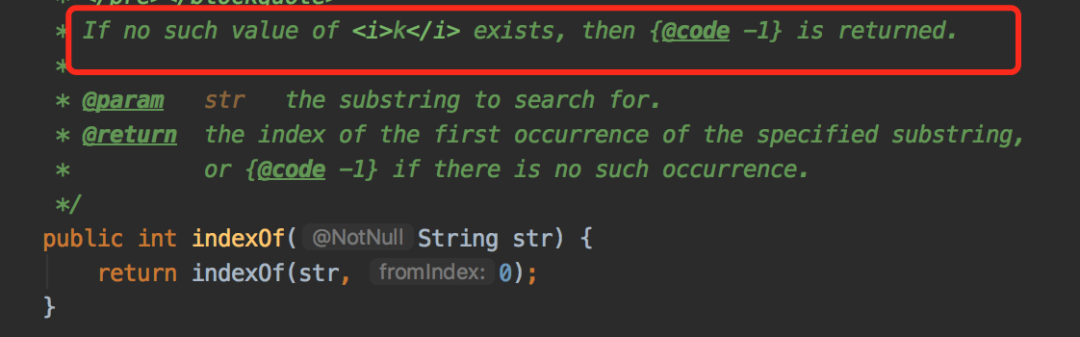
indexOf方法返回的是指定元素在字符串中的位置,從0開始。而上面的例子#在字符串的第一個(gè)位置,所以調(diào)用indexOf方法后的值其實(shí)是0。所以,條件是false,不會(huì)打印do something。
如果想通過indexOf判斷某個(gè)元素是否存在時(shí),要用:
if(source.indexOf("#") > -1) {
System.out.println("do something");
}
其實(shí),還有更優(yōu)雅的contains方法:
if(source.contains("#")) {
System.out.println("do something");
}
最后說一句(求關(guān)注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發(fā)的話,幫忙掃描下發(fā)二維碼關(guān)注一下,您的支持是我堅(jiān)持寫作最大的動(dòng)力。
求一鍵三連:點(diǎn)贊、轉(zhuǎn)發(fā)、在看。
關(guān)注公眾號(hào):【蘇三說技術(shù)】,在公眾號(hào)中回復(fù):面試、代碼神器、開發(fā)手冊、時(shí)間管理有超贊的粉絲福利,另外回復(fù):加群,可以跟很多BAT大廠的前輩交流和學(xué)習(xí)。
?個(gè)人公眾號(hào)
?個(gè)人微信