
聊聊 Elasticsearch 的倒排索引
本文公眾號來源:柳樹的絮叨叨作者:靠發(fā)型吃飯的柳樹本文已收錄至我的GitHub為什么需要倒排索引 ?
倒排索引,也是索引。
索引,初衷都是為了快速檢索到你要的數(shù)據(jù)。?
每種數(shù)據(jù)庫都有自己要解決的問題(或者說擅長的領(lǐng)域),對應(yīng)的就有自己的數(shù)據(jù)結(jié)構(gòu),而不同的使用場景和數(shù)據(jù)結(jié)構(gòu),需要用不同的索引,才能起到最大化加快查詢的目的。 ?
對 Mysql 來說,是 B+ 樹,對 Elasticsearch/Lucene 來說,是倒排索引。?
為什么叫倒排索引 ?Elasticsearch 是建立在全文搜索引擎庫 Lucene 基礎(chǔ)上的搜索引擎,它隱藏了 Lucene 的復(fù)雜性,取而代之的提供一套簡單一致的 RESTful API,不過掩蓋不了它底層也是 Lucene 的事實。
Elasticsearch 的倒排索引,其實就是 Lucene 的倒排索引。
在沒有搜索引擎時,我們是直接輸入一個網(wǎng)址,然后獲取網(wǎng)站內(nèi)容,這時我們的行為是:?
document -> to -> words ?
通過文章,獲取里面的單詞,此謂「正向索引」,forward index. ?
后來,我們希望能夠輸入一個單詞,找到含有這個單詞,或者和這個單詞有關(guān)系的文章:
word -> to -> documents
于是我們把這種索引,成為inverted index,直譯過來,應(yīng)該叫「反向索引」,國內(nèi)翻譯成「倒排索引」,有點委婉了。
現(xiàn)在思考一下,如果讓你來設(shè)計這個可以通過單詞,反向找到文章的索引,你會怎么實現(xiàn)??
倒排索引的內(nèi)部結(jié)構(gòu)關(guān)于 Elasticsearch 這類「搜索引擎」要解決的問題、它和傳統(tǒng)關(guān)系型數(shù)據(jù)庫的區(qū)別等等,可以看我之前寫的文章:為什么需要 Elasticsearch(文末有鏈接)
首先,在數(shù)據(jù)生成的時候,比如爬蟲爬到一篇文章,這時我們需要對這篇文章進(jìn)行分析,將文本拆解成一個個單詞。
這個過程很復(fù)雜,比如“生存還是死亡”,你要如何讓分詞器自動將它分解為“生存”、“還是”、“死亡”三個詞語,然后把“還是”這個無意義的詞語干掉。這里不展開,感興趣的同學(xué)可以查看文末關(guān)于「分析器」的鏈接。
接著,把這兩個詞語以及它對應(yīng)的文檔id存下來:?
word documentId ?
生存 ?1
死亡 ?1
接著爬蟲繼續(xù)爬,又爬到一個含有“生存”的文檔,于是索引變成:
word documentId ?
生存 ?1,2
死亡 ?1
下次搜索“生存”,就會返回文檔ID是 1、2兩份文檔。
然而上面這套索引的實現(xiàn),給小孩子當(dāng)玩具玩還行,要上生產(chǎn)環(huán)境,那還遠(yuǎn)著。
想想看,這個世界上那么多單詞,中文、英文、日文、韓文 … 你每次搜索一個單詞,我都要全局遍歷一遍,很明顯不行。?
于是有了排序,我們需要對單詞進(jìn)行排序,像 B+ 樹一樣,可以在頁里實現(xiàn)二分查找。
光排序還不行,你單詞都放在磁盤呢,磁盤 IO 慢的不得了,所以 Mysql 特意把索引緩存到了內(nèi)存。
你說好,我也學(xué) Mysql 的,放內(nèi)存,3,2,1,放,哐當(dāng),內(nèi)存爆了。
哪本字典,會把所有單詞都貼在目錄里的?
所以,上圖:?
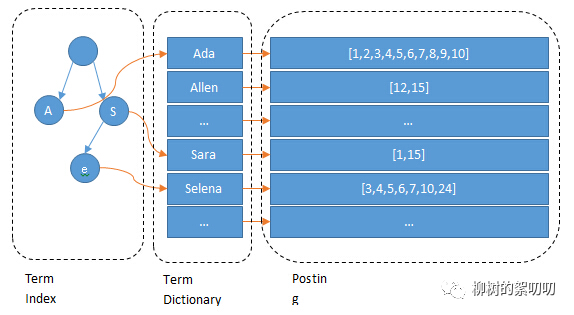
Lucene 的倒排索,增加了最左邊的一層「字典樹」term index,它不存儲所有的單詞,只存儲單詞前綴,通過字典樹找到單詞所在的塊,也就是單詞的大概位置,再在塊里二分查找,找到對應(yīng)的單詞,再找到單詞對應(yīng)的文檔列表。
當(dāng)然,內(nèi)存寸土寸金,能省則省,所以 Lucene 還用了 FST(Finite State Transducers)對它進(jìn)一步壓縮。
FST 是什么?這里就不展開了,這次重點想聊的,是最右邊的 Posting List 的,別看它只是存一個文檔 ID 數(shù)組,但是它在設(shè)計時,遇到的問題可不少。
Frame Of Reference原生的 Posting List 有兩個痛點:
如何壓縮以節(jié)省磁盤空間
如何快速求交并集(intersections and unions)
先來聊聊壓縮。
我們來簡化下 Lucene 要面對的問題,假設(shè)有這樣一個數(shù)組:
[73, 300, 302, 332, 343, 372] ?
如何把它進(jìn)行盡可能的壓縮?
Lucene 里,數(shù)據(jù)是按 Segment 存儲的,每個 Segment 最多存 65536 個文檔 ID, 所以文檔 ID 的范圍,從 0 到 2^32-1,所以如果不進(jìn)行任何處理,那么每個元素都會占用 2 bytes ,對應(yīng)上面的數(shù)組,就是 6 * 2 = 12 bytes. ?
怎么壓縮呢?
壓縮,就是盡可能降低每個數(shù)據(jù)占用的空間,同時又能讓信息不失真,能夠還原回來。
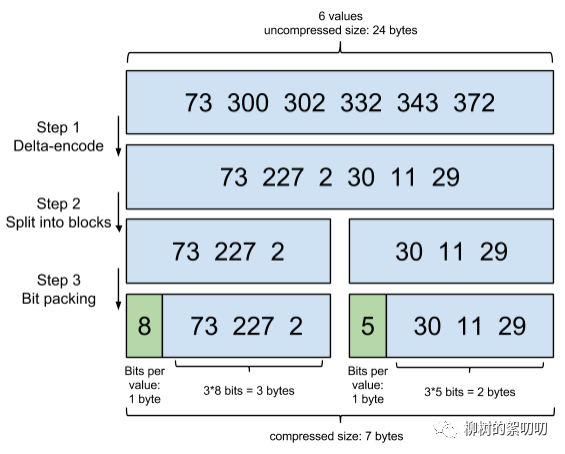
Step 1:Delta-encode —— 增量編碼
我們只記錄元素與元素之間的增量,于是數(shù)組變成了:
[73, 227, 2, 30, 11, 29]
Step 2:Split into blocks —— 分割成塊
Lucene里每個塊是 256 個文檔 ID,這樣可以保證每個塊,增量編碼后,每個元素都不會超過 256(1 byte).
為了方便演示,我們假設(shè)每個塊是 3 個文檔 ID:
[73, 227, 2], [30, 11, 29]
Step 3:Bit packing —— 按需分配空間
對于第一個塊,[73, 227, 2],最大元素是227,需要 8 bits,好,那我給你這個塊的每個元素,都分配 8 bits的空間。
但是對于第二個塊,[30, 11, 29],最大的元素才30,只需要 5 bits,那我就給你每個元素,只分配 5 bits 的空間,足矣。
這一步,可以說是把吝嗇發(fā)揮到極致,精打細(xì)算,按需分配。
以上三個步驟,共同組成了一項編碼技術(shù),F(xiàn)rame Of Reference(FOR):
接著來聊聊 Posting List 的第二個痛點 —— 如何快速求交并集(intersections and unions)。
在 Lucene 中查詢,通常不只有一個查詢條件,比如我們想搜索:
含有“生存”相關(guān)詞語的文檔
文檔發(fā)布時間在最近一個月
文檔發(fā)布者是平臺的特約作者
這樣就需要根據(jù)三個字段,去三棵倒排索引里去查,當(dāng)然,磁盤里的數(shù)據(jù),上一節(jié)提到過,用了 FOR 進(jìn)行壓縮,所以我們要把數(shù)據(jù)進(jìn)行反向處理,即解壓,才能還原成原始的文檔 ID,然后把這三個文檔 ID 數(shù)組在內(nèi)存中做一個交集。
即使沒有多條件查詢, Lucene 也需要頻繁求并集,因為 Lucene 是分片存儲的。
同樣,我們把 Lucene 遇到的問題,簡化成一道算法題。
假設(shè)有下面三個數(shù)組:
[64, 300, 303, 343] ?
[73, 300, 302, 303, 343, 372] ?
[303, 311, 333, 343] ?
求它們的交集。
Option 1: Integer 數(shù)組
直接用原始的文檔 ID ,可能你會說,那就逐個數(shù)組遍歷一遍吧,遍歷完就知道交集是什么了。
其實對于有序的數(shù)組,用跳表(skip table)可以更高效,這里就不展開了,因為不管是從性能,還是空間上考慮,Integer 數(shù)組都不靠譜,假設(shè)有100M 個文檔 ID,每個文檔 ID 占 2 bytes,那已經(jīng)是 200 MB,而這些數(shù)據(jù)是要放到內(nèi)存中進(jìn)行處理的,把這么大量的數(shù)據(jù),從磁盤解壓后丟到內(nèi)存,內(nèi)存肯定撐不住。
Option 2: Bitmap
假設(shè)有這樣一個數(shù)組:
[3,6,7,10]
那么我們可以這樣來表示:
[0,0,1,0,0,1,1,0,0,1]
看出來了么,對,我們用 0 表示角標(biāo)對應(yīng)的數(shù)字不存在,用 1 表示存在。
這樣帶來了兩個好處:
節(jié)省空間:既然我們只需要0和1,那每個文檔 ID 就只需要 1 bit,還是假設(shè)有 100M 個文檔,那只需要 100M bits = 100M * 1/8 bytes = 12.5 MB,比之前用 Integer 數(shù)組 的 200 MB,優(yōu)秀太多
運(yùn)算更快:0 和 1,天然就適合進(jìn)行位運(yùn)算,求交集,「與」一下,求并集,「或」一下,一切都回歸到計算機(jī)的起點
Option 3: Roaring Bitmaps
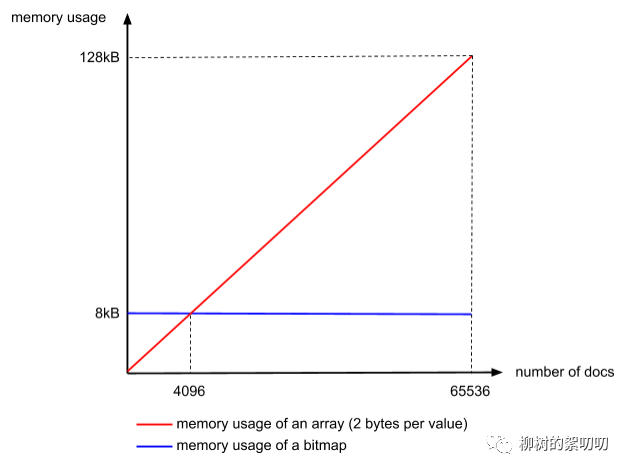
細(xì)心的你可能發(fā)現(xiàn)了,bitmap 有個硬傷,就是不管你有多少個文檔,你占用的空間都是一樣的,之前說過,Lucene ?Posting List 的每個 Segement 最多放 65536 個文檔ID,舉一個極端的例子,有一個數(shù)組,里面只有兩個文檔 ID:
[0, 65535]
用 Bitmap,要怎么表示?
[1,0,0,0,….(超級多個0),…,0,0,1]
你需要 65536 個 bit,也就是 65536/8 = 8192 bytes,而用 Integer 數(shù)組,你只需要 2 * 2 bytes = 4 bytes
呵呵,死板的 bitmap。可見在文檔數(shù)量不多的時候,使用 Integer 數(shù)組更加節(jié)省內(nèi)存。
我們來算一下臨界值,很簡單,無論文檔數(shù)量多少,bitmap都需要 8192 bytes,而 Integer 數(shù)組則和文檔數(shù)量成線性相關(guān),每個文檔 ID 占 2 bytes,所以:
8192 / 2 = 4096
當(dāng)文檔數(shù)量少于 4096 時,用 Integer 數(shù)組,否則,用 bitmap.
升華與總結(jié)這里補(bǔ)充一下 Roaring bitmaps 和 之前講的 Frame Of Reference 的關(guān)系。
Frame Of Reference 是壓縮數(shù)據(jù),減少磁盤占用空間,所以當(dāng)我們從磁盤取數(shù)據(jù)時,也需要一個反向的過程,即解壓,解壓后才有我們上面看到的這樣子的文檔ID數(shù)組:[73, 300, 302, 303, 343, 372] ?,接著我們需要對數(shù)據(jù)進(jìn)行處理,求交集或者并集,這時候數(shù)據(jù)是需要放到內(nèi)存進(jìn)行處理的,我們有三個這樣的數(shù)組,這些數(shù)組可能很大,而內(nèi)存空間比磁盤還寶貴,于是需要更強(qiáng)有力的壓縮算法,同時還要有利于快速的求交并集,于是有了Roaring Bitmaps 算法。
另外,Lucene 還會把從磁盤取出來的數(shù)據(jù),通過 Roaring bitmaps 處理后,緩存到內(nèi)存中,Lucene 稱之為 filter cache. ?
文章的最后,如果來一段話總結(jié)(zhuang)升華(bi)一下,這篇文章就會得高分。
有什么總結(jié),可以拔高這篇文章的高度呢?
首先,你會發(fā)現(xiàn),很多業(yè)務(wù)上、技術(shù)上要解決的問題,最后都可以抽象為一道算法題,復(fù)雜問題簡單化。
呃,這個“華”,升的還不夠。
另一個具有高度的“華”,其實在開頭已經(jīng)講出來了:
每種數(shù)據(jù)庫都有自己要解決的問題(或者說擅長的領(lǐng)域),對應(yīng)的就有自己的數(shù)據(jù)結(jié)構(gòu),而不同的使用場景和數(shù)據(jù)結(jié)構(gòu),需要用不同的索引,才能起到最大化加快查詢的目的。
這篇文章講的雖是 Lucene 如何實現(xiàn)倒排索引,如何精打細(xì)算每一塊內(nèi)存、磁盤空間、如何用詭譎的位運(yùn)算加快處理速度,但往高處思考,再類比一下 Mysql,你就會發(fā)現(xiàn),雖然都是索引,但是實現(xiàn)起來,截然不同。
這個往細(xì)講,又是一篇文章:如此不同,如此成功 —— B+ 樹索引 vs 倒排索引
留個作業(yè)吧知識要融合起來看才有意思。
來,放大招了,兩個問題:
Lucene 為什么不用 b+ 樹來搜索數(shù)據(jù)?
Mysql 為什么不用 倒排索引來檢索數(shù)據(jù)?
附上兩張圖:
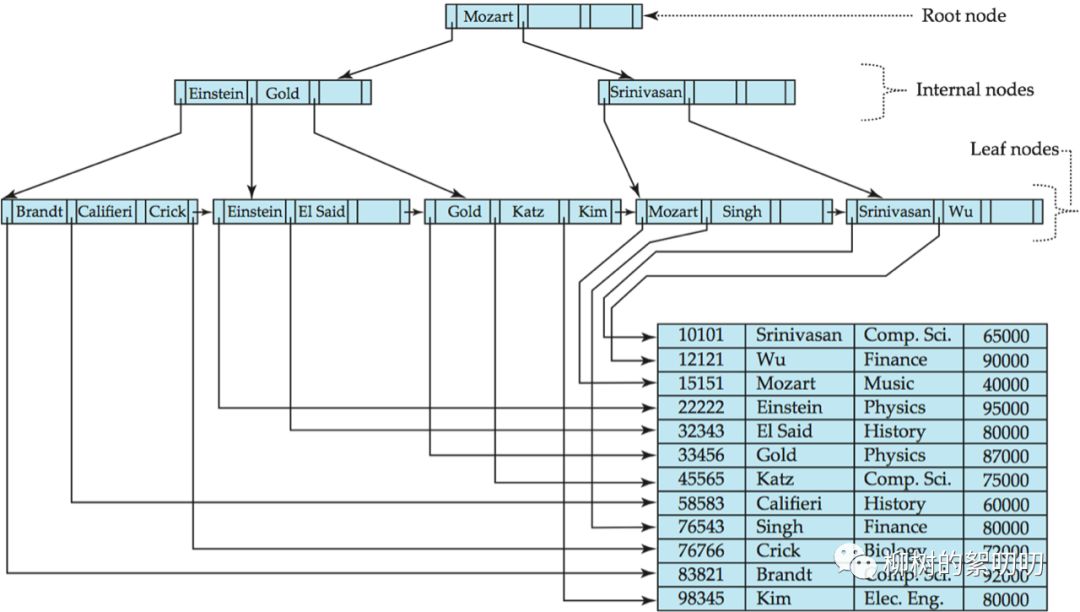
Mysql 的 B+樹索引
推薦阿里云推廣服務(wù)器89/年,229/3年,買來送自己,送女朋友馬上過年再合適不過了,買了搭建個項目給面試官看也香,還可以熟悉技術(shù)棧,(老用戶用家人賬號買就好了,我用我女朋友的?)。掃碼購買
我這里還有一個:搭建教程,從0開始一步一步帶你搭建?