
數(shù)據(jù)庫SQL語句中 where,group by,having,order by的執(zhí)行順序

一、SQL查詢
1.查詢中用到的關(guān)鍵詞主要包含六個(gè),并且他們的順序依次為:select>from>where>group by>having>order by
其中select和from是必須的,其他關(guān)鍵詞是可選的,這六個(gè)關(guān)鍵詞的執(zhí)行順序與sql語句的書寫順序并不是一樣的,而是按照下面的順序來執(zhí)行:from>where>group by>having>select>order by
from:需要從哪個(gè)數(shù)據(jù)表檢索數(shù)據(jù)
where:過濾表中數(shù)據(jù)的條件?
group by:如何將上面過濾出的數(shù)據(jù)分組?
having:對(duì)上面已經(jīng)分組的數(shù)據(jù)進(jìn)行過濾的條件
select:查看結(jié)果集中的哪個(gè)列,或列的計(jì)算結(jié)果 order by:按照什么樣的順序來查看返回的數(shù)據(jù)
2.from后面的表關(guān)聯(lián),是自右向左解析的;而where條件的解析順序是自下而上的。
也就是說,在寫SQL語句的時(shí)候,盡量把數(shù)據(jù)量小的表放在最右邊來進(jìn)行關(guān)聯(lián)(用小表去匹配大表),而把能篩選出小量數(shù)據(jù)的條件放在where語句的最左邊 (用小表去匹配大表)。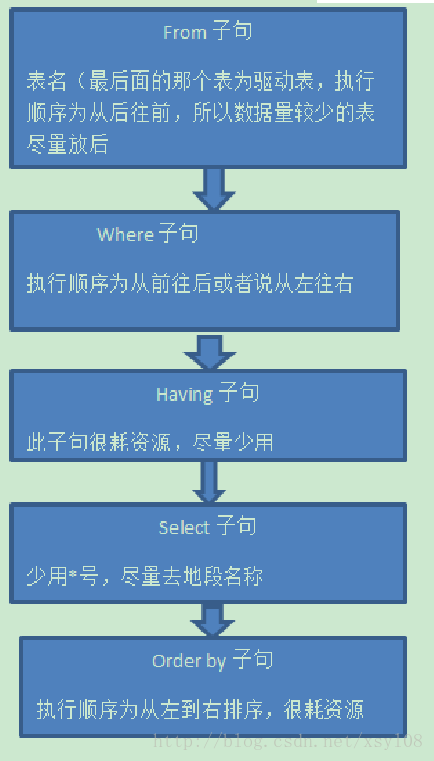
使用count(列名)當(dāng)某列出現(xiàn)null值的時(shí)候,count(*)仍然會(huì)計(jì)算,但是count(列名)不會(huì)。
二、數(shù)據(jù)分組(group by):
select 列a,聚合函數(shù)(聚合函數(shù)規(guī)范) from 表名 where 過濾條件 group by 列a
group by子句也和where條件語句結(jié)合在一起使用。當(dāng)結(jié)合在一起時(shí),where在前,group by 在后。即先對(duì)select xx from xx的記錄集合用where進(jìn)行篩選,然后再使用group by對(duì)篩選后的結(jié)果進(jìn)行分組。
三、使用having字句對(duì)分組后的結(jié)果進(jìn)行篩選,語法和where差不多:having 條件表達(dá)式
需要注意having和where的用法區(qū)別:
1.having只能用在group by之后,對(duì)分組后的結(jié)果進(jìn)行篩選(即使用having的前提條件是分組)。
2.where肯定在group by 之前,即也在having之前。
3.where后的條件表達(dá)式里不允許使用聚合函數(shù),而having可以。
四、當(dāng)一個(gè)查詢語句同時(shí)出現(xiàn)了where,group by,having,order by的時(shí)候,執(zhí)行順序和編寫順序是:
1.執(zhí)行where xx對(duì)全表數(shù)據(jù)做篩選,返回第1個(gè)結(jié)果集。
2.針對(duì)第1個(gè)結(jié)果集使用group by分組,返回第2個(gè)結(jié)果集。
3.針對(duì)第2個(gè)結(jié)集執(zhí)行having xx進(jìn)行篩選,返回第3個(gè)結(jié)果集。
4.針對(duì)第3個(gè)結(jié)果集中的每1組數(shù)據(jù)執(zhí)行select xx,有幾組就執(zhí)行幾次,返回第4個(gè)結(jié)果集。
5.針對(duì)第4個(gè)結(jié)果集排序。
例子:
完成一個(gè)復(fù)雜的查詢語句,需求如下:
按由高到低的順序顯示個(gè)人平均分在70分以上的學(xué)生姓名和平均分,為了盡可能地提高平均分,在計(jì)算平均分前不包括分?jǐn)?shù)在60分以下的成績,并且也不計(jì)算賤人(jr)的成績。分析:
1.要求顯示學(xué)生姓名和平均分
因此確定第1步select s_name,avg(score) from student
2.計(jì)算平均分前不包括分?jǐn)?shù)在60分以下的成績,并且也不計(jì)算賤人(jr)的成績
因此確定第2步 where score>=60 and s_name!=’jr’
3.顯示個(gè)人平均分
相同名字的學(xué)生(同一個(gè)學(xué)生)考了多門科目 因此按姓名分組 確定第3步 group by s_name 4.顯示個(gè)人平均分在70分以上
因此確定第4步 having avg(s_score)>=70 5.按由高到低的順序
因此確定第5步 order by avg(s_score) desc
五、索引
1.索引是單獨(dú)的數(shù)據(jù)庫對(duì)象,索引也需要被維護(hù)。
2.索引可以提高查詢速度,但會(huì)降增刪改的速度。
3.通過一定的查詢觸發(fā),并不是越多越好。什么時(shí)候不適合用索引?1).當(dāng)增刪改的操作大于查詢的操作時(shí)。2).查詢的語句大于所有語句的三分之一時(shí)。
創(chuàng)建索引語法:create index 索引名 on 表名 (列名) 刪除索引語法:drop index 索引名
更多信息請(qǐng)關(guān)注公眾號(hào):「軟件老王」,關(guān)注不迷路,軟件老王和他的IT朋友們,分享一些他們的技術(shù)見解和生活故事。