
工作中落地prompt 的一些實(shí)踐和心得體會(huì)

文 | Severus
就如同《倚天屠龍記》中的主角張無忌,語言模型修煉了深厚的內(nèi)功,但是遇到他的乾坤大挪移之前,他空有一身本領(lǐng)卻不會(huì)用。但學(xué)會(huì)之后,于所有武功又都融會(huì)貫通。光明頂上血戰(zhàn)六大派,他可以打出比崆峒派威力更大的七傷拳,比少林寺更加正宗的龍爪手。武當(dāng)山上,他可以最快學(xué)會(huì)太極拳和太極劍法。prompt 是否又是語言模型的乾坤大挪移呢?
大家好,我是 Severus,一個(gè)在某廠做中文文本理解的程序員。今天我想要分享的是在工業(yè)實(shí)踐中使用 prompt 的一些實(shí)踐和心得體會(huì)。話不多說,我們直接開始。
初次關(guān)注到 prompt 是在去年GPT-3發(fā)布之后,我讀到了一篇論文,It' s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners ,了解我的小伙伴都會(huì)知道,雖然我是一個(gè)預(yù)訓(xùn)練語言模型的使用者,甚至生產(chǎn)者,但對于超大規(guī)模的語言模型,我一直持相對否定的態(tài)度,所以這篇文章的標(biāo)題就相當(dāng)吸引我,并且讀下來之后,隱隱感覺,將文本理解任務(wù)轉(zhuǎn)換為預(yù)訓(xùn)練的任務(wù)形式,再使用預(yù)訓(xùn)練語言模型,去做這個(gè)任務(wù),這個(gè)思路簡直太無懈可擊了!利用它,我們可以更輕松地完成很多工作,又不必去面對例如樣本類別均衡之類的數(shù)據(jù)分布上的困擾。
但當(dāng)時(shí)卻沒有勇氣直接應(yīng)用起來。
到了今年,prompt 成為了一個(gè)相當(dāng)火熱的方向,在那篇 prompt 綜述[1]出來了之后,我們知道,prompt 已經(jīng)成氣候了,它已經(jīng)被很多工作驗(yàn)證是有用的了,也終于下定了決心,在我們的項(xiàng)目中嘗試使用它,并看一下它到底有多么神奇。用過之后,不得不說,真香!而且除了小樣本之外,我們也解鎖了 prompt 的一些花式用法,今天我竹筒倒豆子,分享出來。
淺談我對prompt的理解
本節(jié)是我基于我近幾年的分析經(jīng)驗(yàn),嘗試去理解一下 prompt 為什么這么香,以及怎么要使用它,它才這么香,當(dāng)然這一節(jié)絕大多數(shù)是我的胡亂猜想,沒有什么實(shí)驗(yàn)數(shù)據(jù)支撐,一家之言,不一定對。
初見 prompt,我的第一反應(yīng)就是,在下游任務(wù)上的訓(xùn)練方式和預(yù)訓(xùn)練的訓(xùn)練方式直接同源了,那必然是可以充分利用到預(yù)訓(xùn)練語言模型的“遺產(chǎn)”了啊,而相比之下,fine-tuning 的思路則是強(qiáng)行將任務(wù)轉(zhuǎn)換成了另一種形式,對于預(yù)訓(xùn)練語言模型的知識是沒有充分利用到的,這么一看,簡直是越看越靠譜了。

當(dāng)然,上面那些想法現(xiàn)在有了更加明白的解釋,那就是將語言模型看做是知識庫(Language Models as Knowledge Bases)。實(shí)際上,prompt 可以看做是對預(yù)訓(xùn)練語言模型中已經(jīng)記憶的知識的一種檢索方式,由于 prompt 任務(wù)形式就是預(yù)訓(xùn)練任務(wù),所以相比于 fine-tuning,當(dāng)使用 prompt 形式向模型中輸入樣本時(shí),預(yù)測時(shí)所需使用到的信息量是更多的。因?yàn)橐玫礁嗟男畔⒘浚?strong>樣本的類別分布在 prompt 視角之下都是稀疏的,這應(yīng)該也是 prompt 在 few-shot 上效果顯著的原因。
#?使用我們開發(fā)的預(yù)訓(xùn)練語言模型直接預(yù)測的結(jié)果
input:??送元二使安西是一首[MASK][MASK]。
output:??送元二使安西是一首詩詞。
我們的文本分類任務(wù),類別標(biāo)簽都是有語義的,且這個(gè)語義是自然語義,所以,我們假設(shè),在自編碼預(yù)訓(xùn)練語言模型中,樣本標(biāo)簽和樣本之間天然就存在潛在的關(guān)聯(lián),而在 prompt-tuning 上,我們只需要將這個(gè)關(guān)聯(lián)抽取出來,強(qiáng)化它就好。
與之不同的是,fine-tuning 形式中,對于模型來講,每個(gè)類別標(biāo)簽只是一個(gè) id,所以在訓(xùn)練過程中,模型是根據(jù)樣本什么樣的分布來調(diào)整參數(shù)的對于我們來講是不可感知的,但是單從模型的表現(xiàn)來看,我們可以注意到,模型是很容易走捷徑的,如果某一類樣本中存在明顯的分布 bias,則對其他少量分布的樣本就是相當(dāng)不友好的。而如果那個(gè) bias 和類別本身在語義上不相關(guān),則更加是一個(gè)災(zāi)難。
總之,prompt 更加依賴先驗(yàn),而 fine-tuning 更加依賴后驗(yàn)。也正因?yàn)檫@種特點(diǎn),prompt 生效的最基本前提是預(yù)訓(xùn)練語料已經(jīng)覆蓋了任務(wù)語料的分布,所幸,得力于超大規(guī)模的公開語料,現(xiàn)在絕大多數(shù)任務(wù)都是可以做到的,做不到的也可以利用領(lǐng)域適配等 trick 去補(bǔ)足。
以上是我對 prompt 的一些個(gè)人理解,同時(shí),我猜想 prompt 可能還存在一些特點(diǎn)(但我不確定):
使用 prompt 的前提是,任務(wù)中,輸入和答案之間需要存在語言的自然語義分布中的關(guān)聯(lián),由于預(yù)訓(xùn)練語言模型使用的是海量的自然語料,我們便理想化地認(rèn)為預(yù)訓(xùn)練語言模型中學(xué)習(xí)到的知識就是自然的語義分布; 也正因?yàn)榈?點(diǎn),同時(shí)也因?yàn)?prompt 所檢索出來的信息量是更多的,所以 prompt 對樣本中的噪音、混淆會(huì)很敏感,對任務(wù)的數(shù)據(jù)質(zhì)量要求很高(這或許也是在大規(guī)模數(shù)據(jù)上,prompt 可能干不過 fine-tuning 的原因); 在自編碼模型上,prompt 的重點(diǎn)可能是關(guān)聯(lián),而非一定要符合自然的表達(dá)習(xí)慣,但在自回歸模型上,可能就更要求 prompt 符合自然表達(dá)習(xí)慣(這點(diǎn)是我基于兩個(gè)模型的概率公式口胡的)。
接下來我介紹一下我們在prompt上的一些實(shí)踐。
直接使用 prompt 進(jìn)行細(xì)粒度分類
我們的第一個(gè)作為 prompt 試水的項(xiàng)目,是一個(gè)短文本分類的任務(wù),這個(gè)任務(wù)的輸入是一個(gè)名詞性短語,比如:劉德華、李達(dá)康、豉汁蒸排骨,預(yù)測這個(gè)名詞性短語的類別,比如:人、菜品等。起初,這個(gè)任務(wù)我們只去做粗粒度類別的分類,總共是42個(gè)類別,而決定使用 prompt 之后,我們認(rèn)為,prompt 這么好的性質(zhì),不直接做細(xì)粒度分類簡直浪費(fèi)了啊!所以我們根據(jù)詞語后綴(名詞性短語的類別絕大多數(shù)由后綴決定)將原本的任務(wù)轉(zhuǎn)換成了2100個(gè)類別,準(zhǔn)備開始做。
實(shí)際上,在開始做之前,我還是有一點(diǎn)擔(dān)憂,畢竟,初期實(shí)驗(yàn),我們打算直接用預(yù)訓(xùn)練的參數(shù),做 token 級的分類,但是由于中文是字級別的 token,但是類別標(biāo)簽都是多于一個(gè)字的,而且長度是不固定的(畢竟在此之前好像我看到的 prompt 的答案多數(shù)是一個(gè) token 的),所以就有兩個(gè)擔(dān)心:
最終預(yù)測的結(jié)果是否會(huì)控制在類別標(biāo)簽集合中,預(yù)測出來的 token 是否在類別標(biāo)簽集合對應(yīng)的字符集合中 模型能否學(xué)會(huì)變長的 prompt
于是我去查找文章,看到一些文章里給出的結(jié)論說 prompt 的長度可以是10~20,并且自己也打算用 padding 的方式直接去控制不定長答案學(xué)習(xí),也不管字符集的問題,直接使用最樸素的方法去訓(xùn)練,訓(xùn)練過后,測試結(jié)果直接讓我震驚了:精度是88.9%!而之前42個(gè)類的分類精度,也僅僅是89%。
后續(xù)我們不斷地迭代數(shù)據(jù),去除樣本中的噪音之后,現(xiàn)在測試精度已經(jīng)達(dá)到了90.17%,并且還有繼續(xù)改進(jìn)的空間。
這個(gè)過程中,超出了我的預(yù)期的是,首先預(yù)測結(jié)果中不在類別標(biāo)簽集合中的結(jié)果占比僅僅在2%左右,且這些預(yù)測結(jié)果與已有標(biāo)簽僅僅相差1~2個(gè)萊文斯坦距離(levenstein distance,將字符串 A 編輯轉(zhuǎn)換為字符串 B 最少需要經(jīng)過多少次單字符增加、刪除、替換操作),這些預(yù)測結(jié)果,如果考慮到用戶體驗(yàn),我只需要使用BK樹修正即可。并且預(yù)測結(jié)果中完全沒有預(yù)測到標(biāo)簽集合所對應(yīng)字符集之外的 token,且我用 padding 控制長度也是生效的。而這全程,我使用的都是平常 fine-tuning 時(shí)使用的學(xué)習(xí)率(相比于預(yù)訓(xùn)練小了兩個(gè)數(shù)量級)。
同時(shí),我的訓(xùn)練樣本類別分布是極其不平衡的,樣本最多的類可能有幾十萬,樣本最少的類可能僅僅有幾十個(gè),但無論多少,模型最終預(yù)測的結(jié)果都是正確的,這又恰恰證明了 prompt 視角下,樣本的類別分布都是稀疏的,進(jìn)一步給出了一個(gè)啟發(fā):使用 prompt 可以輕松地解決不平衡分類的問題。
在做這個(gè)任務(wù)的過程中,還發(fā)生了一個(gè)小插曲,就是我把標(biāo)簽列表的 offset 設(shè)置串位了,所有的標(biāo)簽 token 提前了兩位,不在 mask 的位置上了,但是最終的測試精度居然仍是88.9%,原本是一個(gè)低級錯(cuò)誤,但我講出來,主要還是認(rèn)為它佐證了我所說的,自編碼模型的 prompt 似乎只需要考慮關(guān)聯(lián),而不需要考慮自然表達(dá)習(xí)慣。當(dāng)然這個(gè)驗(yàn)證不合理,我需要在其他任務(wù)上使用不那么符合自然分布的 prompt 驗(yàn)證一下效果。
在我做這個(gè)項(xiàng)目的同時(shí),我的同事也嘗試了一些其他的項(xiàng)目,例如使用 span 結(jié)果直接去詢問NER類別,也達(dá)到了93%的F1(那份數(shù)據(jù)集本身的質(zhì)量大概也就是那個(gè)數(shù)了,例如“中國人民銀行”的類別有10:7的矛盾,景點(diǎn)和地址的類別定義混淆不清),使用 prompt 做關(guān)系分類,也達(dá)到了96%左右的F1。
這個(gè)模型,我們也將于11月在PaddleNLP-解語項(xiàng)目中開源,有興趣的小伙伴們敬請期待。
以上這些實(shí)驗(yàn)結(jié)果,直接堅(jiān)定了我在其他任務(wù)上繼續(xù)使用 prompt 的信心,而在做這些任務(wù)的過程中,我也發(fā)現(xiàn)了更加有趣的事情。
使用 prompt 檢測數(shù)據(jù)噪音
前文說到了,prompt 對噪音、混淆數(shù)據(jù)是非常敏感的,那么我們就想到,可以反過來利用這個(gè)特性,去探測數(shù)據(jù)中的噪音,迭代優(yōu)化數(shù)據(jù)。最直接的,就是 prompt 方式預(yù)測出的不在標(biāo)簽集里面的數(shù)據(jù)。
因?yàn)?strong>模型的預(yù)測表現(xiàn)一定反映了訓(xùn)練樣本的情況,那么,模型出現(xiàn)了預(yù)測結(jié)果不在標(biāo)簽集里面的情況,則一定反映了訓(xùn)練樣本中,某一類數(shù)據(jù)出現(xiàn)了類別混淆。所以使用模型預(yù)測全量的訓(xùn)練樣本之后,將此類樣本找出,即可判定訓(xùn)練樣本中需要做什么樣的調(diào)整。例如:某一版模型將“軟刺裸裂尻魚”預(yù)測成了“魚物”,則反映出訓(xùn)練樣本中的魚類一定出現(xiàn)了類別標(biāo)簽混淆,一部分被標(biāo)注成了“魚類”,一部分被標(biāo)注成了“動(dòng)物”,且二者在語義上都是成立的,所以模型也無法分辨最終想要的是哪一個(gè)知識。這種現(xiàn)象不僅僅在這個(gè)名詞性短語分類中見到,也在上面提到的NER任務(wù)中有體現(xiàn)。
除根據(jù)類別混淆情況探測之外,我們同樣也可以使用訓(xùn)練樣本的真實(shí)標(biāo)簽與預(yù)測標(biāo)簽的錯(cuò)誤,找到那些根本無法區(qū)分的邊緣樣本。對于名詞性短語分類這個(gè)任務(wù),我們知道,命名實(shí)體類樣本,如作品名、角色名、品牌名等,是極易與其他類樣本混淆,因?yàn)檫@一類名字可以任意起,且很容易與一般詞語重合,例如作品中各種專業(yè)書籍、教科書、人物傳記等,角色名與人名也極易出現(xiàn)混淆。在沒有上下文的情況下,哪怕是人類也難以區(qū)分這些短語的正確類別。但是,比如“高等數(shù)學(xué)”,當(dāng)這個(gè)詞單獨(dú)出現(xiàn)的時(shí)候,我們大概率會(huì)認(rèn)為它所指的是那個(gè)學(xué)科,而不是某一本教科書。
所以,根據(jù)這一原則,我們找到那些沖突的類別,直接從訓(xùn)練樣本中刪掉,避免模型困惑。果真,基于這一原則刪掉了幾萬條數(shù)據(jù)之后,模型的效果甚至提升了1個(gè)點(diǎn)。
我們認(rèn)為,這個(gè)結(jié)果是可以推廣到所有基于 prompt 的任務(wù)上的。prompt 模型、樣本、預(yù)測錯(cuò)誤三者之間形成了一個(gè)對抗、迭代的關(guān)系,基于這樣一種機(jī)制,充分利用預(yù)訓(xùn)練語言模型從海量語料里面學(xué)習(xí)到的知識,我們可以更加輕松地去迭代優(yōu)化數(shù)據(jù),同時(shí)也能夠標(biāo)注生成更大規(guī)模的高質(zhì)量數(shù)據(jù),幫助其他的模型得到更好的結(jié)果。
用于知識增強(qiáng)
至此,我們就沒有必要拘泥于 prompt 的任務(wù)形式了,試著開一開其他的腦洞。
前面提到,prompt 思路本質(zhì)上是將預(yù)訓(xùn)練語言模型看作是一個(gè)知識庫(Language Models as Knowledge Bases),而 prompt 奏效了,給我們的啟發(fā)是,知識增強(qiáng)的方式,可以更加自然。
首先,我們假設(shè)海量的預(yù)訓(xùn)練語料中已經(jīng)包含了比如對于某一個(gè)實(shí)體的知識,包括它的描述知識,和它的分布知識(即上下文提示)。那么,不僅限于 prompt 的任務(wù)形式,我們直接使用包含了知識的自然文本,到預(yù)訓(xùn)練語言模型中檢索出它的表示,是否就可以得到一種更加自然,且與預(yù)訓(xùn)練語言模型天生更加契合的知識增強(qiáng)方式呢?
實(shí)際上,在細(xì)粒度命名實(shí)體識別任務(wù) CLUENER 上,就存在類似的例子。CLUENER 任務(wù)中,有幾個(gè)非常難以區(qū)分的類別,分別是電影、游戲、書籍。這三種都是作品類的命名實(shí)體,在上下文中沒有相應(yīng)的信息的時(shí)候,極易發(fā)生混淆,實(shí)際上數(shù)據(jù)中的標(biāo)簽上也有一些混淆。但是在實(shí)驗(yàn)中,我們發(fā)現(xiàn),在輸入文本中明確提示了答案的時(shí)候,模型往往能正確標(biāo)注出命名實(shí)體的類別。這間接佐證了,模型是有能力感知到輸入文本中的提示的。
那么我們當(dāng)即決定先采取最樸素的方法,在輸入文本的后面追加一些知識文本做提示,實(shí)驗(yàn)過后,在一些易混淆 case 上取得了一些成效,但是整體效果提升不大,這當(dāng)然是符合預(yù)期的,畢竟這種樸素的插入并沒有什么目的,沒有讓模型有“觀察的重點(diǎn)”,而下面的一篇工作[2],則是我們的想法的更完善版本。
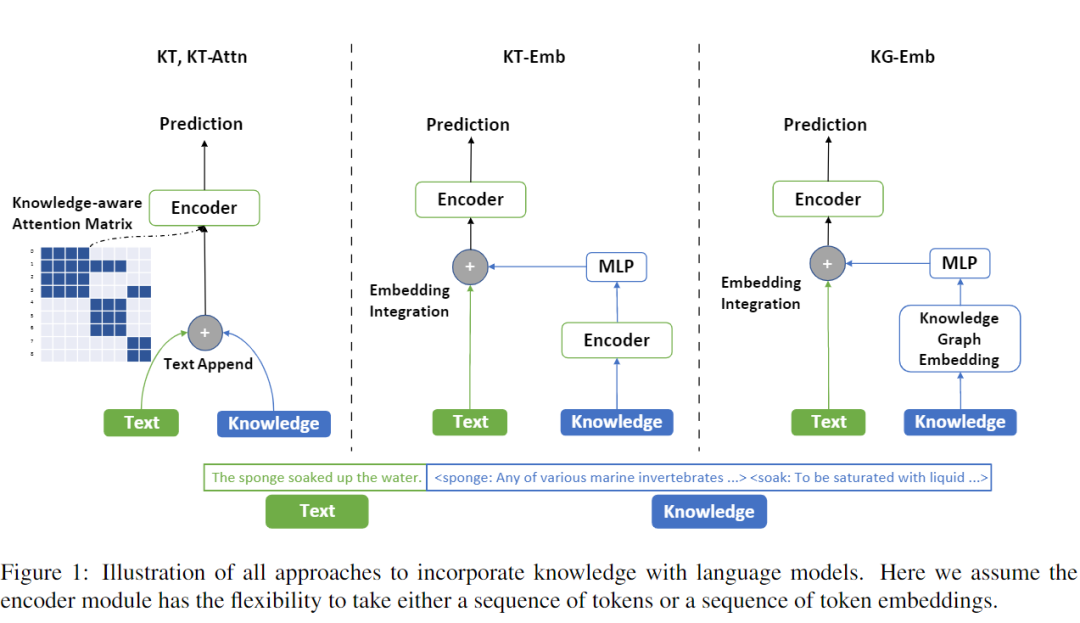
這篇工作使用了4種方式將知識融合到 NLP 模型中:
KT 方式和我前面嘗試的方式一樣,直接將知識文本(KT)追加到輸入之中; KT-Attn 則是在 attention 上疊加了一個(gè)可見性矩陣,控制只有知識描述的 token 能夠看到自身描述的知識; KT-Emb 是使用 encoder 先計(jì)算得到 KT 的表示,再疊加到文本表示上; KG-Emb 則是使用知識圖譜表示去增強(qiáng)模型,圖譜表示則是使用 TransE 計(jì)算得到
其中,KT 方式的知識來自于 Wikitonary 詞典數(shù)據(jù),通過詞性標(biāo)注等方式查到對應(yīng)的詞,將詞典中的釋義看作是知識,加入到任務(wù)之中。KG-Emb 的方式,則是使用 Wikidata 的數(shù)據(jù),將圖譜知識融合到任務(wù)中。其中 KT-Attn 方式是我心中比較理想的增強(qiáng)方式,而 KT-Emb 方法是我沒有想到過的,但是看了文章之后我也嘗試?yán)斫饬诉@個(gè)方法,感覺上也是 make sense 的。
實(shí)驗(yàn)結(jié)果如下:
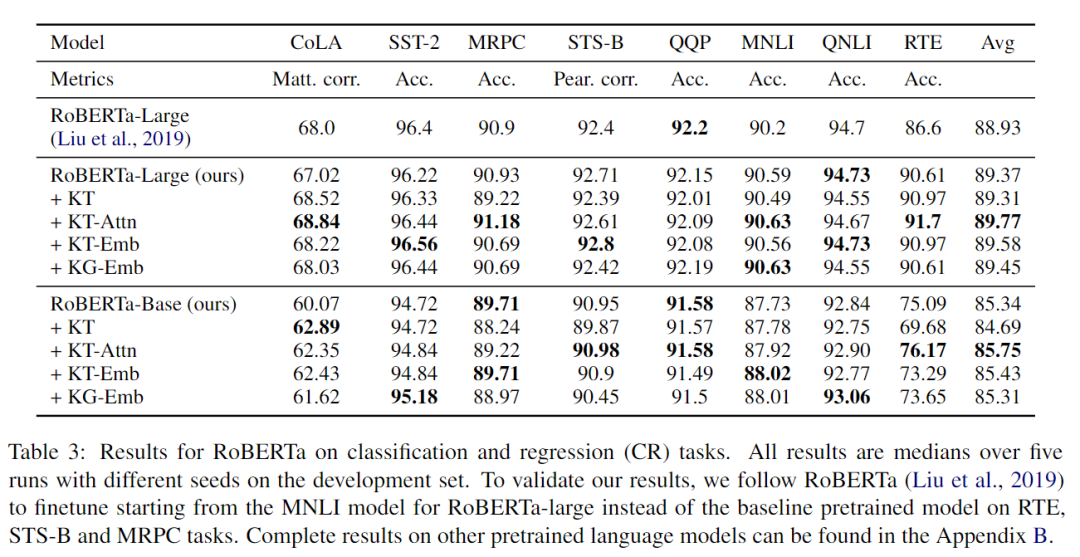
可以看到,KT-Attn 的方式和 KT-Emb 方式在兩種規(guī)模的模型里面取得的增益也是最多的,這也符合我這一節(jié)想要表述的觀點(diǎn)。同時(shí),作者還做了一個(gè) case 分析,在 CoLA (語法檢測)任務(wù)上,作者分別比對了知識增強(qiáng)前和知識增強(qiáng)后,各個(gè) token 對結(jié)果的重要程度貢獻(xiàn),結(jié)果如下:
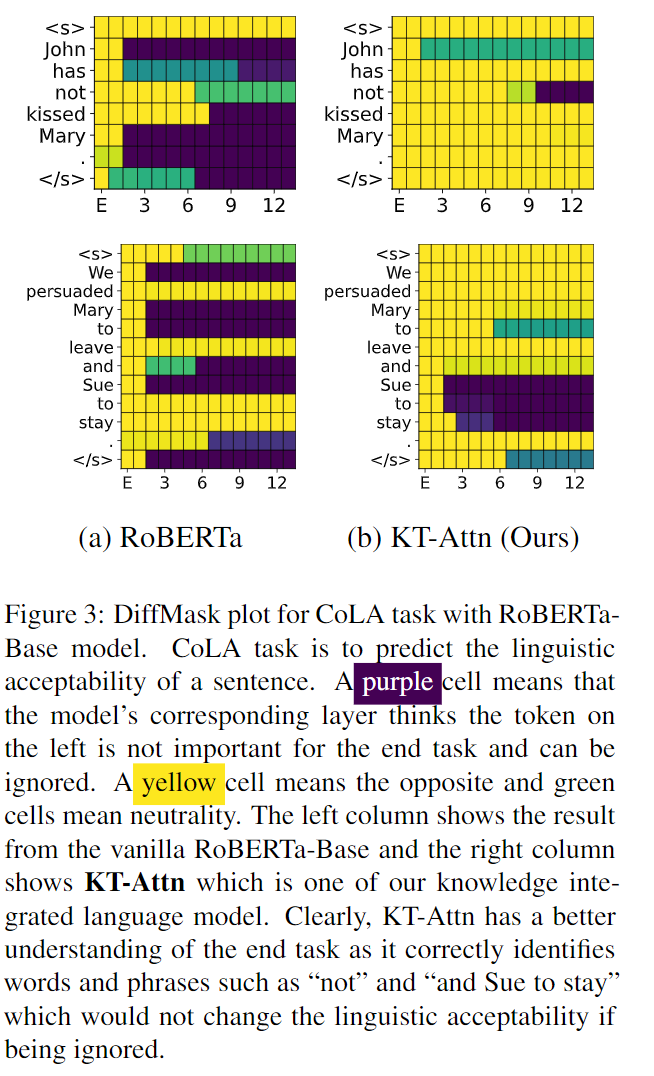
其中,黃色代表重要,紫色代表不重要。可以看到,知識增強(qiáng)之后,第一句 has 和 kissed 最終的重要度顯著提升,我們也知道,這兩個(gè)詞對語法正確的判定尤為重要,第二句中 Sue to stay 最終被視作不重要,也符合我們對英文語法的認(rèn)知。
后面作者也做了各種分析,以及分析了什么樣的知識在什么樣的任務(wù)上會(huì)起到作用,以及分別評估了在不同的預(yù)訓(xùn)練模型上,使用這4種方式分別取得了什么樣的效果。我就不再贅述了,感興趣的讀者們可以去看原文。
我在另一篇論文[3]的解讀中,也提到了另外一種利用預(yù)訓(xùn)練語言模型做圖譜 linking 消歧的方式,這里也不再重復(fù)解讀了。
小結(jié)
總而言之,我認(rèn)為 prompt 作為一種可以更加充分利用預(yù)訓(xùn)練語言模型的方法,其未來是無限可期的,畢竟現(xiàn)在的預(yù)訓(xùn)練語言模型,還是基于大量的自然語料訓(xùn)練而成的,也就是說,預(yù)訓(xùn)練語言模型里面的知識是正確的,所以更需要我們充分抽取、利用它。prompt 還是一個(gè)年輕的方向,還有大量的可能性可以去發(fā)掘,例如,怎樣將它優(yōu)雅地應(yīng)用在序列標(biāo)注任務(wù)上,就是我一直想要弄明白的問題,我們也會(huì)在我們未來的中文理解項(xiàng)目上不斷地去探索 prompt 的應(yīng)用方式,爭取也能夠做出我們理想中的各種中文文本理解的模型。
萌屋作者:Severus
Severus,在某廠工作的老程序員,主要從事自然語言理解方向,資深死宅,日常憤青,對個(gè)人覺得難以理解的同行工作都采取直接吐槽的態(tài)度。筆名取自哈利波特系列的斯內(nèi)普教授,覺得自己也像他那么自閉、刻薄、陰陽怪氣,也向往他為愛而偉大。
作品推薦
?
[1] Liu, Pengfei, et al. "Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing." arXiv preprint arXiv:2107.13586 (2021).
[2] Xu, Ruochen, et al. "Does Knowledge Help General NLU? An Empirical Study." arXiv preprint arXiv:2109.00563 (2021).
[3] Islam, Sk Mainul, and Sourangshu Bhattacharya. "Scalable End-to-End Training of Knowledge Graph-Enhanced Aspect Embedding for Aspect Level Sentiment Analysis." arXiv preprint arXiv:2108.11656 (2021).
