
Elasticsearch 聚合性能優(yōu)化六大猛招
1、問題引出
默認情況下,Elasticsearch 已針對大多數用例進行了優(yōu)化,確保在寫入性能和查詢性能之間取得平衡。我們將介紹一些聚合性能優(yōu)化的可配置參數,其中部分改進是以犧牲寫入性能為代價的。目標是將聚合優(yōu)化招數匯總到一個易于消化的短文中,為大家的 Elasticsearch 集群聚合性能優(yōu)化提供一些指導。
2、聚合實戰(zhàn)問題
問題1:1天的數據 70W,聚合2次分桶正常查詢時間是 200ms左右, 增加了一個去重條件, 就10-13秒了,有優(yōu)化的地方不?
問題2:請問在很多 terms 聚合的情況下,怎樣優(yōu)化檢索?我的場景在無聚合時,吞吐量有 300,在加入 12 個聚合字段后,吞吐量不到20。
問題3:哪位兄弟 幫忙發(fā)一個聚合優(yōu)化的鏈接,我這個聚合 幾千萬 就好幾秒了?
3、認知前提
3.1 Elasticsearch 聚合是不嚴格精準的
原因在于:數據分散到多個分片,聚合是每個分片的取 Top X,導致結果不精準。
可以看一下之前的文章:Elasticsearch 聚合數據結果不精確,怎么破?
3.2 從業(yè)務層面規(guī)避全量聚合
聚合結果的精準性和響應速度之間是相對矛盾的。
正常業(yè)務開發(fā),產品經理往往要求:
第一:快速秒級或者毫秒級聚合響應。
第二:聚合結果精準。
殊不知,二者不可兼得。
遇到類似兩者都要兼得的需求,建議從架構選型和業(yè)務層面做規(guī)避處理。
3.3 刷新頻率
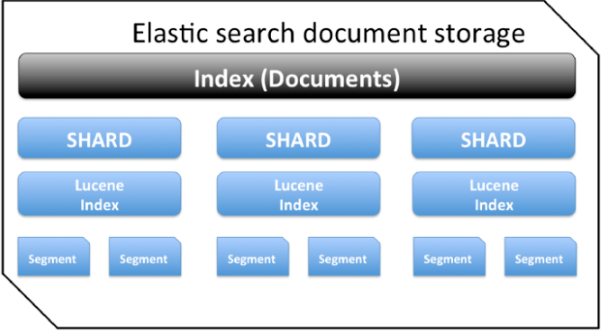
如下圖所示,Elasticsearch 中的 1 個索引由一個或多個分片組成,每個分片包含多個segment(段),每一個段都是一個倒排索引。
在 lucene 中,為了實現高索引速度,使用了segment 分段架構存儲。一批寫入數據保存在一個段中,其中每個段最終落地為磁盤中的單個文件。
如下圖所示,將文檔插入 Elasticsearch 時,它們會被寫入緩沖區(qū)中,然后在刷新時定期從該緩沖區(qū)刷新到段中。刷新頻率由 refresh_interval 參數控制,默認每1秒發(fā)生一次。也就是說,新插入的文檔在刷新到段(內存中)之前,是不能被搜索到的。
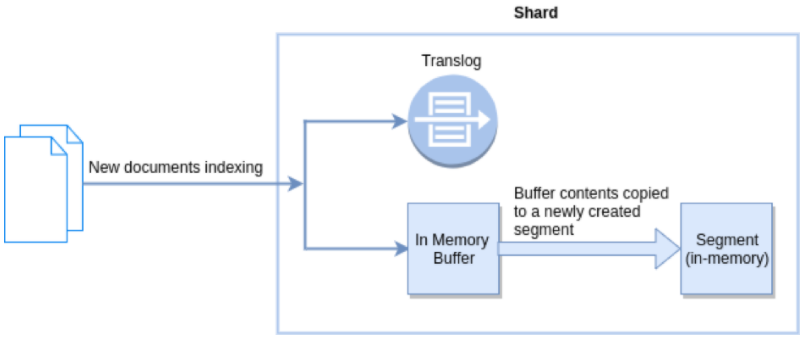
刷新的本質是:寫入數據由內存 buffer 寫入到內存段中,以保證搜索可見。
來看個例子,加深對 refresh_inteval ?的理解,注釋部分就是解讀。
PUT?test_0001/_doc/1
{
??"title":"just?testing"
}
#?默認一秒的刷新頻率,秒級可見(用戶無感知)
GET?test_0001/_search
DELETE?test_0001
#?設置了60s的刷新頻率
PUT?test_0001
{
??"settings":?{
????"index":{
??????"refresh_interval":"60s"
????}
??}
}
PUT?test_0001/_doc/1
{
??"title":"just?testing"
}
#?60s后才可以被搜索到
GET?test_0001/_search
關于是否需要實時刷新:
如果新插入的數據需要近乎實時的搜索功能,則需要頻繁刷新。
如果對最新數據的檢索響應沒有實時性要求,則應增加刷新間隔,以提高數據寫入的效率,從而應釋放資源輔助提高查詢性能。
關于刷新頻率對查詢性能的影響:
由于每刷新一次都會生成一個 Lucene 段,刷新頻率越小就意味著同樣時間間隔,生成的段越多。
每個段都要消耗句柄和內存。
每次查詢請求都需要輪詢每個段,輪詢完畢后再對結果進行合并。
也就意味著:refresh_interval 越小,產生的段越多,搜索反而會越慢;反過來說,加大 refresh_interval,會相對提升搜索性能。
4、聚合性能優(yōu)化猛招
4.1 ? ?啟用 eager global ordinals 提升高基數聚合性能
適用場景:高基數聚合。
高基數聚合場景中的高基數含義:一個字段包含很大比例的唯一值。
global ordinals 中文翻譯成全局序號,是一種數據結構,應用場景如下:
基于 keyword,ip 等字段的分桶聚合,包含:terms聚合、composite 聚合等。
基于text 字段的分桶聚合(前提條件是:fielddata 開啟)。
基于父子文檔 Join 類型的 has_child 查詢和 父聚合。
global ordinals 使用一個數值代表字段中的字符串值,然后為每一個數值分配一個 bucket(分桶)。
global ordinals 的本質是:啟用 eager_global_ordinals 時,會在刷新(refresh)分片時構建全局序號。這將構建全局序號的成本從搜索階段轉移到了數據索引化(寫入)階段。
創(chuàng)建索引的同時開啟:eager_global_ordinals。
PUT?my-index-000001
{
??"mappings":?{
????"properties":?{
??????"tags":?{
????????"type":?"keyword",
????????"eager_global_ordinals":?true
??????}
????}
??}
}
注意:開啟 eager_global_ordinals 會影響寫入性能,因為每次刷新時都會創(chuàng)建新的全局序號。為了最大程度地減少由于頻繁刷新建立全局序號而導致的額外開銷,請調大刷新間隔 refresh_interval。
動態(tài)調整刷新頻率的方法如下:
PUT?my-index-000001/_settings
{
??"index":?{
????"refresh_interval":?"30s"
??}
}
該招數的本質是:以空間換時間。
4.2 插入數據時對索引進行預排序
Index sorting (索引排序)可用于在插入時對索引進行預排序,而不是在查詢時再對索引進行排序,這將提高范圍查詢(range query)和排序操作的性能。
在 Elasticsearch 中創(chuàng)建新索引時,可以配置如何對每個分片內的段進行排序。
這是 Elasticsearch 6.X 之后版本才有的特性。
Index sorting 實戰(zhàn)舉例:
PUT?my-index-000001
{
??"settings":?{
????"index":?{
??????"sort.field":?"cur_time",
??????"sort.order":?"desc"
????}
??},
??"mappings":?{
????"properties":?{
??????"cur_time":?{
????????"type":?"date"
??????}
????}
??}
}
如上示例是在:創(chuàng)建索引的設置部分設置待排序的字段:cur_time 以及 排序方式:desc 降序。
注意:預排序將增加 Elasticsearch 寫入的成本。在某些用戶特定場景下,開啟索引預排序會導致大約 40%-50% 的寫性能下降。
也就是說,如果用戶場景更關注寫性能的業(yè)務,開啟索引預排序不是一個很好的選擇。
4.3 使用節(jié)點查詢緩存
節(jié)點查詢緩存(Node query cache)可用于有效緩存過濾器(filter)操作的結果。如果多次執(zhí)行同一 filter 操作,這將很有效,但是即便更改過濾器中的某一個值,也將意味著需要計算新的過濾器結果。
例如,由于 “now” 值一直在變化,因此無法緩存在過濾器上下文中使用 “now” 的查詢。
那怎么使用緩存呢?通過在 now 字段上應用 datemath 格式將其四舍五入到最接近的分鐘/小時等,可以使此類請求更具可緩存性,以便可以對篩選結果進行緩存。
關于 datemath 格式及用法,舉個例子來說明:
以下的示例,無法使用緩存。
PUT?index/_doc/1
{
??"my_date":?"2016-05-11T16:30:55.328Z"
}
GET?index/_search
{
??"query":?{
????"constant_score":?{
??????"filter":?{
????????"range":?{
??????????"my_date":?{
????????????"gte":?"now-1h",
????????????"lte":?"now"
??????????}
????????}
??????}
????}
??}
}
但是,下面的示例就可以使用節(jié)點查詢緩存。
GET?index/_search
{
??"query":?{
????"constant_score":?{
??????"filter":?{
????????"range":?{
??????????"my_date":?{
????????????"gte":?"now-1h/m",
????????????"lte":?"now/m"
??????????}
????????}
??????}
????}
??}
}
上述示例中的“now-1h/m” 就是 datemath 的格式。
更細化點說,如果當前時間 now 是:16:31:29,那么range query 將匹配 my_date 介于:15:31:00 和 15:31:59 之間的時間數據。
同理,聚合的前半部分 query 中如果有基于時間查詢,或者后半部分 aggs 部分中有基于時間聚合的,建議都使用 datemath 方式做緩存處理以優(yōu)化性能。
4.4 使用分片請求緩存
聚合語句中,設置:size:0,就會使用分片請求緩存緩存結果。
size = 0 的含義是:只返回聚合結果,不返回查詢結果。
GET?/my_index/_search
{
??"size":?0,
??"aggs":?{
????"popular_colors":?{
??????"terms":?{
????????"field":?"colors"
??????}
????}
??}
}
4.5 拆分聚合,使聚合并行化
這里有個認知前提:Elasticsearch 查詢條件中同時有多個條件聚合,這個時候的多個聚合不是并行運行的。
這里就有疑問:是不是可以通過 msearch 拆解多個聚合為單個子語句來改善響應時間?
什么意思呢,給個 Demo,toy_demo_003 數據來源:
示例一:常規(guī)的多條件聚合實現
如下響應時間:15 ms。
POST?toy_demo_003/_search
{
??"size":?0,
??"aggs":?{
????"hole_terms_agg":?{
??????"terms":?{
????????"field":?"has_hole"
??????}
????},
????"max_aggs":{
??????"max":{
????????"field":"size"
??????}
????}
??}
}
示例二:msearch 拆分多個語句的聚合實現
如下響應時間:9 ms。
POST?_msearch
{"index"?:?"toy_demo_003"}
{"size":0,"aggs":{"hole_terms_agg":{"terms":{"field":"has_hole"}}}}
{"index"?:?"toy_demo_003"}
{"size":0,"aggs":{"max_aggs":{"max":{"field":"size"}}}}
來個對比驗證吧:

藍色:類似示例一,單個query 中包含多個聚合,聚合數分別是:1,2,5,10。
紅色:類似示例二,multi_search 拆解多個聚合,拆分子句個數分別為:1,2,5,10。
橫軸:藍色對應聚合個數;紅色對應子句個數;
縱軸:響應時間,響應時間越短、性能越好。
初步結論是:
默認情況下聚合不是并行運行。
當為每個聚合提供自己的查詢并執(zhí)行 msearch 時,性能會有顯著提升。
尤其在 10 個聚合的場景下,性能提升了接近 2 倍。
因此,在 CPU 資源不是瓶頸的前提下,如果想縮短響應時間,可以將多個聚合拆分為多個查詢,借助:msearch 實現并行聚合。
4.6 將聚合中的查詢條件移動到 query 子句部分
示例一:
POST?my_index/_search
{
??"size":?0,
??"aggregations":?{
????"1":?{
??????"filter":?{
????????"match":?{
??????????"search_field":?"text"
????????}
??????},
??????"aggregations":?{
????????"items":?{
??????????"top_hits":?{
????????????"size":?100,
????????????"_source":?{
??????????????"includes":?"field1"
????????????}
??????????}
????????}
??????}
????},
????"2":?{
??????"filter":?{
????????"match":?{
??????????"search_field":?"text"
????????}
??????},
??????"aggregations":?{
????????"items":?{
??????????"top_hits":?{
????????????"size":?100,
????????????"_source":?{
??????????????"includes":?"field2"
????????????}
??????????}
????????}
??????}
????}
??}
}
示例二:
{
??"query":?{
????"bool":?{
??????"filter":?[
????????{
??????????"match":?{
????????????"search_field":?"text"
??????????}
????????}
??????]
????}
??},
??"size":?0,
??"aggregations":?{
????"1":?{
??????"top_hits":?{
????????"size":?100,
????????"_source":?{
??????????"includes":?"field1"
????????}
??????}
????},
????"2":?{
??????"top_hits":?{
????????"size":?100,
????????"_source":?{
??????????"includes":?"field2"
????????}
??????}
????}
??}
}
示例一和示例二的本質區(qū)別:
第二個查詢已將此過濾器提取到較高級別,這應使聚合共享結果。
如下對比實驗表明,由于 Elasticsearch 自身做了優(yōu)化,示例一(藍色)和示例二(紅色)響應時間基本一致。

更多驗證需要結合業(yè)務場景做一下對比驗證,精簡起見,推薦使用第二種。
5、更多優(yōu)化參考
官方關于檢索性能優(yōu)化同樣適用于聚合
https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-search-speed.html
分片數設置多少合理?
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
堆內存大小設置?
https://www.elastic.co/cn/blog/a-heap-of-trouble
禁用 swapping
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration-memory.html
6、小結
本文的六大猛招出自:Elastic 原廠咨詢架構師 Alexander 以及 Coolblue 公司的軟件開發(fā)工程師 Raoul Meyer。
六大猛招中的 msearch 并行聚合方式,令人眼前一亮,相比我在業(yè)務實戰(zhàn)中用的多線程方式實現并行,要“高級”了許多。
我結合自己的聚合優(yōu)化實踐做了翻譯和擴展,希望對大家的聚合性能優(yōu)化有所幫助。
歡迎留言寫下您的聚合優(yōu)化實踐和思考。
和你一起,死磕 Elastic!
參考
https://qbox.io/blog/refresh-flush-operations-elasticsearch-guide
https://alexmarquardt.com/how-to-tune-elasticsearch-for-aggregation-performance/
https://www.elastic.co/cn/blog/index-sorting-elasticsearch-6-0
《Elasticsearch 源碼解析與優(yōu)化實戰(zhàn)》
推薦
中國最大的 Elastic 非官方公眾號
點擊查看“閱讀原文”,和全球近1000 位 Elastic 愛好者一起每日精進 ELK 技能!