
如何實(shí)現(xiàn)刪除重復(fù)記錄并且只保留一條?
點(diǎn)擊上方?泥瓦匠 關(guān)注我!

最近,在做題庫(kù)系統(tǒng),由于在題庫(kù)中添加了重復(fù)的試題,所以需要查詢出重復(fù)的試題,并且刪除掉重復(fù)的試題只保留其中1條,以保證考試的時(shí)候抽不到重復(fù)的題。
一、單個(gè)字段的操作
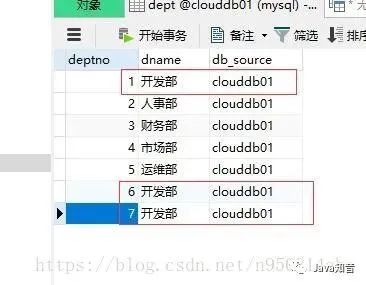
分組介紹
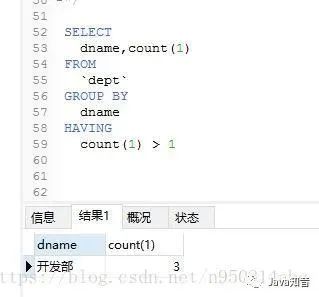
Select?重復(fù)字段?From?表?Group?By?重復(fù)字段?Having?Count(*)>1GROUP BY <列名序列>
HAVING <組條件表達(dá)式>
1. 查詢?nèi)恐貜?fù)的數(shù)據(jù)
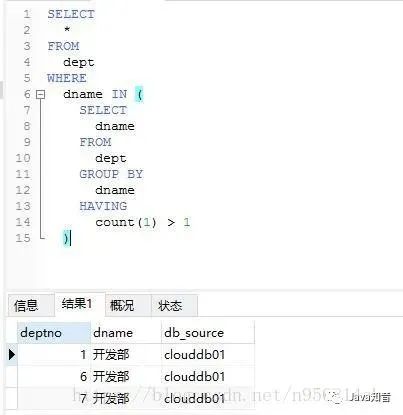
Select?*?From?表?Where?重復(fù)字段?In?(Select?重復(fù)字段?From?表?Group?By?重復(fù)字段?Having?Count(*)>1)2. 刪除全部重復(fù)試題
DELETEFROMdeptWHEREdname IN (SELECTdnameFROMdeptGROUP BYdnameHAVINGcount(1) > 1)
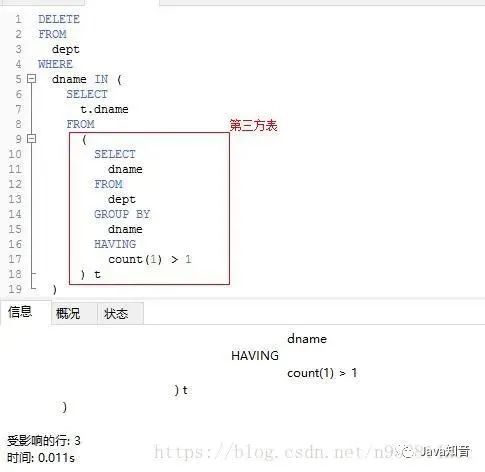
3. 查詢表中多余重復(fù)試題(根據(jù)depno來(lái)判斷,除了rowid最小的一個(gè))
a. 第一種方法
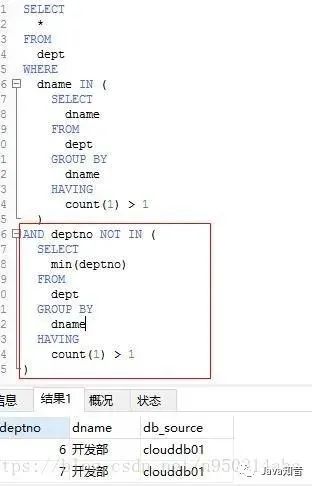
SELECT*FROMdeptWHEREdname IN (SELECTdnameFROMdeptGROUP BYdnameHAVINGCOUNT(1) > 1)AND deptno NOT IN (SELECTMIN(deptno)FROMdeptGROUP BYdnameHAVINGCOUNT(1) > 1)
b. 第二種方法
SELECT *FROMdeptWHEREdeptno NOT IN (SELECTdt.minnoFROM(SELECTMIN(deptno) AS minnoFROMdeptGROUP BYdname) dt)
c. 補(bǔ)充第三種方法
SELECT*FROMtable_name AS taWHEREta.唯一鍵 <> ( SELECT max( tb.唯一鍵 ) FROM table_name AS tb WHERE ta.判斷重復(fù)的列 = tb.判斷重復(fù)的列 );
4. 刪除表中多余重復(fù)試題并且只留1條
a. 第一種方法:
DELETEFROMdeptWHEREdname IN (SELECTt.dnameFROM(SELECTdnameFROMdeptGROUP BYdnameHAVINGcount(1) > 1) t)AND deptno NOT IN (SELECTdt.mindeptnoFROM(SELECTmin(deptno) AS mindeptnoFROMdeptGROUP BYdnameHAVINGcount(1) > 1) dt)
b. 第二種方法(與上面查詢的第二種方法對(duì)應(yīng),只是將select改為delete)
DELETEFROMdeptWHEREdeptno NOT IN (SELECTdt.minnoFROM(SELECTMIN(deptno) AS minnoFROMdeptGROUP BYdname) dt)
c. 補(bǔ)充第三種方法(評(píng)論區(qū)推薦的一種方法)
DELETEFROMtable_name AS taWHEREta.唯一鍵 <> (SELECTt.maxidFROM( SELECT max( tb.唯一鍵 ) AS maxid FROM table_name AS tb WHERE ta.判斷重復(fù)的列 = tb.判斷重復(fù)的列 ) t);
二、多個(gè)字段的操作
DELETEFROMdeptWHERE(dname, db_source) IN (SELECTt.dname,t.db_sourceFROM(SELECTdname,db_sourceFROMdeptGROUP BYdname,db_sourceHAVINGcount(1) > 1) t)AND deptno NOT IN (SELECTdt.mindeptnoFROM(SELECTmin(deptno) AS mindeptnoFROMdeptGROUP BYdname,db_sourceHAVINGcount(1) > 1) dt)
# 總結(jié)
在經(jīng)常查詢的字段上加上索引
將*改為你需要查詢出來(lái)的字段,不要全部查詢出來(lái)
小表驅(qū)動(dòng)大表用IN,大表驅(qū)動(dòng)小表用EXISTS。IN適合的情況是外表數(shù)據(jù)量小的情況,而不是外表數(shù)據(jù)大的情況,因?yàn)镮N會(huì)遍歷外表的全部數(shù)據(jù),假設(shè)a表100條,b表10000條那么遍歷次數(shù)就是100*10000次,而exists則是執(zhí)行100次去判斷a表中的數(shù)據(jù)是否在b表中存在,它只執(zhí)行了a.length次數(shù)。至于哪一個(gè)效率高是要看情況的,因?yàn)閕n是在內(nèi)存中比較的,而exists則是進(jìn)行數(shù)據(jù)庫(kù)查詢操作的。

往期推薦
下方二維碼關(guān)注我

技術(shù)草根,堅(jiān)持分享?編程,算法,架構(gòu)
評(píng)論
圖片
表情